Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Bevor Sie Prompts erstellen, ist es wichtig zu verstehen, wie sie funktionieren. Das System ruft zunächst alle Daten ab, die auf Retrieval Augmented Generation (RAG) basieren, wie beispielsweise Dataverse-Tabellen, die dem Prompt zugeordnet sind. Anschließend analysiert es Eingabedokumente. Schließlich verarbeitet das große Sprachmodell (LLM) die gesammelten Informationen, kombiniert mit den Befehlen.
Je größer die kombinierte Eingabe, desto länger die Antwortzeit, wobei Dokumentdaten der bedeutendste Beitrag sind.
Wir müssen diese Punkte im Kontext der Einschränkungen des Prompts betrachten.
- Die schnelle Ausführung ist auf 100 Sekunden begrenzt.
- Jedes Modell hat eine maximal zulässige Größe für die kombinierte Eingabe, einschließlich Befehle, Daten und der Antwort des Modells.
- Obwohl wir die GPU-Kapazität regelmäßig erhöhen, bleiben Ressourcen begrenzt und werden pro Region und Modell zugeteilt.
Infolgedessen können Probleme wie Zeitüberschreitungen bei der Ausführung, die Erreichung von der Tokenfensterlimits, inkonsistente Antwortzeiten oder Drosselung auftreten. Die folgenden Maßnahmen können Ihnen helfen, diese Probleme zu minimieren.
Wählen Sie das effizienteste Modell für die Aufgabe
Fortschrittlichere Modelle brauchen in der Regel länger, um zu reagieren. Beginne immer mit dem Basic-Modell für dein Szenario, betrachte dann das Standardmodell und reserviere das Premium-Modell nur für Aufgaben, die es wirklich erfordern.
Beispiel: Die Verwendung eines Premium-Modells für eine einfache Sentiment-Analyse ist nicht notwendig.
Optimierung der Länge der Modellausgabe
Die Länge der Ausgabe ist der größte einzelne Faktor, der sowohl die Reaktionszeit als auch die Kosten beeinflusst.
Einschränken Sie das Modell
Bei der Erstellung von Zusammenfassungen oder ähnlichen Ausgaben geben Sie Grenzen wie Wort- oder Satzanzahl an. Ohne Einschränkungen können Modellantworten in Länge, Komplexität und Zeit variieren.
Beispiel: Fassen Sie es in 50 Wörtern zusammen.
Optimieren Sie die JSON-Struktur
Bei Verwendung von JSON-Ausgaben reduzieren Sie die Komplexität, indem Sie die Struktur vereinfachen und die Anzahl der Schlüssel minimieren.
Beispiel: Diese beiden Ausgaben enthalten dieselben Informationen, aber Ausgabe 2 ist deutlich kompakter und effizienter.
| Ausgabe 1 | Ausgabe 2 |
|---|---|
{"extracted data from document":{"Contoso internal policy number": "value"}} |
{"policy":"value"} |
Berücksichtigen Sie nur notwendige Informationen
Vermeiden Sie es, das Modell zu bitten, Informationen zu liefern, die nicht verwendet werden. Unnötige Inhalte erhöhen Kosten und Latenz.
Beispiel: Fordern Sie das Modell nur dann auf, einen Grund anzugeben, wenn dies für menschliche Validierung oder Prüfbarkeit erforderlich ist.
Optimieren Sie die Größe der Modelleingabe
Die Größe der Eingabe hat einen moderaten Einfluss auf Reaktionszeit und Kosten, insbesondere bei der Verarbeitung von Dokumenten oder Bildern.
Redundanz vermeiden
Das Wiederholen ähnlicher Anweisungen erhöht die Kosten und kann das Modell verwirren.
Beispiel: Vermeiden Sie es, mehrere Anweisungen bereitzustellen, die dieselbe Anforderung vermitteln.
Konvertiere die Zahlen in US-Format ... Verwenden Sie bei der Analyse des Inhalts stets US-Normen
Sei prägnant
Modelle verstehen prägnante und direkte Anweisungen. Kurze Prompts sind leichter zu verarbeiten und liefern oft präzisere Ergebnisse.
Beispiel: Der zweite Prompt ist effizienter.
- Erstellen Sie eine Zusammenfassung aus diesem [Inhalt]. Die Zusammenfassung muss professionell sein und als Aufzählungspunkte formatiert sein.
- Fasse [Inhalt] als Aufzählungspunkte mit professionellem Ton zusammen.
Eingabegröße reduzieren
Eingaben enthalten oft Inhalte, die für die Analyse irrelevant sind (zum Beispiel HTML-Tags, wiederholte E-Mail-Signaturen, Standardtext). Verarbeiten Sie den Inhalt möglichst vor: Text extrahieren, Formatierung bereinigen oder große Abschnitte zusammenfassen, bevor Sie sie an eine komplexere Eingabeaufforderung senden.
Beispiel: Verwenden Sie die Html-to-Text-Aktion in einem Workflow, wenn Sie eine E-Mail mit einem Prompt analysieren.
Dokumente nur dann bearbeiten, wenn es erforderlich ist
Dokumentenbearbeitung ist teuer. Wenn du dasselbe Dokument wiederholt verwendest, extrahiere den Inhalt einmal und verwende es wieder, anstatt es jedes Mal neu zu verarbeiten.
Beispiel: In diesem Beispiel sollte [Leitliniendokument] nicht bei jedem Durchlauf verarbeitet werden, sondern dem Prompt als Text bereitgestellt werden. "Betrachten Sie dieses [Leitdokument], um Informationen aus diesem [Dokument zur Verarbeitung] zu extrahieren"
Bearbeiten Sie lange Dokumente in Abschnitten
Lange Dokumente können zu Timeouts führen oder Token-Limits überschreiten. Wenn möglich, verarbeiten Sie Inhalte schrittweise, Seite für Seite oder indem Sie unnötige Seiten vorher kürzen. Das Gleiche gilt für andere Inhaltstypen wie E-Mails, indem nur der aktuellste Thread bereitgestellt wird.
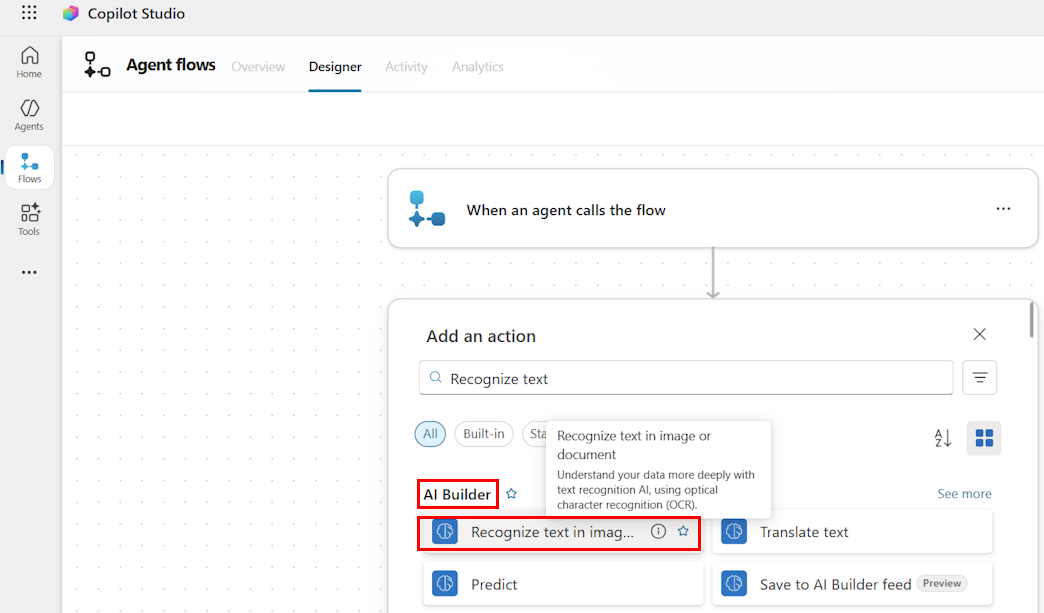
Beispiel: Verwenden Sie die Aktion Text in Bild oder Dokument erkennen in der Kategorie AI Builder, um Seiteninhalte abzurufen und jedes Seitenergebnis mit jeweils angewendeten Seitenergebnissen zu verarbeiten.
Verwenden Sie Filter beim Anwenden von Retrieval Augmented Generation (RAG)
Beim Hinzufügen von Geschäftskontext aus Quellen wie Dataverse-Tabellen werden nur die notwendigen Felder abgerufen und Filter angewendet, um den Datensatz zu reduzieren.
Beispiel: Filtern Sie Produkte nach der Computergerätefamilie und rufen Sie vor dem Abgleich der Produktnamen in einer E-Mail nur das Namensfeld ab.