Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel beschreibt den generischen SQL-Connector. Der Artikel bezieht sich auf folgende Produkte:
- Microsoft Identity Manager 2016 (MIM2016)
- Microsoft Entra ID
Für MIM2016 steht der Connector als Download aus dem Microsoft Download Center zur Verfügung.
Um diesen Connector in Aktion zu sehen, lesen Sie den Artikel Schrittweise Anleitung für den generischen SQL-Connector .
Hinweis
Microsoft Entra ID bietet jetzt eine einfache Agent-basierte Lösung für die Bereitstellung von Benutzern in einer SQL-Datenbank, ohne dass eine MIM-Synchronisierungsbereitstellung erforderlich ist. Wir empfehlen die Verwendung für die Bereitstellung ausgehender Benutzer. Weitere Informationen
Übersicht über den generischen SQL-Connector
Der generische SQL-Connector ermöglicht die Integration des Synchronisierungsdiensts in ein Datenbanksystem mit ODBC-Konnektivität.
Im Anschluss finden Sie einen allgemeinen Überblick über die von der aktuellen Connector-Version unterstützten Features:
| Funktion | Unterstützung |
|---|---|
| Verbundene Datenquelle | Der Connector wird mit allen 64-Bit-ODBC-Treibern* unterstützt. Es wurde mit folgenden Tests getestet: |
| Szenarien | |
| Vorgänge | |
| Schema |
Voraussetzungen
Zur Verwendung des Connectors muss auf dem Synchronisierungsserver Folgendes vorhanden sein:
- Microsoft .NET 4.6.2 Framework oder höher
- 64-Bit-ODBC-Clienttreiber
- Wenn Sie den Connector für die Kommunikation mit Oracle 12c verwenden, erfordert dies Oracle Instant Client 12.2.0.1 oder höher mit dem ODBC-Paket.
- Wenn Sie den Connector für die Kommunikation mit Oracle 18c-23c verwenden, erfordert dies Oracle Instant Client 18-23 oder höher mit dem ODBC-Paket und die NLS_LANG Systemvariable, die so festgelegt werden soll, dass UTF8-Zeichen unterstützt werden, z. B. NLS_LANG=AMERICAN_AMERICA. AL32UTF8.
- Dieser Connector verwendet SQL-vorbereitete Anweisungen und mehrere Anweisungen pro Transaktion. Einige RDBM-Systeme haben möglicherweise Probleme in ihren ODBC-Treibern im Zusammenhang mit der Transaktionsverarbeitung, serverseitigen vorbereiteten SQL-Anweisungen und mehreren Anweisungen innerhalb derselben Transaktion. Konfigurieren Sie ihre DSN-Verbindungsoptionen entsprechend, um sicherzustellen, dass diese Anweisungen ordnungsgemäß an Ihre Datenbank gesendet werden., z. B. benötigt MySQL ODBC-Treiber, Version 8.0.32 Optionen NO_SSPS=1 und MULTI_STATEMENTS=1. Andere Optionen wie "Autocommit" oder "Commit nur für erfolgreiche Vorgänge" können sich darauf auswirken, wie Batchexporte verarbeitet werden; Weitere Informationen erhalten Sie von Ihrem Datenbankadministrator. Um Probleme während des Exports zu beheben, legen Sie die Batchgröße auf 1 fest, und aktivieren Sie die ausführliche Protokollierung des Connectors.
Die Bereitstellung dieses Connectors erfordert möglicherweise Änderungen an der Konfiguration der Datenbank sowie Konfigurationsänderungen an MIM. Für Bereitstellungen, die die Integration von MIM mit einem Drittanbieterdatenbankserver in einer Produktionsumgebung umfassen, empfehlen wir Kunden, mit ihrem Datenbankanbieter oder einem Bereitstellungspartner für Hilfe, Anleitungen und Unterstützung für diese Integration zu arbeiten.
Berechtigungen für die verbundene Datenquelle
Zum Erstellen des generischen SQL-Connectors sowie zum Ausführen der unterstützten Aufgaben benötigen Sie Folgendes:
- db_datareader
- db_datawriter
Ports und Protokolle
Welche Ports für die ordnungsgemäße Verwendung des ODBC-Treibers benötigt werden, können Sie der Dokumentation des Datenbankanbieters entnehmen.
Erstellen eines neuen Connectors
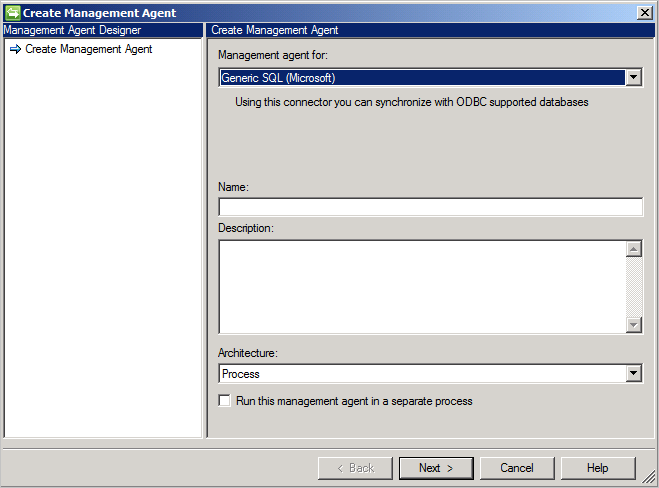
Wählen Sie zum Erstellen eines generischen SQL-Connectors im Synchronisierungsdienst die Option Verwaltungs-Agent und anschließend Erstellen aus. Wählen Sie den Connector Generic SQL (Microsoft) (Generisch, SQL (Microsoft)) aus.
Konnektivität
Der Connector verwendet eine ODBC-DSN-Datei für die Konnektivität. Erstellen Sie die DSN-Datei mithilfe von ODBC Data Sources (ODBC-Datenquellen) (im Startmenü unter Verwaltungstools). Erstellen Sie im Verwaltungstool einen Datei-DSN , um ihn für den Connector bereitzustellen.
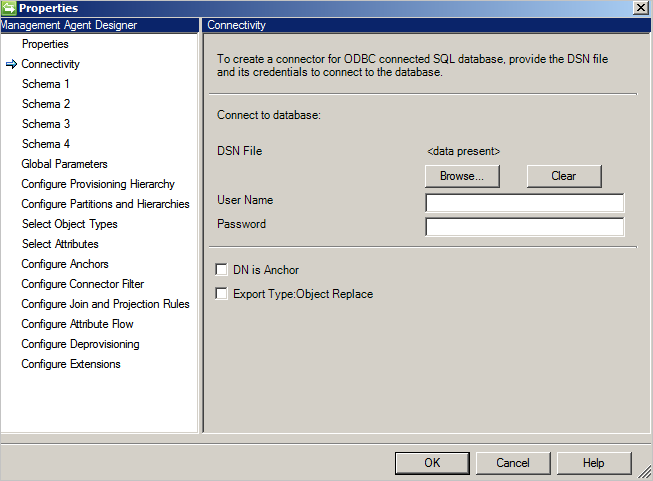
Der Konnektivitätsbildschirm ist der erste, der beim Erstellen eines neuen generischen SQL-Connectors angezeigt wird. Beginnen Sie mit der Angabe folgender Informationen:
- DSN-Dateipfad
- Authentifizierung
- Benutzername
- Kennwort
Die Datenbank muss eine der folgenden Authentifizierungsmethoden unterstützen:
- Windows-Authentifizierung: Die authentifizierende Datenbank überprüft den Benutzer anhand der Windows-Anmeldeinformationen. Zur Authentifizierung bei der Datenbank werden der angegebene Benutzername und das angegebene Kennwort verwendet. Dieses Konto benötigt Berechtigungen für die Datenbank.
- SQL-Authentifizierung: Die authentifizierende Datenbank verwendet zum Herstellen der Datenbankverbindung den im Konnektivitätsbildschirm definierten Benutzernamen und das dazugehörige Kennwort. Wenn Sie Benutzername und Kennwort in der DSN-Datei speichern, haben die im Konnektivitätsbildschirm angegebenen Anmeldeinformationen Vorrang.
- Azure SQL-Datenbank Authentifizierung: Weitere Informationen finden Sie unter Herstellen einer Verbindung mit SQL-Datenbank über die Microsoft Entra-Authentifizierung.
DN is Anchor(DN ist Anker): Wenn Sie diese Option aktivieren, wird der DN auch als Ankerattribut verwendet. Die Option kann bei einer einfachen Implementierung verwendet werden, es gelten jedoch folgende Einschränkungen:
- Der Connector unterstützt nur einen einzelnen Objekttyp. Daher müssen alle Verweisattribute auf den gleichen Objekttyp verweisen.
Export Type: Object Replace(Exporttyp: Objekt ersetzen): Falls nur einige Attribute geändert wurden, wird beim Exportieren das gesamte Objekt mit allen Attributen exportiert und das vorhandene Objekt ersetzt.
Schema 1 (Objekttyperkennung)
Auf dieser Seite wird für den Connector die Suche nach den verschiedenen Objekttypen in der Datenbank konfiguriert.
Jeder Objekttyp wird als Partition dargestellt und unter Configure Partitions and Hierarchies(Konfigurieren von Partitionen und Hierarchien) weiter konfiguriert.
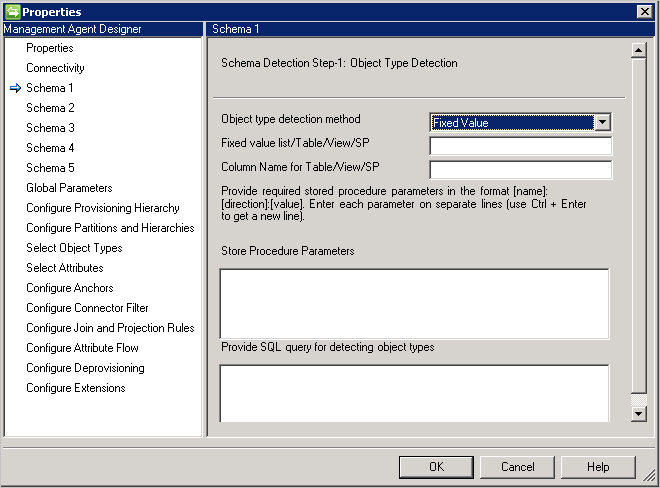
Object Type detection method(Objekttyp-Erkennungsmethode): Der Connector unterstützt folgende Objekttyp-Erkennungsmethoden:
- Fester Wert: Geben Sie eine kommagetrennte Liste mit Objekttypen an. Beispiel:
User,Group,Department
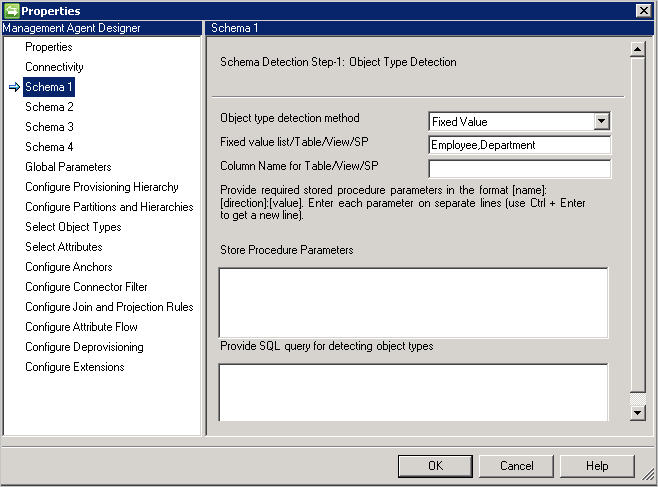
- Table/View/Stored Procedure(Tabelle/Sicht/Gespeicherte Prozedur): Geben Sie den Namen der Tabelle, Sicht oder gespeicherten Prozedur und anschließend den Namen der Spalte mit der Objekttypenliste an. Geben Sie bei Verwendung einer gespeicherten Prozedur außerdem Parameter im Format [Name]:[Richtung]:[Wert]an. Geben Sie die Parameter jeweils in einer separaten Zeile an.
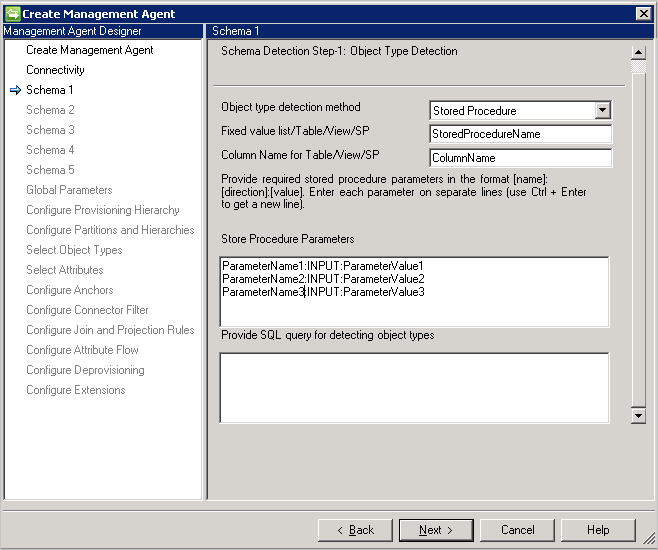
- SQL-Abfrage: Diese Option ermöglicht die Angabe einer SQL-Abfrage, die eine einzelne Spalte mit Objekttypen zurückgibt (Beispiel:
SELECT [Column Name] FROM TABLENAME). Die zurückgegebene Spalte muss vom Typ „String“ (varchar) sein.
Schema 2 (Attributtyperkennung)
Auf dieser Seite wird die Erkennung der Attributnamen und -typen konfiguriert. Die Konfigurationsoptionen werden für jeden auf der vorherigen Seite ermittelten Objekttyp aufgeführt.
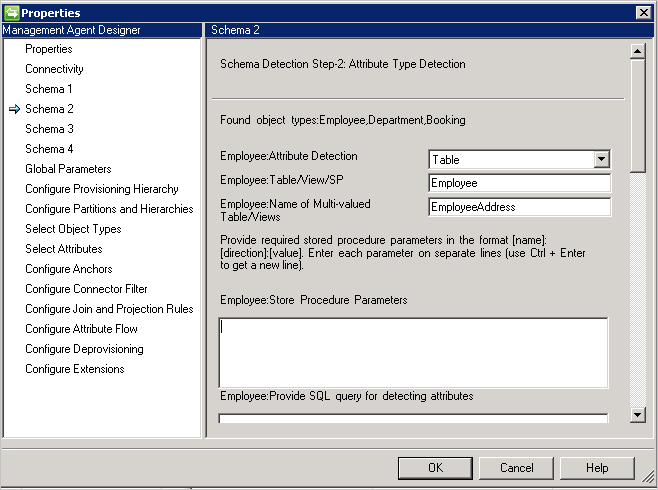
Attribute Type detection method(Attributtyp-Erkennungsmethode): Der Connector unterstützt für jeden im Schema 1-Bildschirm erkannten Objekttyp folgende Attributtyp-Erkennungsmethoden:
- Table/View/Stored Procedure(Tabelle/Sicht/Gespeicherte Prozedur): Geben Sie den Namen der Tabelle, Sicht oder gespeicherten Prozedur an, die für die Suche nach den Attributnamen verwendet werden soll. Geben Sie bei Verwendung einer gespeicherten Prozedur außerdem Parameter im Format [Name]:[Richtung]:[Wert]an. Geben Sie die Parameter jeweils in einer separaten Zeile an. (Drücken Sie STRG+EINGABETASTE, um eine neue Zeile zu erhalten.) Wenn Sie Attributnamen in einem mehrwertigen Attribut ermitteln möchten, geben Sie eine kommagetrennte Tabellen- oder Sichtenliste an. Mehrwertige Szenarien, bei denen die übergeordnete und die untergeordnete Tabelle die gleichen Spaltennamen enthalten, werden nicht unterstützt.
- SQL-Abfrage: Diese Option ermöglicht die Angabe einer SQL-Abfrage, die eine einzelne Spalte mit Attributnamen zurückgibt (Beispiel:
SELECT [Column Name] FROM TABLENAME). Die zurückgegebene Spalte muss vom Typ „String“ (varchar) sein.
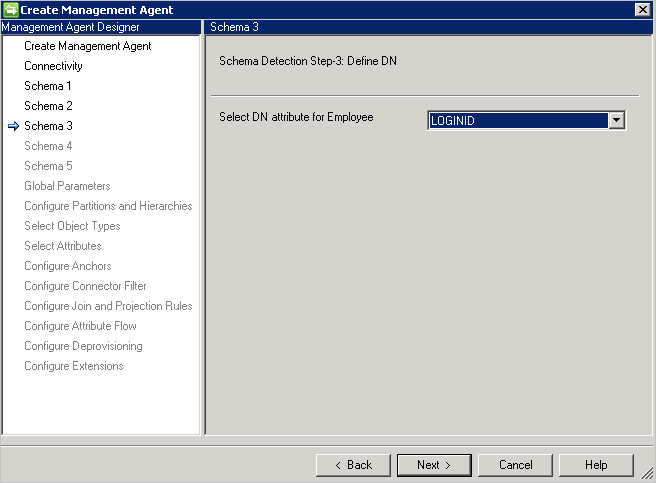
Schema 3 (Definieren von Anker und DN)
Auf dieser Seite können Sie jeweils das Anker- und DN-Attribut für die erkannten Objekttypen konfigurieren. Sie können mehrere Attribute auswählen, um einen eindeutigen Anker zu erhalten.
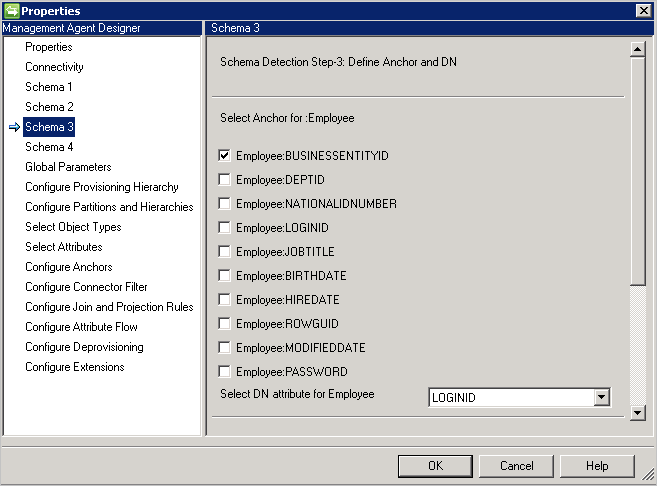
Mehrwertige und boolesche Attribute werden nicht aufgeführt.
Für DN und Anker kann nicht das gleiche Attribut verwendet werden, es sei denn, auf der Konnektivitätsseite wurde die Option DN is Anchor (DN ist Anker) aktiviert.
Ist auf der Konnektivitätsseite die Option DN is Anchor (DN ist Anker) aktiviert, wird auf dieser Seite nur das DN-Attribut benötigt. Dieses Attribut wird dann auch als Ankerattribut verwendet.
Schema 4 (Definieren von Attributtyp, Verweis und Richtung)
Auf dieser Seite können Sie für die Attribute jeweils den Attributtyp (beispielsweise ganze Zahl, Binärwert oder boolescher Wert) und die Richtung konfigurieren. Hier werden alle Attribute der Seite Schema 2 aufgeführt (auch mehrwertige Attribute).
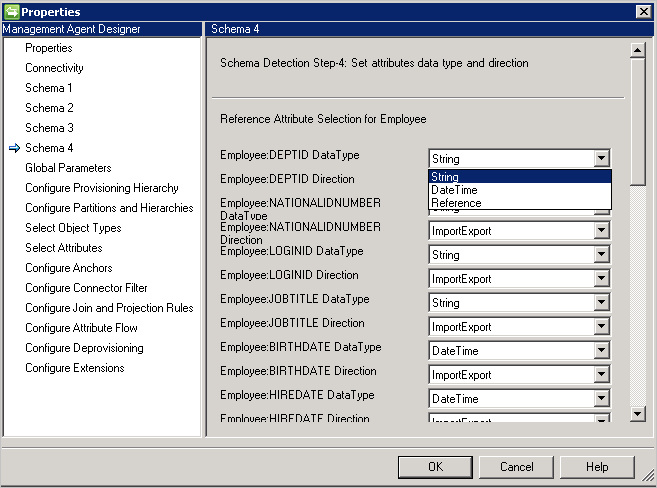
- DataType: Dient dazu, den Attributtyp den Typen zuzuordnen, die dem Synchronisierungsmodul bekannt sind. Standardmäßig wird der im SQL-Schema erkannte Typ verwendet, „Datum/Uhrzeit“ und „Verweis“ sind jedoch nicht so einfach erkennbar. Hierfür muss DateTime oder Reference angegeben werden.
- Direction: Die Richtung des Attributs kann auf „Import“, „Export“ oder „ImportExport“ festgelegt werden. „ImportExport“ ist die Standardeinstellung.
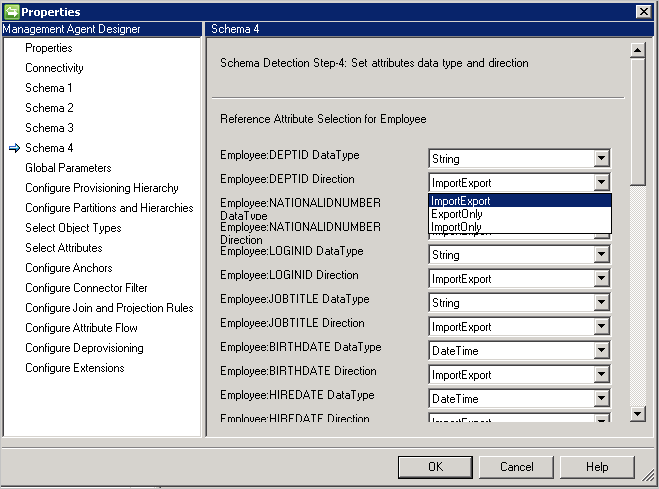
Hinweise:
- Falls ein Attributtyp nicht vom Connector erkannt werden kann, wird der Datentyp „String“ verwendet.
- Geschachtelte Tabellen können als einspaltige Datenbanktabellen betrachtet werden. Oracle speichert die Zeilen einer geschachtelten Tabelle in keiner bestimmten Reihenfolge. Beim Abrufen der geschachtelten Tabelle in eine PL/SQL-Variable werden die Zeilen jedoch mit fortlaufenden tiefgestellten Zeichen (beginnend mit 1) versehen. Dies ermöglicht einen arrayähnlichen Zugriff auf einzelne Zeilen.
- VARRYS werden vom Connector nicht unterstützt.
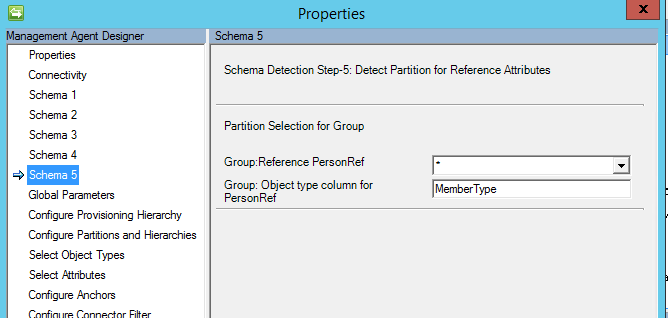
Schema 5 (Definieren der Partition für Verweisattribute)
Auf dieser Seite wird für alle Referenzattribute konfiguriert, auf welche Partition (Objekttyp) das jeweilige Attribut verweist.
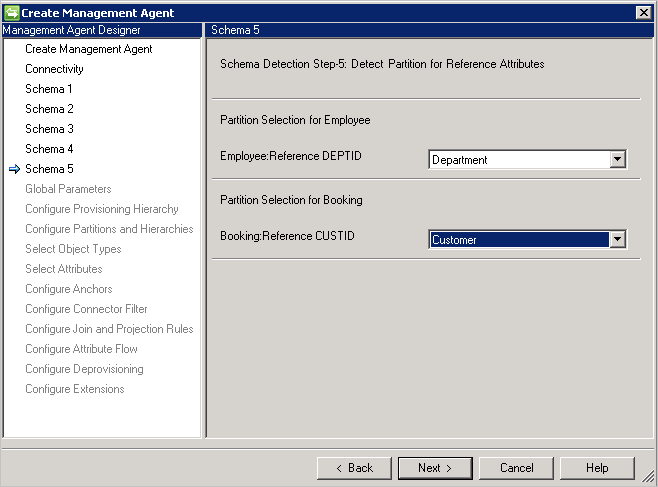
Bei Verwendung von DN is anchor(DN ist Anker) muss der gleiche Objekttyp verwendet werden, der auch den Ausgangspunkt des Verweises darstellt. Sie können nicht auf einen anderen Objekttyp verweisen.
Hinweis
Seit dem Update vom März 2017 steht nun eine Option für „*“ zur Verfügung. Bei Auswahl dieser Option werden alle möglichen Mitgliedstypen importiert.
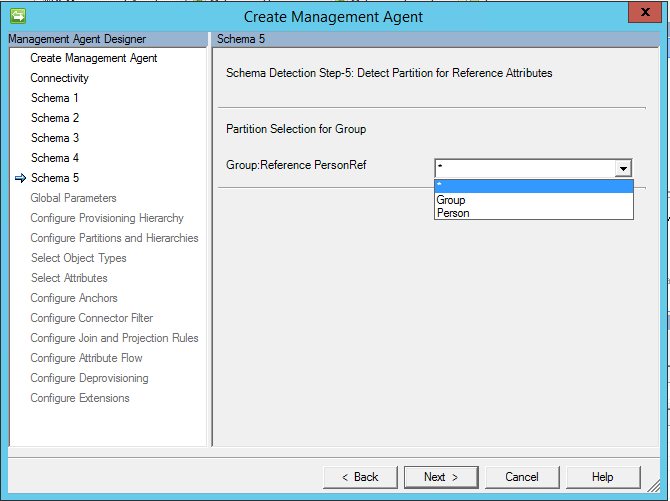
Wichtig
Ab Mai 2017 wurde die Option „*“ (beliebige Option) geändert, um auch Import- und Exportflows zu unterstützen. Wenn Sie diese Option verwenden möchten, muss Ihre mehrwertige Tabelle/Sicht ein Attribut mit dem Objekttyp enthalten.

Wenn "*" ausgewählt ist, muss auch der Name der Spalte mit dem Objekttyp angegeben werden.
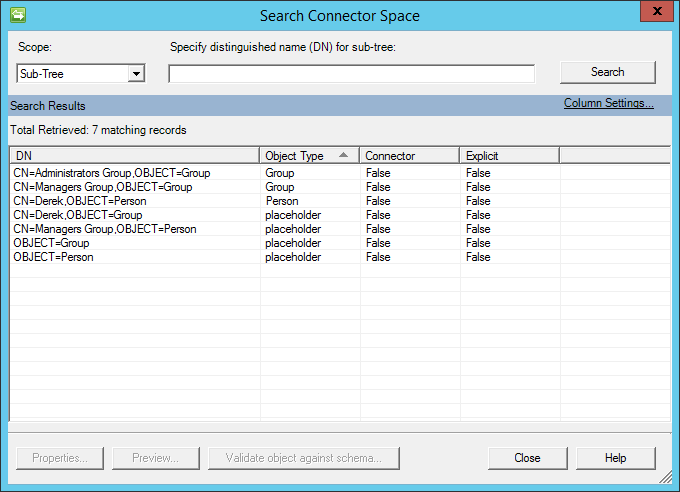
Nach dem Import wird etwas Ähnliches wie in der folgenden Abbildung angezeigt:
Globale Parameter
Auf der Seite für globale Parameter können Sie den Deltaimport, das Datums-/Uhrzeitformat sowie die Kennwortmethode konfigurieren.
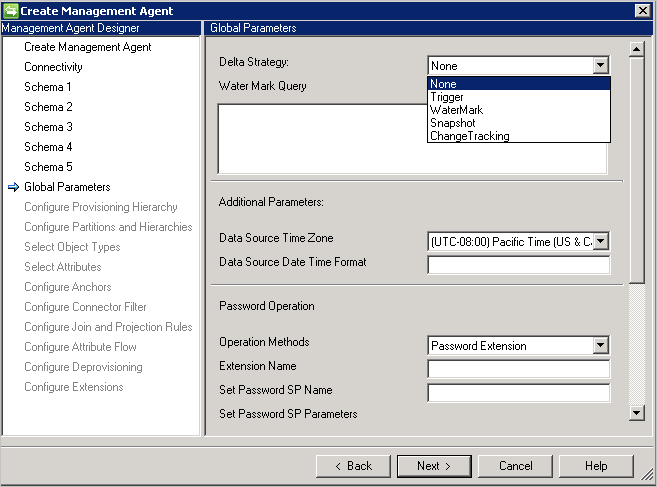
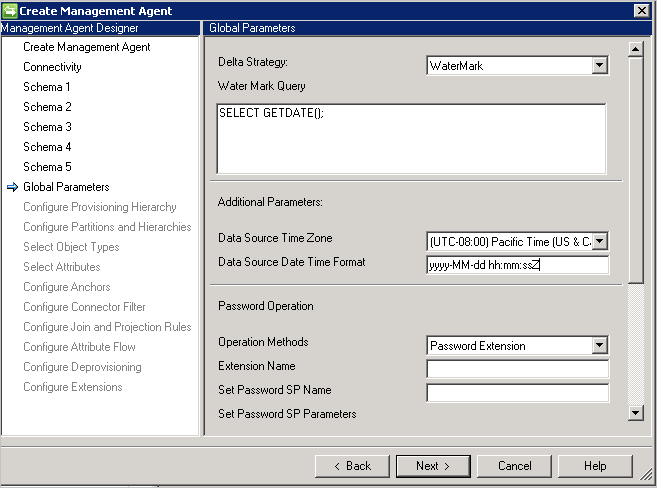
Der generische SQL-Connector unterstützt folgende Methoden für den Deltaimport:
- Trigger: Weitere Informationen finden Sie unter Generieren von Deltasichten mithilfe von Triggern.
- Wasserzeichen: Eine allgemeine Methode, die für jede beliebige Datenbank verwendet werden kann. Die Wasserzeichenabfrage wird auf der Grundlage des Datenbankanbieters vorab aufgefüllt. Jede verwendete Tabelle/Sicht muss über eine Wasserzeichenspalte verfügen. Diese Spalte muss Einfüge- und Aktualisierungsvorgänge für die Tabellen sowie für abhängige (mehrwertige oder untergeordnete) Tabellen nachverfolgen. Die Uhren zwischen Synchronisierungsdienst und Datenbankserver müssen synchronisiert werden. Andernfalls werden unter Umständen einige Einträge im Deltaimport ausgelassen.
Einschränkung:- Die Wasserzeichenstrategie unterstützt keine gelöschten Objekte.
- Momentaufnahme: (Kann nur mit Microsoft SQL Server verwendet werden.) Generieren von Deltasichten mithilfe von Momentaufnahmen
- Änderungsnachverfolgung: (Kann nur mit Microsoft SQL Server verwendet werden.) About Änderungsnachverfolgung
Begrenzungen:- Anker- und DN-Attribut müssen Teil des Primärschlüssels für das ausgewählte Objekt in der Tabelle sein.
- Die SQL-Abfrage wird beim Importieren und Exportieren mit Änderungsnachverfolgung nicht unterstützt.
Zusätzliche Parameter: Geben Sie mithilfe der Zeitzone des Datenbankservers den Standort Ihres Datenbankservers an. Dieser Wert dient zur Unterstützung der verschiedenen Formate von Datums-/Uhrzeitattributen.
Der Connector speichert Datums- und Datums-/Uhrzeitwerte immer im UTC-Format. Zur ordnungsgemäßen Konvertierung von Datums- und Uhrzeitangaben müssen die Zeitzone des Datenbankservers und das verwendete Format angegeben werden. Das Format sollte im .NET-Format ausgedrückt werden.
Beim Exportieren muss jedes Datums-/Uhrzeitattribut für den Connector im UTC-Format angegeben werden.
Password Configuration(Kennwortkonfiguration): Der Connector bietet Kennwortsynchronisierungsfunktionen und unterstützt das Festlegen und Ändern von Kennwörtern.
Der Connector stellt zwei Methoden zur Unterstützung der Kennwortsynchronisierung bereit:
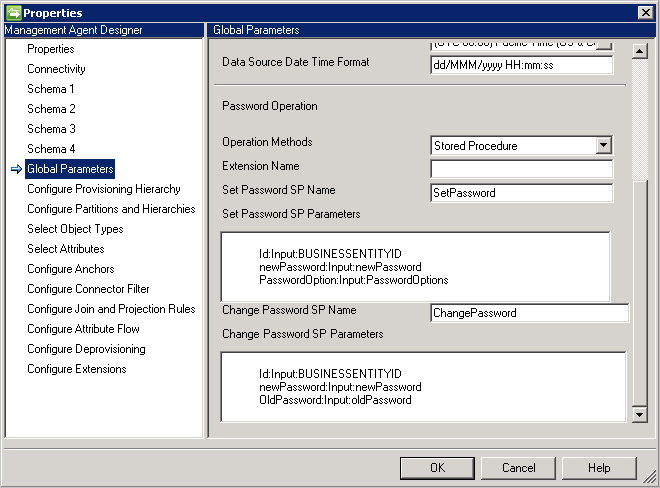
- Stored Procedure (Gespeicherte Prozedur): Diese Methode erfordert zwei gespeicherte Prozeduren, um das Festlegen und Ändern von Kennwörtern zu unterstützen. Geben Sie alle Parameter für das Hinzufügen und Ändern von Kennwörtern unter Set Password SP (Parameter für die gespeicherte Prozedur zum Festlegen von Kennwörtern) bzw. unter Change Password SP (Parameter für die gespeicherte Prozedur zum Ändern von Kennwörtern) ein, wie im folgenden Beispiel zu sehen:
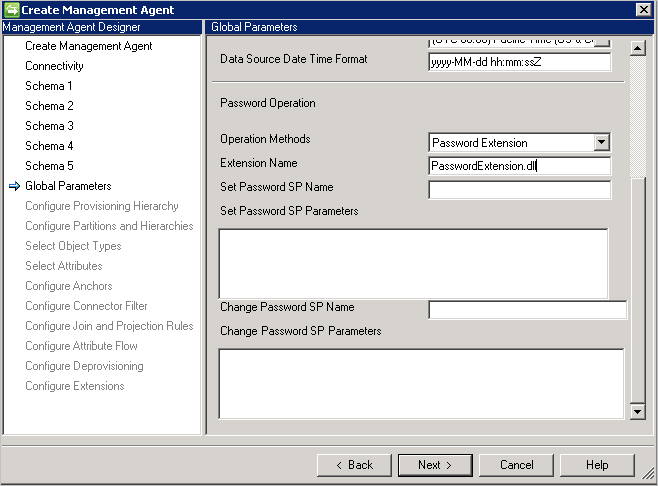
- Password Extension (Kennworterweiterung): Diese Methode erfordert eine Kennworterweiterungs-DLL. (Geben Sie den Namen der Erweiterungs-DLL an, die die Schnittstelle IMAExtensible2Password implementiert.) Die Kennworterweiterungsassembly muss im Erweiterungsordner platziert werden, damit der Connector die DLL zur Laufzeit laden kann.
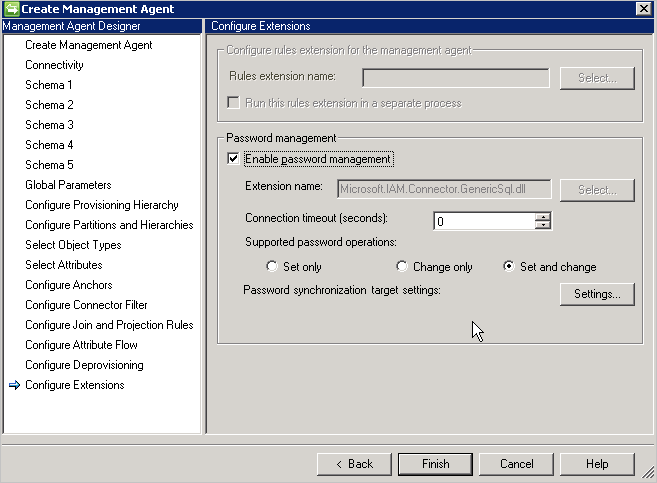
Außerdem muss auf der Seite Erweiterung konfigurieren die Kennwortverwaltung aktiviert werden.
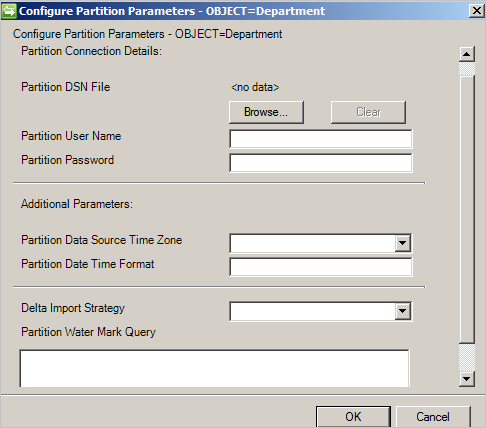
Konfigurieren von Partitionen und Hierarchien
Wählen Sie auf der Seite mit den Partitionen und Hierarchien alle Objekttypen aus. Jeder Objekttyp stellt eine eigene Partition dar.
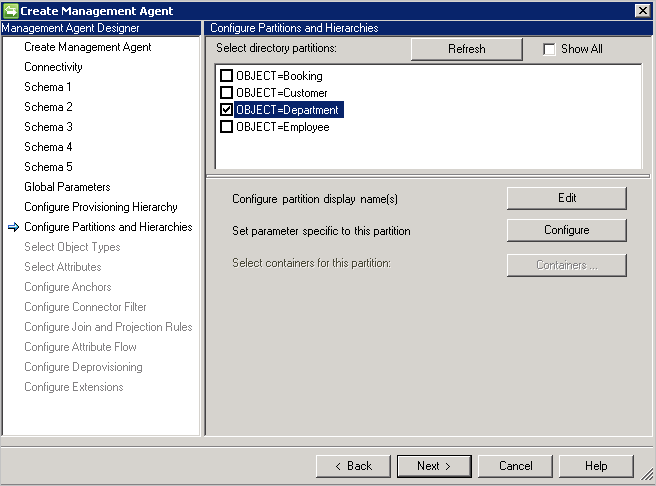
Darüber hinaus können Sie die auf der Konnektivitätsseite oder auf der Seite mit den globalen Parametern definierten Werte überschreiben.
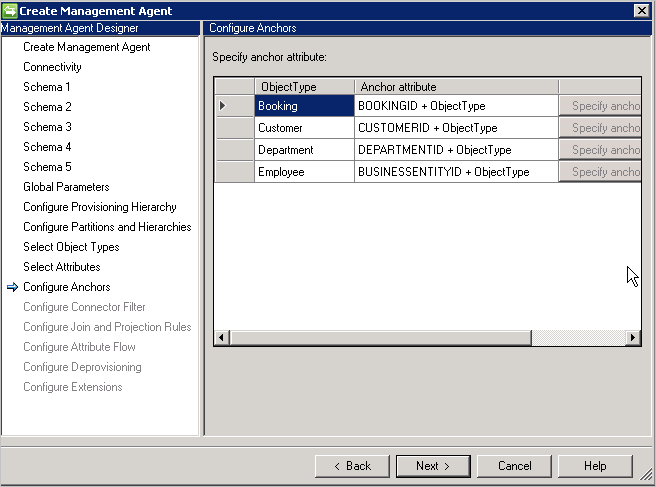
Konfigurieren von Ankern
Diese Seite ist schreibgeschützt, da der Anker bereits definiert wurde. Dem ausgewählten Ankerattribut wird immer der Objekttyp angefügt, um sicherzustellen, dass es objekttypübergreifend eindeutig ist.
Konfigurieren des Ausführungsschrittparameters
Diese Schritte werden für die connectorspezifischen Ausführungsprofile konfiguriert. Die Konfigurationen übernehmen das eigentliche Importieren und Exportieren von Daten.
Vollständiger Import und Deltaimport
Der generische SQL-Connector unterstützt vollständige Importe und Deltaimporte mit folgenden Methoden:
- Tabelle
- Sicht
- Gespeicherte Prozedur
- SQL-Abfrage
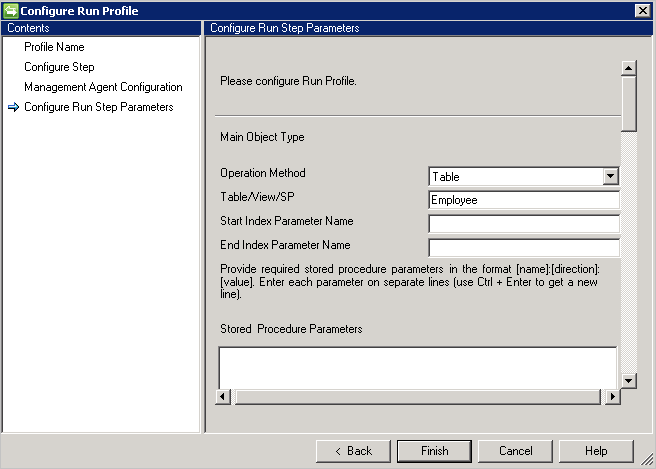
Table/View
Zum Importieren mehrwertiger Attribute für ein Objekt müssen Sie unter Name der mehrwertigen Tabelle/Sichten die Tabellen-/Sichtnamen und unter Verknüpfungsbedingung die entsprechenden Verknüpfungsbedingungen für die übergeordnete Tabelle angeben. Wenn die Datenquelle mehrere mehrwertige Tabellen enthält, können Sie „union“ verwenden, um eine einzelne Sicht zu erhalten.
Wichtig
Der Agent für die generische SQL-Verwaltung kann nur mit einer mehrwertigen Tabelle verwendet werden. Geben Sie unter „Name der mehrwertigen Tabelle/Sichten“ nur einen Tabellennamen ein. Dies ist eine Einschränkung bei der generischen SQL-Verwaltung.
Ein Beispiel: Sie möchten das Employee-Objekt und alle dazugehörigen mehrwertigen Attribute importieren. Es gibt zwei Tabellen: die Haupttabelle „Employee“ und die mehrwertige Tabelle „Department“. Gehen Sie folgendermaßen vor:
- Geben Sie unter Table/View/SP (Tabelle/Sicht/Gespeicherte Prozedur) die Zeichenfolge Employee ein.
- Geben Sie unter Name of Multi-Valued table/views(Name der mehrwertigen Tabelle/Sichten) die Zeichenfolge „Department“ ein.
- Geben Sie unter Verknüpfungsbedingung die Verknüpfungsbedingung zwischen „Employee“ und „Department“ ein (beispielsweise
Employee.DEPTID=Department.DepartmentID).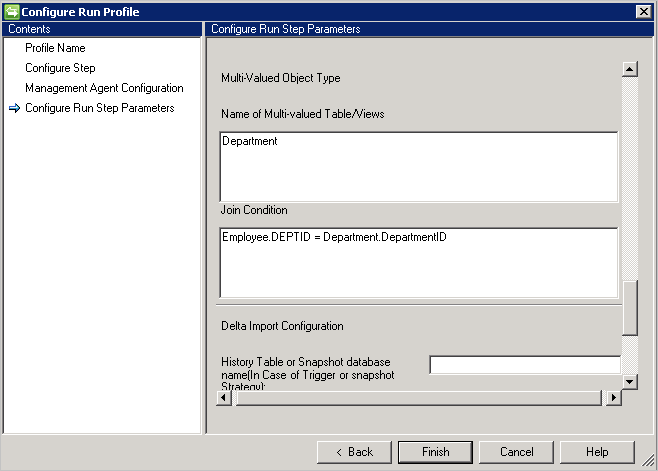
Gespeicherten Prozeduren
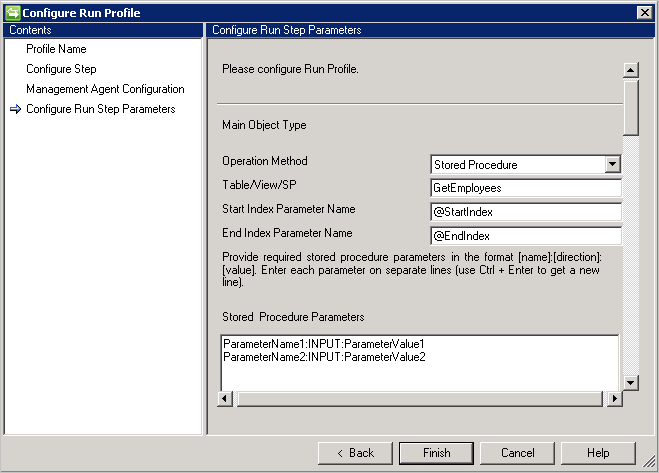
- Bei großen Datenmengen empfiehlt sich die Implementierung der Paginierung für gespeicherte Prozeduren.
- Damit Ihre gespeicherte Prozedur die Paginierung unterstützt, müssen Sie den Start- und den Endindex angeben. Weitere Informationen finden Sie unter Effiziente Paginierung bei großen Datenmengen.
- @StartIndex@EndIndex werden zur Ausführungszeit durch entsprechende Seitengrößenwerte ersetzt, die auf der Seite Configure Step (Schritt konfigurieren) konfiguriert wurden. Ein Beispiel: Angenommen, der Connector ruft die erste Seite ab, und die Seitengröße ist auf 500 festgelegt. In diesem Fall wird @StartIndex auf 1 und @EndIndex auf 500 festgelegt. Diese Werte werden größer, wenn der Connector weitere Seiten abruft, was die Änderung von @StartIndex und @EndIndex nach sich zieht.
- Geben Sie zum Ausführen einer parametrisierten gespeicherten Prozedur die Parameter im Format
[Name]:[Direction]:[Value]an. Geben Sie die Parameter jeweils in eine separate Zeile ein. (Drücken Sie STRG+EINGABETASTE, um eine neue Zeile zu erhalten.) - Der generische SQL-Connector unterstützt auch Importvorgänge aus Verbindungsservern in Microsoft SQL Server. Falls Informationen aus einer Tabelle auf dem Verbindungsserver abgerufen werden sollen, muss die Tabelle im folgenden Format angegeben werden:
[ServerName].[Database].[Schema].[TableName] - Der generische SQL-Connector unterstützt nur Objekte mit ähnlicher Struktur (Aliasname und Datentyp) zwischen Ausführungsschrittinformationen und Schemaerkennung. Wenn sich das Schema und die für den Ausführungsschritt angegebenen Informationen bei dem ausgewählten Objekt unterscheiden, unterstützt der SQL-Connector das entsprechende Szenario nicht.
SQL-Abfrage
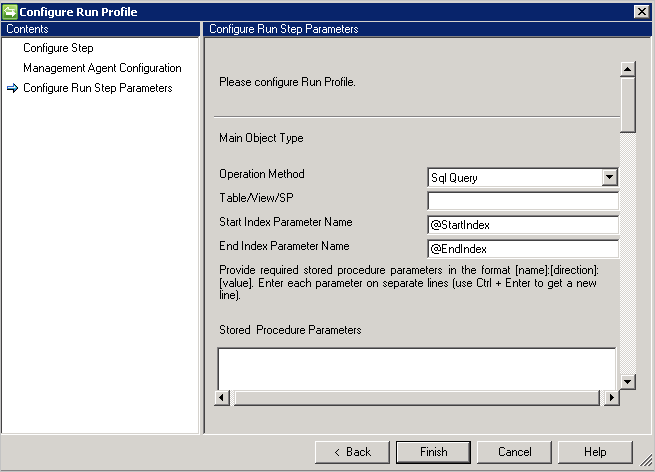
Wichtig
CRLF- oder neue Zeilenzeichen dienen als Trennzeichen zwischen mehreren Anweisungen.
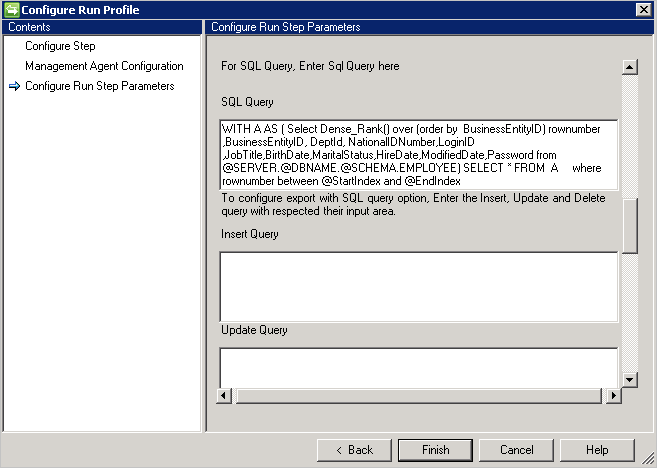
Beispiel-SQL-Abfrage mit Paginierung - falsche Abfrage, funktioniert nicht, wenn das neue Zeilenzeichen verwendet wird:
WITH A AS
(select dense_rank() over (order by BusinessEntityID)
rownumber, BusinessEntityID, DeptID, NationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, HireDate, ModifiedDate, Password
from Employees
) select * from A where rownumber between @StartIndex and @EndIndex
Beispiel-SQL-Abfrage mit Paginierung – richtige Abfrage:
WITH A AS (select dense_rank() over (order by BusinessEntityID) rownumber, BusinessEntityID, DeptID, NationalIDNumber, LoginID, JobTitle, BirthDate, MaritalStatus, HireDate, ModifiedDate, Password from Employees) select * from A where rownumber between @StartIndex and @EndIndex
- Abfragen mit mehreren Resultsets werden nicht unterstützt.
- SQL-Abfrage unterstützt die Paginierung und stellt Startindex und Endindex als Variable zur Unterstützung der Paginierung bereit.
Deltaimport
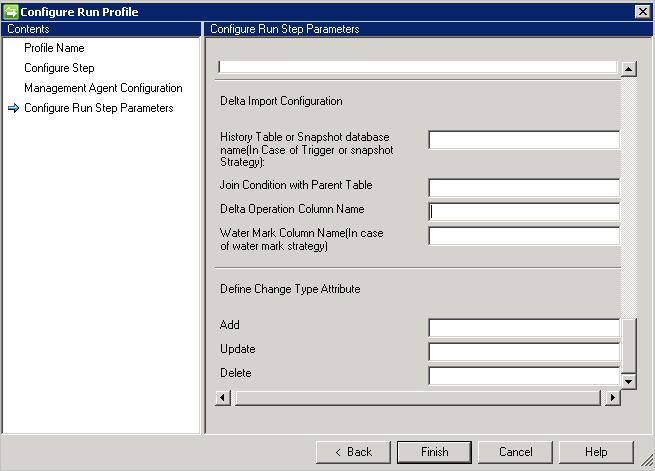
Im Vergleich zum vollständigen Import erfordert der Deltaimport einige weitere Konfigurationsschritte.
- Bei Verwendung der Nachverfolgung von Deltaänderungen mithilfe der Trigger- oder Momentaufnahmemethode müssen Sie im Feld History Table or Snapshot database name (Name der Verlaufstabelle oder Momentaufnahmedatenbank) den Namen der Verlaufstabelle oder der Momentaufnahmedatenbank angeben.
- Darüber hinaus müssen Sie Verknüpfungsbedingungen für die Verlaufstabelle und die übergeordnete Tabelle angeben. Beispiel:
Employee.ID=History.EmployeeID - Um die Transaktion der übergeordneten Tabelle anhand der Verlaufstabelle nachverfolgen zu können, müssen Sie den Namen der Spalte mit den Vorgangsinformationen (Hinzufügung/Aktualisierung/Löschung) angeben.
- Wenn Sie Deltaänderungen mithilfe der Wasserzeichenmethode nachverfolgen möchten, müssen Sie den Namen der Spalte mit den Vorgangsinformationen unter Water Mark Column Name(Wasserzeichenspaltenname) angeben.
- Die Spalte change Type attribute (Änderungstypattribut) wird für den Änderungstyp benötigt. Diese Spalte ordnet eine Änderung aus der primären oder mehrwertigen Tabelle einem Änderungstyp in der Deltasicht zu. Diese Spalte kann für Änderungen auf Attributebene den Änderungstyp „Modify_Attribute“ und für Änderungen auf Objektebene den Änderungstyp „Hinzufügen“, „Ändern“ oder „Löschen“ enthalten. Sollte es sich um einen anderen Wert als „Hinzufügen“, „Ändern“ oder „Löschen“ handeln, können Sie die entsprechenden Werte mithilfe dieser Option definieren.
Exportieren
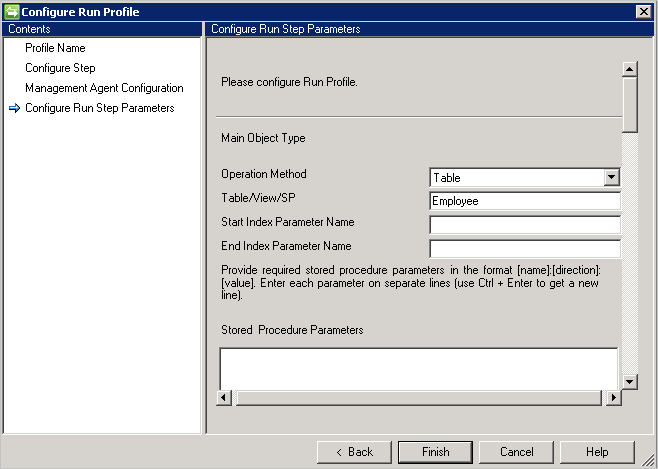
Der generische SQL-Connector unterstützt vier Methoden für den Export:
- Tabelle
- Sicht
- Gespeicherte Prozedur
- SQL-Abfrage
Table/View
(Tabelle/Sicht) Bei Verwendung der Option „Table/View“ (Tabelle/Sicht) generiert der Connector die entsprechenden Abfragen und führt den Exportvorgang aus.
Gespeicherten Prozeduren
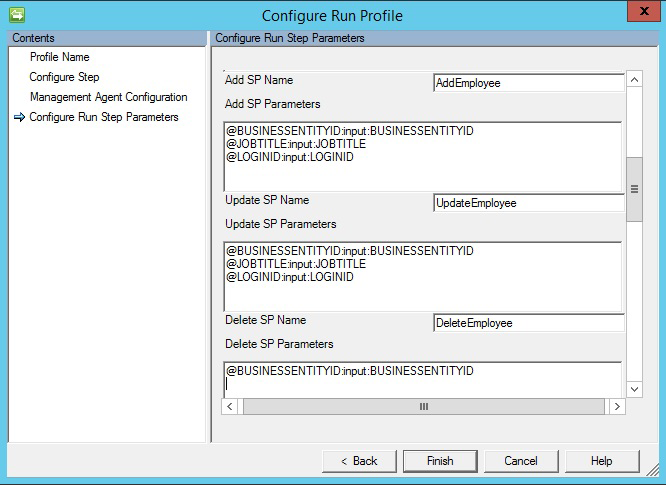
Bei Verwendung der Option „Stored Procedure“ (Gespeicherte Prozedur) werden drei verschiedene gespeicherte Prozeduren für Einfüge-/Aktualisierungs-/Löschvorgänge benötigt:
- Add SP Name(Name der gespeicherten Prozedur zum Hinzufügen): Diese gespeicherte Prozedur wird ausgeführt, wenn der Connector ein Objekt erhält, das in die entsprechende Tabelle eingefügt werden soll.
- Update SP Name(Name der gespeicherten Prozedur zum Aktualisieren): Diese gespeicherte Prozedur wird ausgeführt, wenn der Connector ein Objekt erhält, das in der entsprechenden Tabelle aktualisiert werden soll.
- Delete SP Name(Name der gespeicherten Prozedur zum Löschen): Diese gespeicherte Prozedur wird ausgeführt, wenn der Connector ein Objekt erhält, das in der entsprechenden Tabelle gelöscht werden soll.
- Attribut aus dem Schema, das als Parameterwert für die gespeicherte Prozedur verwendet wird. Beispiel:
@EmployeeName: INPUT: EmployeeName(„EmployeeName“ ist im Connectorschema ausgewählt, und der Connector ersetzt den entsprechenden Wert im Zuge des Exportvorgangs.) - Geben Sie zum Ausführen einer parametrisierten gespeicherten Prozedur Parameter im Format
[Name]:[Direction]:[Value]an. Geben Sie die Parameter jeweils in eine separate Zeile ein. (Drücken Sie STRG+EINGABETASTE, um eine neue Zeile zu erhalten.)
SQL-Abfrage
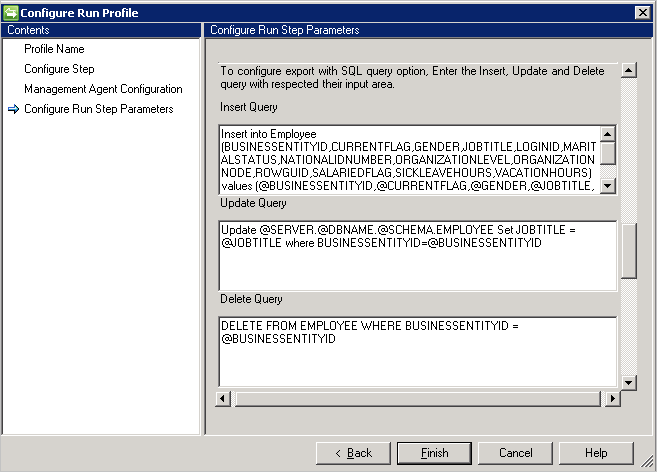
Bei Verwendung der Option „SQL-Abfrage“ werden drei verschiedene Abfragen für Einfüge-/Aktualisierungs-/Löschvorgänge benötigt:
- Insert Query(Abfrage für Einfügevorgänge): Diese Abfrage wird ausgeführt, wenn der Connector ein Objekt erhält, das in die entsprechende Tabelle eingefügt werden soll.
- Update Query(Abfrage für Aktualisierungsvorgänge): Diese Abfrage wird ausgeführt, wenn der Connector ein Objekt erhält, das in der entsprechenden Tabelle aktualisiert werden soll.
- Delete Query(Abfrage für Löschvorgänge): Diese Abfrage wird ausgeführt, wenn der Connector ein Objekt erhält, das in der entsprechenden Tabelle gelöscht werden soll.
- Attribut aus dem Schema, das als Parameterwert für die Abfrage verwendet wird. Beispiel:
Insert into Employee (ID, Name) Values (@ID, @EmployeeName)
Wichtig
CRLF- oder neue Zeilenzeichen dienen als Trennzeichen zwischen mehreren Anweisungen.
Sql-Beispiel-Aktualisierungsabfrage mit mehreren Schritten – das neue Zeilenzeichen wird verwendet, um SQL-Anweisungen zu trennen:
update Employee set jobTitle=@JOBTITLE where BusinessEntityID=@BUSINESSENTITYID
insert into ChangeLog VALUES (@BUSINESSENTITYID)
Problembehandlung
- Informationen zum Aktivieren der Protokollierung für die Behandlung von Connectorproblemen finden Sie unter Vorgehensweise: Aktivieren der ETW-Ablaufverfolgung für Connectors.