Problembehandlung bei der XMLA-Endpunktkonnektivität
XMLA-Endpunkte in Power BI verlassen sich auf das systemeigene Analysis Services-Kommunikationsprotokoll für den Zugriff auf Semantikmodelle von Power BI. Aus diesem Grund ähnelt die Problembehandlung für XMLA-Endpunkte in weiten Teilen der Problembehandlung einer typischen Analysis Services-Verbindung. Es gibt allerdings einige Unterschiede in Bezug auf Power BI-spezifische Abhängigkeiten.
Voraussetzungen
Bevor Sie die Problembehandlung in einem Szenario mit XMLA-Endpunkten durchführen, lesen Sie sich die Grundlagen zur Semantikmodellkonnektivität mit XMLA-Endpunkten durch. Dort werden die meisten gängigen Anwendungsfälle für XMLA-Endpunkte erläutert. Andere Leitfäden zur Problembehandlung in Power BI können auch recht nützlich sein, wie z. B. Lokales Datengateway – Problembehandlung und Problembehandlung bei „In Excel analysieren“.
Aktivieren des XMLA-Endpunkts
Der XMLA-Endpunkt kann sowohl für Kapazitäten von Power BI Premium als auch für Premium per Benutzer und Power BI Embedded aktiviert werden. Bei kleineren Kapazitäten, wie z. B. A1 mit nur 2,5 GB Arbeitsspeicher, kann ein Fehler in den Kapazitätseinstellungen auftreten, wenn Sie versuchen, den XMLA-Endpunkt auf Lesen/Schreiben festzulegen und dann Anwenden auszuwählen. Der Fehler lautet: „Fehler in Ihren Workloadeinstellungen. Versuchen Sie es nach einiger Zeit noch mal.“
Folgendes können Sie ausprobieren:
- Begrenzen Sie den Arbeitsspeicherverbrauch anderer Dienste in der Kapazität – z. B- Dataflows – auf 40 % oder weniger, oder deaktivieren Sie einen nicht benötigten Dienst vollständig.
- Führen Sie ein Upgrade der Kapazität auf eine größere SKU durch. Ein Upgrade von A1 auf A3 beispielsweise löst dieses Konfigurationsproblem, ohne dass Sie Dataflows deaktivieren müssen.
Denken Sie daran, dass Sie im Power BI-Administratorportal auch die Einstellung Daten exportieren auf Mandantenebene aktivieren müssen. Diese Einstellung ist auch für das Feature „In Excel analysieren“ erforderlich.
Herstellen einer Clientverbindung
Nach dem Aktivieren des XMLA-Endpunkts empfiehlt es sich, die Konnektivität mit einem Arbeitsbereich in der Kapazität zu testen. Weitere Informationen finden Sie unter Herstellen einer Verbindung mit einem Premium-Arbeitsbereich. Lesen Sie auch unbedingt den Abschnitt Verbindungsanforderungen, in dem Sie nützliche Tipps und Informationen zu aktuellen Einschränkungen der XMLA-Konnektivität erhalten.
Herstellen einer Verbindung mit einem Dienstprinzipal
Wenn Sie die Mandanteneinstellungen so festgelegt haben, dass Dienstprinzipale Power BI-APIs verwenden dürfen, wie unter Aktivieren von Dienstprinzipalen beschrieben, können Sie über einen Dienstprinzipal eine Verbindung mit einem XMLA-Endpunkt herstellen. Denken Sie daran, dass der Dienstprinzipal dieselben Zugriffsberechtigungen auf Arbeitsbereichs- oder Semantikmodellebene benötigt wie normale Benutzer.
Wenn Sie einen Dienstprinzipal verwenden möchten, stellen Sie sicher, dass Sie die Identitätsinformationen für die Anwendung in der Verbindungszeichenfolge wie folgt angeben:
User ID=<app:appid@tenantid>Password=<application secret>
Beispiel:
Data Source=powerbi://api.powerbi.com/v1.0/myorg/Contoso;Initial Catalog=PowerBI_Dataset;User ID=app:91ab91bb-6b32-4f6d-8bbc-97a0f9f8906b@19373176-316e-4dc7-834c-328902628ad4;Password=6drX...;
Möglicherweise wird eine Fehlermeldung wie diese angezeigt:
„Wir können keine Verbindung zum Semantikmodell herstellen, da die Kontoinformationen unvollständig sind. Stellen Sie bei Dienstprinzipalen sicher, dass Sie die Mandanten-ID zusammen mit der App-ID im folgenden Format angeben: app:<appId>@<tenantId>. Versuchen Sie es dann noch mal.“
Geben Sie die Mandanten-ID zusammen mit der App-ID im richtigen Format an.
Es ist auch möglich, die App-ID ohne die Mandanten-ID anzugeben. In diesem Fall müssen Sie allerdings den Alias myorg in der Datenquellen-URL durch die tatsächliche Mandanten-ID ersetzen. Dann kann Power BI den Dienstprinzipal im richtigen Mandanten ermitteln. Es empfiehlt sich jedoch, den Alias myorg zu verwenden und die Mandanten-ID zusammen mit der App-ID im User ID-Parameter anzugeben.
Herstellen einer Verbindung mit Microsoft Entra B2B
Mit dem Support für Microsoft Entra Business-to-Business (B2B) in Power BI können Sie externen Gastbenutzern über den XMLA-Endpunkt Zugriff auf Semantikmodelle gewähren. Stellen Sie sicher, dass die Einstellung Inhalte für externe Benutzer freigeben im Power BI-Verwaltungsportal aktiviert ist. Weitere Informationen finden Sie unter Verteilen von Power BI-Inhalten an externe Gastbenutzer mit Microsoft Entra B2B.
Bereitstellen eines Semantikmodells
Sie können ein tabellarisches Modellprojekt in Visual Studio (SSDT) in einem Arbeitsbereich bereitstellen, der einer Premium-Kapazität zugewiesen ist, ähnlich wie bei einer Server-Ressource in Azure Analysis Services. Bei der Bereitstellung sind jedoch einige zusätzliche Aspekte zu beachten. Lesen Sie den Abschnitt Bereitstellen von Modellprojekten aus Visual Studio (SSDT) im Artikel „Semantikmodellkonnektivität mithilfe des XMLA-Endpunkts“.
Bereitstellen eines neuen Modells
In der Standardkonfiguration versucht Visual Studio, das Modell als Teil des Bereitstellungsvorgangs zu verarbeiten, um Daten aus den Datenquellen in das Semantikmodell zu laden. Wie unter Bereitstellen von Modellprojekten aus Visual Studio (SSDT) beschrieben, kann hierbei ein Fehler auftreten, weil die Anmeldeinformationen der Datenquelle nicht als Teil eines Bereitstellungsvorgangs angegeben werden können. Wenn die Anmeldeinformationen für Ihre Datenquelle nicht bereits für eines Ihrer bestehenden Semantikmodelle definiert sind, müssen Sie stattdessen die Anmeldeinformationen für die Datenquelle in den Einstellungen des Semantikmodells über die Power BI-Benutzeroberfläche angeben (Semantikmodelle>Einstellungen>Datenquelle Anmeldeinformationen>Anmeldeinformationen bearbeiten). Sobald die Anmeldeinformationen für die Datenquelle definiert wurden, kann Power BI diese Informationen für jedes neue Semantikmodell automatisch auf diese Datenquelle anwenden, nachdem die Metadaten erfolgreich bereitgestellt wurden und das Dataset erstellt wurde.
Wenn Power BI Ihr neues Semantikmodell nicht an Anmeldeinformationen für die Datenquelle binden kann, erhalten Sie folgende Fehlermeldung: „Die Datenbank kann nicht verarbeitet werden. Ursache: Fehler beim Speichern von Änderungen auf dem Server.“ mit dem Fehlercode „DMTS_DatasourceHasNoCredentialError“, wie im Folgenden dargestellt:
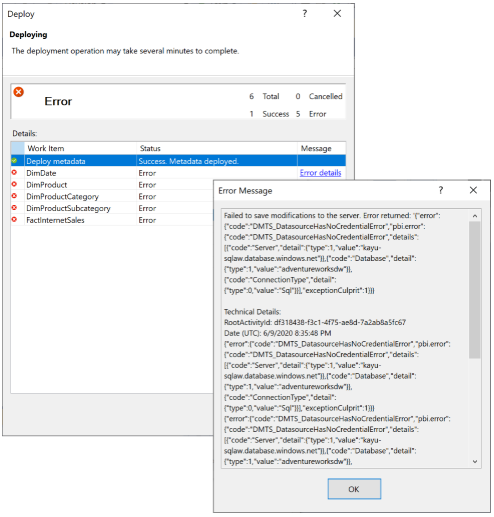
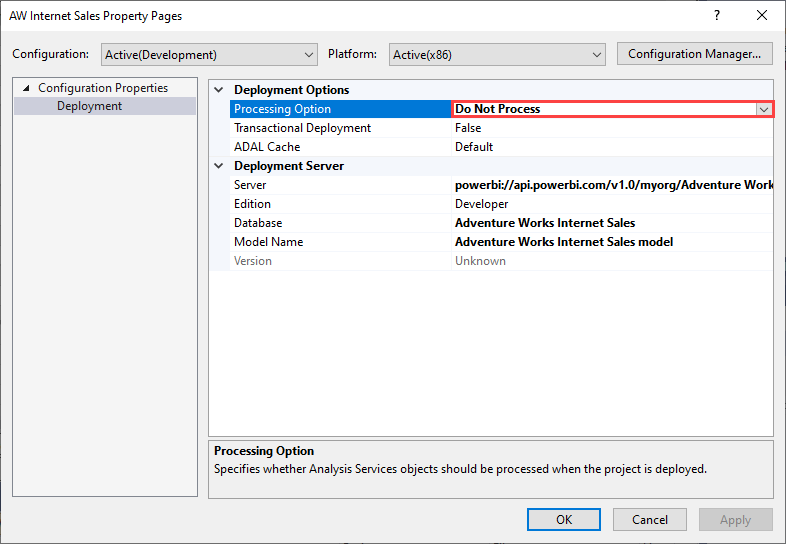
Um diesen Verarbeitungsfehler zu vermeiden, legen Sie Bereitstellungsoptionen>Verarbeitungsoptionen auf Nicht verarbeiten fest, wie in der folgenden Abbildung gezeigt. In diesem Fall stellt Visual Studio nur Metadaten bereit. Sie können dann die Anmeldeinformationen für die Datenquelle bereitstellen und auf der Power BI-Benutzeroberfläche für das Semantikmodell auf Jetzt aktualisieren klicken.
Neues Projekt aus einem vorhandenen Semantikmodell
Das Erstellen eines neuen tabellarischen Projekts in Visual Studio durch Importieren der Metadaten aus einem vorhandenen Semantikmodell wird nicht unterstützt. Sie können jedoch über SQL Server Management Studio eine Verbindung mit einem Semantikmodell herstellen, die Metadaten in ein Skript einfügen und so in anderen tabellarischen Projekten wiederverwenden.
Migrieren eines Semantikmodells zu Power BI
Es wird empfohlen, für tabellarische Modelle den Kompatibilitätsgrad 1500 (oder höher) festzulegen. Dieser Kompatibilitätsgrad unterstützt die meisten Funktionen und Datenquellentypen. Höhere Kompatibilitätsgrade sind immer mit früheren Graden abwärtskompatibel.
Unterstützte Datenanbieter
Mit dem Kompatibilitätsgrad 1500 unterstützt Power BI die folgenden Datenquellentypen:
- Anbieter von Datenquellen (veraltete Verwendung mit einer Verbindungszeichenfolge in den Modellmetadaten)
- Strukturierte Datenquellen (eingeführt mit dem Kompatibilitätsgrad 1400)
- Inline-M-Deklarationen von Datenquellen (gemäß Deklaration von Power BI Desktop)
Es empfiehlt sich strukturierte Datenquellen zu verwenden, die Visual Studio beim Durchlaufen des Importdataflows standardmäßig erstellt. Wenn Sie jedoch planen, ein vorhandenes Modell zu Power BI zu migrieren, das eine Anbieterdatenquelle verwendet, stellen Sie sicher, dass diese Datenquelle von einem unterstützten Datenanbieter stammt. Hier sind insbesondere der Microsoft OLE DB-Treiber für SQL Server sowie alle ODBC-Treiber von Drittanbietern zu nennen. Beim OLE DB-Treiber für SQL Server müssen Sie die Datenquellendefinition in den .NET Framework-Datenanbieter für SQL Server ändern. Bei ODBC-Treibern von Drittanbietern, die im Power BI-Dienst möglicherweise nicht verfügbar sind, müssen Sie stattdessen die Definition einer strukturierten Datenquelle verwenden.
Es wird auch empfohlen, den veralteten Microsoft OLE DB-Treiber für SQL Server (SQLNCLI11) in Ihren SQL Server-Datenquellendefinitionen durch den .NET Framework-Datenanbieter für SQL Server zu ersetzen.
Die folgende Tabelle zeigt das Beispiel einer Verbindungszeichenfolge für einen .NET Framework-Datenanbieter für SQL Server, die eine entsprechende Verbindungszeichenfolge für den OLE DB-Treiber für SQL Server ersetzt.
| OLE DB-Treiber für SQL Server | .NET Framework-Datenanbieter für SQL Server |
|---|---|
Provider=SQLNCLI11;Data Source=sqldb.database.windows.net;Initial Catalog=AdventureWorksDW;Trusted_Connection=yes; |
Data Source=sqldb.database.windows.net;Initial Catalog=AdventureWorksDW2016;Integrated Security=SSPI;Encrypt=true;TrustServerCertificate=false |
Querverweise auf Partitionsquellen
Genauso, wie es mehrere Datenquellentypen gibt, gibt es auch mehrere Partitionsquellentypen, die in einem tabellarischen Modell zum Importieren von Daten in eine Tabelle enthalten sein können. Eine Partition kann eine Abfragepartitionsquelle oder eine M-Partitionsquelle verwenden. Diese Partitionsquellentypen können wiederum auf Anbieterdatenquellen oder strukturierte Datenquellen verweisen. Tabellarische Modelle in Azure Analysis Services unterstützen Querverweise zwischen diesen verschiedenen Datenquellen- und Partitionstypen; Power BI dagegen erzwingt eine strengere Beziehung. Abfragepartitionsquellen müssen auf Anbieterdatenquellen verweisen, und M-Partitionsquellen müssen auf strukturierte Datenquellen verweisen. Andere Kombinationen werden in Power BI nicht unterstützt. Wenn Sie ein Semantikmodell mit Querverweisen migrieren möchten, erhalten Sie in der folgenden Tabelle Informationen zu den unterstützten Konfigurationen:
| Datenquellen- | Partitionsquelle | Kommentare | Unterstützt mit XMLA-Endpunkt |
|---|---|---|---|
| Anbieterdatenquelle | Abfragepartitionsquelle | Die AS-Engine verwendet den cartridgebasierten Konnektivitätsstapel für den Zugriff auf die Datenquelle. | Ja |
| Anbieterdatenquelle | M-Partitionsquelle | Die AS-Engine übersetzt die Anbieterdatenquelle in eine generische strukturierte Datenquelle und verwendet dann die Mashup-Engine zum Importieren der Daten. | Nein |
| Strukturierte Datenquelle | Abfragepartitionsquelle | Die AS-Engine umschließt die native Abfrage in der Partitionsquelle mit einem M-Ausdruck und verwendet dann die Mashup-Engine zum Importieren der Daten. | Nein |
| Strukturierte Datenquelle | M-Partitionsquelle | Die AS-Engine verwendet die Mashup-Engine zum Importieren der Daten. | Ja |
Datenquellen und Identitätswechsel
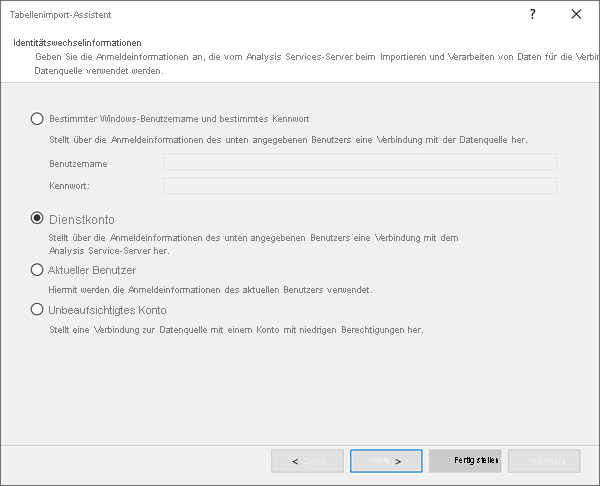
Einstellungen für Identitätswechsel, die Sie für Anbieterdatenquellen definieren können, sind für Power BI nicht relevant. Power BI verwendet einen anderen Mechanismus, der auf semantischen Modelleinstellungen basiert, um die Anmeldeinformationen für Datenquellen zu verwalten. Stellen Sie daher sicher, dass Sie Dienstkonto auswählen, wenn Sie eine Anbieterdatenquelle erstellen.
Differenzierte Verarbeitung
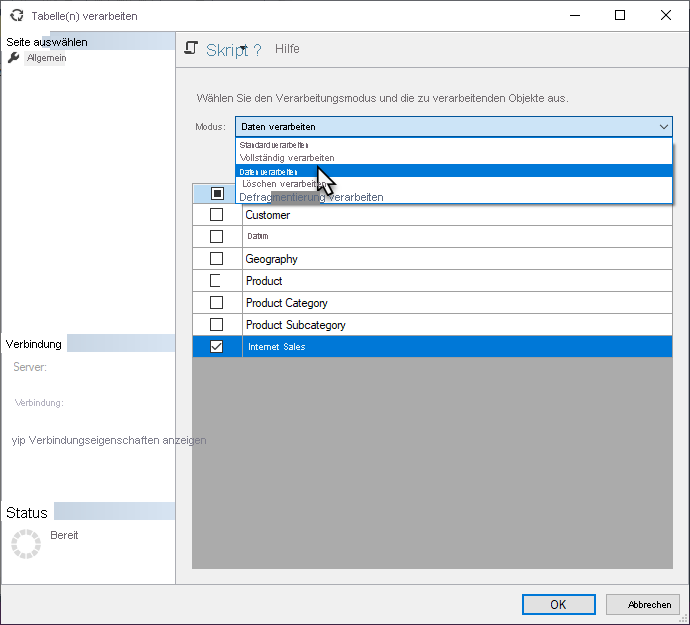
Wenn Sie eine geplante oder bedarfsgesteuerte Aktualisierung in Power BI auslösen, aktualisiert Power BI normalerweise das gesamte Semantikmodell. In vielen Fällen ist es effizienter, Aktualisierungen selektiver auszuführen. Sie können differenzierte Verarbeitungsaufgaben in SQL Server Management Studio (SSMS) ausführen, wie unten gezeigt, oder Tools oder Skripts von Drittanbietern dafür verwenden.
Außerkraftsetzungen im TMSL-Befehl „refresh“
Außerkraftsetzungen im „refresh“-Befehl (TMSL) ermöglichen Benutzern das Auswählen einer anderen Partitionsabfrage- oder Datenquellendefinition für den Aktualisierungsvorgang.
E-Mail-Abonnements
Semantikmodelle, die mithilfe eines XMLA-Endpunkts aktualisiert werden, lösen kein E-Mail-Abonnement aus.
Fehler bei Premium-Kapazität
SSMS-Fehler beim Verbinden mit dem Server
Wenn Sie sich über SQL Server Management Studio (SSMS) mit einem Power BI-Arbeitsbereich verbinden, wird möglicherweise der folgende Fehler angezeigt:
TITLE: Connect to Server
------------------------------
Cannot connect to powerbi://api.powerbi.com/v1.0/[tenant name]/[workspace name].
------------------------------
ADDITIONAL INFORMATION:
The remote server returned an error: (400) Bad Request.
Technical Details:
RootActivityId:
Date (UTC): 10/6/2021 1:03:25 AM (Microsoft.AnalysisServices.AdomdClient)
------------------------------
The remote server returned an error: (400) Bad Request. (System)
Wenn Sie sich über SSMS mit einem Power BI-Arbeitsbereich verbinden, stellen Sie Folgendes sicher:
- Die XMLA-Endpunkteinstellung ist für die Kapazität Ihres Mandanten aktiviert. Weitere Informationen finden Sie unter Aktivieren von XMLA-Lese-/Schreibzugriff.
- Die Einstellung XMLA-Endpunkte und Analysieren in Excel mit lokalen Semantikmodellen zulassen ist in den Mandanteneinstellungen aktiviert.
- Sie verwenden die neueste Version von SSMS. Laden Sie die neueste Version herunter.
Abfrageausführung in SSMS
Wenn eine Verbindung mit einem Arbeitsbereich in einer Power BI Premium- oder einer Power BI Embedded-Kapazität besteht, zeigt SQL Server Management Studio möglicherweise den folgenden Fehler an:
Executing the query ...
Error -1052311437: We had to move the session with ID '<Session ID>' to another Power BI Premium node. Moving the session temporarily interrupted this trace - tracing will resume automatically as soon as the session has been fully moved to the new node.
Dies ist eine Informationsmeldung, die in SSMS 18.8 und höheren Versionen ignoriert werden kann, da die Verbindung mit den Clientbibliotheken automatisch wiederhergestellt wird. Beachten Sie, dass Clientbibliotheken, die mit SSMS v18.7.1 oder früheren Versionen installiert wurden, keine Ablaufverfolgung für Supportsitzungen unterstützen. Laden Sie die neueste Version von SSMS herunter.
Ausführen eines umfangreichen Befehls mit dem XMLA-Endpunkt
Wenn Sie einen umfangreichen Befehl mit dem XMLA-Endpunkts ausführen, tritt möglicherweise der folgende Fehler auf:
Executing the query ...
Error -1052311437:
The remote server returned an error: (400) Bad Request.
Technical Details:
RootActivityId: 3716c0f7-3d01-4595-8061-e6b2bd9f3428
Date (UTC): 11/13/2020 7:57:16 PM
Run complete
Wenn Sie SSMS v18.7.1 oder niedriger zum Ausführen eines zeitintensiven Aktualisierungsvorgangs (>1 Minute) für ein Semantikmodell in einer Power BI Premium- oder einer Power BI Embedded-Kapazität verwenden, zeigt SSMS möglicherweise selbst dann diesen Fehler an, wenn der Aktualisierungsvorgang erfolgreich ausgeführt wurde. Dies ist auf ein bekanntes Problem in den Clientbibliotheken zurückzuführen, bei denen der Status der Aktualisierungsanforderung nicht korrekt nachverfolgt wird. Dies wird in SSMS 18.8 und höher gelöst. Laden Sie die neueste Version von SSMS herunter.
Dieser Fehler kann auch auftreten, wenn eine sehr umfangreiche Anforderung an einen anderen Knoten im Premium-Cluster umgeleitet werden muss. Dies kommt häufig vor, wenn Sie versuchen, ein Semantikmodell mit einem umfangreichen TMSL-Skript zu erstellen oder zu ändern. In solchen Fällen kann der Fehler in der Regel vermieden werden, indem der Anfangskatalog für den Namen der Datenbank angegeben wird, bevor der Befehl ausgeführt wird.
Beim Erstellen einer neuen Datenbank können Sie ein leeres Semantikmodell erstellen, z. B.:
{
"create": {
"database": {
"name": "DatabaseName"
}
}
}
Nachdem Sie das neue Semantikmodell erstellt haben, geben Sie den Anfänglichen Katalog an, und nehmen Sie dann Änderungen am Semantikmodell vor.
Andere Clientanwendungen und -tools
Clientanwendungen und -tools wie Excel, Power BI Desktop, SSMS oder externe Tools, die eine Verbindung mit Semantikmodellen in Power BI Premium-Kapazitäten herstellen und damit arbeiten, können den folgenden Fehler verursachen: Der Remoteserver hat einen Fehler zurückgegeben: (400) Ungültige Anforderung. Der Fehler kann insbesondere dann verursacht werden, wenn eine zugrunde liegende DAX-Abfrage oder ein XMLA-Befehl lang ausgeführt wird. Um potenzielle Fehler zu minimieren, stellen Sie sicher, dass Sie die neuesten Anwendungen und Tools verwenden, die die aktuellen Versionen der Analysis Services-Clientbibliotheken mit regelmäßigen Updates installieren. Dies sind die unabhängig von der Anwendung oder dem Tool mindestens erforderlichen Clientbibliotheksversionen, um über den XMLA-Endpunkt eine Verbindung mit Semantikmodellen in einer Premium-Kapazität herzustellen und mit diesen zu arbeiten:
| Clientbibliothek | Version |
|---|---|
| MSOLAP | 15.1.65.22 |
| AMO | 19.12.7.0 |
| ADOMD | 19.12.7.0 |
Bearbeiten von Rollenmitgliedschaften in SSMS
Wenn Sie in SQL Server Management Studio v18.8 (SSMS) eine Rollenmitgliedschaft in einem Semantikmodell bearbeiten, wird in SSMS möglicherweise die folgende Fehlermeldung angezeigt:
Failed to save modifications to the server.
Error returned: ‘Metadata change of current operation cannot be resolved, please check the command or try again later.’
Dies ist auf ein bekanntes Problem in der App-Dienste-REST-API zurückzuführen. Dieses Problem wird in einem zukünftigen Release behoben. In der Zwischenzeit können Sie zur Fehlerumgehung unter Role Properties (Rolleneigenschaften) auf Skript klicken und dann den folgenden TMSL-Befehl eingeben:
{
"createOrReplace": {
"object": {
"database": "AdventureWorks",
"role": "Role"
},
"role": {
"name": "Role",
"modelPermission": "read",
"members": [
{
"memberName": "xxxx",
"identityProvider": "AzureAD"
},
{
"memberName": “xxxx”
"identityProvider": "AzureAD"
}
]
}
}
}
Veröffentlichungsfehler – Live verbundenes Semantikmodell
Beim erneuten Veröffentlichen eines live verbundenen Semantikmodells, das den Analysis Services-Connector verwendet, lautet der folgende Fehler: „Es gibt ein vorhandenes Berichts-/Semantikmodell mit demselben Namen. Löschen oder benennen Sie das vorhandene Semantikmodell um, und versuchen Sie es erneut.“ kann angezeigt werden.

Das liegt daran, dass das zu veröffentlichende Semantikmodell eine andere Verbindungszeichenfolge, aber denselben Namen wie das bestehende Semantikmodell aufweist. Um dieses Problem zu beheben, löschen Sie das vorhandene Semantikmodell oder benennen es um. Sie müssen außerdem sicherstellen, dass Sie alle Apps neu veröffentlichen, die vom Bericht abhängen. Bei Bedarf sollten Benutzer angewiesen werden, alle Lesezeichen mit der neuen Berichtsadresse zu aktualisieren, um sicherzustellen, dass sie auf den aktuellen Bericht zugreifen.
Arbeitsbereich/Serveralias
Im Gegensatz zu Azure Analysis Services werden Aliasse von Servernamen für Premium-Arbeitsbereiche nicht unterstützt.
DISCOVER_M_EXPRESSIONS
Die Datenverwaltungsansicht (DMV, Data Management View) DMV DISCOVER_M_EXPRESSIONS wird derzeit nicht in Power BI mit dem XMLA-Endpunkt unterstützt. Anwendungen können das Tabellenobjektmodell (TOM) zum Abrufen von M-Ausdrücken verwenden, die vom Datenmodell verwendet werden.
Arbeitsspeichergrenzwert für Ressourcenverwaltungsbefehle in Premium
Premium-Kapazitäten verwenden Ressourcenverwaltung, um sicherzustellen, dass kein einzelner Semantikmodellvorgang die Menge der verfügbaren Arbeitsspeicherressourcen für die durch die SKU bestimmte Kapazität überschreiten kann. Beispielsweise gilt für ein P1-Abonnement ein effektiver Arbeitsspeichergrenzwert von 25 GB pro Element, für ein P2-Abonnement ist der Grenzwert 50 GB und für ein P3-Abonnement 100 GB. Zusätzlich zur Größe des Semantikmodells (der Datenbank) gilt der effektive Speichergrenzwert auch für zugrunde liegende Semantikmodellbefehlsvorgänge wie Erstellen, Ändern und Aktualisieren.
Der effektive Arbeitsspeichergrenzwert für einen Befehl basiert auf dem kleineren Arbeitsspeichergrenzwert der Kapazität (durch SKU bestimmt) oder dem Wert der XMLA-Eigenschaft DbpropMsmdRequestMemoryLimit.
Für eine P1-Kapazität gilt beispielsweise in diesen Fällen:
DbpropMsmdRequestMemoryLimit = 0 (oder nicht angegeben), der effektive Arbeitsspeichergrenzwert für den Befehl beträgt 25 GB.
DbpropMsmdRequestMemoryLimit = 5 GB, der effektive Arbeitsspeichergrenzwert für den Befehl beträgt 5 GB.
DbpropMsmdRequestMemoryLimit = 50 GB, der effektive Arbeitsspeichergrenzwert für den Befehl ist 25 GB.
In der Regel wird der effektive Arbeitsspeichergrenzwert für einen Befehl aufgrund des für das Semantikmodell zulässigen Arbeitsspeichers anhand der Kapazität (25 GB, 50 GB, 100 GB) und der Menge an Arbeitsspeicher berechnet, die das Semantikmodell bereits verbraucht, wenn die Befehlsausführung beginnt. Beispielsweise ermöglicht ein Semantikmodell, das 12 GB für eine P1-Kapazität verwendet, für einen neuen Befehl einen effektiven Arbeitsspeichergrenzwert von 13 GB. Der effektive Arbeitsspeichergrenzwert kann jedoch durch die XMLA-Eigenschaft DbPropMsmdRequestMemoryLimit weiter eingeschränkt werden, wenn dies optional von einer Anwendung angegeben wird. Wenn im vorherigen Beispiel 10 GB in der DbPropMsmdRequestMemoryLimit-Eigenschaft angegeben sind, wird der effektive Grenzwert des Befehls weiter auf 10 GB reduziert.
Wenn der Befehlsvorgang versucht, mehr Arbeitsspeicher zu verbrauchen, als der Grenzwert zulässt, kann der Vorgang fehlschlagen, und es wird ein Fehler zurückgegeben. Der folgende Fehler beschreibt beispielsweise, dass ein effektiver Arbeitsspeichergrenzwert von 25 GB (P1-Kapazität) überschritten wurde, da das Semantikmodell bereits 12 GB (12288 MB) verbraucht hat, als die Ausführung des Befehls begann, und ein effektiver Grenzwert von 13 GB (13312 MB) für den Befehlsvorgang angewendet wurde:
„Dieser Vorgang wurde abgebrochen, weil nicht genügend Arbeitsspeicher vorhanden war, um ihn zu Ende zu führen. Erhöhen Sie entweder den Arbeitsspeicher der Premium-Kapazität, auf der dieses Semantikmodell gehostet wird, oder reduzieren Sie den Speicherbedarf Ihres Semantikmodells, indem Sie z. B. die Menge der importierten Daten begrenzen. Weitere Details: verbrauchter Arbeitsspeicher 13312 MB, Arbeitsspeicherlimit 13312 MB, Datenbankgröße vor Befehlsausführung 12288 MB. Weitere Informationen finden Sie unter https://go.microsoft.com/fwlink/?linkid=2159753.“
In einigen Fällen, wie im folgenden Fehler gezeigt, ist „verbrauchter Arbeitsspeicher“ 0, aber die für „Datenbankgröße vor der Befehlsausführung“ angezeigte Menge ist bereits größer als der effektive Arbeitsspeichergrenzwert. Dies bedeutet, dass der Vorgang nicht mit der Ausführung beginnen konnte, da bereits die vom Semantikmodell verwendete Arbeitsspeichermenge die Arbeitsspeichergrenze für die SKU überschreitet.
„Dieser Vorgang wurde abgebrochen, weil nicht genügend Arbeitsspeicher vorhanden war, um ihn zu Ende zu führen. Erhöhen Sie entweder den Arbeitsspeicher der Premium-Kapazität, auf der dieses Semantikmodell gehostet wird, oder reduzieren Sie den Speicherbedarf Ihres Semantikmodells, indem Sie z. B. die Menge der importierten Daten begrenzen. Weitere Details: verbrauchter Arbeitsspeicher 0 MB, Arbeitsspeicherlimit 25.600 MB, Datenbankgröße vor Befehlsausführung 26.000 MB. Weitere Informationen finden Sie unter https://go.microsoft.com/fwlink/?linkid=2159753.“
So vermeiden Sie potenziell die Überschreitung des effektiven Arbeitsspeichergrenzwerts:
- Führen Sie für das Semantikmodell ein Upgrade auf eine größere Premium-Kapazität (SKU) durch.
- Reduzieren Sie den Speicherbedarf Ihres Semantikmodells, indem Sie die Menge der Daten begrenzen, die bei jeder Aktualisierung geladen werden.
- Reduzieren Sie bei Aktualisierungsvorgängen über den XMLA-Endpunkt die Anzahl der Partitionen, die parallel verarbeitet werden. Zu viele Partitionen, die parallel mit einem einzelnen Befehl verarbeitet werden, können den effektiven Arbeitsspeichergrenzwert überschreiten.