Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel finden Sie eine technische Erläuterung zu Power BI-Semantikmodellmodi. Er gilt für Semantikmodelle, die eine Liveverbindung mit einem extern gehosteten Analysis Services-Modell darstellen, sowie Modelle, die in Power BI Desktop entwickelt werden. Der Artikel legt den Schwerpunkt auf das Grundprinzip der einzelnen Modi und mögliche Einflüsse auf die Kapazitätsressourcen von Power BI.
Die drei Semantikmodellmodi sind:
Import-Modus
Der Modus Import ist der bei der Entwicklung von Semantikmodellen am häufigsten verwendete Modus. Dieser Modus bietet dank der Ausführung der Abfragen im Arbeitsspeicher eine hohe Leistung. Er bietet Modellentwicklern darüber hinaus Flexibilität und Unterstützung für bestimmte Power BI-Dienstfunktionen (Q&A, Quick Insights usw.). Aufgrund dieser Vorzüge ist er der Standardmodus beim Erstellen einer neuen Power BI Desktop-Projektmappe.
Es ist wichtig, zu verstehen, dass importierte Daten immer auf dem Datenträger gespeichert werden. Beim Abfragen oder Aktualisieren müssen die Daten vollständig in den Arbeitsspeicher der Power BI-Kapazität geladen werden. Sobald sie sich im Arbeitsspeicher befinden, können Import-Modelle sehr schnell Abfrageergebnisse erzielen. Es ist ebenfalls wichtig, zu verstehen, dass es kein Konzept des teilweisen Ladens eines Import-Modells in den Arbeitsspeicher gibt.
Beim Aktualisieren werden die Daten zuerst komprimiert und optimiert und anschließend von der VertiPaq-Speicher-Engine auf dem Datenträger gespeichert. Beim Laden vom Datenträger in den Arbeitsspeicher lässt sich eine bis zu zehnfache Komprimierung erzielen. Es kann also sinnvoll davon ausgegangen werden, dass 10 GB Quelldaten zu einem 1 GB komprimiert werden können. Die Speichergröße auf dem Datenträger kann eine Reduzierung von 20 % von der komprimierten Größe erreichen. (Der Größenunterschied kann durch Vergleich der Dateigröße in Power BI Desktop mit der Arbeitsspeicherbelegung der Datei im Task-Manager ermittelt werden.)
Flexibilität im Entwurf kann auf drei verschiedenen Wegen erreicht werden.
- Integrieren von Daten durch Zwischenspeichern von Dataflows und externen Datenquellen, unabhängig von Typ oder Format der Datenquelle
- Verwenden Sie bei der Erstellung von Datenvorbereitungsabfragen den gesamten Satz der Power Query M-Formelsprache, genannt M, Funktionen.
- Nutzen der gesamten Menge der DAX-Funktionen (Data Analysis Expressions) beim Anreichern des Modells mit Geschäftslogik. Es besteht Unterstützung für berechnete Spalten, berechnete Tabellen und Measures.
Wie in der folgenden Abbildung dargestellt, kann ein Importmodell Daten aus einer beliebigen Anzahl unterstützter Datenquellentypen integrieren.
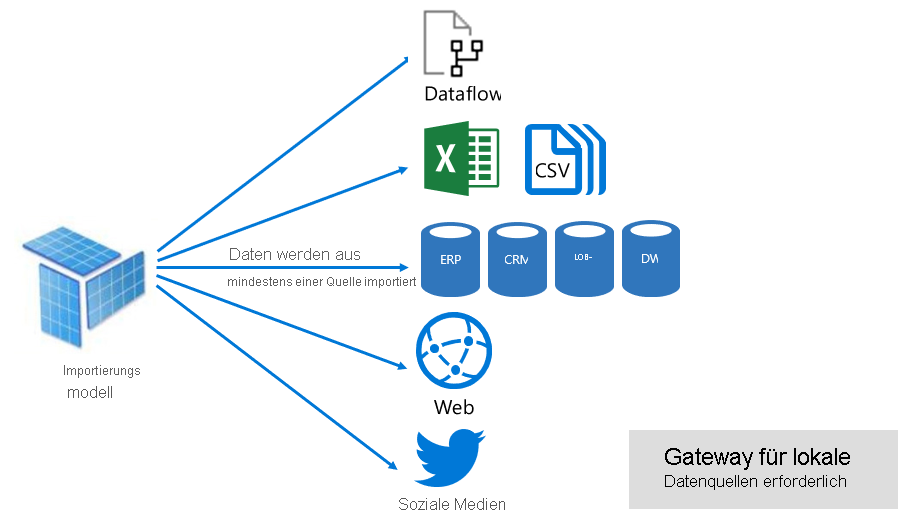
Während Importmodelle einerseits überzeugende Vorzüge zu bieten haben, gibt es auch Nachteile:
- Das gesamte Modell muss in den Arbeitsspeicher geladen werden, damit Power BI Abfragen für das Modell ausführen kann, was die verfügbaren Kapazitätsressourcen unter Druck setzen kann, insbesondere bei steigender Anzahl und Größe der Importmodelle
- Modelldaten sind stets nur so aktuell wie die letzte Aktualisierung, daher müssen Importmodelle aktualisiert werden, normalerweise mithilfe eines Zeitplans
- Eine vollständige Aktualisierung entfernt alle Daten aus allen Tabellen und lädt sie neu aus der Datenquelle. Dieser Vorgang kann im Hinblick auf Zeit und Ressourcen aufwändig für den Power BI-Dienst und die Datenquelle(n) sein.
Hinweis
Power BI kann eine inkrementelle Aktualisierung ausführen, um das Abschneiden und erneute Laden gesamter Tabellen zu vermeiden. Weitere Informationen, einschließlich unterstützter Pläne und Lizenzierung, finden Sie unter Inkrementelle Aktualisierung und Echtzeitdaten für Semantikmodelle.
Aus der Perspektive einer Power BI-Dienstressource ist für Importmodelle Folgendes erforderlich:
- Ausreichender Arbeitsspeicher, um das Modell zum Abfragen oder Aktualisieren zu laden
- Verarbeitungsressourcen und zusätzliche Arbeitsspeicherressourcen zum Aktualisieren der Daten
DirectQuery-Modus
Der DirectQuery-Modus stellt eine Alternative zum Importmodus dar. Im DirectQuery-Modus entwickelte Modelle importieren keine Daten. Stattdessen bestehen sie nur aus Metadaten, die die Modellstruktur definieren. Wenn eine Abfrage für das Modell ausgeführt wird, werden native Abfragen verwendet, um Daten aus der zugrunde liegenden Datenquelle abzurufen.
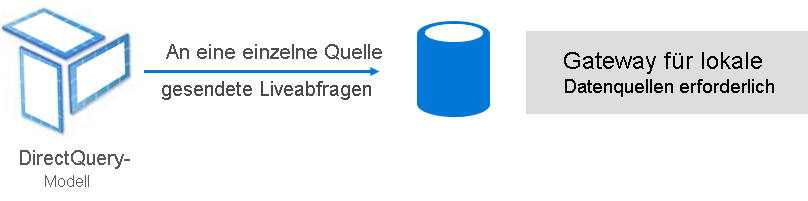
Es gibt zwei Hauptgründe, warum man sich für die Entwicklung eines DirectQuery-Modells entscheiden kann:
- Wenn die Datenvolumen zu groß sind – selbst bei Anwendung von Methoden zur Datenreduktion – um sie in ein Modell zu laden oder auf praktikable Weise zu aktualisieren
- Wenn Berichte und Dashboards Daten nahezu in Echtzeit bereitstellen müssen, jenseits dessen, was im Rahmen von planmäßiger Aktualisierung erreicht werden kann. (Der Grenzwert für planmäßige Aktualisierung liegt bei 8-mal am Tag, 48-mal täglich für Premium-Kapazität.)
DirectQuery-Modelle bringen eine Reihe von Vorteilen mit:
- Die Größenbeschränkungen für Importmodelle spielen keine Rolle.
- Für Modelle ist keine geplante Datenaktualisierung erforderlich.
- Benutzer von Berichten greifen bei der Interaktion mit Berichtsfiltern und Slicern auf die aktuellen Daten zu. Außerdem können Benutzer einen gesamten Bericht aktualisieren, um aktuelle Daten abzurufen.
- Echtzeitberichte können mithilfe der Funktion Automatische Seitenaktualisierung entwickelt werden.
- Dashboardkacheln, die auf DirectQuery-Modellen basieren, können automatisch bis zu alle 15 Minuten aktualisiert werden.
Allerdings gehen mit DirectQuery-Modellen auch einige Einschränkungen einher:
- Power Query-/Mashup-Ausdrücke sind auf die Verwendung von Funktionen beschränkt, die in native, für die Datenquelle verständliche Abfragen umgewandelt werden können.
- DAX-Formeln sind auf die Verwendung von M-Ausdrücken und -Funktionen beschränkt, die in native Abfragen umgewandelt werden können, die von der Datenquelle verstanden werden. Berechnete Tabellen werden nicht unterstützt.
- Quick Insights-Features werden nicht unterstützt.
Aus der Perspektive einer Power BI-Dienstressource ist für DirectQuery-Modelle Folgendes erforderlich:
- Minimaler Arbeitsspeicher zum Laden des Modells (nur Metadaten) bei der Abfrage
- Manchmal muss der Power BI-Dienst erhebliche Prozessorressourcen verwenden, um die an die Datenquelle gesendeten Abfragen zu generieren und zu verarbeiten. Wenn diese Situation eintritt, kann sie den Durchsatz beeinträchtigen, insbesondere, wenn das Modell gleichzeitig von mehreren Benutzern abgefragt wird.
Weitere Informationen finden Sie unter Verwenden von DirectQuery in Power BI Desktop.
Zusammengesetzter Modus
Im Zusammengesetzten Modus können Import- und DirectQuery-Modi gemischt oder mehrere DirectQuery-Datenquellen integriert werden. Im zusammengesetzten Modus entwickelte Modelle unterstützen die Konfiguration des Speichermodus für jede Modelltabelle. Dieses Modell unterstützt außerdem berechnete Tabellen (die mit DAX definiert wurden).
Der Tabellenspeichermodus kann als „Import“, „DirectQuery“ oder „Dual“ konfiguriert werden. Eine für den Speichermodus „Dual“ konfigurierte Tabelle weist beide Speichermodi „Import“ und „DirectQuery“ auf, und diese Einstellung ermöglicht es dem Power BI-Dienst, von Abfrage zu Abfrage den effizientesten Modus zu bestimmen.
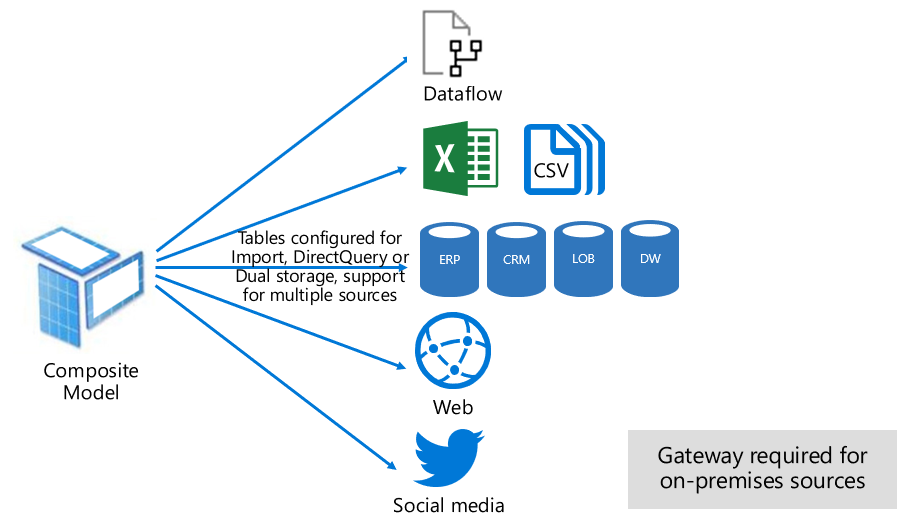
Hinter zusammengesetzten Modellen steht die Bestrebung, das Beste aus Import--und DirectQuery-Modus zu vereinen. Bei entsprechender Konfiguration kann die hohe Abfrageleistung von In-Memory-Modellen mit der Möglichkeit kombiniert werden, Daten nahezu in Echtzeit aus Datenquellen abzurufen.
Weitere Informationen finden Sie unter Verwenden zusammengesetzter Modelle in Power BI Desktop.
Reine Import- und DirectQuery-Tabellen
Datenmodellierer, die zusammengesetzte Modelle entwickeln, werden wahrscheinlich Tabellen vom Dimensionstyp im Import- oder DirectQuery-Modus und Tabellen vom Faktentyp im DirectQuery-Modus konfigurieren. Weitere Informationen zur Rolle von Modelltabellen finden Sie unter Informationen zum Sternschema und der Wichtigkeit für Power BI.
Betrachten Sie beispielsweise ein Modell mit einer Tabelle Produkt vom Dimensionstyp und einer Tabelle Umsatz vom Faktentyp im DirectQuery-Modus. Die Tabelle Produkt kann effizient und schnell aus dem Arbeitsspeicher abgefragt werden, um einen Berichtsdatenschnitt zu rendern. Die Tabelle Umsatz könnte ebenso im DirectQuery-Modus mit der zugeordneten Tabelle Produkt abgefragt werden. Diese zweite Abfrage könnte die Generierung einer einzelnen, effizienten nativen SQL-Abfrage ermöglichen, die die Tabellen Produkt und Umsatz vereint und nach den Datenschnittwerten filtert.
Hybridtabellen
Datenmodellersteller, die zusammengesetzte Modelle entwickeln, können auch Faktentabellen als Hybridtabellen konfigurieren. Eine Hybridtabelle ist eine Tabelle mit mindestens einer Importpartition und einer DirectQuery-Partition. Eine Hybridtabelle hat den Vorteil, dass sie effizient ist und schnell aus dem Arbeitsspeicher abgefragt werden kann. Gleichzeitig enthält sie die neuesten Datenänderungen aus der Datenquelle, die nach dem letzten Importzyklus aufgetreten sind, wie in der folgenden Abbildung zu sehen:
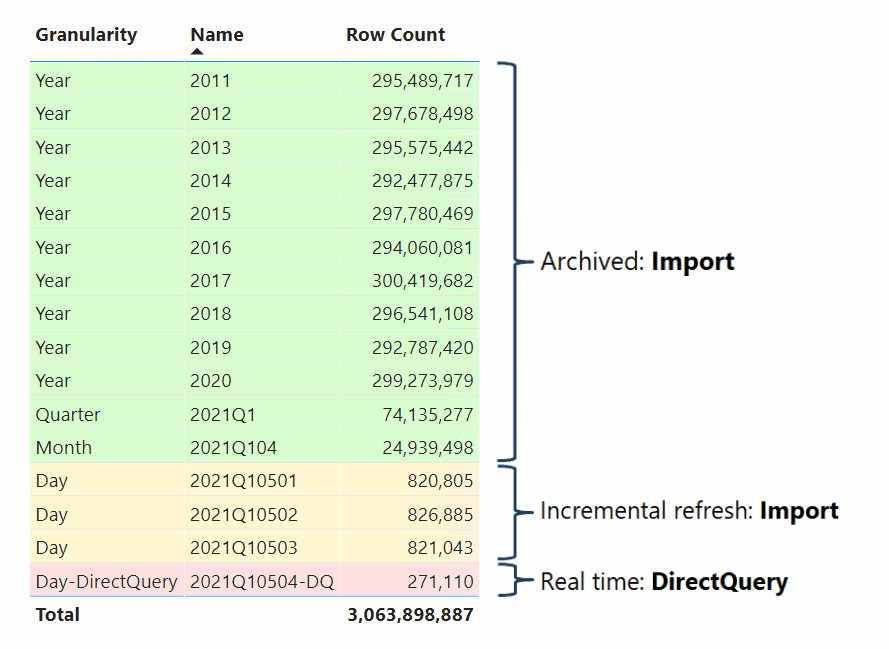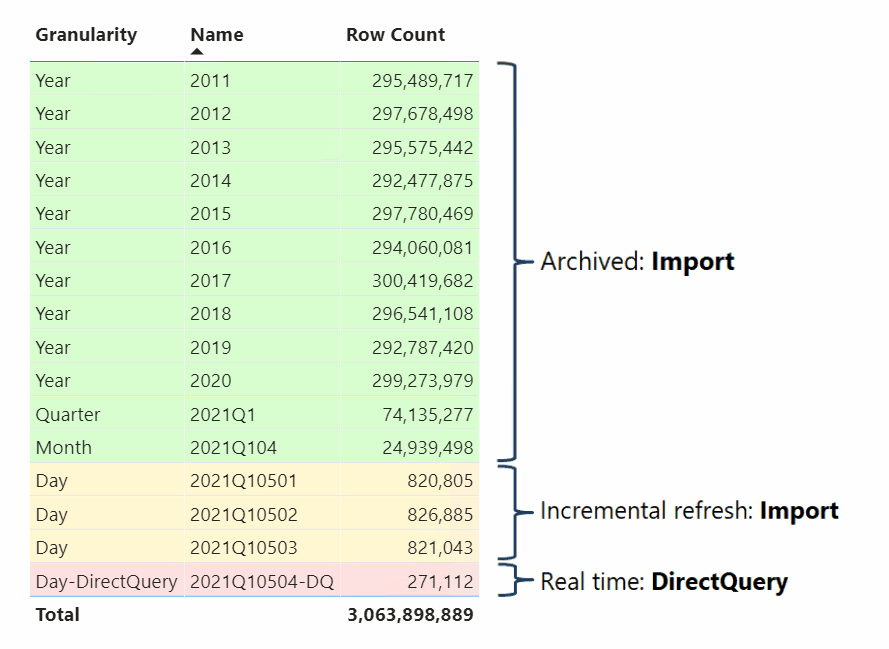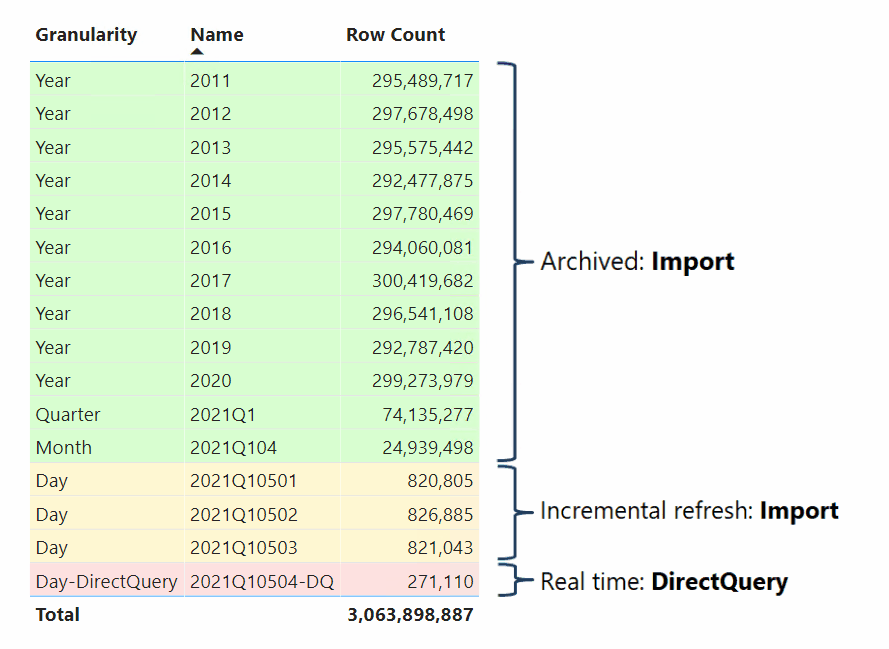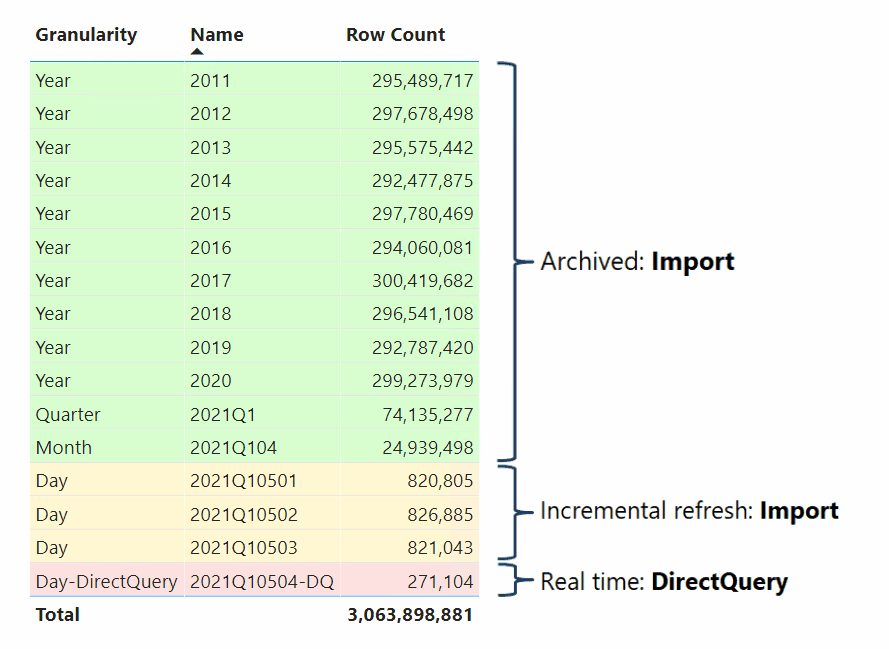
Die einfachste Möglichkeit zum Erstellen einer Hybridtabelle besteht darin, in Power BI Desktop eine Richtlinie für die inkrementelle Aktualisierung zu konfigurieren und die Option Abrufen der neuesten Daten in Echtzeit mit DirectQuery (nur Premium) zu aktivieren. Wenn von Power BI eine Richtlinie für die inkrementelle Aktualisierung angewendet wird, für die diese Option aktiviert ist, wird die Tabelle nach dem obigen Partitionierungsschema partitioniert, wie im vorhrigen Diagramm angezeigt. Konfigurieren Sie Ihre Dimensionstabellen im Speichermodus „Dual“, damit von Power BI beim Abfragen der DirectQuery-Partition effiziente native SQL-Abfragen generiert werden können, um eine gute Leistung zu gewährleisten.
Hinweis
Power BI unterstützt Hybridtabellen nur, wenn das Semantikmodell in Arbeitsbereichen in Premium-Kapazitäten gehostet wird. Daher müssen Sie Ihr Semantikmodell in einen Premium-Arbeitsbereich hochladen, wenn Sie eine Richtlinie für die inkrementelle Aktualisierung mit der Option zum Abrufen der neuesten Daten in Echtzeit mit DirectQuery konfigurieren. Weitere Informationen finden Sie unter Inkrementelle Aktualisierung und Echtzeitdaten für Semantikmodelle.
Sie können auch eine Importtabelle in eine Hybridtabelle konvertieren, indem Sie per Tabular Model Scripting Language (TMSL) oder Tabular Object Model (TOM) oder mithilfe eines Drittanbietertools eine DirectQuery-Partition hinzufügen. Beispielsweise können Sie eine Faktentabelle so partitionieren, dass der Großteil der Daten im Data Warehouse verbleibt und nur ein Bruchteil der neuesten Daten importiert wird. Dieser Ansatz kann zur Leistungsoptimierung beitragen, wenn es sich bei den Daten größtenteils um historische Daten handelt, auf die selten zugegriffen wird. Eine Hybridtabelle kann über mehrere Importpartitionen, aber nur über eine einzelne DirectQuery-Partition verfügen.