Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel richtet sich an IT-Experten und IT-Manager. Sie erfahren mehr über die BI-Lösungsarchitektur im COE und die verschiedenen verwendeten Technologien. Technologien umfassen Azure, Power BI und Excel. Gemeinsam können sie genutzt werden, um eine skalierbare und datengesteuerte Cloud BI-Plattform bereitzustellen.
Das Entwerfen einer robusten BI-Plattform ähnelt dem Erstellen einer Brücke; eine Brücke, die transformierte und angereicherte Quelldaten mit Datenkunden verbindet. Das Design einer solchen komplexen Struktur erfordert eine technische Denkweise, obwohl es eine der kreativsten und lohnendsten IT-Architekturen sein kann, die Sie entwerfen könnten. In einer großen Organisation kann eine BI-Lösungsarchitektur aus Folgendem bestehen:
- Datenquellen
- Datenaufnahme
- Big Data/ Datenvorbereitung
- Datenlager
- BI-Semantikmodelle
- Berichte
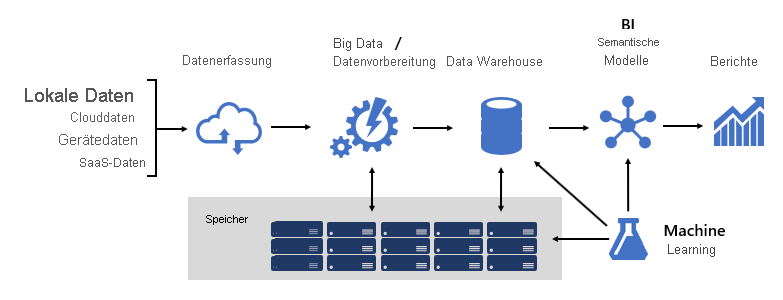
Die Plattform muss spezifische Anforderungen unterstützen. Insbesondere muss sie skaliert und ausgeführt werden, um die Erwartungen von Geschäftsdiensten und Datenkonsumenten zu erfüllen. Gleichzeitig muss es von Grund auf sicher sein. Und es muss ausreichend belastbar sein, um sich an Veränderungen anzupassen – denn es ist eine Gewissheit, dass in der Zeit neue Daten- und Themenbereiche online gebracht werden müssen.
Rahmenwerke
Bei Microsoft haben wir von Anfang an einen systemähnlichen Ansatz eingeführt, indem wir in die Frameworkentwicklung investieren. Technische und Geschäftsprozessframeworks erhöhen die Wiederverwendung von Design und Logik und bieten ein konsistentes Ergebnis. Sie bieten auch Flexibilität bei der Architektur, indem sie viele Technologien nutzen, und sie optimieren und reduzieren den Technischen Aufwand über wiederholbare Prozesse.
Wir haben gelernt, dass gut gestaltete Frameworks die Sichtbarkeit von Datenherkunft, Auswirkungsanalysen, Wartung der Geschäftslogik, Taxonomieverwaltung und die Vereinfachung der Governance erhöhen. Außerdem wurde die Entwicklung schneller und die Zusammenarbeit in großen Teams wurde schneller und effektiver.
In diesem Artikel werden einige unserer Frameworks beschrieben.
Datenmodelle
Mit Datenmodellen können Sie steuern, wie Daten strukturiert und darauf zugegriffen werden. Für Geschäftsdienste und Datenkonsumenten sind Datenmodelle ihre Schnittstelle mit der BI-Plattform.
Eine BI-Plattform kann drei verschiedene Typen von Modellen liefern:
- Enterprise-Modelle
- BI-Semantikmodelle
- Machine Learning (ML)-Modelle
Enterprise-Modelle
Enterprise-Modelle werden von IT-Architekten erstellt und verwaltet. Sie werden manchmal als dimensionale Modelle oder Data Marts bezeichnet. In der Regel werden Daten im relationalen Format als Dimensions- und Faktentabellen gespeichert. Diese Tabellen speichern bereinigte und angereicherte Daten aus vielen Systemen und stellen eine autoritative Quelle für Berichterstellung und Analyse dar.
Enterprise-Modelle bieten eine konsistente und einzelne Datenquelle für Berichterstellung und BI. Sie werden einmal erstellt und als Unternehmensstandard freigegeben. Governancerichtlinien stellen sicher, dass Daten sicher sind, sodass der Zugriff auf vertrauliche Datensätze wie Kundeninformationen oder Finanzdaten auf Bedarfsbasis eingeschränkt ist. Sie übernehmen Benennungskonventionen, um Konsistenz zu gewährleisten und so die Glaubwürdigkeit von Daten und Qualität weiter zu etablieren.
In einer Cloud BI-Plattform können Unternehmensmodelle in einem Synapse SQL-Pool in Azure Synapse bereitgestellt werden. Der Synapse SQL-Pool wird dann zur einzelnen Version der Wahrheit, auf die sich die Organisation verlassen kann, um schnelle und robuste Einblicke zu erhalten.
BI-Semantikmodelle
BI-Semantikmodelle stellen eine semantische Ebene über Enterprise-Modelle dar. Sie werden von BI-Entwicklern und Geschäftsbenutzern erstellt und verwaltet. BI-Entwickler erstellen kerne BI-Semantikmodelle, die Daten aus Unternehmensmodellen beziehen. Geschäftsbenutzer können kleinere, unabhängige Modelle erstellen oder kerne BI-Semantikmodelle mit abteilungsbezogenen oder externen Quellen erweitern. BI-Semantikmodelle konzentrieren sich häufig auf einen einzelnen Themenbereich und sind häufig weit verbreitet.
Geschäftsfunktionen werden nicht allein durch Daten, sondern durch BI-Semantikmodelle ermöglicht, die Konzepte, Beziehungen, Regeln und Standards beschreiben. Auf diese Weise stellen sie intuitive und leicht verständliche Strukturen dar, die Datenbeziehungen definieren und Geschäftsregeln als Berechnungen kapseln. Sie können auch fein abgestimmte Datenberechtigungen erzwingen, um sicherzustellen, dass die richtigen Personen Zugriff auf die richtigen Daten haben. Wichtig ist, dass sie die Abfrageleistung beschleunigen und extrem reaktionsfähige interaktive Analysen bieten – sogar über Terabyte an Daten. Wie Bei Enterprise-Modellen übernehmen BI-Semantikmodelle Namenskonventionen, die Konsistenz gewährleisten.
In einer Cloud-BI-Plattform können BI-Entwickler BI-Semantikmodelle in Azure Analysis Services, Power BI Premium-Kapazitäten und Microsoft Fabric-Kapazitäten bereitstellen.
Von Bedeutung
Dieser Artikel bezieht sich auf Power BI Premium oder seine Kapazitätsabonnements (P-SKUs). Derzeit konsolidiert Microsoft Kaufoptionen und setzt die Power BI Premium-SKUs pro Kapazität zurück. Neue und vorhandene Kunden sollten stattdessen den Kauf von Fabric-Kapazitätsabonnements (F-SKUs) in Betracht ziehen.
Weitere Informationen finden Sie unter Wichtige Updates zur Power BI Premium-Lizenzierung und Häufig gestellte Fragen zu Power BI Premium.
Es wird empfohlen, Power BI bereitzustellen, wenn sie als Berichterstellungs- und Analyseebene verwendet wird. Diese Produkte unterstützen unterschiedliche Speichermodi, sodass Datenmodelltabellen ihre Daten zwischenspeichern oder DirectQuery verwenden können. Dabei handelt es sich um eine Technologie, die Abfragen an die zugrunde liegende Datenquelle übergibt. DirectQuery ist ein idealer Speichermodus, wenn Modelltabellen große Datenvolumes darstellen oder es erforderlich ist, nahezu echtzeitbezogene Ergebnisse bereitzustellen. Die beiden Speichermodi können kombiniert werden: Zusammengesetzte Modelle kombinieren Tabellen, die unterschiedliche Speichermodi in einem einzigen Modell verwenden.
Bei stark abgefragten Modellen kann Azure Load Balancer verwendet werden, um die Abfragelast gleichmäßig über Modellreplikate hinweg zu verteilen. Außerdem können Sie Ihre Anwendungen skalieren und hoch verfügbare BI-Semantikmodelle erstellen.
Machine Learning-Modelle
Machine Learning (ML)-Modelle werden von Data Scientists erstellt und verwaltet. Sie werden hauptsächlich aus Rohdatenquellen im Data Lake entwickelt.
Trainierte ML-Modelle können Muster innerhalb Ihrer Daten offenlegen. In vielen Fällen können diese Muster verwendet werden, um Vorhersagen zu erstellen, die zum Anreichern von Daten verwendet werden können. Beispielsweise kann das Einkaufsverhalten verwendet werden, um Kundenabwanderungen oder Segmentkunden vorherzusagen. Vorhersageergebnisse können Enterprise-Modellen hinzugefügt werden, um analysen nach Kundensegment zu ermöglichen.
In einer Cloud BI-Plattform können Sie Azure Machine Learning verwenden, um ML-Modelle zu trainieren, bereitzustellen, zu automatisieren, zu verwalten und nachzuverfolgen.
Datenlager
Im Mittelpunkt einer BI-Plattform steht das Data Warehouse, das Ihre Unternehmensmodelle hosten. Es ist eine Quelle sanktionierter Daten – als System of Record und als Hub – zur Unterstützung von Unternehmensmodellen für Berichterstattung, BI und Data Science.
Viele Geschäftsdienste, einschließlich Branchenanwendungen, können sich auf das Data Warehouse als autorisierende und geregelte Quelle von Unternehmenswissen verlassen.
Bei Microsoft wird unser Data Warehouse auf Azure Data Lake Storage Gen2 (ADLS Gen2) und Azure Synapse Analytics gehostet.
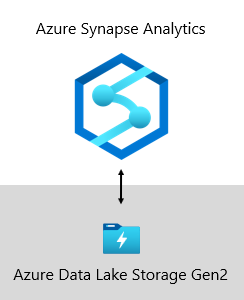
- ADLS Gen2 macht Azure Storage zur Grundlage für die Erstellung von Unternehmensdatenseen in Azure. Diese SKU ist darauf ausgelegt, mehrere Petabyte an Informationen bereitzustellen und gleichzeitig Hunderte von Gigabyte an Durchsatz zu unterstützen. Und es bietet kostengünstige Speicherkapazität und Transaktionen. Darüber hinaus unterstützt es Hadoop-kompatiblen Zugriff, mit dem Sie Daten genauso wie bei einem Hadoop Distributed File System (HDFS) verwalten und darauf zugreifen können. Tatsächlich können Azure HDInsight, Azure Databricks und Azure Synapse Analytics auf in ADLS Gen2 gespeicherte Daten zugreifen. Daher ist es in einer BI-Plattform eine gute Wahl, rohe Quelldaten, halbverarbeitete oder mehrstufige Daten und produktionsfähige Daten zu speichern. Wir verwenden es, um alle unsere Geschäftsdaten zu speichern.
- Azure Synapse Analytics ist ein Analysedienst, der Enterprise Data Warehouse und Big Data Analytics zusammenführt. Es bietet Ihnen die Freiheit, Daten zu Ihren Bedingungen abzufragen, entweder serverlosen On-Demand-Ressourcen oder bereitgestellten Ressourcen—in großem Maßstab. Synapse SQL, eine Komponente von Azure Synapse Analytics, unterstützt vollständige T-SQL-basierte Analysen, daher ist es ideal, Unternehmensmodelle zu hosten, die Ihre Dimension- und Faktentabellen umfassen. Tabellen können mithilfe einfacher Polybase T-SQL-Abfragen effizient aus ADLS Gen2 geladen werden. Sie haben dann die Leistungsfähigkeit von MPP , um Hochleistungsanalysen auszuführen.
Framework für das Geschäftsregelnmodul
Wir haben ein Business Rules Engine (BRE)-Framework entwickelt, um jede Geschäftslogik zu katalogisieren, die in der Data Warehouse-Ebene implementiert werden kann. Ein BRE kann viele Dinge bedeuten, aber im Kontext eines Data Warehouses ist es nützlich, berechnete Spalten in relationalen Tabellen zu erstellen. Diese berechneten Spalten werden in der Regel als mathematische Berechnungen oder Ausdrücke unter Verwendung von Bedingungsanweisungen dargestellt.
Die Absicht besteht darin, Geschäftslogik vom BI-Kerncode zu trennen. Traditionell sind Geschäftsregeln hartcodiert in GESPEICHERTe SQL-Prozeduren, sodass es häufig zu großen Anstrengungen führt, diese beizubehalten, wenn sich die Geschäftlichen Anforderungen ändern. In einem BRE werden Geschäftsregeln einmal definiert und mehrmals verwendet, wenn sie auf verschiedene Data Warehouse-Entitäten angewendet werden. Wenn sich die Berechnungslogik ändern muss, muss sie nur an einem Ort und nicht in zahlreichen gespeicherten Prozeduren aktualisiert werden. Es gibt auch einen Nebenvorteil: Ein BRE-Framework fördert Transparenz und Sichtbarkeit der implementierten Geschäftslogik, die durch eine Reihe von Berichten verfügbar gemacht werden kann, welche eine sich selbst aktualisierende Dokumentation erstellen.
Datenquellen
Ein Data Warehouse kann Daten aus praktisch jeder Datenquelle konsolidieren. Es basiert hauptsächlich auf branchenspezifischen Datenquellen, die häufig relationale Datenbanken sind, die themenspezifische Daten für Vertrieb, Marketing, Finanzen usw. speichern. Diese Datenbanken können in der Cloud gehostet werden oder lokal gespeichert werden. Andere Datenquellen können dateibasiert sein, insbesondere Webprotokolle oder IOT-Datenquellen, die von Geräten stammen. Darüber hinaus können Daten von Software-as-a-Service (SaaS)-Anbietern stammen.
Bei Microsoft geben einige unserer internen Systeme Betriebsdaten direkt in ADLS Gen2 mithilfe von Rohdateiformaten aus. Neben unserem Data Lake umfassen andere Quellsysteme relationale Fachbereichsanwendungen, Excel-Arbeitsmappen, andere dateibasierte Quellen sowie das Master Data Management (MDM) und benutzerdefinierte Datenrepositorys. MDM-Repositorys ermöglichen es uns, unsere Stammdaten zu verwalten, um autoritative, standardisierte und validierte Versionen von Daten sicherzustellen.
Datenaufnahme
Regelmäßig und nach den Rhythmen des Geschäfts werden Daten aus Quellsystemen aufgenommen und in das Data Warehouse geladen. Es könnte einmal pro Tag oder in häufigeren Abständen sein. Die Datenaufnahme befasst sich mit dem Extrahieren, Transformieren und Laden von Daten. Oder vielleicht umgekehrt: Extrahieren, Laden und anschließendes Transformieren von Daten. Der Unterschied liegt darin, wo die Transformation stattfindet. Transformationen werden auf die Bereinigung, Konformität, Integration und Standardisierung von Daten angewendet. Weitere Informationen finden Sie unter Extrahieren, Transformieren und Laden (ETL).
Letztendlich ist es das Ziel, die richtigen Daten so schnell und effizient wie möglich in Ihr Unternehmensmodell zu laden.
Bei Microsoft verwenden wir Azure Data Factory (ADF). Die Dienste werden verwendet, um Datenüberprüfungen, Transformationen und Massenlasten von externen Quellsystemen in unseren Data Lake zu planen und zu koordinieren. Es wird von benutzerdefinierten Frameworks verwaltet, um Daten parallel und skaliert zu verarbeiten. Darüber hinaus wird eine umfassende Protokollierung zur Unterstützung der Problembehandlung, Leistungsüberwachung und zum Auslösen von Warnungsbenachrichtigungen durchgeführt, wenn bestimmte Bedingungen erfüllt sind.
In der Zwischenzeit führt Azure Databricks – eine apache Spark-basierte Analyseplattformen, die für die Azure Cloud Services-Plattform optimiert sind – Transformationen speziell für Data Science durch. Außerdem werden ML-Modelle mit Python-Notizbüchern erstellt und ausgeführt. Ergebnisse dieser ML-Modelle werden in das Data Warehouse geladen, um Vorhersagen in Unternehmensanwendungen und -berichte zu integrieren. Da Azure Databricks direkt auf die Datenseedateien zugreift, wird die Notwendigkeit zum Kopieren oder Abrufen von Daten beseitigt oder minimiert.
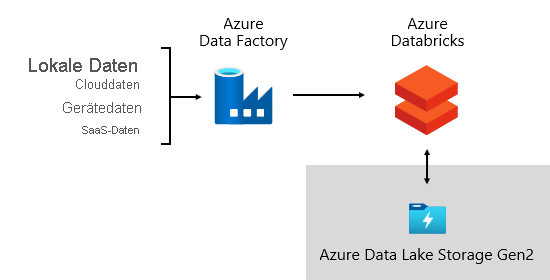
Datenaufnahme-Framework
Wir haben ein Importrahmen als eine Reihe von Konfigurations- und Verfahrenstabellen entwickelt. Es unterstützt einen datengesteuerten Ansatz zum Abrufen großer Datenmengen mit hoher Geschwindigkeit und mit minimalem Code. Kurz gesagt, dieses Framework vereinfacht den Prozess der Datenerfassung, um das Data Warehouse zu laden.
Das Framework hängt von Konfigurationstabellen ab, in denen Datenquellen- und Datenzielinformationen wie Quelltyp, Server, Datenbank, Schema und tabellenbezogene Details gespeichert werden. Dieser Entwurfsansatz bedeutet, dass wir keine spezifischen ADF-Pipelines oder SQL Server Integration Services (SSIS)- Pakete entwickeln müssen. Stattdessen werden Prozeduren in der Sprache unserer Wahl geschrieben, um ADF-Pipelines zu erstellen, die dynamisch generiert und zur Laufzeit ausgeführt werden. Die Datenerfassung wird also zu einer Konfigurationsübung, die leicht operationalisiert wird. Traditionell würde es umfangreiche Entwicklungsressourcen erfordern, um hartcodierte ADF- oder SSIS-Pakete zu erstellen.
Das Aufnahmeframework wurde entwickelt, um auch die Verarbeitung von Upstream-Quellschemaänderungen zu vereinfachen. Es ist einfach, Konfigurationsdaten – manuell oder automatisch – zu aktualisieren, wenn Schemaänderungen erkannt werden, um neu hinzugefügte Attribute im Quellsystem zu erhalten.
Orchestrierungs-Framework
Wir haben ein Orchestrierungsframework entwickelt, um unsere Datenpipelinen zu operationalisieren und zu koordinieren. Das Orchestrierungsframework verwendet ein datengesteuertes Design, das von einer Reihe von Konfigurationstabellen abhängt. In diesen Tabellen werden Metadaten gespeichert, die Pipelineabhängigkeiten beschreiben und wie Quelldaten Zieldaten zugeordnet werden. Die Investition in die Entwicklung dieses adaptiven Rahmens hat sich seitdem bezahlt; es ist nicht mehr erforderlich, jede Datenverschiebung hart zu codieren.
Datenspeicherung
Ein Data Lake kann große Mengen von Rohdaten zur späteren Verwendung zusammen mit Staging-Datentransformationen speichern.
Bei Microsoft verwenden wir ADLS Gen2 als einzige Quelle der Wahrheit. Sie speichert Rohdaten zusammen mit mehrstufigen Daten und produktionsbereiten Daten. Es bietet eine hoch skalierbare und kostengünstige Data Lake-Lösung für Big Data Analytics. Durch die Kombination der Leistungsfähigkeit eines Hochleistungs-Dateisystems mit großer Skalierbarkeit ist es für Datenanalyse-Workloads optimiert und verkürzt die Zeit bis zur Erkenntnis.
ADLS Gen2 bietet das Beste aus zwei Welten: es ist BLOB-Speicher und ein leistungsstarker Dateisystemnamespace, den wir mit differenzierten Zugriffsberechtigungen konfigurieren.
Verfeinerte Daten werden dann in einer relationalen Datenbank gespeichert, um einen leistungsfähigen, hoch skalierbaren Datenspeicher für Unternehmensmodelle mit Sicherheit, Governance und Verwaltbarkeit bereitzustellen. Fachspezifische Data Marts werden in Azure Synapse Analytics gespeichert, die von Azure Databricks- oder Polybase T-SQL-Abfragen geladen werden.
Nutzung der Daten
Auf der Berichtsschicht nutzen Geschäftsdienste Unternehmensdaten, die aus dem Data Warehouse stammen. Sie greifen auch direkt im Datensee auf Daten für Ad-hoc-Analysen oder Data Science-Aufgaben zu.
Feinkörnige Berechtigungen werden auf allen Ebenen erzwungen: im Data Lake, in Unternehmensmodellen und BI-Semantikmodellen. Die Berechtigungen stellen sicher, dass Datenkonsumenten nur die Daten sehen können, auf die sie Zugriffsrechte haben.
Bei Microsoft verwenden wir Power BI-Berichte und Dashboards sowie Power BI-Paginierte Berichte. Einige Berichte und Ad-hoc-Analysen werden in Excel durchgeführt, insbesondere für die Finanzberichterstattung.
Wir veröffentlichen Datenwörterbücher, die Referenzinformationen zu unseren Datenmodellen bereitstellen. Sie werden unseren Benutzern zur Verfügung gestellt, damit sie Informationen über unsere BI-Plattform entdecken können. Wörterbücher Dokumentmodelldesigns, die Beschreibungen zu Entitäten, Formaten, Struktur, Datenherkunft, Beziehungen und Berechnungen bereitstellen. Wir verwenden den Azure-Datenkatalog , um unsere Datenquellen leicht auffindbar und verständlich zu machen.
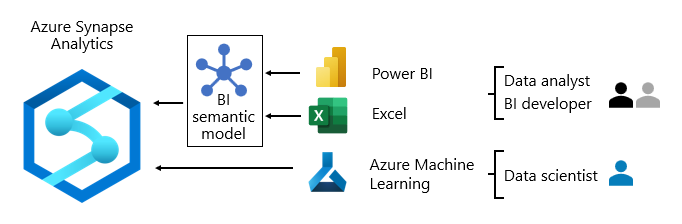
In der Regel unterscheiden sich Datenverbrauchsmuster je nach Rolle:
- Datenanalysten verbinden sich direkt mit kernen BI-Semantikmodellen. Wenn kerne BI-Semantikmodelle alle benötigten Daten und Logik enthalten, verwenden sie Liveverbindungen zum Erstellen von Power BI-Berichten und Dashboards. Wenn sie die Modelle mit Abteilungsdaten erweitern müssen, erstellen sie Zusammengesetzte Power BI-Modelle. Wenn Berichte im Tabellenkalkulationsformat erforderlich sind, verwenden sie Excel, um Berichte basierend auf kernen BI-Semantikmodellen oder abteilungsspezifischen BI-Semantikmodellen zu erstellen.
- BI-Entwickler und Berichtsautoren verbinden sich direkt mit Enterprise-Modellen. Sie verwenden Power BI Desktop zum Erstellen von Analyseberichten für Liveverbindungen. Sie können auch BI-Berichte vom Typ Operational als Power BI-paginierte Berichte erstellen, indem sie native SQL-Abfragen schreiben, um auf Daten aus den Azure Synapse Analytics-Modellen mithilfe von T-SQL zuzugreifen oder auf Power BI-Semantikmodelle mithilfe von DAX oder MDX.
- Data Scientists verbinden sich direkt mit Daten im Data Lake. Sie verwenden Azure Databricks und Python-Notizbücher, um ML-Modelle zu entwickeln, die oft experimentell sind und Spezialkenntnisse für die Produktionsverwendung erfordern.
Verwandte Inhalte
Weitere Informationen zu diesem Beitrag finden Sie in den folgenden Ressourcen:
- Roadmap für die Einführung von Fabric: Center of Excellence
- Enterprise BI in Azure mit Azure Synapse Analytics
- Haben Sie Fragen? Versuchen Sie die Fabric Community um Rat zu fragen
- Vorschläge? Tragen Sie Ideen bei, um Fabric zu verbessern
Dienstleistungsunternehmen
Zertifizierte Power BI-Partner stehen zur Verfügung, damit Ihre Organisation bei der Einrichtung eines COE erfolgreich ist. Sie können Ihnen kostengünstige Schulungen oder eine Prüfung Ihrer Daten bieten. Um einen Power BI-Partner zu finden, besuchen Sie das Microsoft Power BI-Partnerportal.
Sie können sich auch mit erfahrenen Beratungspartnern beschäftigen. Sie können Ihnen helfen, Power BI zu bewerten, auszuwerten oder zu implementieren .