Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Mithilfe von Beziehungen mit m:n-Kardinalität in Power BI Desktop können Sie Tabellen mit m:n-Kardinalität verknüpfen. Sie können einfacher und intuitiver Datenmodelle erstellen, die zwei oder mehr Datenquellen enthalten können. Beziehungen mit m:n-Kardinalität sind Teil der umfangreicheren Funktionen zusammengesetzter Modelle in Power BI Desktop. Weitere Informationen zu zusammengesetzten Modellen finden Sie unter Verwenden zusammengesetzter Modelle in Power BI Desktop
Zweck einer Beziehung mit m:n-Kardinalität
Bevor Beziehungen mit m:n-Kardinalität verfügbar waren, wurde die Beziehung zwischen zwei Tabellen in Power BI definiert. Mindestens eine der Tabellenspalten, die an der Beziehung beteiligt war, musste eindeutige Werte enthalten. Häufig hat jedoch keine Spalte eindeutige Werte enthalten.
Angenommen, zwei Tabellen verfügen über eine Spalte mit der Bezeichnung „Country/Region“. Die Werte für „Country/Region“ sind jedoch in keiner Tabelle eindeutig. Solche Tabellen konnten nur über eine Problemumgehung miteinander verknüpft werden. Eine Möglichkeit zur Umgehung des Problems bestand darin, zusätzliche Tabellen mit den erforderlichen eindeutigen Werten einzufügen. Mithilfe der Beziehungen mit m:n-Kardinalität können Sie solche Tabellen direkt miteinander verknüpfen, indem Sie eine Beziehung mit m:n-Kardinalität verwenden.
Verwenden von Beziehungen mit m:n-Kardinalität
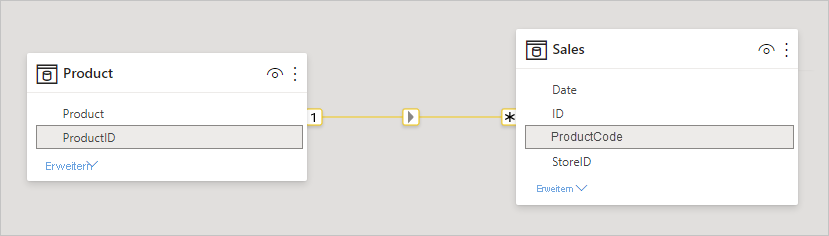
Wenn Sie eine Beziehung zwischen zwei Tabellen in Power BI definieren, müssen Sie die Kardinalität der Beziehung definieren. Die Beziehung zwischen „Produktverkäufen“ (ProductSales) und „Produkt“ kann beispielsweise mithilfe der Spalten „Produktverkäufe[Produkt-Code]“ und „Produkt[Produkt-Code]“ als n:1 definiert werden. Die Beziehung wird auf diese Weise definiert, weil es für jedes Produkt viele Verkäufe gibt und die Spalte „ProductCode“ in der Tabelle „Product“ eindeutig ist. Wenn Sie die Kardinalität einer Beziehung als n:1, 1:n oder 1:1 definieren, überprüft Power BI, ob die ausgewählte Kardinalität den tatsächlichen Daten auch entspricht.
Die folgende Abbildung zeigt beispielsweise ein einfaches Modell:
Nehmen Sie nun an, dass die Tabelle Product wie im Folgenden dargestellt nur zwei Zeilen anzeigt:
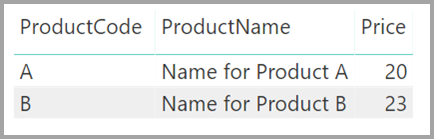
Stellen Sie sich auch vor, dass die Tabelle "Vertrieb" nur vier Zeilen enthält, einschließlich einer Zeile für ein Produkt C. Da die Zeile "Produkt C" in der Tabelle " Product " nicht vorhanden ist, liegt ein Fehler bei der referenziellen Integrität vor.
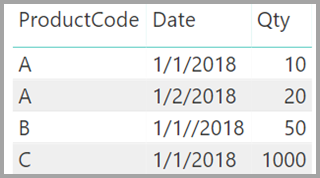
Die Spalten ProductName und Price (aus der Tabelle Product) zusammen mit der Gesamtmenge Qty für jedes Produkt (aus der Tabelle „ProductSales“) würden nun wie folgt angezeigt:
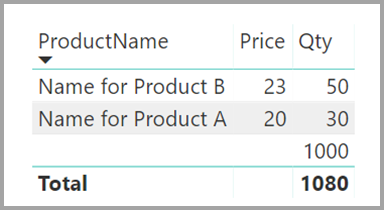
Sie sehen in der vorherigen Abbildung, dass eine leere ProductName-Zeile den Verkäufen für Produkt C zugeordnet ist. Folgende Gründe können für die leere Zeile vorliegen:
Alle Zeilen in der Tabelle ProductSales, für die keine zugehörige Zeile in der Tabelle Product vorhanden ist. Es besteht ein Problem mit der referenziellen Integrität, das sich in diesem Beispiel auf Produkt C auswirkt.
Zeilen in der Tabelle ProductSales, bei denen die Fremdschlüsselspalte NULL ist.
Aus diesen Gründen deckt die leere Zeile in beiden Fällen Verkäufe ab, bei denen ProductName und Price unbekannt sind.
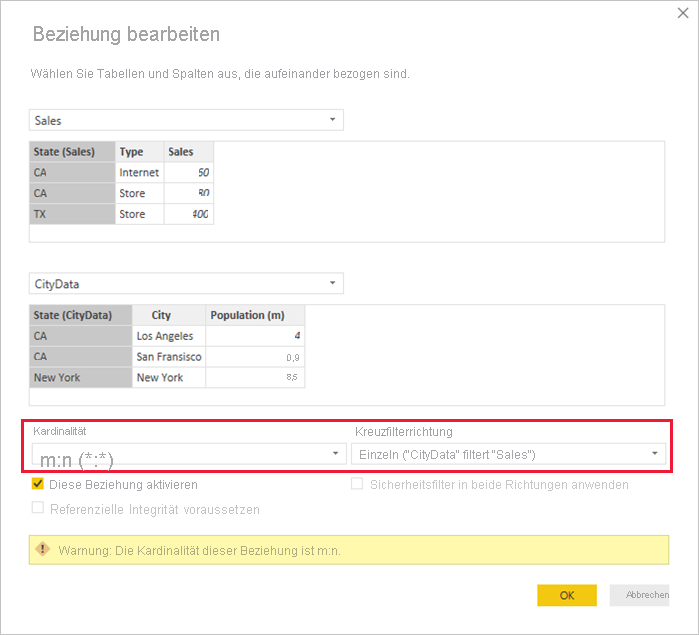
Manchmal werden die Tabellen durch zwei Spalten verknüpft, von denen jedoch keine eindeutig ist. Betrachten Sie beispielsweise die folgenden beiden Tabellen:
Die Tabelle Sales stellt die Umsatzdaten nach State dar, wobei jede Zeile den Umsatzbetrag für den Typ des Umsatzes im jeweiligen Bundesstaat enthält. Zu diesen Bundesstaaten zählen z.B. Kalifornien, Washington und Texas (CA, WA, TX).
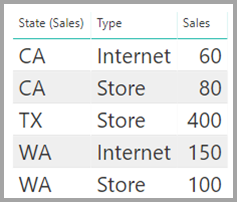
Die Tabelle CityData enthält Daten zu Städten, wie etwa Einwohnerzahl und Bundesstaat (z. B. CA, WA und New York).
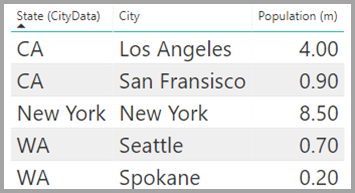
Beide Tabellen enthalten also eine Spalte für State. Es liegt nun nahe, in einem Bericht die Gesamtumsätze pro Bundesstaat mit der Gesamtbevölkerung der einzelnen Bundesstaaten zu kombinieren. Dabei gibt es jedoch ein Problem: In keiner Tabelle ist die Spalte State eindeutig.
Die bisherige Problemumgehung
Vor dem Power BI Desktop-Release vom Juli 2018 konnten Benutzer keine direkte Beziehung zwischen diesen Tabellen erstellen. Eine gängige Problemumgehung bestand aus den folgenden Schritten:
Eine dritte Tabelle wurde erstellt, die ausschließlich die eindeutigen IDs von „State“ enthielt. Für die Tabelle galt eine oder alle der folgenden Optionen:
- Eine berechnete Tabelle, die mithilfe von DAX (Data Analysis Expressions) definiert wurde
- Eine Tabelle, die auf einer im Power Query-Editor definierten Abfrage basiert und in der die eindeutigen IDs enthalten sein können, die aus einer der Tabellen abgerufen wurden.
- Eine Kombination aus beidem.
Anschließend wurde mithilfe herkömmlicher n:1-Beziehungen eine Beziehung zwischen den beiden ursprünglichen Tabellen und der neuen Tabelle hergestellt.
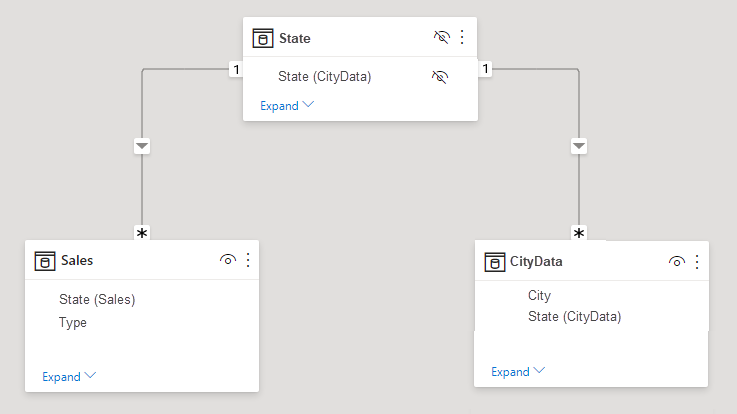
Dabei konnte die Tabelle für die Problemumgehung sichtbar bleiben. Sie können die Problemumgehungstabelle auch ausblenden, damit sie nicht in der Liste Felder angezeigt wird. Bei ausgeblendeter Tabelle wurden die n:1-Beziehungen üblicherweise so festgelegt, dass in beide Richtungen gefiltert wurde. So konnte das Feld „State“ von jeder Tabelle verwendet werden. Die spätere Kreuzfilterung wird an die andere Tabelle weitergegeben. Dieser Ansatz wird in der folgenden Abbildung veranschaulicht:
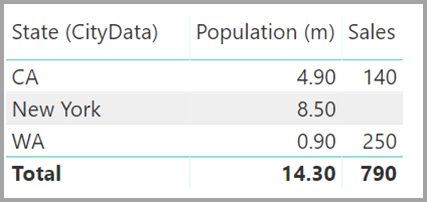
Ein Visual, das State (aus der Tabelle CityData) zusammen mit der Gesamtwert von Population und Sales anzeigt, würde dann wie folgt aussehen:
Hinweis
Da in dieser Problemumgehung der Wert für „State“ aus der Tabelle CityData verwendet wird, werden nur die State-Werte dieser Tabelle aufgeführt (weshalb TX ausgeschlossen wurde). Im Gegensatz zu n:1-Beziehungen ist zudem in den Details keine leere Zeile enthalten, die solche nicht übereinstimmenden Zeilen abdeckt. Die Zeile „Total“ enthält hingegen alle Sales-Werte (einschließlich der von TX). Analog dazu gäbe es keine leere Zeile für alle Sales-Werte, bei denen der Wert für State NULL lautet.
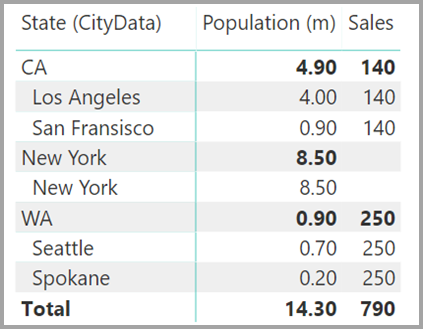
Angenommen, Sie fügen dem Visual auch die Spalte „City“ hinzu. Obwohl die Einwohnerzahl für jeden City-Wert bekannt ist, wird in der Sales-Spalte für „City“ nur der Sales-Wert für die entsprechende State-Spalte wiederholt. Zu diesem Szenario kann es kommen, wenn die Spaltengruppierung, wie in der folgenden Abbildung gezeigt, mit keinem aggregierten Measure verknüpft ist:
Angenommen, Sie definieren die neue Tabelle „Sales“ als Kombination aller Werte für „States“ und machen dies in der Liste Felder sichtbar. Dasselbe Visual würde State (in der neuen Tabelle), die Gesamtbevölkerung für Population und den Gesamtumsatz für Sales anzeigen:
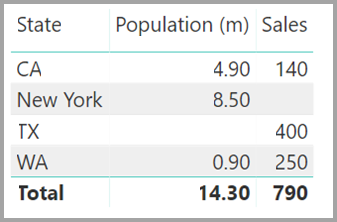
Sie sehen, dass TX (inklusive der Daten für Verkäufe, jedoch ohne Daten für Bevölkerung) und New York (inklusive der Daten für Bevölkerung, jedoch ohne Daten für Verkäufe) enthalten wäre. Diese Umgehung ist nicht ideal und führt zu vielen Problemen. Für Beziehungen mit m:n-Kardinalität werden die daraus resultierenden Probleme wie im folgenden Abschnitt beschrieben behoben.
Weitere Informationen zum Implementieren dieser Problemumgehung finden Sie in der Anleitung zu m:n-Beziehungen.
Verwenden von Beziehungen mit m:n-Kardinalität anstelle der Problemumgehung
Sie können Tabellen direkt miteinander verknüpfen, ohne auf die oben beschriebene Problemumgehung zurückgreifen zu müssen. Die Kardinalität einer Beziehung kann nun auf m:n festgelegt werden. Diese Einstellung gibt an, dass keine der Tabellen eindeutige Werte enthält. Dennoch können Sie für derartige Beziehungen weiterhin steuern, welche Tabelle die andere Tabelle filtern soll. Alternativ können Sie mit einer bidirektionalen Filterung auch festlegen, dass sich die Tabellen gegenseitig filtern sollen.
In Power BI Desktop lautet die Standardeinstellung für die Kardinalität m:n, wenn festgestellt wird, dass keine der Tabellen eindeutige Werte für die Beziehungsspalten enthält. In solchen Fällen müssen Sie in einer Warnmeldung bestätigen, dass Sie eine Beziehung festlegen möchten und dass die Änderung nicht die unbeabsichtigte Auswirkung eines Datenproblems ist.
Wenn Sie z. B. eine direkte Beziehung zwischen Daten zur Stadt (CityData) und dem Umsatz (Sales) erstellen (mit Filterrichtung von den Daten zur Stadt zum Umsatz), zeigt Power BI Desktop das Dialogfeld Beziehung bearbeiten an:
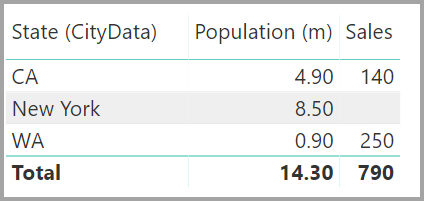
Die resultierende Beziehungsansicht würde dann die direkte m:n-Beziehung zwischen den beiden Tabellen darstellen. Die Darstellung der Tabellen in der Liste Felder und deren späteres Verhalten, wenn die Visuals erstellt wurden, ähneln den Ergebnissen, die durch die Problemumgehung erzielt wurden. In der Problemumgehung wurde die zusätzliche Tabelle mit den eindeutigen Daten für „State“ nicht sichtbar gemacht. Wie oben bereits erwähnt, wird ein Visual mit den Spalten State, Population und Sales folgendermaßen angezeigt:
Zwischen Beziehungen mit m:n-Kardinalität und den geläufigeren n:1-Beziehungen bestehen die folgenden wesentlichen Unterschiede:
Die angezeigten Werte enthalten keine leere Zeile, die nicht übereinstimmende Zeilen in der anderen Tabelle abdeckt. Die Werte decken ebenfalls keine Zeilen ab, bei denen die Spalte, die in der anderen Tabelle der Beziehung verwendet wurde, den Wert NULL aufweist.
Die Funktion
RELATED()kann nicht verwendet werden, da mehr als eine Zeile verknüpft sein könnte.Mit der Funktion
ALL()werden in einer Tabelle keine Filter entfernt, die auf andere verknüpfte Tabellen angewendet wurden, mit denen eine m:n-Beziehung besteht. Im vorherigen Beispiel würde ein Measure, das wie hier definiert wurde, keine Filter für Spalten in der verknüpften Tabelle „CityData“ entfernen:![Screenshot eines Skriptbeispiels. Das Beispiel lautet „Sales total = Calculate(Sum('Sales'[Sales]), All('Sales'))“.](media/desktop-many-to-many-relationships/many-to-many-relationships_13.png)
Ein Visual mit Daten für State, Sales und Sales total würde folgendermaßen angezeigt werden:
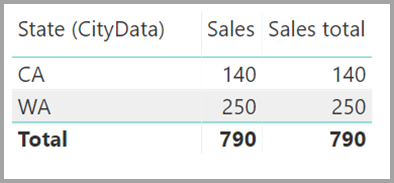
Stellen Sie aufgrund dieser Unterschiede sicher, dass die Berechnungen, die ALL(<Table>) verwenden (wie z. B. % von Gesamtsumme), die gewünschten Ergebnisse zurückgeben.
Überlegungen und Einschränkungen
Bei diesem Release gelten für Beziehungen mit m:n-Kardinalität und zusammengesetzte Modelle einige Einschränkungen.
Die folgenden (mehrdimensionalen) Live Connect-Quellen können nicht mit zusammengesetzten Modellen verwendet werden:
- SAP HANA
- SAP Business Warehouse
- SQL Server Analysis Services
- Power BI-Semantikmodelle
- Azure Analysis Services (Azure-Analysedienste)
Wenn Sie mithilfe von DirectQuery eine Verbindung mit diesen mehrdimensionalen Quellen herstellen, können Sie keine Verbindung mit einer anderen DirectQuery-Quelle herstellen oder diese mit importierten Daten kombinieren.
Die bestehenden Einschränkungen für die Verwendung von DirectQuery gelten nach wie vor, wenn Sie Beziehungen mit m:n-Kardinalität verwenden. Viele Einschränkungen gelten jetzt abhängig vom Speichermodus der Tabelle für eine einzelne Tabelle. Beispielsweise kann eine berechnete Spalte in einer importierten Tabelle auf andere Tabellen verweisen, wohingegen eine berechnete Spalte in einer DirectQuery-Tabelle nach wie vor nur auf Spalten in derselben Tabelle verweisen kann. Es gelten weitere Einschränkungen für das ganze Modell, wenn darin enthaltene Tabellen den Modus „DirectQuery“ aufweisen. Die Funktionen „QuickInsights“ und „Q&A“ sind nicht für Modelle verfügbar, wenn darin enthaltene Tabellen den Speichermodus „DirectQuery“ aufweisen.
Zugehöriger Inhalt
Weitere Informationen zu zusammengesetzten Modellen und DirectQuery finden Sie in den folgenden Artikeln: