Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel richtet sich an Modellierer von Importdaten, die mit Power BI Desktop arbeiten. Es ist ein wichtiges Modelldesignthema, das für intuitive, genaue und optimale Modelle unerlässlich ist.
Eine ausführlichere Erläuterung des optimalen Modelldesigns, einschließlich Tabellenrollen und Beziehungen, finden Sie unter "Grundlegendes zum Sternschema" und zur Wichtigkeit von Power BI.
Beziehungszweck
Eine Modellbeziehung verteilt Filter, die auf die Spalte einer Modelltabelle angewendet werden, auf eine andere Modelltabelle. Filter werden weitergeleitet, so lange ein Beziehungspfad zu befolgen ist, der dabei die Weiterleitung auf mehrere Tabellen umfassen kann.
Beziehungspfade sind deterministisch, was bedeutet, dass Filter immer auf die gleiche Weise und ohne zufällige Variation verteilt werden. Beziehungen können jedoch deaktiviert werden oder den Filterkontext durch Modellberechnungen ändern lassen, die bestimmte DAX-Funktionen (Data Analysis Expressions) verwenden. Weitere Informationen finden Sie im Abschnitt "Relevante DAX-Funktionen" weiter unten in diesem Artikel.
Wichtig
Modellbeziehungen erzwingen keine Datenintegrität. Weitere Informationen finden Sie im Abschnitt "Beziehungsauswertung " weiter unten in diesem Artikel, in dem erläutert wird, wie sich Modellbeziehungen verhalten, wenn Datenintegritätsprobleme mit Ihren Daten auftreten.
Hier erfahren Sie, wie Beziehungen Filter mit einem animierten Beispiel verteilen.
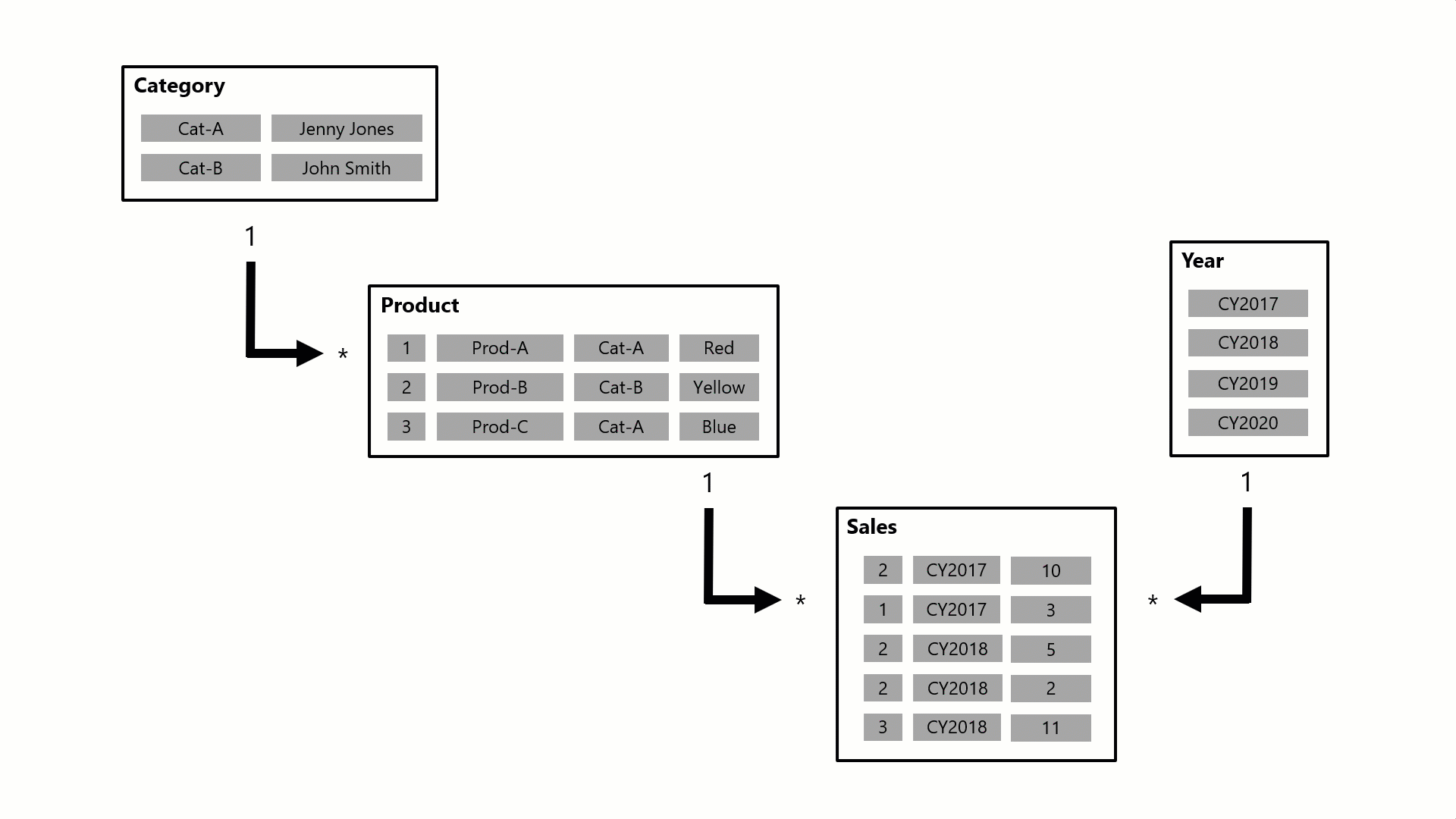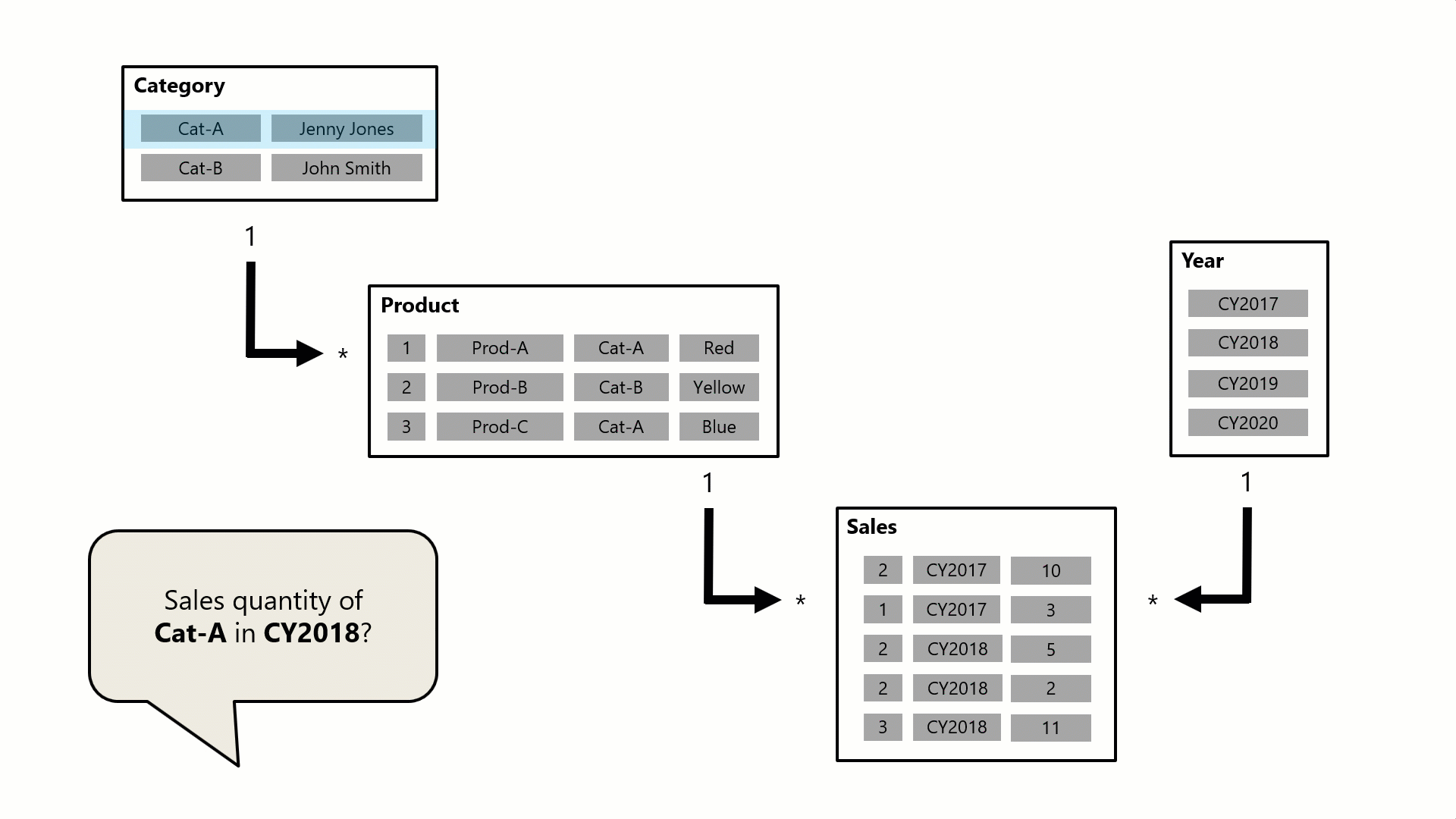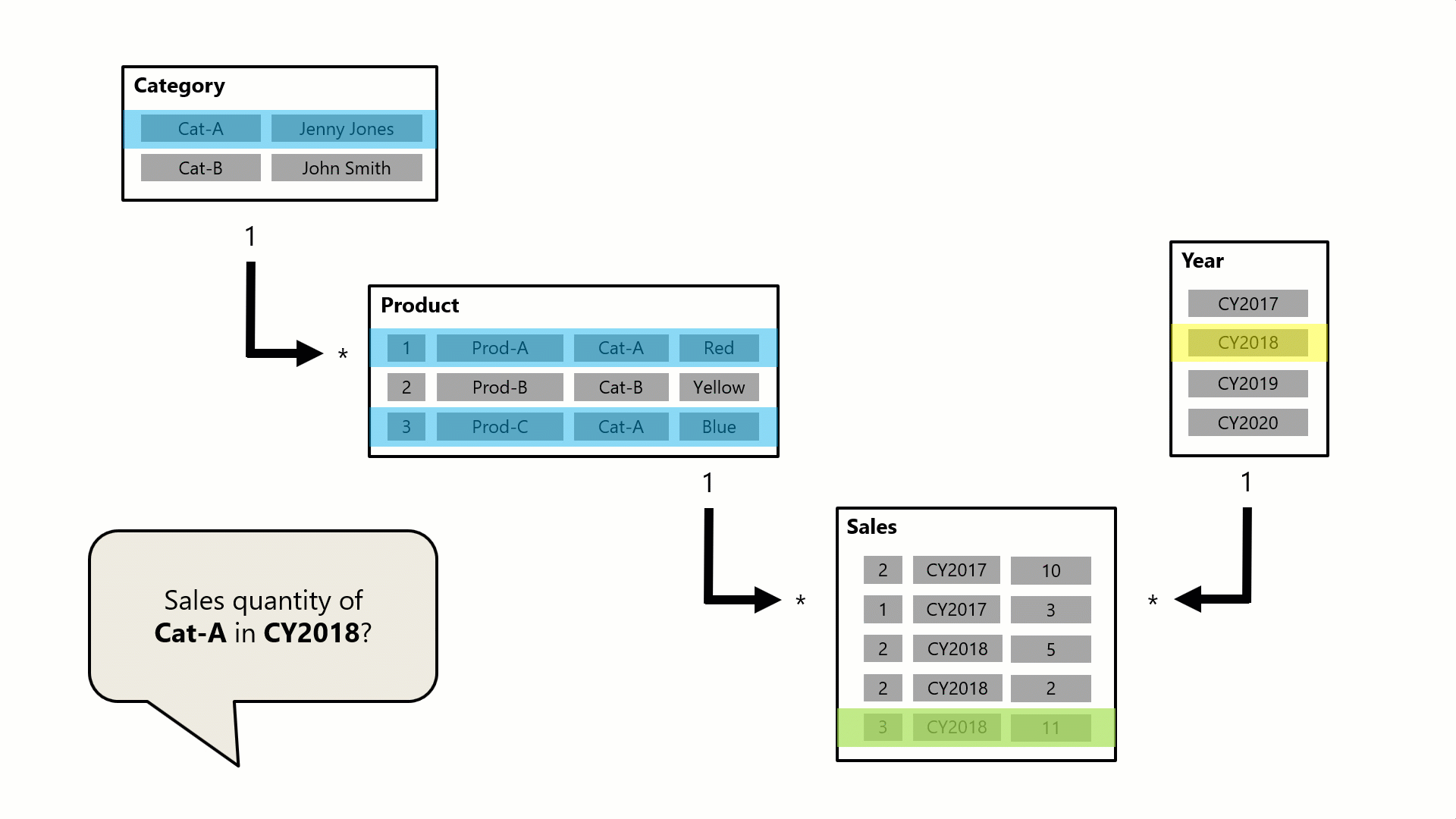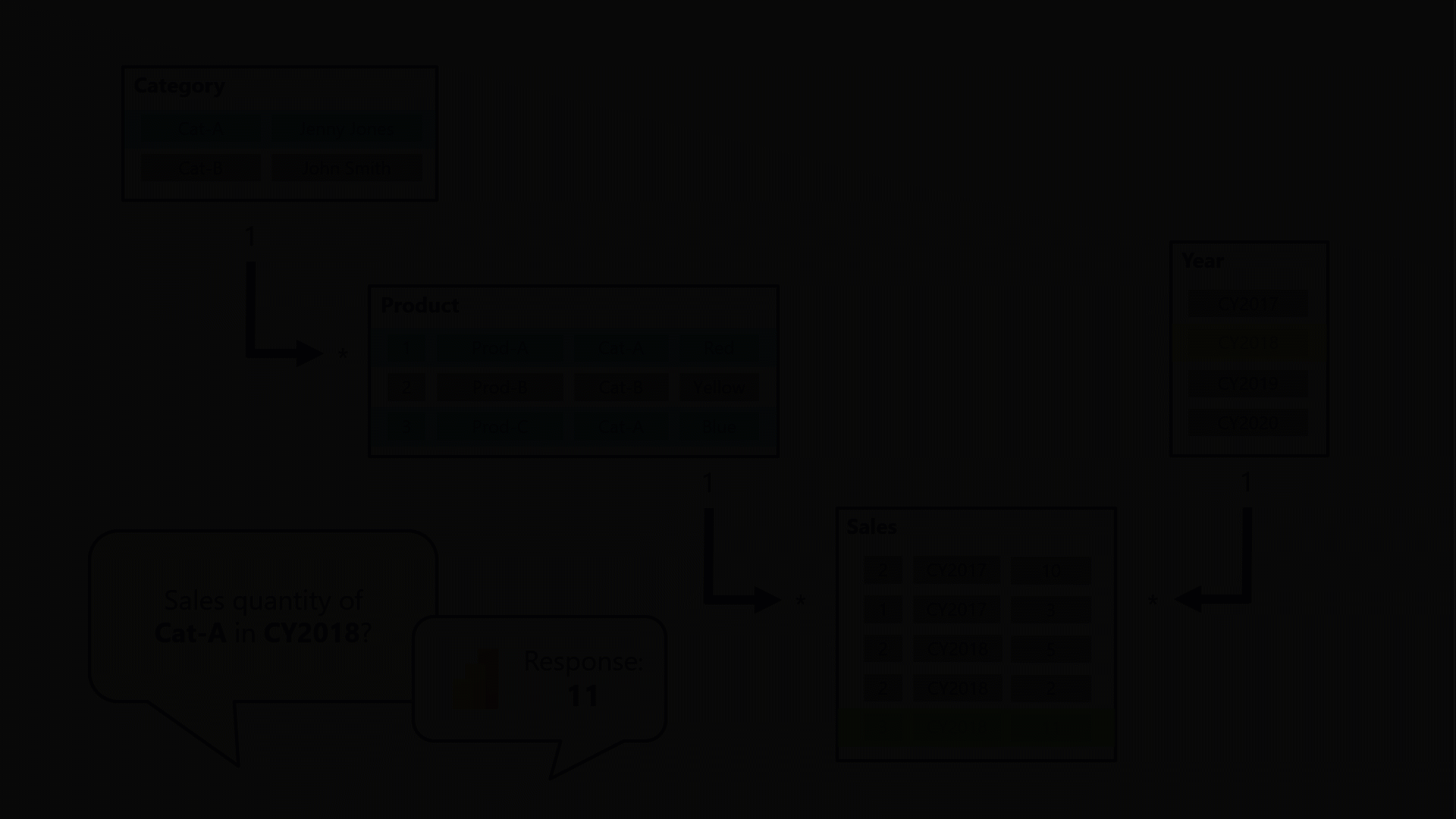
In diesem Beispiel besteht das Modell aus vier Tabellen: Kategorie, Produkt, Jahr und Vertrieb. Die Tabelle "Kategorie " bezieht sich auf die Tabelle " Artikel ", und die Tabelle " Artikel " bezieht sich auf die Tabelle " Umsatz ". Die Tabelle "Jahr " bezieht sich auch auf die Tabelle " Umsatz ". Alle Beziehungen sind 1:n-Beziehungen (Näheres hierzu erfahren Sie später in diesem Artikel).
Eine Abfrage, die möglicherweise von einer Visuellen Power BI-Karte generiert wird, fordert die Gesamtumsatzmenge für Verkaufsaufträge an, die für eine einzelne Kategorie, Cat-A und für ein einzelnes Jahr, CY2018, getätigt wurden. Aus diesem Grund können Sie Filter anzeigen, die auf die Tabellen "Kategorie" und " Jahr " angewendet wurden. Der Filter in der Tabelle "Kategorie " wird an die Tabelle " Produkt " weitergegeben, um zwei Produkte zu isolieren, die der Kategorie Cat-A zugewiesen sind. Anschließend werden die Filter der Produkttabelle auf die Vertriebstabelle übertragen, um nur zwei Verkaufszeilen für diese Produkte zu isolieren. Diese beiden Verkaufszeilen stellen den Verkauf von Produkten dar, die der Kategorie Cat-A zugewiesen sind. Die kombinierte Menge beträgt 14 Einheiten. Gleichzeitig verteilt sich der Tabellenfilter "Jahr " weiter, um die Tabelle " Vertrieb " weiter zu filtern. Dies führt zu einer einzigen Umsatzzeile, die für Produkte der Kategorie Cat-A bestimmt ist und die im Jahr CY2018 bestellt wurde. Der von der Abfrage zurückgegebene Mengenwert beträgt 11 Einheiten. Wenn mehrere Filter auf eine Tabelle angewendet werden (z. B. die Tabelle " Sales " in diesem Beispiel), ist es immer ein AND-Vorgang, der erfordert, dass alle Bedingungen erfüllt sein müssen.
Anwendung von Prinzipien des Sternschema-Designs
Es wird empfohlen, Designprinzipien des Sternschemas anzuwenden, um ein Modell mit Dimensionstabellen und Faktentabellen zu erstellen. Es ist üblich, Power BI einzurichten, um Regeln zu erzwingen, die Bemaßungstabellen filtern, sodass Modellbeziehungen diese Filter effizient an Faktentabellen weitergeben können.
Die folgende Abbildung ist das Modelldiagramm des Adventure Works-Vertriebsanalysedatenmodells. Es zeigt ein Sternschemadesign, das eine einzelne Faktentabelle mit dem Namen "Vertrieb" enthält. Die anderen vier Tabellen sind Dimensionstabellen, die die Analyse von Verkaufsmaßnahmen nach Datum, Bundesland, Region und Produkt unterstützen. Beachten Sie die Modellbeziehungen, die alle Tabellen verbinden. Diese Beziehungen verteilen Filter (direkt oder indirekt) an die Tabelle " Sales ".
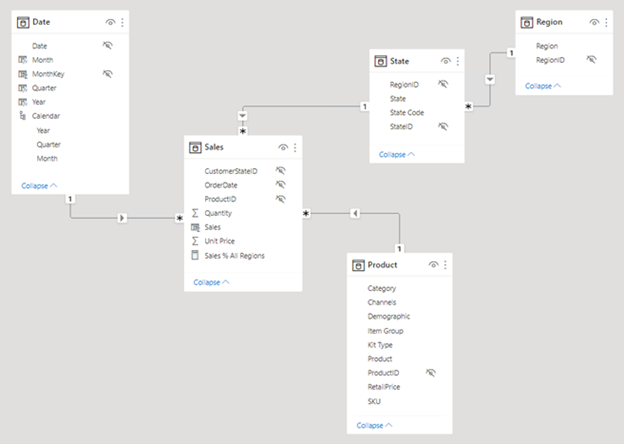
Getrennte Tabellen
Es ist ungewöhnlich, dass eine Modelltabelle nicht mit einer anderen Modelltabelle verknüpft ist. Eine solche Tabelle in einem gültigen Modellentwurf wird als getrennte Tabelle beschrieben. Eine getrennte Tabelle ist nicht für die Weitergabe von Filtern an andere Modelltabellen vorgesehen. Stattdessen akzeptiert es „Benutzereingaben“ (möglicherweise mit einem Slicervisual), sodass der Eingabewert auf sinnvolle Weise für Modellberechnungen verwendet werden kann. Ziehen Sie z. B. eine getrennte Tabelle in Betracht, die mit einem Bereich von Währungskurswerten geladen wird. Solange ein Filter angewendet wird, um nach einem einzelnen Ratenwert zu filtern, kann ein Messausdruck diesen Wert verwenden, um Umsatzwerte umzurechnen.
Der What-if-Parameter von Power BI Desktop ist ein Feature, das eine getrennte Tabelle erstellt. Weitere Informationen finden Sie unter Erstellen und Verwenden eines Was-wäre-wenn-Parameters (What if) zum Visualisieren von Variablen in Power BI Desktop.
Beziehungseigenschaften
In einer Modellbeziehung ist eine Spalte in einer Tabelle mit einer Spalte in einer anderen Tabelle verknüpft. (Es gibt einen speziellen Fall, in dem diese Anforderung nicht zutrifft, und sie gilt nur für mehrspaltige Beziehungen in DirectQuery-Modellen. Weitere Informationen finden Sie im Artikel zur FUNKTION COMBINEVALUES DAX.)
Hinweis
Es ist nicht möglich, eine Spalte mit einer anderen Spalte in derselben Tabelle zu verknüpfen. Dieses Konzept wird manchmal mit der Möglichkeit verwechselt, eine relationale Fremdschlüsseleinschränkung für Datenbanken zu definieren, die sich selbst auf die Tabelle bezieht. Sie können dieses relationale Datenbankkonzept verwenden, um Beziehungen zwischen übergeordneten und untergeordneten Elementen zu speichern (z. B. ist jeder Mitarbeiterdatensatz mit einem Mitarbeiter "Berichte an" verknüpft). Sie können modellbasierte Beziehungen jedoch nicht verwenden, um eine Modellhierarchie basierend auf dieser Art von Beziehung zu generieren. Informationen zum Erstellen einer Eltern-Kind-Hierarchie finden Sie unter Eltern- und Kindfunktionen.
Datentypen von Spalten
Der Datentyp für die Spalte "von" und "zu" der Beziehung sollte identisch sein. Das Arbeiten mit Beziehungen, die in DateTime-Spalten definiert sind, verhält sich möglicherweise nicht wie erwartet. Das Modul, das Power BI-Daten speichert, verwendet nur DateTime-Datentypen ; Datentypen "Datum", " Uhrzeit" und " Datum/Uhrzeit/Zeitzone" sind Power BI-Formatierungskonstrukte, die oben implementiert werden. Alle modellabhängigen Objekte werden weiterhin als DateTime im Modul angezeigt (z. B. Beziehungen, Gruppen usw.). Wenn ein Benutzer beispielsweise Date auf der Registerkarte Modellierung für solche Spalten auswählt, wird es immer noch nicht als das gleiche Datum registriert, da der Zeitanteil der Daten weiterhin von der Engine berücksichtigt wird. Erfahren Sie mehr darüber, wie Datums-/Uhrzeittypen behandelt werden. Um das Verhalten zu korrigieren, sollten die Spaltendatentypen im Power Query-Editor aktualisiert werden, um den Zeitteil aus den importierten Daten zu entfernen. Wenn das Modul die Daten verarbeitet, werden die Werte also gleich angezeigt.
Kardinalität
Jede Modellbeziehung wird durch einen Kardinalitätstyp definiert. Es gibt vier Kardinalitätstypoptionen, die die Dateneigenschaften der „von“- und „zu“-verknüpften Spalten darstellen. Die „one“-Seite bedeutet, dass die Spalte eindeutige Werte enthält; die „many“-Seite bedeutet, dass die Spalte doppelte Werte enthalten kann.
Hinweis
Wenn bei einer Datenaktualisierung versucht wird, doppelte Werte in eine „Eins“-Seiten-Spalte zu laden, wird die gesamte Datenaktualisierung nicht durchgeführt.
Die vier Optionen werden zusammen mit ihren Kurzhandnotationen in der folgenden Liste beschrieben:
- Eine-zu-vielen (1:*)
- Viele-zu-einer (*:1)
- Eins-zu-eins (1:1)
- Viele-zu-vielen (*:*)
Wenn Sie in Power BI Desktop eine Beziehung erstellen, erkennt der Designer den Kardinalitätstyp automatisch und legt ihn fest. Power BI Desktop fragt das Modell ab, um zu ermitteln, welche Spalten eindeutige Werte enthalten. Für Importmodelle werden interne Speicherstatistiken verwendet; für DirectQuery-Modelle sendet es Profilerstellungsabfragen an die Datenquelle. Manchmal können dabei aber in Power BI Desktop Fehler auftreten. Das kann passieren, wenn Tabellen noch mit Daten geladen werden müssen oder wenn Spalten, von denen Sie erwarten, dass sie doppelte Werte enthalten, derzeit eindeutige Werte enthalten. In beiden Fällen können Sie den Kardinalitätstyp aktualisieren, sofern alle Spalten der 1-Seite eindeutige Werte enthalten (oder noch Datenzeilen in die Tabelle geladen werden müssen).
Kardinalität Eine-zu-vielen (und viele-zu-einer)
Die Kardinalitätsoptionen eins-zu-vielen und vielen-zu-einem sind im Grunde identisch. Zudem sind sie die am häufigsten vorkommenden Kardinalitätstypen.
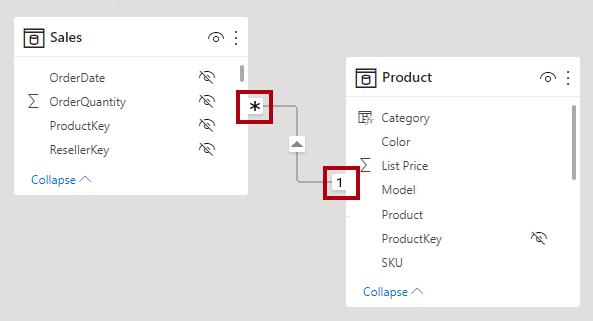
Wenn Sie eine 1:n- oder n:1-Beziehung konfigurieren, wählen Sie die Relation aus, die der Reihenfolge entspricht, in der Sie die Spalten verknüpft haben. Überlegen Sie, wie Sie die Beziehung zwischen der Tabelle Product und der Tabelle Sales mithilfe der in beiden Tabellen vorhandenen Spalte ProductID konfigurieren würden. Der Kardinalitätstyp wäre Eine-zu-vielen , da die Spalte ProductID in der Tabelle Product eindeutige Werte enthält. Wenn Sie die Tabellen in umgekehrter Richtung verknüpft haben, von Verkäufe zu Produkt, wäre die Kardinalität Viele-zu-Eins.
Eine-zu-eine-Kardinalität
Eine 1:1-Beziehung bedeutet, dass beide Spalten eindeutige Werte enthalten. Dieser Kardinalitätstyp ist nicht gängig und weist aufgrund der Speicherung redundanter Daten eher auf einen suboptimalen Modellentwurf hin.
Weitere Informationen zur Verwendung dieses Kardinalitätstyps finden Sie im Leitfaden zu 1:1-Beziehungen.
Viele-zu-vielen-Kardinalität
Eine m:n-Beziehung bedeutet, dass beide Spalten doppelte Werte enthalten können. Dieser Kardinalitätstyp wird selten verwendet. Er ist in der Regel nützlich, wenn komplexe Modellanforderungen entworfen werden. Sie können es verwenden, um viele-zu-vielen-Fakten zu verknüpfen oder höhere Korndaten zu verknüpfen. Wenn z. B. Verkaufszieldaten auf Produktkategorieebene gespeichert werden und die Produktdimensionstabelle auf Produktebene gespeichert wird.
Hinweise zur Verwendung dieses Kardinalitätstyps finden Sie unter Leitfaden zu Eine-zu-vielen-Beziehungen.
Hinweis
Der viele -zu-vielen-Kardinalitätstyp wird für Modelle, die für den Power BI-Berichtsserver entwickelt werden ab Januar 2024 unterstützt.
Tipp
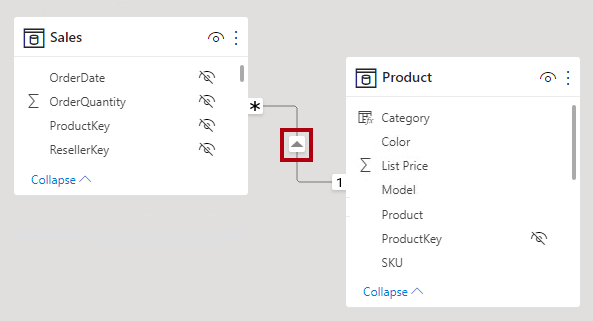
In der Power-BI-Desktop-Modellansicht können Sie den Kardinalitätstyp einer Beziehung interpretieren, indem Sie sich die Indikatoren (1 oder *) auf beiden Seiten der Beziehungslinie ansehen. Um zu bestimmen, welche Spalten verknüpft sind, markieren oder zeigen Sie mit dem Mauszeiger auf die Beziehungslinie, um die Spalten hervorzuheben.
Kreuzfilterrichtung
Jede Modellbeziehung wird mit einer Kreuzfilterrichtung definiert. Ihre Auswahl bestimmt die Richtungen, in denen die Filter weitergegeben werden. Die möglichen Kreuzfilteroptionen sind vom Kardinalitätstyp abhängig.
| Kardinalitätstyp | Kreuzfilteroptionen |
|---|---|
| Eine-zu-vielen (oder Viele-zu-einer) | Ledig Beide |
| 1:1 | Beide |
| Viele-zu-vielen | Einzeln (Tabelle1 zu Tabelle2) Einzeln (Tabelle2 zu Tabelle1) Beide |
Einfache Kreuzfilterrichtung bedeutet "Eine Richtung", und Beides bedeutet "beide Richtungen". Eine Beziehung, die in beide Richtungen filtert, wird häufig als bidirektional beschrieben.
Bei Eine-zu-vielen-Beziehungen verläuft die Kreuzfilterrichtung immer von der „Eins“-Seite und optional von der „Viele“-Seite (bidirektional). Bei 1:1-Beziehungen verläuft die Kreuzfilterrichtung immer von beiden Tabellen aus. Schließlich kann für viele-zu-viele Beziehungen die Kreuzfilterrichtung entweder von einer der Tabellen oder von beiden ausgehen. Beachten Sie: Wenn der Kardinalitätstyp eine „Eins“-Seite enthält, werden Filter immer von dieser Seite weitergegeben.
Wenn die Kreuzfilterrichtung auf "Beide" festgelegt ist, wird eine andere Eigenschaft verfügbar. Es kann eine bidirektionale Filterung anwenden, wenn Power BI Sicherheitsregeln auf Zeilenebene (RLS) durchsetzt. Weitere Informationen zu RLS finden Sie unter Sicherheit auf Zeilenebene (RLS) mit Power BI Desktop.
Mithilfe einer Modellberechnung können Sie die Kreuzfilterrichtung einer Beziehung ändern, einschließlich der Deaktivierung der Filterverteilung. Sie wird mithilfe der FUNKTION CROSSFILTER DAX erreicht.
Denken Sie daran, dass bidirektionale Beziehungen negative Auswirkungen auf die Leistung haben können. Außerdem kann der Versuch, eine bidirektionale Beziehung zu konfigurieren, zu mehrdeutigen Filterweitergabe-Pfaden führen. In diesem Fall kann Power BI Desktop die Beziehungsänderung nicht übernehmen und Sie mit einer Fehlermeldung benachrichtigen. In einigen Fällen können Sie in Power BI Desktop jedoch möglicherweise mehrdeutige Beziehungspfade zwischen Tabellen definieren. Das Auflösen von Beziehungspfaddeutigkeiten wird weiter unten in diesem Artikel beschrieben.
Sie sollten die bidirektionale Filterung nur bei Bedarf verwenden. Weitere Informationen finden Sie im Leitfaden zu bidirektionalen Beziehungen.
Tipp
In der Power BI Desktop-Modellansicht können Sie die Kreuzfilterrichtung einer Beziehung interpretieren, indem Sie die Pfeilspitzen entlang der Beziehungslinie notieren. Eine einzelne Pfeilspitze stellt einen in Richtung der Pfeilspitze verlaufenden Einzelrichtungsfilter dar; eine doppelte Pfeilspitze stellt eine bidirektionale Beziehung dar.
Diese Beziehung aktiv machen
Zwischen zwei Modelltabellen kann nur ein einziger aktiver Filterweitergabe-Pfad vorhanden sein. Es ist jedoch möglich, zusätzliche Beziehungspfade einzuführen, obwohl Sie diese Beziehungen als inaktiv festlegen müssen. Inaktive Beziehungen können nur während der Auswertung einer Modellberechnung aktiviert werden. Sie wird mithilfe der DAX-Funktion USERELATIONSHIP erreicht.
Im Allgemeinen wird empfohlen, nach Möglichkeit aktive Beziehungen zu definieren. Sie erweitern den Umfang und das Potenzial, wie Berichtsautoren Ihr Modell verwenden können. Die Verwendung nur aktiver Beziehungen bedeutet, dass Rollenspieldimensionstabellen in Ihrem Modell dupliziert werden sollen.
Unter bestimmten Umständen können Sie jedoch eine oder mehrere inaktive Beziehungen für eine Dimensionstabelle mit unterschiedlichen Rollen definieren. Erwägen Sie diesen Entwurf in den folgenden Fällen:
- Es ist nicht erforderlich, Berichtsvisuals gleichzeitig nach unterschiedlichen Rollen zu filtern.
- Sie verwenden die DAX-Funktion
USERELATIONSHIP, um eine bestimmte Beziehung für relevante Modellberechnungen zu aktivieren.
Weitere Informationen finden Sie unter Aktive und inaktive Beziehungen im Vergleich – Leitfaden.
Tipp
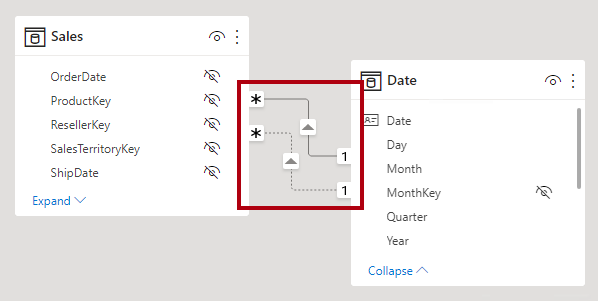
In der Power BI Desktop-Modellansicht können Sie den aktiven oder inaktiven Status einer Beziehung interpretieren. Eine durchgezogene Linie stellt eine aktive Beziehung dar, und eine gestrichelte Linie stellt eine inaktive Beziehung dar.
Referenzielle Integrität voraussetzen
Die Eigenschaft Referentielle Integrität annehmen ist nur für eine -zu-viele- und eine-zu-eine-Beziehungen zwischen zwei DirectQuery-Speichermodustabellen verfügbar, die derselben Quellgruppe angehören. Sie können diese Eigenschaft nur aktivieren, wenn die "viele"-Seitenspalte keine NULL-Werte enthält.
Wenn es aktiviert ist, werden die beiden Tabellen durch native Abfragen, die an die Datenquelle gesendet werden, mit einem INNER JOIN statt einem OUTER JOIN verknüpft. Die Abfrageleistung wird mit Aktivierung dieser Eigenschaft somit generell verbessert, obwohl dies von den Besonderheiten der Datenquelle abhängt.
Aktivieren Sie diese Eigenschaft immer, wenn zwischen den beiden Tabellen eine Einschränkung des Fremdschlüssels der Datenbank vorhanden ist. Selbst wenn keine Fremdschlüsseleinschränkung vorhanden ist, sollten Sie die Aktivierung der Eigenschaft in Betracht ziehen, sofern Sie sicher sind, dass die Datenintegrität gegeben ist.
Wichtig
Wenn die Datenintegrität kompromittiert wird, wird der INNER JOIN nicht übereinstimmende Zeilen zwischen den Tabellen beseitigen. Betrachten Sie z. B. eine Modell-Verkaufstabelle mit einem ProductID-Spaltenwert , der in der verknüpften Produkttabelle nicht vorhanden war. Die Filterverteilung aus der Tabelle " Artikel " in die Tabelle " Vertrieb " beseitigt Verkaufszeilen für unbekannte Produkte, was zu einer Unterbewertung der Verkaufsergebnisse führt.
Weitere Informationen finden Sie unter Einstellungen für „Referenzielle Integrität voraussetzen“ in Power BI Desktop.
Relevante DAX-Funktionen
Es gibt mehrere DAX-Funktionen, die für Modellbeziehungen relevant sind. Jede Funktion wird kurz in der folgenden Liste beschrieben:
- Die Funktion RELATEDruft den Wert der „eins“-Seite einer Beziehung ab. Es ist nützlich, wenn Berechnungen aus verschiedenen Tabellen einbezogen werden, die im Zeilenkontext ausgewertet werden.
- Die Funktion RELATEDTABLEruft den Wert der „viele“-Seite einer Beziehung ab.
- USERELATIONSHIP: Ermöglicht einer Berechnung die Verwendung einer inaktiven Beziehung. (Technisch ändert diese Funktion die Gewichtung einer bestimmten inaktiven Modellbeziehung, die dazu beiträgt, ihre Verwendung zu beeinflussen.) Es ist nützlich, wenn Ihr Modell eine Rollenspieldimensionstabelle enthält, und Sie entscheiden, inaktive Beziehungen aus dieser Tabelle zu erstellen. Sie können diese Funktion auch verwenden, um Mehrdeutigkeit in Filterpfaden aufzulösen.
- CROSSFILTER: Ändert die Beziehungsübergreifende Filterrichtung (in eine oder beide) oder deaktiviert die Filterverteilung (keine). Es ist nützlich, wenn Sie modellbezogene Beziehungen während der Auswertung einer bestimmten Berechnung ändern oder ignorieren müssen.
- COMBINEVALUES: Verknüpft zwei oder mehr Textzeichenfolgen zu einer Textzeichenfolge. Der Zweck dieser Funktion besteht darin, Mehrspaltenbeziehungen in DirectQuery-Modellen zu unterstützen, wenn Tabellen zur selben Quellgruppe gehören.
- TREATAS: Wendet das Ergebnis eines Tabellenausdrucks als Filter auf Spalten aus einer nicht verknüpften Tabelle an. Es ist hilfreich in erweiterten Szenarien, wenn Sie während der Auswertung einer bestimmten Berechnung eine virtuelle Beziehung erstellen möchten.
- Eltern- und Kindfunktionen: Eine Familie verwandter Funktionen, mit denen Sie berechnete Spalten generieren können, um eine Eltern-Kind-Hierarchie zu naturalisieren. Anschließend können Sie dann diese Spalten verwenden, um eine Hierarchie mit festen Ebenen zu erstellen.
Beziehungsauswertung
Modellbeziehungen werden aus Auswertungsperspektive entweder als normal oder eingeschränkt klassifiziert. Es handelt sich nicht um eine konfigurierbare Beziehungseigenschaft. Es wird tatsächlich vom Kardinalitätstyp und der Datenquelle der beiden verknüpften Tabellen abgeleitet. Es ist wichtig, den Auswertungstyp zu verstehen, da es Leistungsauswirkungen oder Folgen geben kann, wenn die Datenintegrität kompromittiert werden sollte. Diese Auswirkungen und Integritätsfolgen werden in diesem Abschnitt beschrieben.
Zuerst ist eine Modellierungstheorie erforderlich, um Beziehungsauswertungen vollständig verstehen zu können.
Ein Import- oder DirectQuery-Modell stellt alle zugehörigen Daten aus dem Vertipaq-Cache oder der Quelldatenbank her. In beiden Fällen kann Power BI bestimmen, ob die „Eins“-Seite einer Beziehung vorhanden ist.
Ein zusammengesetztes Modell kann jedoch Tabellen mit unterschiedlichen Speichermodi (Import, DirectQuery oder Dual) oder mehreren DirectQuery-Quellen umfassen. Jede Quelle, einschließlich des Vertipaq-Caches importierter Daten, wird als Quellgruppe betrachtet. Modellbeziehungen können dann als intra source group oder inter/cross source group klassifiziert werden. Eine innerhalb einer Quellgruppe bestehende Beziehung bezieht sich auf zwei Tabellen, während eine inter- oder quellenübergreifende Gruppenbeziehung sich auf Tabellen in zwei unterschiedlichen Quellgruppen bezieht. Beachten Sie, dass Beziehungen in Import- oder DirectQuery-Modellen immer innerhalb derselben Quellgruppe sind.
Im Folgenden sehen Sie ein Beispiel für ein zusammengesetztes Modell.
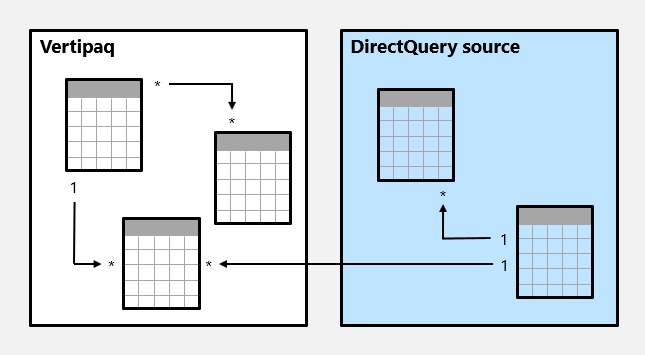
In diesem Beispiel besteht das zusammengesetzte Modell aus zwei Quellgruppen: einer Vertipaq-Quellgruppe und einer DirectQuery-Quellgruppe. Die Vertipaq-Quellgruppe enthält drei Tabellen, und die DirectQuery-Quellgruppe enthält zwei Tabellen. Eine quellübergreifende Gruppenbeziehung besteht darin, eine Tabelle in der Vertipaq-Quellgruppe mit einer Tabelle in der DirectQuery-Quellgruppe zu verknüpfen.
Reguläre Beziehungen
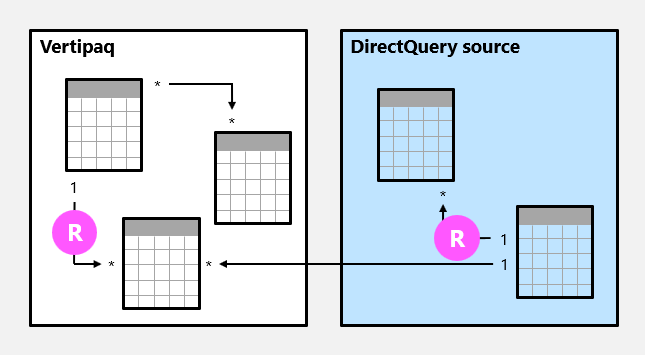
Eine Modellbeziehung ist normal , wenn das Abfragemodul die 1-Seite der Beziehung bestimmen kann. Sie hat die Bestätigung, dass die Spalte der „Eins“-Seite eindeutige Werte enthält. Alle quellgruppeninternen eine-zu-viele-Beziehungen sind reguläre Beziehungen.
Im folgenden Beispiel gibt es zwei reguläre Beziehungen, die beide als R gekennzeichnet sind. Beziehungen umfassen die 1:n-Beziehung, die in der Vertipaq-Quellgruppe enthalten ist, und die 1:n-Beziehung, die in der DirectQuery-Quelle enthalten ist.
Bei Importmodellen, bei denen alle Daten im Vertipaq-Cache gespeichert werden, erstellt Power BI eine Datenstruktur für jede normale Beziehung zur Datenaktualisierungszeit. Die Datenstrukturen bestehen aus indizierten Zuordnungen aller „Spalte-zu-Spalte“-Werte, und sie sollen das Verknüpfen von Tabellen zur Abfragezeit beschleunigen.
Zur Abfragezeit ermöglichen reguläre Beziehungen die Tabellenerweiterung . Die Tabellenerweiterung führt zum Erstellen einer virtuellen Tabelle, indem die nativen Spalten der Basistabelle einbezogen und dann in verknüpfte Tabellen erweitert werden. Bei Importtabellen erfolgt die Tabellenerweiterung im Abfragemodul; für DirectQuery-Tabellen erfolgt dies in der systemeigenen Abfrage, die an die Quelldatenbank gesendet wird (sofern die Angenommen-referentielle Integritätseigenschaft nicht aktiviert ist). Die Abfrage-Engine bearbeitet dann die erweiterte Tabelle, wendet Filter an und führt eine Gruppierung nach den Werten in den Spalten der erweiterten Tabelle durch.
Hinweis
Auch inaktive Beziehungen werden erweitert, selbst wenn sie nicht in einer Berechnung verwendet werden. Bidirektionale Beziehungen haben keine Auswirkung auf die Erweiterung der Tabelle.
Bei eine-bis-viele-Beziehungen erfolgt die Tabellenerweiterung von der „viele“ auf die „eine“-Seiten mithilfe von LEFT OUTER JOIN Semantik. Wenn ein übereinstimmender Wert von der „Viele“-Seite zur „Eins“-Seite nicht existiert, wird der Tabelle auf der „Eins“-Seite eine leere virtuelle Zeile hinzugefügt. Dieses Verhalten gilt nur für reguläre Beziehungen, nicht für eingeschränkte Beziehungen.
Die Tabellenerweiterung wird auch für quellgruppeninterne 1:1-Beziehungen durchgeführt, jedoch mithilfe der FULL OUTER JOIN-Semantik. Dieser Join-Typ stellt sicher, dass, falls nötig, auf beiden Seiten leere virtuelle Zeilen hinzugefügt werden.
Leere virtuelle Zeilen sind effektiv unbekannte Elemente. Unbekannte Mitglieder stellen Verstöße gegen die referenzielle Integrität dar. Dies tritt auf, wenn der Wert auf der Seite 'Viele' keinen entsprechenden Wert auf der Seite 'Eins' hat. Im Idealfall sollten diese Leerzeichen nicht vorhanden sein. Sie können durch Bereinigung oder Reparatur der Quelldaten entfernt werden.
Hier erfahren Sie, wie die Tabellenerweiterung mit einem animierten Beispiel funktioniert.

In diesem Beispiel besteht das Modell aus drei Tabellen: Category, Product und Sales. Die Tabelle Kategorie bezieht sich auf die Tabelle Produkt mit einer 1:n-Beziehung, und die Tabelle Produkt bezieht sich auf die Tabelle Umsatz mit einer 1:n-Beziehung. Die Tabelle Category enthält zwei Zeilen, die Tabelle Product drei Zeilen und die Tabelle Sales fünf Zeilen. Es gibt übereinstimmende Werte auf beiden Seiten aller Beziehungen, was bedeutet, dass es keine Verletzungen der referenziellen Integrität gibt. Eine erweiterte Tabelle zur Abfragezeit wird angezeigt. Die Tabelle besteht aus den Spalten aller drei Tabellen. Es handelt sich tatsächlich um eine denormalisierte Perspektive der in den drei Tabellen enthaltenen Daten. Der Sales-Tabelle wird eine neue Zeile hinzugefügt, und sie verfügt über einen Produktionsbezeichnerwert (9), für den es keine Übereinstimmung in der Product-Tabelle gibt. Dies ist ein Verstoß gegen die referenzielle Integrität. In der erweiterten Tabelle enthält die neue Zeile (leere) Werte für die Tabellenspalten Category und Product.
Eingeschränkte Beziehungen
Eine Modellbeziehung ist begrenzt , wenn keine garantierte "1"-Seite vorhanden ist. Eine eingeschränkte Beziehung kann aus zwei Gründen entstehen:
- Die Beziehung verwendet einen viele-zu-viele-Kardinalitätstyp (auch wenn eine oder beide Spalten eindeutige Werte enthalten).
- Die Beziehung ist quellgruppenübergreifend (was überhaupt nur bei zusammengesetzten Modellen der Fall sein kann).
Im folgenden Beispiel gibt es zwei eingeschränkte Beziehungen, die beide mit L gekennzeichnet sind. Zu den beiden Beziehungen gehören die in der Vertipaq-Quellgruppe enthaltene viele-zu-viele-Beziehung und die quellgruppenübergreifende 1:n-Beziehung.
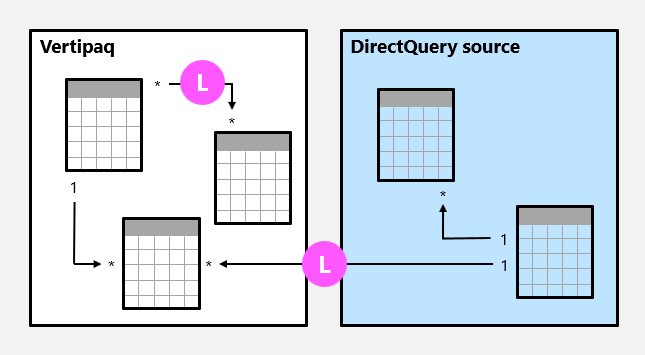
Bei Importmodellen werden für eingeschränkte Beziehungen nie Datenstrukturen erstellt. In diesem Fall löst Power BI Tabellenverknüpfungen zur Abfragezeit auf.
Tabellenerweiterungen werden nie für eingeschränkte Beziehungen durchgeführt. Tabellenverknüpfungen werden mithilfe der INNER JOIN-Semantik erreicht, und deshalb werden keine leeren virtuellen Zeilen hinzugefügt, um referentielle Integritätsverletzungen auszugleichen.
Es gibt weitere Einschränkungen im Zusammenhang mit eingeschränkten Beziehungen:
- Die
RELATEDDAX-Funktion kann nicht verwendet werden, um die "einseitigen" Spaltenwerte abzurufen. - Das Erzwingen von RLS unterliegt Topologieeinschränkungen.
Tipp
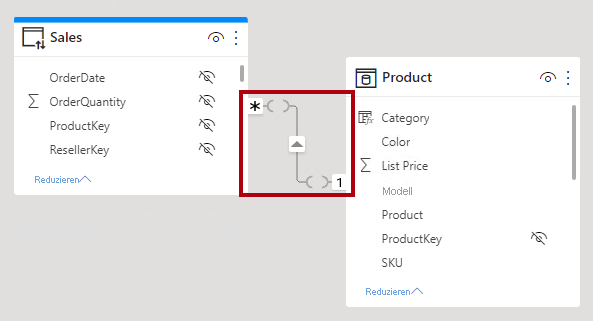
In der Power BI Desktop-Modellansicht können Sie eine Beziehung als eingeschränkt interpretieren. Eine begrenzte Beziehung wird nach den Kardinalitätsindikatoren mit Klammern () dargestellt.
Beseitigung von Unklarheiten im Beziehungspfad
Bidirektionale Beziehungen können mehrere – und somit mehrdeutige – Filterweitergabepfade zwischen Modelltabellen einführen. Wenn sie Mehrdeutigkeit auswertet, wählt Power BI den Filterverteilungspfad entsprechend ihrer Priorität und Gewichtung aus.
Priorität
Prioritätsebenen definieren eine Abfolge von Regeln, die Power BI verwendet, um die Mehrdeutigkeit des Beziehungspfads aufzulösen. Die erste Regel übereinstimmung bestimmt den Pfad, dem Power BI folgt. In der folgenden Sequenz beschreibt jede Regel, wie Filter von einer Quelltabelle zu einer Zieltabelle fließen.
- Ein Pfad, der aus eine-zu-vielen-Beziehungen besteht.
- Ein Pfad, der aus eine-zu-vielen- oder viele-zu-vielen-Beziehungen besteht.
- Ein Pfad, der aus viele-zu-eins-Beziehungen besteht.
- Ein Pfad, der aus eins-zu-viele-Beziehungen von der Quelltabelle zu einer Zwischentabelle besteht, denen viele-zu-eins-Beziehungen von der Zwischentabelle zur Zieltabelle folgen.
- Ein Pfad, der aus eine-zu-vielen- oder viele-zu-vielen-Beziehungen von der Quelltabelle zu einer Zwischentabelle besteht, gefolgt von vielen-zu-einer- oder viele-zu-vielen-Beziehungen von der Zwischentabelle zur Zieltabelle.
- Jeder andere Pfad.
Wenn eine Beziehung in allen verfügbaren Pfaden enthalten ist, wird sie aus der Betrachtung in allen Pfaden entfernt.
Gewichtung
Jede Beziehung in einem Pfad weist eine Gewichtung auf. Standardmäßig ist jede Beziehungsgewichtung gleich, es sei denn, die FUNKTION USERELATIONSHIP wird verwendet. Die Pfadstärke ist das Maximum aller Beziehungsgewichtungen entlang des Pfads. Power BI verwendet die Pfadstärken, um Mehrdeutigkeit zwischen mehreren Pfaden auf derselben Prioritätsebene aufzulösen. Er wählt keinen Pfad mit einer niedrigeren Priorität aus, aber er wählt den Pfad mit der höheren Gewichtung aus. Die Anzahl der Beziehungen im Pfad wirkt sich nicht auf die Gewichtung aus.
Sie können die Gewichtung einer Beziehung mithilfe der FUNKTION USERELATIONSHIP beeinflussen. Die Gewichtung wird durch die Schachtelungsebene des Aufrufs dieser Funktion bestimmt, wobei der innerste Aufruf die höchste Gewichtung erhält.
Betrachten Sie das folgende Beispiel. Das Measure "Product Sales " weist der Beziehung zwischen Sales[ProductID] und Product[ProductID], gefolgt von der Beziehung zwischen Inventory[ProductID] und Product[ProductID], eine höhere Gewichtung zu.
Product Sales =
CALCULATE(
CALCULATE(
SUM(Sales[SalesAmount]),
USERELATIONSHIP(Sales[ProductID], Product[ProductID])
),
USERELATIONSHIP(Inventory[ProductID], Product[ProductID])
)
Hinweis
Wenn Power BI mehrere Pfade erkennt, die dieselbe Priorität und die gleiche Gewichtung aufweisen, wird ein mehrdeutiger Pfadfehler zurückgegeben. In diesem Fall müssen Sie die Mehrdeutigkeit auflösen, indem Sie die Beziehungsgewichte mithilfe der USERELATIONSHIP-Funktion beeinflussen oder Modellbeziehungen entfernen oder ändern.
Leistungspräferenz
Die folgende Liste ordnet die Filterweitergabegeschwindigkeit von der schnellsten zur langsamsten Leistung.
- Quellgruppeninterne eine-zu-vielen-Beziehungen
- Viele-zu-vielen-Modellbeziehungen, die mit einer zwischengeschalteten Tabelle erzielt wurden und mindestens eine bidirektionale Beziehung umfassen
- Viele-zu-viele-Kardinalitätsbeziehungen
- quellgruppenübergreifende Beziehungen
Verwandte Inhalte
Weitere Informationen zu diesem Beitrag finden Sie in den folgenden Ressourcen:
- Verstehen Sie das Sternschema und seine Bedeutung für Power BI
- Leitfaden zu 1:1-Beziehungen
- Leitfaden zu Viele-zu-vielen-Beziehungen
- Aktive und inaktive Beziehungen im Vergleich – Leitfaden
- Leitfaden zu bidirektionalen Beziehungen
- Leitfaden zur Problembehandlung bei Beziehungen
- Video: Die Dos und Don'ts von Power BI-Beziehungen
- Haben Sie Fragen? Versuchen Sie, die Power BI Community um Rat zu fragen
- Vorschläge? Einbringen von Ideen zur Verbesserung von Power BI