Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR:![]() Power BI Desktop
Power BI Desktop ![]() Power BI-Dienst
Power BI-Dienst
Die Schlüssel-Influencer-Visualisierung hilft Ihnen, die Faktoren zu verstehen, die eine Metrik beeinflussen, die Sie interessiert. Es analysiert die Daten, erstellt eine Rangfolge für wichtige Faktoren und stellt diese dar. Angenommen, Sie möchten ermitteln, wodurch die Personalfluktuation oder Abwanderung beeinflusst wird. Faktoren können z. B. die Länge des Anstellungsvertrags oder die Anfahrtszeit des Mitarbeiters sein.
Dieser Artikel bietet eine Schritt-für-Schritt-Anleitung zur Verwendung des Schlüssel-Beitraggeber-Visuals in Power BI. Es wird erläutert, wie Sie das visuelle Element einrichten, die Ergebnisse interpretieren und häufige Probleme beheben. Wenn Sie verstehen möchten, welche Faktoren bestimmte Ergebnisse in Ihren Daten fördern, z. B. Kundenfeedback, Vertrieb oder andere Metriken, hilft Ihnen dieses Handbuch, umsetzbare Einblicke mithilfe der KI-basierten Analysetools von Power BI zu erhalten.
Wann empfiehlt sich die Verwendung des Visuals „Wichtige Einflussfaktoren“?
Das "Key Influencers"-Visual ist eine hervorragende Wahl, wenn Sie:
- Zur Übersicht über die Faktoren, die sich auf die analysierte Metrik auswirken.
- Stellen Sie die relative Wichtigkeit dieser Faktoren gegenüber. z. B. bei der Frage, ob Kurzzeitverträge sich stärker als Langzeitverträge auf die Fluktuation auswirken.
Features des Visuals „Wichtige Einflussfaktoren“
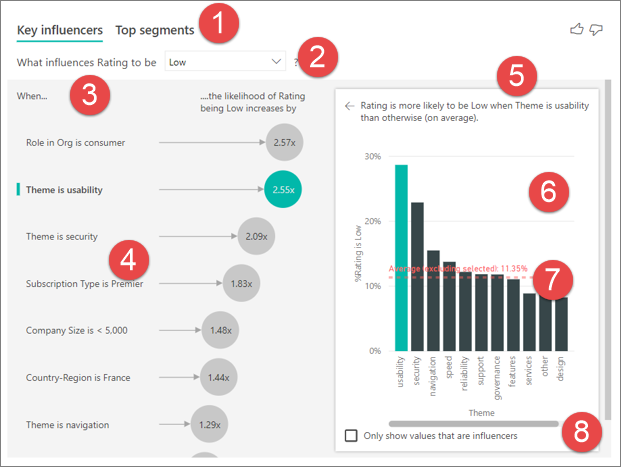
Registerkarten: Wählen Sie eine Registerkarte aus, und wechseln Sie zwischen Ansichten. Wichtige Influencer zeigen Ihnen die wichtigsten Mitwirkenden zum ausgewählten Metrikwert an. Die obersten Segmente zeigen die obersten Segmente an, die zum ausgewählten Metrikwert beitragen. Ein Segment besteht aus einer Kombination von Werten. Ein Segment kann beispielsweise Verbraucher sein, die langfristige Kunden sind und in der Westregion leben.
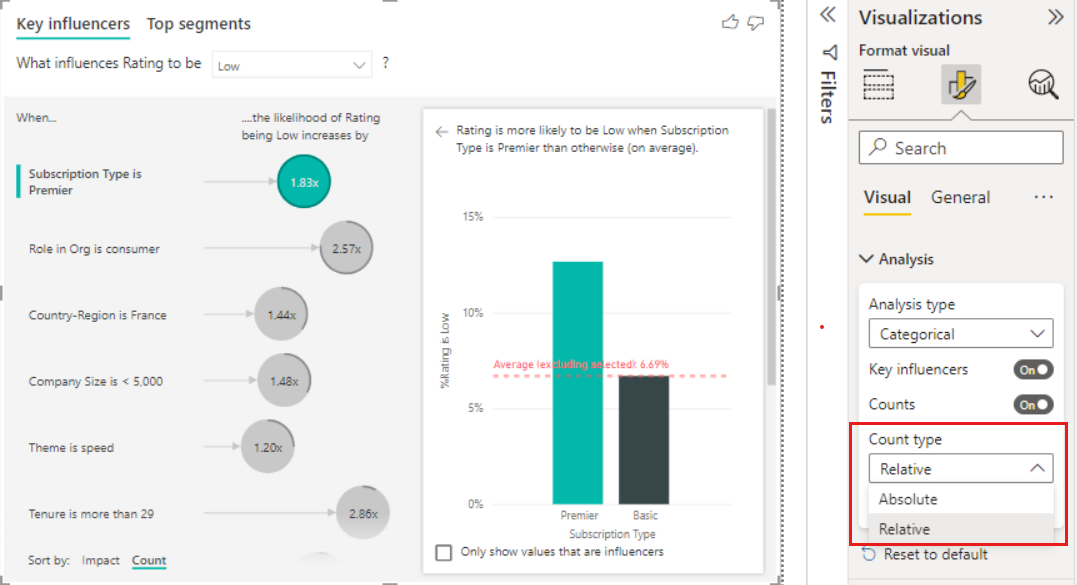
Dropdown-Menü: Der Wert der Metrik, die untersucht wird. Sehen Sie sich in diesem Beispiel die Metrik Rating an. Der ausgewählte Wert ist Niedrig.
Restatement: Es hilft Ihnen, die Visualisierung im linken Fenster zu interpretieren.
Linker Bereich: Der linke Bereich enthält ein visuelles Element. In diesem Fall zeigt der linke Bereich eine Liste der wichtigsten Einflussfaktoren.
Revision: unterstützt Sie beim Interpretieren des Visuals im rechten Bereich
Rechter Bereich: Der rechte Bereich enthält ein visuelles Element. In diesem Fall zeigt das Säulendiagramm alle Werte für das Schlüsselthema Einflussfaktoren an, das im linken Bereich ausgewählt wurde. Der spezifische Wert der Benutzerfreundlichkeit aus dem linken Bereich wird grün angezeigt. Alle anderen Werte für Design werden schwarz angezeigt.
Durchschnittliche Linie: Der Mittelwert wird für alle möglichen Werte für Thema mit Ausnahme von Benutzerfreundlichkeit (welche der ausgewählte Influencer ist) berechnet. Die Berechnung gilt also für alle schwarz dargestellten Werte. Es zeigt an, welcher Prozentsatz der anderen Themen eine niedrige Bewertung hatte. In diesem Fall hatten 11,35 % eine niedrige Bewertung (dargestellt durch die gepunktete Linie).
Kontrollkästchen: Filtert das visuelle Element im rechten Bereich, um nur Werte anzuzeigen, die als Einflussfaktoren für dieses Feld dienen.
Analysieren einer kategorischen Metrik
- Ihr Produkt-Manager möchte, dass Sie ermitteln, welche Faktoren dazu führen, dass Kunden negative Bewertungen zu Ihrem Clouddienst abgeben. Um in Power BI Desktop zu folgen, öffnen Sie die PBIX-Datei "Kundenfeedback".
Hinweis
Das Customer Feedback-Dataset basiert auf dem Werk [Moro et al., 2014] S. Moro, P. Cortez und P. Rita. "Ein Data-Driven Ansatz, um den Erfolg der Bank Telemarketing vorherzusagen." Decision Support Systems, Elsevier, 62:22-31, Juni 2014.
Wählen Sie im Bereich Visualisierungen unter Visualisierungen erstellen das Symbol Key Influencers aus.
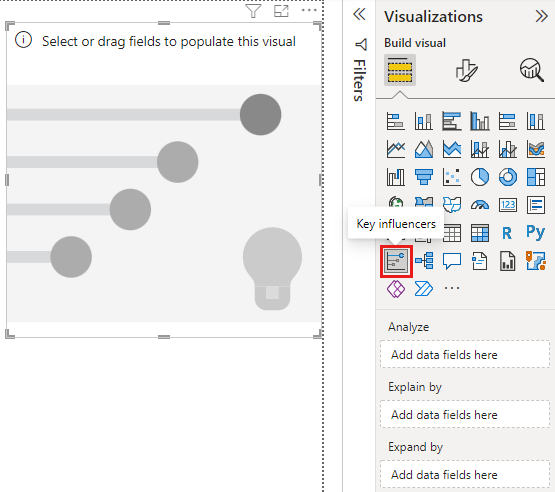
Verschieben Sie die Metrik, die Sie untersuchen möchten, in das Feld "Analysieren ". Wählen Sie Kundentabelle>Bewertung aus, um zu sehen, was eine Kundenbewertung des Dienstes als niedrig antreibt.
Verschieben Sie die Felder, von denen Sie denken, dass sie die Bewertung beeinflussen könnten, in das Feld Erläutern nach. Sie können beliebig viele Felder verschieben. Beginnen Sie in diesem Beispiel mit den folgenden Feldern:
- Land/Region
- Role in Org (Rolle in der Organisation)
- Subscription Type (Abonnementtyp)
- Company Size (Unternehmensgröße)
- Design
Lassen Sie das Feld Expand by leer. Dieses Feld wird nur beim Analysieren einer Maßnahme oder eines zusammengefassten Feldes verwendet.
Um sich auf die negativen Bewertungen zu konzentrieren, wählen Sie Niedrig im Dropdownfeld Einfluss auf die Bewertung aus.
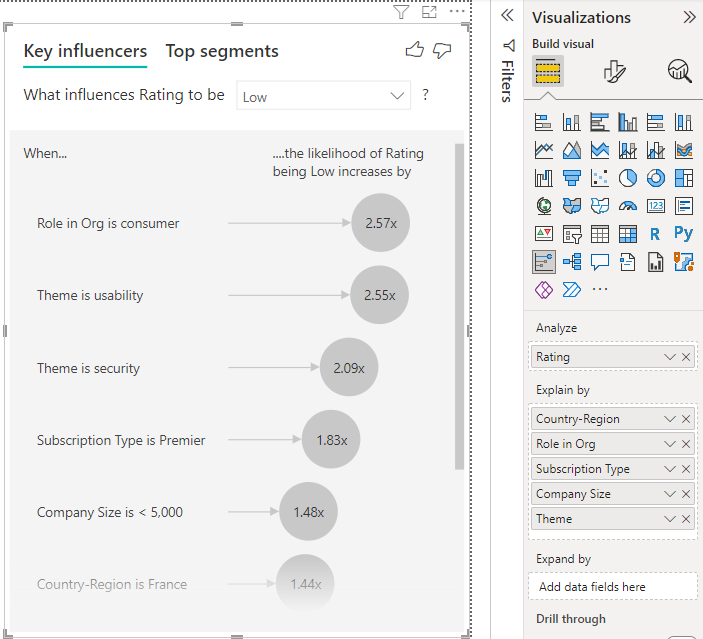
Die Analyse wird auf Tabellenebene des entsprechenden Felds ausgeführt. In diesem Fall handelt es sich um die Bewertungsmetrik . Diese Metrik wird auf Kundenebene definiert. Jeder Kunde gibt entweder eine hohe oder eine niedrige Bewertung. Alle erläuternden Faktoren müssen auf Kundenebene definiert werden, damit das Visual sie verwenden kann.
Im obigen Beispiel weisen alle erläuternden Faktoren eine 1:1- oder eine n:1-Beziehung zur Metrik auf. In diesem Fall hat jeder Kunde seiner Bewertung ein einzelnes Thema zugewiesen. Gleichermaßen stammen die Kunden aus einem Land oder einer Region, weisen einen Mitgliedschaftstyp auf und haben eine Rolle in der Organisation inne. Bei den erläuternden Faktoren handelt es sich um bereits vorhandenen Attribute eines Kunden, sodass keine Transformation nötig ist. Das Visual kann sie direkt verwenden.
Im Verlauf des Tutorials werden komplexere Beispiele mit 1:n-Beziehungen behandelt. In solchen Fällen müssen Spalten zunächst auf Kundenebene aggregiert werden, bevor die Analyse ausgeführt werden kann.
Maße und Aggregate, die als erklärende Faktoren verwendet werden, werden auch auf Tabellenebene der Analyse-Metrik ausgewertet. Im weiteren Verlauf des Artikels finden Sie hierfür Beispiele.
Interpretieren von kategorischen wichtigen Einflussfaktoren
Nun sehen wir uns die wichtigsten Einflussfaktoren für niedrige Bewertungen genauer an.
Wichtigster Einzelaspekt, der höchstwahrscheinlich zu einer niedrigen Bewertung führt
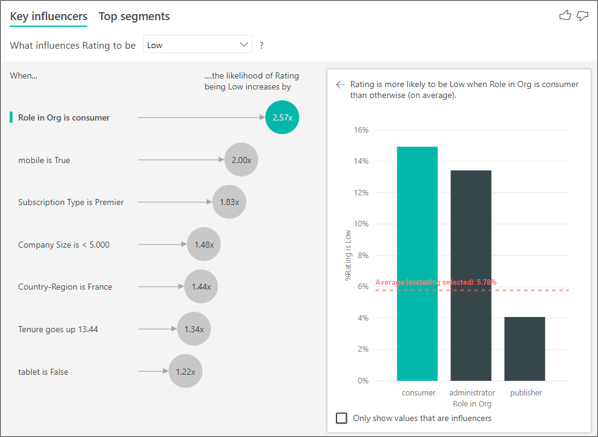
Der Kunde in diesem Beispiel kann eine von drei Rollen haben: Consumer, Administrator oder Herausgeber. Konsument zu sein, ist der wichtigste Faktor, der zu einer niedrigen Bewertung beiträgt.
Genauer gesagt ist es 2,57-mal wahrscheinlicher, dass ein Verbraucher eine negative Bewertung zu Ihrem Dienst abgibt. Im Diagramm „Wichtige Einflussfaktoren“ wird Rolle in der Organisation ist Verbraucher auf der linken Seite ganz oben aufgeführt. Wenn Sie Rolle in der Organisation ist Verbraucher auswählen, werden im rechten Bereich von Power BI weitere Details angezeigt. Die vergleichende Wirkung der einzelnen Rollen auf die Wahrscheinlichkeit einer niedrigen Bewertung wird angezeigt.
- 14,93 % der Verbraucher geben eine niedrige Bewertung ab.
- Im Durchschnitt geben alle anderen Rollen in 5,78 % der Fälle eine niedrige Bewertung ab.
- Die Wahrscheinlichkeit, dass Verbraucher eine im Vergleich zu anderen Rollen niedrigere Bewertung abgeben, ist 2,57-mal höher. Dieser Wert kann ermittelt werden, indem Sie den grünen Balken durch die rot gestrichelte Linie dividieren.
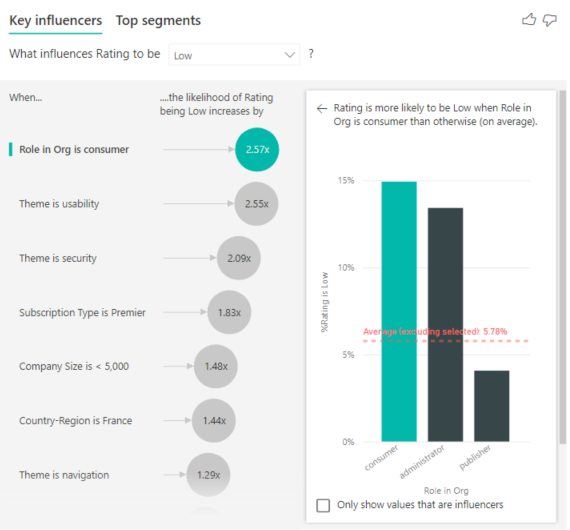
Zweiter Einzelaspekt, der die Wahrscheinlichkeit einer niedrigen Bewertung beeinflusst
Mit dem Visual „Wichtige Einflussfaktoren“ können die Faktoren aus vielen verschiedenen Variablen verglichen und nach Rangfolge sortiert werden. Der zweitgrößte Einflussfaktor unterscheidet sich sehr von Rolle in der Organisation. Wählen Sie in der Liste den zweitgrößten Einflussfaktor aus: Thema ist gleich Benutzerfreundlichkeit.
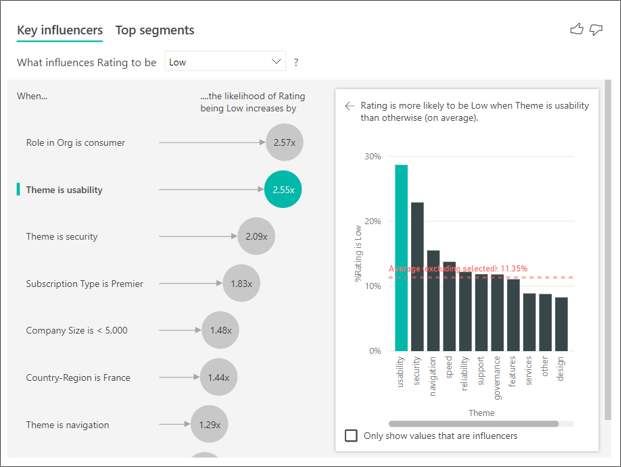
Der zweitwichtigste Faktor bezieht sich auf das Thema der Kundenbewertung. Verbraucher, die Feedback zur Benutzerfreundlichkeit des Produkts abgegeben haben, haben 2,55-mal wahrscheinlicher eine schlechte Bewertung abgegeben als Kunden, die Feedback zu den Themen Zuverlässigkeit, Design oder Geschwindigkeit abgegeben haben.
Zwischen den Visualisierungen hat sich der durch die rot gestrichelte Linie dargestellte Durchschnitt von 5,78 % auf 11,35 % geändert. Der Durchschnittswert ist dynamisch, da er auf dem Durchschnitt aus allen anderen Werten basiert. Beim ersten Einflussfaktor wurde die Verbraucherrolle aus dem Durchschnitt ausgeschlossen. Beim zweiten Einflussfaktor wurde das Thema Benutzerfreundlichkeit ausgeschlossen.
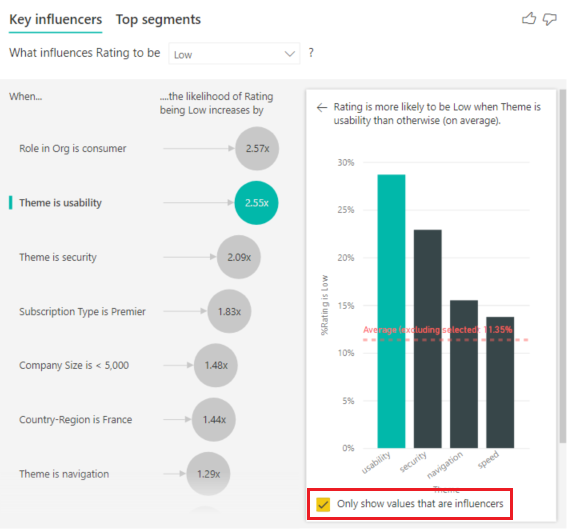
Aktivieren Sie das Kontrollkästchen "Nur Anzeigen von Werten, die Influencer sind ", um die Daten mit nur den einflussreichen Werten zu filtern. In diesem Beispiel sind sie die Rollen, die für eine niedrige Bewertung verantwortlich sind. 12 Themen werden auf die vier reduziert, die Power BI als die Themen identifiziert hat, die niedrige Bewertungen verursachen.
Interaktion mit anderen Visuals
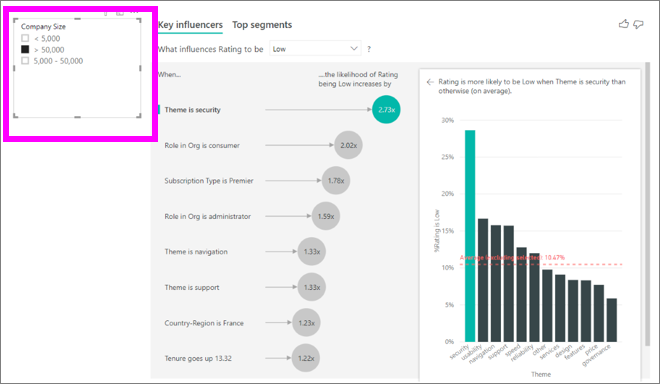
Immer, wenn Sie einen Slicer, einen Filter oder ein anderes Visual im Zeichenbereich auswählen, führt das Visual für wichtige Einflussfaktoren die Analyse für die neu ausgewählten Daten erneut aus. Sie können beispielsweise die Unternehmensgröße in den Bericht verschieben und als Datenschnitt verwenden. Verwenden Sie es, um festzustellen, ob sich die wichtigen Einflussfaktoren für Unternehmenskunden von denen der restlichen Kunden unterscheiden. Die Unternehmensgröße eines Unternehmens liegt bei mehr als 50.000 Mitarbeitern.
Wählen Sie >50.000 aus, um die Analyse erneut auszuführen, und Sie können sehen, dass sich die Influencer geändert haben. Bei großen Unternehmenskunden ist das Thema Sicherheit der wichtigste Einflussfaktor für eine niedrige Bewertung. Sie sollten nun weiter untersuchen, ob es bestimmte Sicherheitsfeatures gibt, mit denen große Kunden nicht zufrieden sind.
Interpretieren Sie kontinuierliche Schlüsseleinflussfaktoren
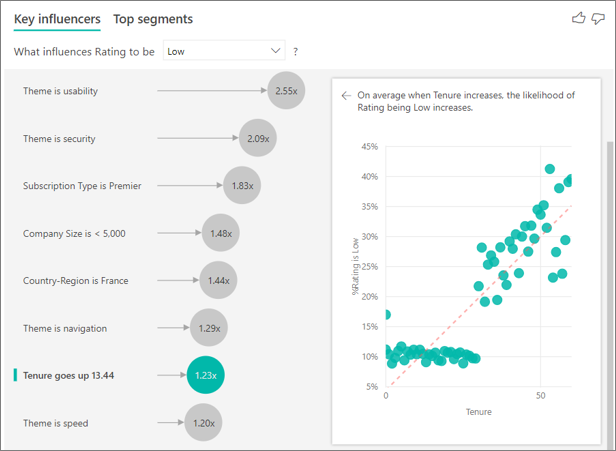
Bisher haben Sie gelernt, wie Sie mithilfe des visuellen Elements untersuchen können, wie verschiedene kategorisierte Felder niedrige Bewertungen beeinflussen. Es ist auch möglich, fortlaufende Faktoren wie Alter, Höhe und Preis im Feld "Erläutern nach " zu haben. Sehen wir uns an, was passiert, wenn Tenure aus der Kundentabelle in "Erklären nach" verschoben wird. Tenure zeigt, wie lange ein Kunde den Dienst nutzt.
Bei einem höheren Wert für „Tenure“ (Verwendungsdauer) steigt die Wahrscheinlichkeit, dass eine niedrige Bewertung abgegeben wird. Dieser Trend lässt darauf schließen, dass Langzeitkunden häufiger eine negative Bewertung abgeben. Diese Information ist interessant. Sie sollten sie später weiterverfolgen.
An der Visualisierung ist zu erkennen, dass mit jedem Anstieg der Betriebszugehörigkeit um 13,44 Monate die Wahrscheinlichkeit einer niedrigen Bewertung im Durchschnitt um das 1,23-Fache steigt. In diesem Fall stellen 13,44 Monate die Standardabweichung der Verwendungsdauer dar. So erhalten Sie einen Einblick, wie eine Erhöhung der Verwendungsdauer um eine Standardmenge, nämlich die Standardabweichung der Verwendungsdauer, die Wahrscheinlichkeit beeinflusst, eine niedrige Bewertung zu erhalten.
Das Punktdiagramm im rechten Bereich zeigt den durchschnittlichen Prozentsatz niedriger Bewertungen für jeden Dienstzeitwert an. Die Steigung wird mit einer Trendlinie hervorgehoben.
Klassifizierte kontinuierliche wichtige Einflussfaktoren
In einigen Fällen stellen Sie möglicherweise fest, dass Ihre fortlaufenden Faktoren automatisch in kategorisierte faktoren umgewandelt wurden. Wenn die Beziehung zwischen den Variablen nicht linear ist, können wir die Beziehung nicht so beschreiben, dass sie einfach zunimmt oder abnimmt (wie im vorherigen Beispiel).
Wir führen Korrelationstests durch, um zu bestimmen, wie linear der Influencer mit dem Ziel verglichen wird. Wenn das Ziel kontinuierlich ist, führen wir Pearson-Korrelation aus; Wenn das Ziel kategorisiert ist, führen wir Punkt-Biserial-Korrelationstests aus. Wenn wir feststellen, dass die Beziehung nicht ausreichend linear ist, führen wir überwachte Binning durch und generieren maximal fünf Container. Um herauszufinden, welche Bins am sinnvollsten sind, verwenden wir eine beaufsichtigte Binning-Methode. Die überwachte Binning-Methode untersucht die Beziehung zwischen dem erklärenden Faktor und dem zu analysierenden Ziel.
Interpretation von Messwerten und Aggregaten als wichtige Einflussfaktoren
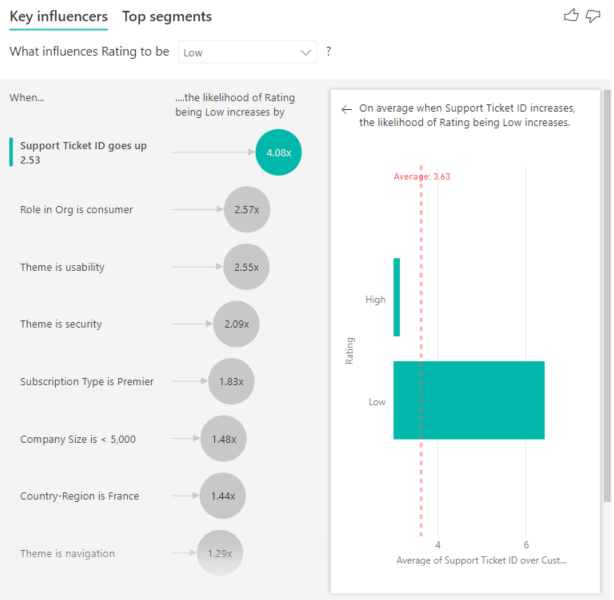
Sie können Maßeinheiten und Aggregationen als erläuternde Faktoren in Ihrer Analyse verwenden. Welche Auswirkungen hat beispielsweise die Anzahl der Kundensupporttickets auf die erhaltenen Bewertung? Oder, welche Auswirkungen hat die durchschnittliche Dauer eines offenen Tickets auf die erhaltene Bewertung?
In diesem Fall möchten Sie sehen, ob die Anzahl der Support-Tickets eines Kunden die von ihm gegebene Bewertung beeinflusst. Jetzt bringen Sie die Supportticket-ID aus der Tabelle "Supporttickets" ein. Da ein Kunde mehrere Supporttickets öffnen kann, aggregieren Sie die ID auf die Kundenebene. Die Aggregation ist wichtig, da die Analyse auf Kundenebene ausgeführt wird, weshalb alle Treiber auf dieser Ebene definiert werden müssen.
Betrachten wir nun die Anzahl der IDs. Jeder Kundenzeile ist eine Anzahl Supporttickets zugeordnet. In diesem Fall steigt mit der Anzahl der Support-Tickets die Wahrscheinlichkeit für eine niedrige Bewertung um das 4,08-fache. Der Screenshot zeigt die durchschnittliche Anzahl von Supporttickets nach unterschiedlichen Bewertungswerten , die auf Kundenebene ausgewertet werden.
Interpretation der Ergebnisse: Wichtigste Segmente
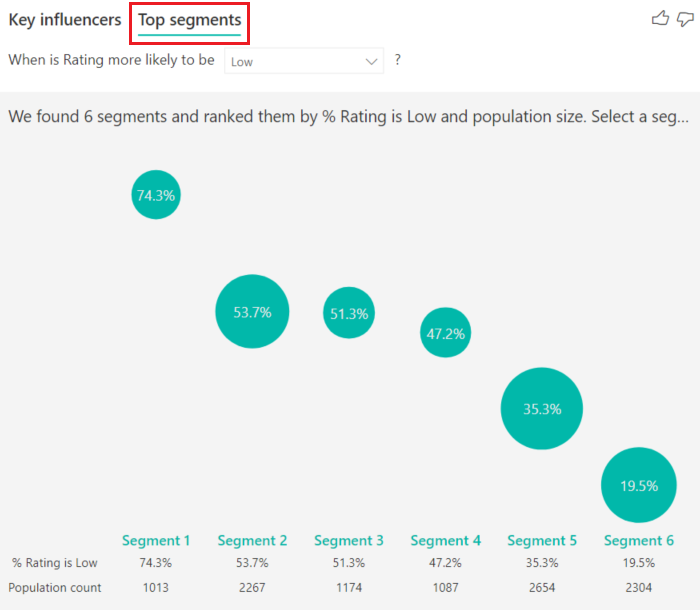
Sie können die Registerkarte " Key Influencers " verwenden, um jeden Faktor einzeln zu bewerten. Sie können auch die Registerkarte " Obere Segmente " verwenden, um zu sehen, wie sich eine Kombination von Faktoren auf die Metrik auswirkt, die Sie analysieren.
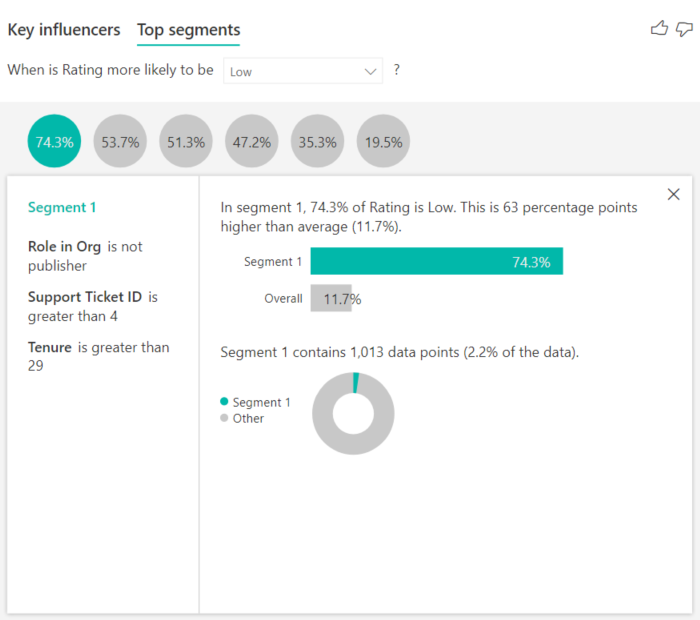
Auf der Registerkarte „Wichtigste Segmente“ wird zunächst eine Übersicht über alle von Power BI ermittelten Segmente angezeigt. Das folgende Beispiel zeigt, dass sechs Segmente gefunden wurden. Der Prozentsatz der niedrigen Bewertungen innerhalb des Segments bestimmt die Rangfolge. Daraus geht beispielsweise hervor, dass 74,3 % aller Kundenbewertungen in Segment 1 niedrig sind. Je höher der Kreis positioniert ist, desto größer ist der Anteil der niedrigen Bewertungen. Die Größe des Kreises gibt an, wie viele Kunden in einem Segment enthalten sind.
Wenn Sie eine Blase auswählen, werden die Details dieses Segments angezeigt. Wenn Sie beispielsweise Segment 1 auswählen, stellen Sie fest, dass es etablierte Kunden darstellt. Sie sind seit mehr als 29 Monaten Kunden und haben mehr als vier Supporttickets. Außerdem handelt es sich bei diesen Benutzern nicht um Herausgeber. Daher muss es sich also um Verbraucher oder Administratoren handeln.
In dieser Gruppe haben 74,3 % der Kunden eine niedrige Bewertung abgegeben. Im Durschnitt gaben 11,7 % aller Benutzer eine negative Bewertung ab. Somit ist der Anteil der niedrigen Bewertung in diesem Segment also größer. Er ist 63 Prozentpunkte größer. Segment 1 enthält zudem 2,2 % aller Daten und stellt damit einen adressierbaren Anteil aller Benutzer dar.
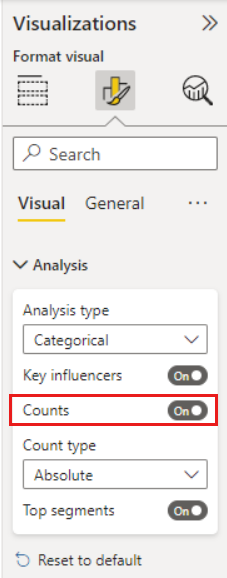
Hinzufügen von Zählungen
Manchmal kann ein Einflussfaktor eine signifikante Auswirkung haben, aber nur wenige Daten darstellen. Design ist Benutzerfreundlichkeit ist z. B. der drittgrößte Einflussfaktor für niedrige Bewertungen. Es gibt jedoch möglicherweise nur wenige Kunden, die sich über die Benutzerfreundlichkeit beschwert haben. Mit Zählungen können Sie priorisieren, auf welche Einflussfaktoren Sie sich konzentrieren möchten.
Sie können die Anzahl der Einträge über die Analysekarte des visuellen Bedienfelds "Format" aktivieren.
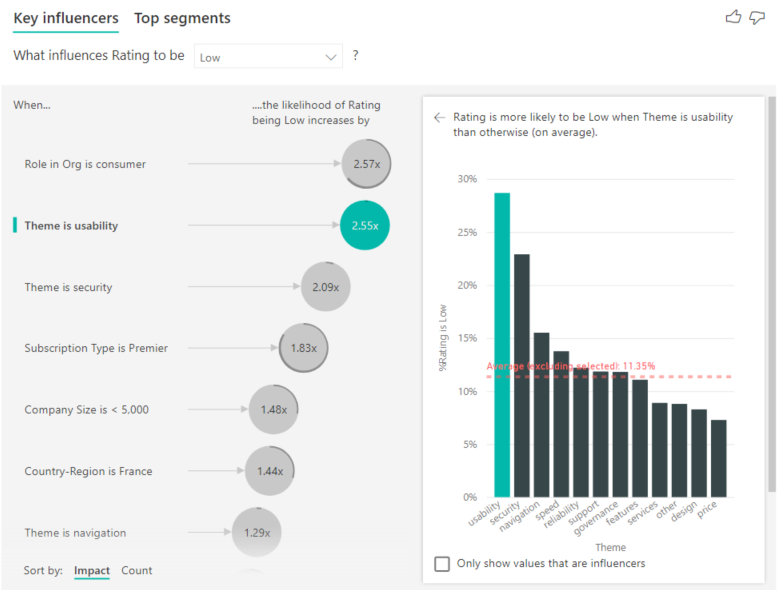
Sobald die Zählungen aktiviert sind, wird ein Ring um die Blase jedes Einflussfaktors angezeigt, der den ungefähren Prozentsatz der Daten darstellt, die der Einflussfaktor enthält. Je mehr der Kreis vom Ring eingeschlossen ist, desto mehr Daten sind in ihm enthalten. Sie sehen, dass „Design ist Benutzerfreundlichkeit“ einen kleinen Teil der Daten enthält.
Sie können auch die Option „Sortieren nach“ unten links im Visual verwenden, um die Blasen zuerst nach Zählung anstelle von Auswirkung zu sortieren. Der Abonnementtyp ist Premier ist der wichtigste Influencer basierend auf der Anzahl.
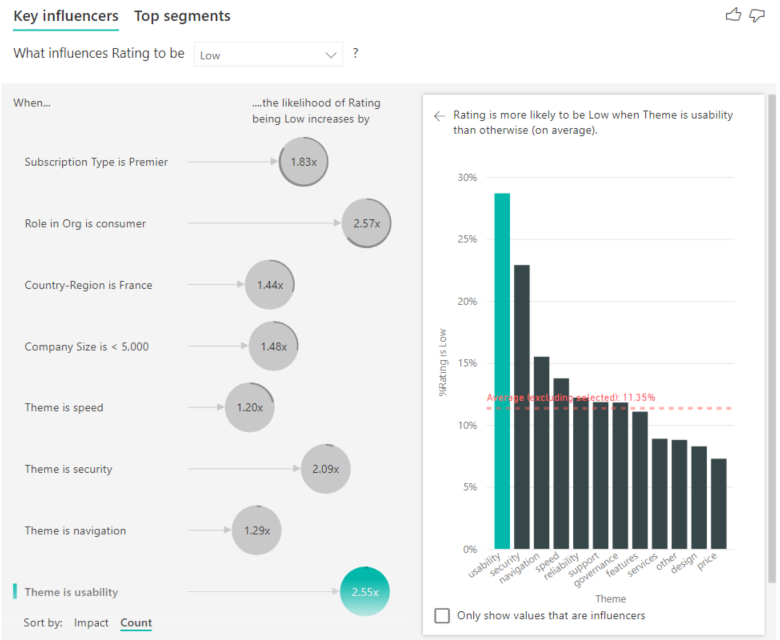
Wenn Sie einen vollständigen Ring um den Kreis sehen, bedeutet dies, dass der Einflussfaktor 100 % der Daten enthält. Sie können den Anzahltyp relativ zum maximalen Einflussfaktor ändern, indem Sie die Dropdown-Liste Anzahltyp auf der Analysekarte des Bereichs für visuelle Formatierung verwenden. Nun wird der Influencer mit der meisten Datenmenge durch einen vollständigen Ring dargestellt, und alle anderen Zählungen sind relativ zu ihr.
Analysieren einer numerischen Metrik
Wenn Sie ein nicht zusammengefasstes numerisches Feld in das Analysieren Feld verschieben, können Sie entscheiden, wie Sie damit umgehen möchten. Sie können das Verhalten des visuellen Elements ändern, indem Sie in den visuellen Bereich "Format" wechseln und zwischen kategorisierten Analysetyp und fortlaufenden Analysetyp wechseln.
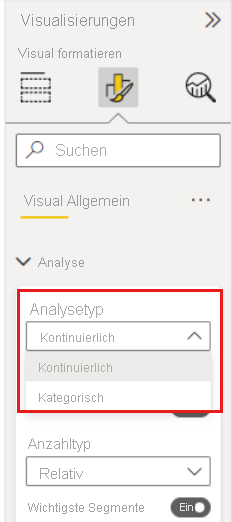
Ein kategorisiererischer Analysetyp wird weiter oben in diesem Artikel beschrieben. Wenn Sie z. B. die Umfrageergebnisse von 1 bis 10 betrachten, können Sie fragen: "Welche Einflüsse führen dazu, dass Umfrageergebnisse bei 1 liegen?"
Ein Fortlaufender Analysetyp ändert die Frage in eine fortlaufende. Im obigen Beispiel lautet die neue Frage: „Welche Faktoren bewirken, dass der Wert der Umfragebewertung ansteigt/abfällt?“.
Diese Unterscheidung ist hilfreich, wenn im zu analysierenden Feld zahlreiche Einzelwerte vorhanden sind. Im nächsten Beispiel sehen wir uns die Hauspreise an. Es ist nicht sinnvoll zu fragen, "Was beeinflusst den Hauspreis von 156.214?", da das spezifisch ist und wir wahrscheinlich nicht genügend Daten haben, um ein Muster zu erkennen.
Stattdessen könnten wir fragen: "Was beeinflusst den Anstieg der Hauspreise", was es uns ermöglicht, Hauspreise als einen Bereich anstatt als einzelne Werte zu behandeln.
Interpretation der Ergebnisse: Wichtigste Einflussfaktoren
Hinweis
In den Beispielen in diesem Abschnitt werden Immobilienpreisdaten aus der Public Domain verwendet. Sie können das Beispiel-Dataset herunterladen , wenn Sie folgen möchten.
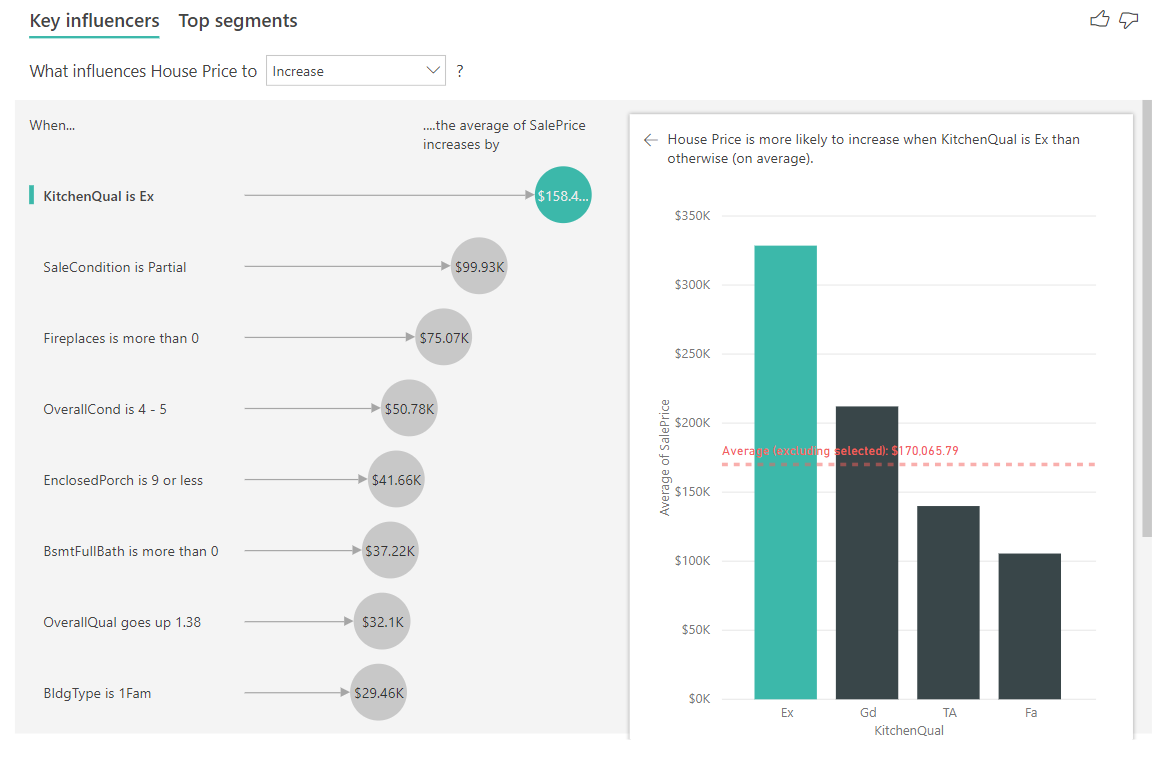
In diesem Szenario betrachten wir "Was beeinflusst den Anstieg des Hauspreises." Eine Reihe von erklärenden Faktoren könnte einen Hauspreis beeinflussen, z. B. Year Built (Jahr, in dem das Haus gebaut wurde), KitchenQual (Küchenqualität) und YearRemodAdd (Jahr, in dem das Haus renoviert wurde).
Im folgenden Beispiel untersuchen Sie den wichtigsten Einflussfaktor, nämlich eine herausragende Küchenqualität. Die Ergebnisse sind mit den Ergebnissen der Analyse kategorischer Metriken vergleichbar. Es gibt jedoch einige wichtige Unterschiede:
- Das Säulendiagramm rechts zeigt die Durchschnittswerte anstelle von Prozentsätzen. Es zeigt uns daher, was der durchschnittliche Hauspreis eines Hauses mit einer ausgezeichneten Küche ist (grüne Leiste) im Vergleich zum durchschnittlichen Hauspreis eines Hauses ohne eine ausgezeichnete Küche (gepunktete Linie).
- Die Zahl in der Blase ist immer noch der Unterschied zwischen der roten gepunkteten Linie und dem grünen Balken, wird jedoch als Zahl (\158,49K) und nicht als Wahrscheinlichkeit (1,93x) ausgedrückt. Im Durchschnitt sind Häuser mit ausgezeichneten Küchen fast \$160K teurer als Häuser ohne ausgezeichnete Küchen.
Im nächsten Beispiel betrachten wir die Auswirkungen, die ein fortlaufender Faktor (das Jahr, in dem das Haus umgestaltet wurde) auf den Hauspreis hat. Im Vergleich zur Analyse von kontinuierlichen Einflussfaktoren gibt es bei kategorischen Metriken folgende Unterschiede:
- Das Streudiagramm im rechten Bereich zeigt den durchschnittlichen Hauspreis für jeden einzigartigen Wert des Jahres der Renovierung.
- Der Wert in der Blase zeigt, um wie viel der durchschnittliche Hauspreis steigt (in diesem Fall $2.870), wenn das Jahr, in dem das Haus umgestaltet wurde, um seine Standardabweichung (in diesem Fall 20 Jahre) erhöht wird.
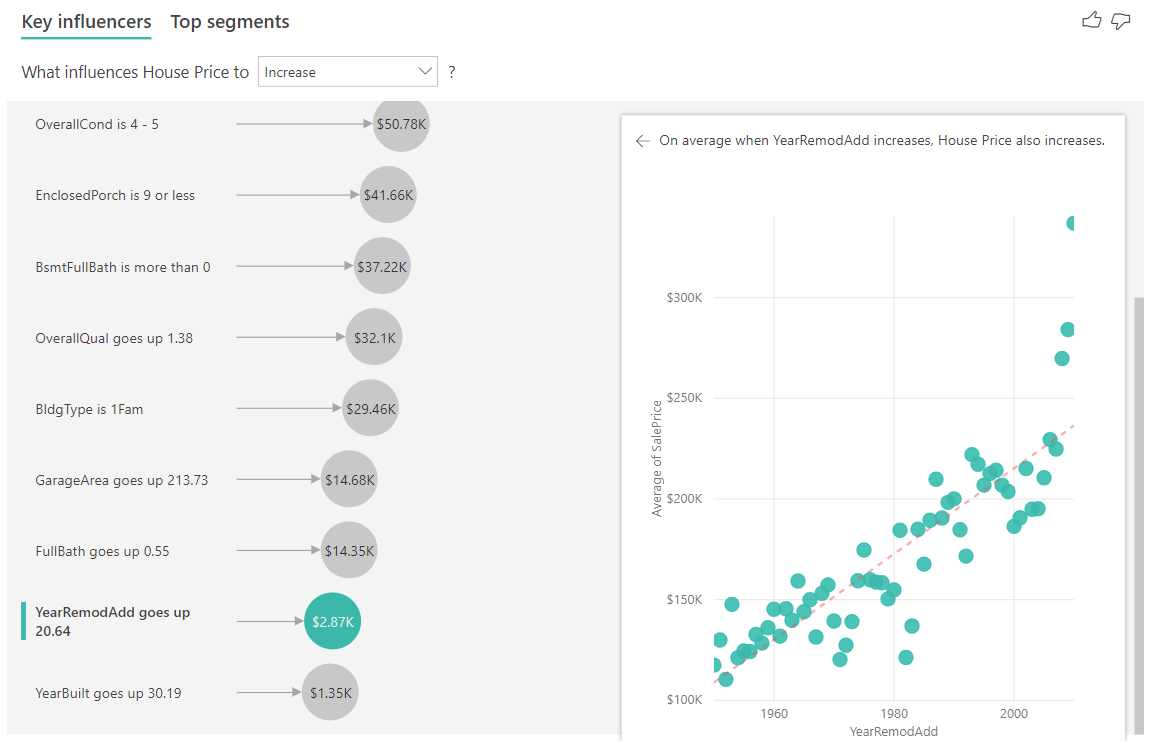
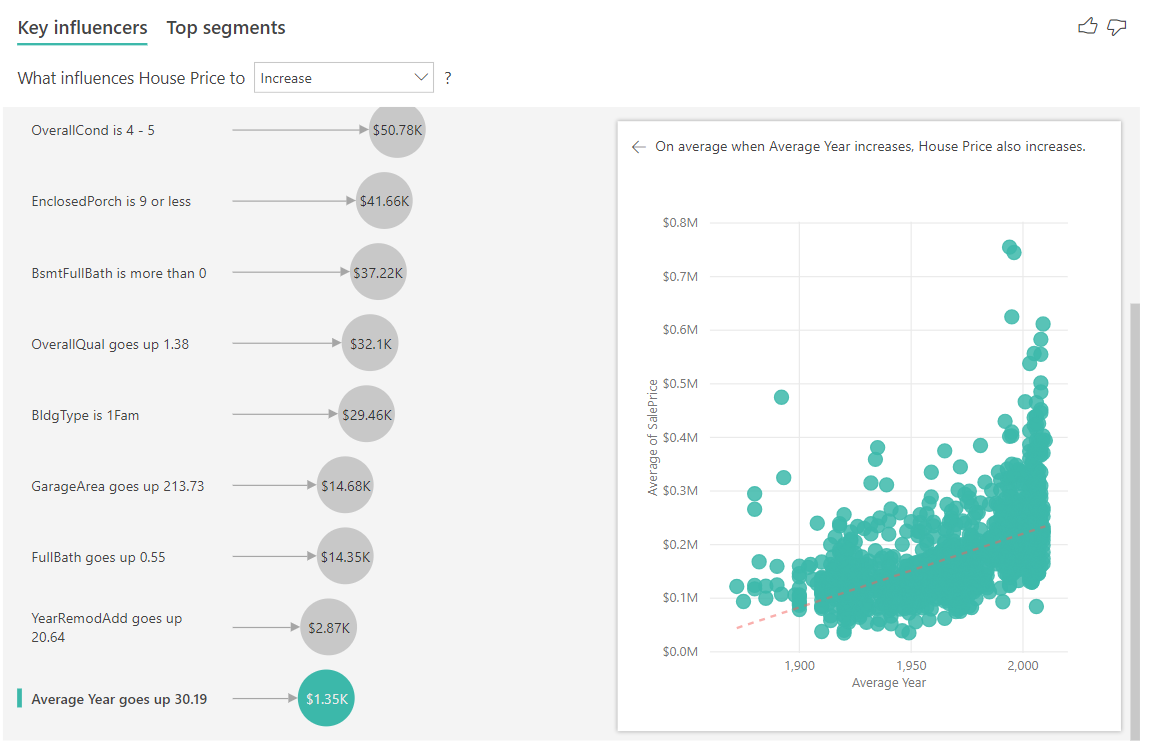
Abschließend betrachten wir bei den Maßnahmen das Durchschnittsjahr, in dem ein Haus gebaut wurde. Die Analyse sieht wie folgt aus:
- Das Punktdiagramm im rechten Bereich zeichnet den durchschnittlichen Hauspreis für jeden unterschiedlichen Wert in der Tabelle aus.
- Der Wert in der Blase zeigt, wie viel der durchschnittliche Hauspreis steigt (in diesem Fall \$1,35K), wenn das durchschnittliche Jahr um seine Standardabweichung steigt (in diesem Fall 30 Jahre).
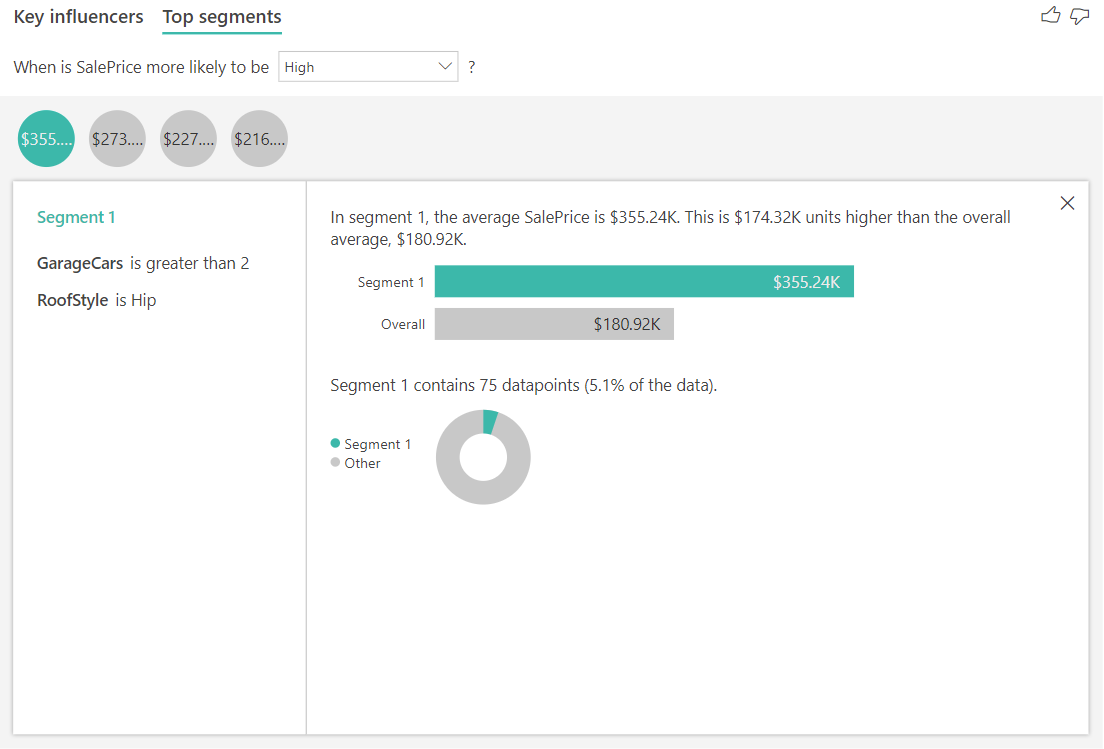
Interpretieren der Ergebnisse mithilfe von Top-Segmenten
In den wichtigsten Segmenten für numerische Zielsetzungen werden Gruppen angegeben, bei denen die Immobilienpreise im Durchschnitt höher sind als im Dataset insgesamt. Unten können wir beispielsweise sehen, dass Segment 1 aus Häusern besteht, in denen GarageCars (Anzahl der Autos, die die Garage passen kann) größer als 2 ist und der RoofStyle hip ist. Häuser mit diesen Merkmalen haben einen Durchschnittspreis von \$355K im Vergleich zum Gesamtdurchschnitt in den Daten, die \$180K sind.
Analysiere eine Metrik, die ein Maß oder eine zusammengefasste Spalte ist
Bei einer Maß- oder Zusammenfassungsspalte wird standardmäßig der
Bei nicht zusammengefassten Spalten wird die Analyse immer auf Tabellenebene ausgeführt. Im Hauspreisbeispiel haben wir die Metrik Hauspreis analysiert, um zu sehen, was einen Hauspreis steigen oder sinken lässt. Die Analyse wird automatisch auf Tabellenebene ausgeführt. Unsere Tabelle verfügt über eine eindeutige ID für jedes Haus, damit die Analyse auf Hausebene ausgeführt wird.
Bei Maßnahmen und zusammengefassten Spalten wissen wir nicht sofort, auf welcher Ebene wir sie analysieren sollen. Wenn Der Hauspreis als Durchschnitt zusammengefasst wurde, müssen wir überlegen, welches Niveau wir für diesen durchschnittlichen Hauspreis berechnen möchten. Handelt es sich um den Durchschnittshauspreis auf Nachbarschaftsebene? Oder vielleicht auf regionaler Ebene?
Maße und zusammengefasste Spalten werden automatisch auf der Ebene der in Erklären nach verwendeten Felder analysiert. Stellen Sie sich vor, wir wollen drei Felder in "Explain by" untersuchen: Küchenqualität, Gebäudetyp und Klimaanlage. Der Durchschnitt des Hauspreises würde für jede eindeutige Kombination dieser drei Felder berechnet. Häufig ist es hilfreich, zu einer Tabellenansicht zu wechseln, um zu sehen, wie die zu bewertenden Daten aussehen.
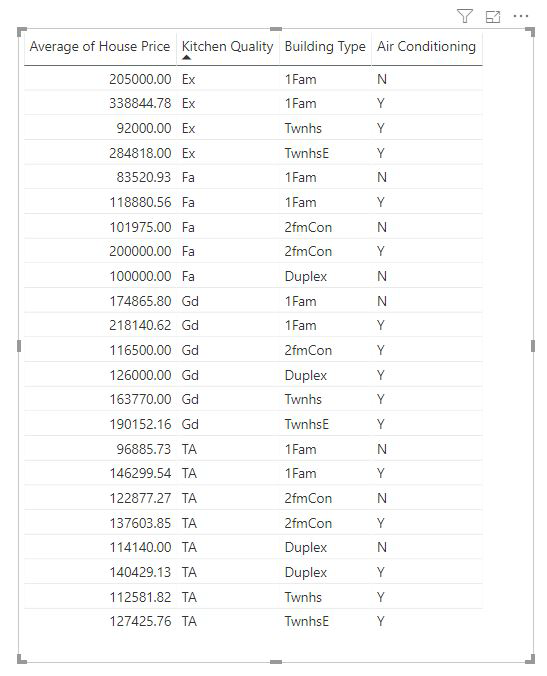
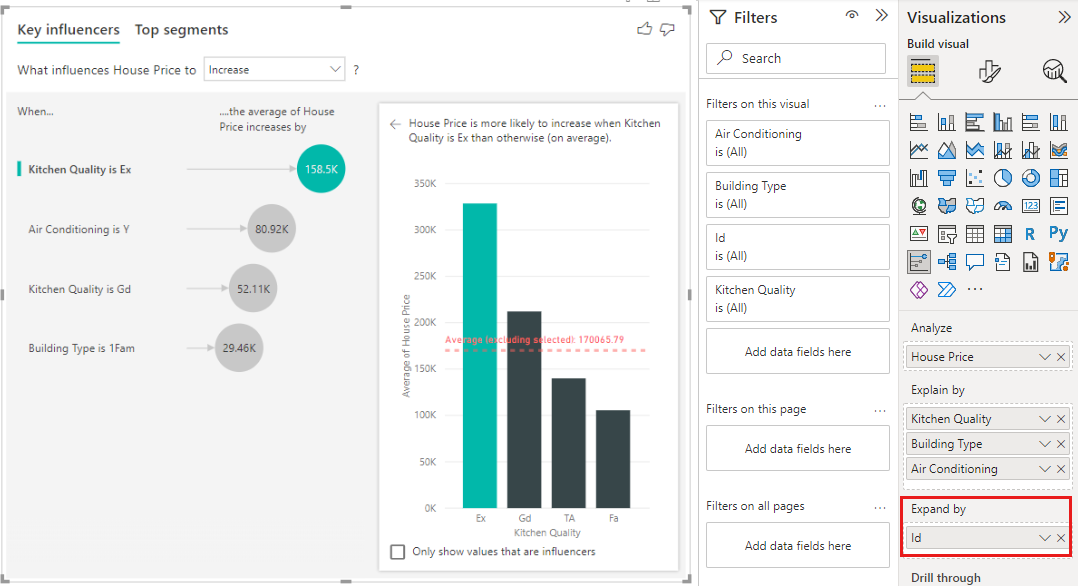
Diese Analyse ist sehr zusammengefasst, daher kann es für das Regressionsmodell schwierig sein, muster in den Daten zu finden, aus denen sie lernen können. Wir sollten die Analyse detaillierter ausführen, um bessere Ergebnisse zu erzielen. Wenn wir den Hauspreis auf Hausebene analysieren möchten, müssen wir der Analyse explizit das Feld "ID " hinzufügen. Trotzdem möchten wir nicht, dass die Haus-ID als Einflussfaktor angesehen wird. Es ist nicht hilfreich zu erfahren, dass mit der Zunahme der Haus-ID auch der Hauspreis steigt. Die Option "Erweitern um"-Feld ist hier nützlich. Sie können "Erweitern" verwenden, um Felder hinzuzufügen, die Sie zum Festlegen der Analyseebene verwenden möchten, ohne nach neuen Influencern zu suchen.
Sehen Sie sich an, wie die Visualisierung aussieht, sobald wir die ID zum Erweitern hinzufügen. Sobald Sie die Ebene festgelegt haben, auf der Ihr Messwert ausgewertet werden soll, entspricht die Interpretation von Influencern genau derjenigen bei nicht zusammengefassten numerischen Spalten.
Um zu erfahren, wie Power BI ML.NET hinter den Kulissen verwendet, um Daten und Einblicke auf natürliche Weise zu verstehen, finden Sie in Power BI wichtige Influencer mithilfe von ML.NET.
Zu beachtende Aspekte und Problembehandlung
Welche Einschränkungen gelten für das visuelle Element?
Für das Visual „Wichtige Einflussfaktoren“ gibt es einige Einschränkungen:
- Direct Query wird nicht unterstützt.
- Die Liveverbindung mit Azure Analysis Services und SQL Server Analysis Services wird nicht unterstützt.
- Die Veröffentlichung im Web wird nicht unterstützt.
- .NET Framework 4.6 oder höher ist erforderlich.
- Das Einbetten von SharePoint Online wird nicht unterstützt.
- Analysieren einer kategorialen Metrik wird nicht unterstützt, wenn Implizite Maßnahmen entmutigen im Datenmodell auf true festgelegt ist (z. B. wenn Berechnungsgruppen im Datenmodell definiert sind).
Es wird ein Fehler angezeigt, dass keine Einflussfaktoren oder Segmente gefunden wurden. Woran liegt das?
Dieser Fehler tritt auf, wenn Sie Felder in Erklärt durch eingefügt haben, aber keine Influencer gefunden wurden. Überprüfen Sie, ob eines der folgenden Probleme zutrifft.
- Sie haben die Metrik, die Sie analysiert haben, sowohl in "Analysieren " als auch in "Erklären nach" eingeschlossen. Entfernen Sie sie aus Erläuterung nach.
- Die erläuternden Felder enthalten zu viele Kategorien, in denen nur wenige Beobachtungen vorhanden sind. In dieser Situation ist es für das Visual schwierig zu erkennen, welche Faktoren Einflussfaktoren sind. Eine Generalisierung auf Basis weniger Beobachtungen ist schwierig. Wenn Sie ein numerisches Feld analysieren, können Sie im visuellen Bereich "Format" auf der Analysekarte von "Kategorisierte Analyse" zu "Fortlaufende Analyse" wechseln.
- Ihre erklärenden Faktoren verfügen über ausreichend Beobachtungen für eine Generalisierung, aber die Visualisierung konnte keine sinnvollen Korrelationen finden, die gemeldet werden können.
Es wird ein Fehler angezeigt, dass die zu analysierende Metrik nicht genügend Daten für eine Analyse enthält. Woran liegt das?

Das Visual funktioniert so, dass in den Daten für eine Gruppe nach Mustern gesucht und mit anderen Gruppen verglichen wird. So wird beispielsweise nach Kunden gesucht, die im Vergleich zu anderen Kunden, die hohe Bewertungen abgegeben haben, niedrige Bewertungen abgegeben haben. Wenn die Daten in Ihrem Modell nur wenige Beobachtungen enthalten, können Muster nur schwer ermittelt werden. Wenn im Visual nicht genügend Daten enthalten sind, um aussagekräftige Einflussfaktoren zu ermitteln, wird angezeigt, dass mehr Daten benötigt werden, um die Analyse durchzuführen.
Für den ausgewählten Zustand sollten mindestens 100 Beobachtungen vorhanden sein. In diesem Beispiel steht der Zustand für Kunden, die abwandern. Ferner benötigen Sie mindestens 10 Beobachtungen für die Zustände, die Sie für den Vergleich verwenden. In diesem Beispiel steht der Vergleichszustand für Kunden, die nicht abwandern.
Wenn Sie ein numerisches Feld analysieren, können Sie im visuellen Bereich "Format" auf der Analysekarte von "Kategorisierte Analyse" zu "Fortlaufende Analyse" wechseln.
Es wird eine Fehlermeldung angezeigt, dass die Analyse immer auf Zeilenebene der übergeordneten Tabelle ausgeführt wird, wenn „Analysieren“ nicht zusammengefasst ist. Das Ändern dieser Ebene über die „Erweitern durch“-Felder ist nicht zulässig. Woran liegt das?
Wenn eine numerische Spalte oder eine kategorische Spalte analysiert wird, wird die Analyse immer auf der Tabellenebene ausgeführt. Wenn Sie beispielsweise Hauspreise analysieren und Ihre Tabelle eine ID-Spalte enthält, wird die Analyse automatisch auf Haus-ID-Ebene ausgeführt.
Bei der Analyse von Maßnahmen oder zusammengefassten Spalten müssen Sie explizit angeben, auf welcher Ebene Sie die Analyse ausführen möchten. Sie können „Erweitern“ verwenden, um die Ebene der Analyse für Kennzahlen und zusammengefasste Spalten zu ändern, ohne neue Einflussfaktoren hinzuzufügen. Wenn Immobilienpreis als Measure definiert wurde, können Sie die Spalte „Immobilien-ID“ der Feldoption Erweitern um hinzufügen, um die Analyseebene zu ändern.
Ich sehe einen Fehler, dass ein Feld in "Explain by " nicht eindeutig mit der Tabelle verknüpft ist, die die zu analysierende Metrik enthält. Woran liegt das?
Die Analyse wird auf Tabellenebene des entsprechenden Felds ausgeführt. Wenn Sie beispielsweise Kundenfeedback für Ihren Dienst analysieren, besitzen Sie möglicherweise eine Tabelle, aus der hervorgeht, ob ein Kunde eine hohe oder eine niedrige Bewertung abgegeben hat. In diesem Fall wird die Analyse auf Ebene der Kundentabelle durchgeführt.
Wenn eine verknüpfte Tabelle auf einer granulareren Ebene als die Tabelle definiert ist, die Ihre Metrik enthält, wird dieser Fehler angezeigt. Hier sehen Sie ein Beispiel:
- Sie analysieren, was Kunden dazu bewegt, eine niedrige Bewertung für Ihren Dienst abzugeben.
- Sie möchten wissen, ob sich das Gerät, auf dem Ihre Kunden den Dienst verwenden, auf die Bewertung auswirkt.
- Kunden können den Dienst auf unterschiedlichen Geräten verwenden.
- Im folgenden Beispiel verwendet Kunde 10000000 sowohl einen Browser als auch ein Tablet, um auf den Dienst zuzugreifen.
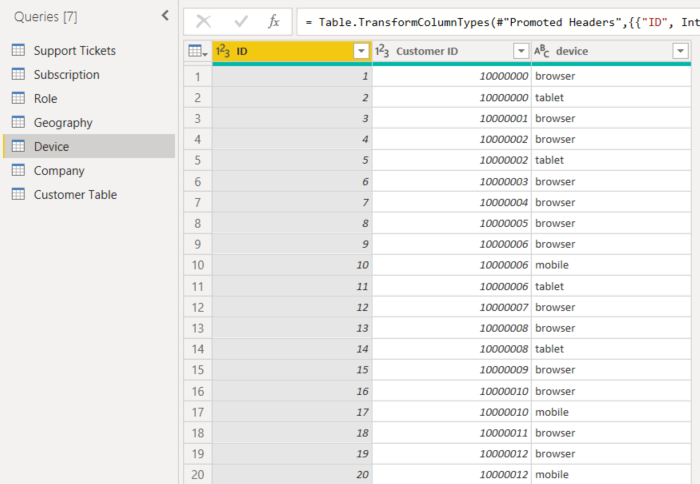
Wenn Sie versuchen, die Spalte „device“ als erläuternden Faktor zu verwenden, wird folgender Fehler angezeigt:
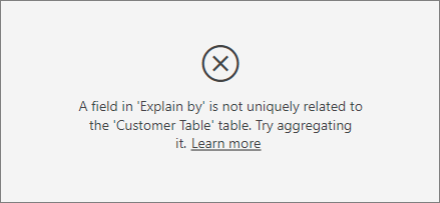
Dieser Fehler wird angezeigt, da das Gerät nicht auf Kundenebene definiert wurde. Kunden können den Dienst auf mehreren Geräten verwenden. Damit die Visualisierung Muster ermitteln kann, muss das Gerät ein Attribut des Kunden sein. Es gibt verschiedene Lösungen, die von Ihren Kenntnissen des Geschäfts abhängen:
- Sie können die Zusammenfassung von zu zählenden Geräten ändern. Verwenden Sie beispielsweise „count“, wenn sich die Anzahl von Geräten möglicherweise auf die Bewertung auswirkt, die ein Kunde abgibt.
- Sie können die Spalte „device“ pivotieren, um festzustellen, ob sich die Verwendung des Diensts auf einem bestimmten Gerät auf die Kundenbewertung auswirkt.
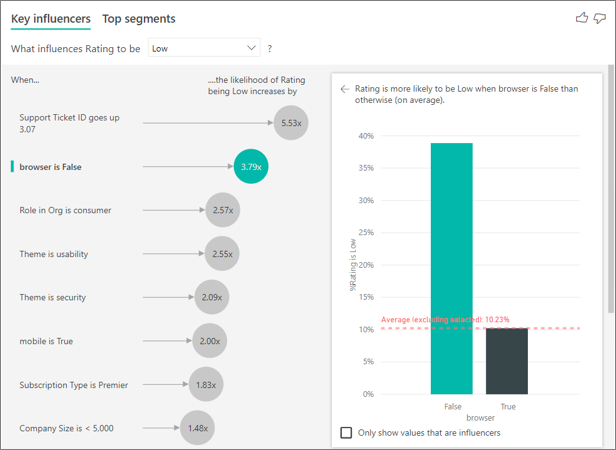
In diesem Beispiel wurden die Daten pivotiert, um neue Spalten für Browser, Mobilgeräte und Tablets zu erstellen (Sie dürfen nicht vergessen, die Beziehungen in der Modellierungsansicht zu löschen und neu zu erstellen, nachdem Sie die Daten pivotiert haben). Sie können diese spezifischen Geräte jetzt in "Explain by" verwenden. Daraus ergibt sich, dass alle Geräte Einflussfaktoren sind, wobei der Browser jedoch die größte Auswirkung auf die Kundenbewertung hat.
Genauer gesagt ist die Wahrscheinlichkeit, dass Kunden eine niedrige Bewertung abgeben, 3,79-mal höher, wenn sie den Dienst nicht über den Browser verwenden. Unten in der Liste ist das Gegenteil der Fall für Mobilgeräte. Es ist wahrscheinlicher, dass Kunden, die die mobile App nutzen, eine niedrige Bewertung abgeben, als Kunden, die sie nicht nutzen.
Es wird eine Warnung angezeigt, dass die Maßnahmen nicht in die Analyse einbezogen wurden. Woran liegt das?
Die Analyse wird auf Tabellenebene des entsprechenden Felds ausgeführt. Wenn Sie die Kundenabwanderung analysieren, haben Sie möglicherweise eine Tabelle, die Ihnen zeigt, ob ein Kunde abgewandert ist oder nicht. In diesem Fall wird die Analyse auf Ebene der Kundentabelle durchgeführt.
Standardmäßig werden Maßnahmen und Aggregate auf Tabellenebene analysiert. Wenn es ein Maß für die durchschnittlichen monatlichen Ausgaben gäbe, würde es auf der Ebene der Kundentabelle analysiert werden.
Wenn die Kundentabelle keinen eindeutigen Bezeichner aufweist, kann die Maßnahme nicht ausgewertet werden und wird bei der Analyse ignoriert. Sorgen Sie zur Vermeidung dieser Situation dafür, dass die Tabelle in Ihrer Metrik einen eindeutigen Bezeichner enthält. In diesem Fall ist es die Kundentabelle, und der eindeutige Bezeichner ist die Kunden-ID. Mithilfe von Power Query können Sie zudem einfach eine Indexspalte hinzufügen.
Es wird eine Warnung angezeigt, dass die analysierte Metrik mehr als 10 Einzelwerte aufweist und somit die Qualität der Analyse beeinträchtigen kann. Woran liegt das?
Mit dem KI-Visual können Kategoriefelder und numerische Felder analysiert werden. Bei kategorischen Feldern sind „Churn“ (Abwanderung) ist „Yes“ (Ja) oder „No“ (Nein) und „Customer Satisfaction“ (Kundenzufriedenheit) ist „High“ (Hoch), „Medium“ (Mittel) oder „Low“ (Niedrig) mögliche Beispiele. Wenn Sie die Anzahl der zu analysierenden Kategorien erhöhen, gibt es weniger Beobachtungen pro Kategorie. Es erschwert es der Visualisierung, in den Daten Muster zu erkennen.
Beim Analysieren numerischer Felder haben Sie die Möglichkeit, die numerischen Felder wie Text zu behandeln. In diesem Fall führen Sie dieselbe Analyse wie bei kategorisierten Daten (Kategorisierungsanalyse) aus. Wenn Sie über viele unterschiedliche Werte verfügen, empfehlen wir, die Analyse in die fortlaufende Analyse zu wechseln, da dies bedeutet, dass wir Muster davon ableiten können, wann Zahlen größer oder verkleinert werden, anstatt sie als unterschiedliche Werte zu behandeln. Sie können im visuellen Bereich "Formatieren" auf der Karte "Analyse" von "Kategorisierte Analyse" zu "Fortlaufende Analyse" wechseln.
Es wird empfohlen, ähnliche Werte in einer einzigen Einheit zu gruppieren, um aussagekräftigere Einflussfaktoren zu ermitteln. Bei einer Metrik für den Preis erhalten Sie beispielsweise bessere Ergebnisse, wenn Sie ähnliche Preise in Kategorien wie „Hoch“, „Mittel“ oder „Niedrig“ gruppieren, anstatt einzelne Preispositionen zu verwenden.
In den Daten sind Faktoren vorhanden, bei denen es sich nicht um wichtige Einflussfaktoren handelt, obwohl sie es sein sollten. Wie kann es dazu kommen?
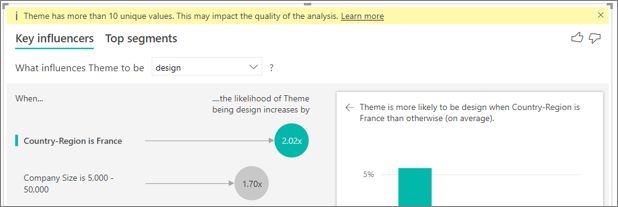
Im folgenden Beispiel geben Kunden, die Verbraucher sind, niedrige Bewertungen ab. Dabei sind 14,93 % der Bewertungen niedrig. Die Administratorrolle hat auch einen hohen Anteil an niedrigen Bewertungen bei 13,42%, gilt aber nicht als Influencer.
Der Grund für diese Festlegung ist, dass die Visualisierung auch die Anzahl der Datenpunkte berücksichtigt, wenn sie Einflussfaktoren identifiziert. Im folgenden Beispiel geht es um mehr als 29.000 Verbraucher und 10-mal weniger Administratoren, also etwa 2.900. Nur 390 Administratoren haben eine niedrige Bewertung abgegeben. Die visuelle Darstellung verfügt nicht über genügend Daten, um zu erkennen, ob es bei den Administratorbewertungen ein Muster gibt oder ob es sich um einen Zufallsfund handelt.
Was sind die Datenpunktgrenzwerte für wichtige Influencer?
Wir führen die Analyse an einer Stichprobe von 10.000 Datenpunkten durch. Die Blasen auf der einen Seite zeigen alle gefundenen Einflussfaktoren. Die Säulendiagramme und Punktdiagramme auf der gegenüberliegenden Seite halten sich an die Samplingstrategien für diese Kernvisualisierungen.
Wie berechnen Sie wichtige Influencer für kategorisierte Analysen?
Hinter den Kulissen verwendet die KI-Visualisierung ML.NET , um eine logistische Regression auszuführen, um die wichtigsten Influencer zu berechnen. Bei einer logistischen Regression handelt es sich um ein Statistikmodell, das verschiedene Gruppen miteinander vergleicht.
Wenn Sie herausfinden möchten, was zu niedrigen Bewertungen führt, untersucht die logistische Regression, wie sich die Kunden unterscheiden, die eine niedrige Bewertung abgegeben haben, von denen, die eine hohe Bewertung abgegeben haben. Bei Verwendung mehrerer Kategorien wie „Hoch“, „Neutral“ und „Niedrig“ können Sie untersuchen, wie sich die Kunden, die eine niedrige Bewertung abgegeben haben, von denjenigen Kunden unterscheiden, die keine niedrige Bewertung abgegeben haben. In diesem Fall, wie unterscheiden sich die Kunden, die eine niedrige Bewertung abgegeben haben, von denen, die eine hohe oder neutrale Bewertung abgegeben haben?
Im Rahmen der logistischen Regression wird in den Daten nach Mustern gesucht, um zu ermitteln, wie sich die Kunden, die eine niedrige abgegeben haben, von denjenigen Kunden unterscheiden, die eine hohe Bewertung abgegeben haben. So lässt sich möglicherweise feststellen, dass Kunden mit vielen Supporttickets einen höheren prozentualen Anteil an den niedrigen Bewertungen ausmachen als die Kunden mit wenigen oder keinen Supporttickets.
Bei der logistischen Regression wird auch die Anzahl der Datenpunkte berücksichtigt. Wenn Beispielsweise Kunden, die eine Administratorrolle spielen, proportional negativere Bewertungen geben, aber es gibt nur wenige Administratoren, wird dieser Faktor nicht als einflussreich angesehen. Diese Feststellung wird getroffen, weil zum Ableiten eines Musters nicht genügend Datenpunkte vorhanden sind. Es wird ein statistischer Test (Wald-Test) verwendet, um zu bestimmen, ob ein Faktor als Einflussfaktor gewertet werden kann. Im Visual wird ein p-Wert von 0,05 verwendet, um den Schwellenwert zu berechnen.
Wie berechnen Sie wichtige Influencer für die numerische Analyse?
Hinter den Kulissen verwendet die KI-Visualisierung ML.NET , um eine lineare Regression auszuführen, um die wichtigsten Influencer zu berechnen. Die lineare Regression ist ein Statistikmodell, mit dem untersucht wird, wie sich das Ergebnis des Felds, das Sie analysieren, basierend auf den erläuternden Faktoren ändert.
Wenn wir beispielsweise Hauspreise analysieren, untersucht eine lineare Regression den Effekt, dass eine ausgezeichnete Küche auf den Hauspreis hat. Lassen sich mit Häusern mit einer sehr guten Küchenqualität generell niedrigere oder höhere Immobilienpreise erzielen als mit Häusern ohne sehr gute Küchenqualität?
Bei der linearen Regression wird auch die Anzahl der Datenpunkte berücksichtigt. Wenn sich mit Häusern mit Tennisplatz höhere Preise erzielen lassen, jedoch nur wenige Häuser mit einem Tennisplatz im Angebot sind, wird dieser Faktor nicht als Einflussfaktor gewertet, Diese Feststellung wird getroffen, weil zum Ableiten eines Musters nicht genügend Datenpunkte vorhanden sind. Es wird ein statistischer Test (Wald-Test) verwendet, um zu bestimmen, ob ein Faktor als Einflussfaktor gewertet werden kann. Im Visual wird ein p-Wert von 0,05 verwendet, um den Schwellenwert zu berechnen.
Wie berechnen Sie Segmente?
Hinter den Kulissen verwendet die KI-Visualisierung ML.NET , um eine Entscheidungsstruktur auszuführen, um interessante Untergruppen zu finden. Das Ziel der Entscheidungsstruktur besteht darin, eine Untergruppe von Datenpunkten zu ermitteln, die in der relevanten Metrik relativ stark vertreten ist. Das könnten Kunden mit niedrigen Bewertungen oder Häuser mit hohen Preisen sein.
Anhand der Entscheidungsstruktur wird jeder erläuternde Faktor analysiert und versucht zu ermitteln, welcher die beste Aufteilung bietet. Wenn Sie beispielsweise die Daten so filtern, dass nur große Unternehmenskunden einbezogen werden, werden dadurch Kunden getrennt, die eine hohe Bewertung im Vergleich zu einer niedrigen Bewertung erhalten haben? Oder vielleicht ist es besser, die Daten zu filtern, um nur Kunden einzuschließen, die zu Sicherheit kommentiert haben?
Nachdem im Rahmen der Entscheidungsstruktur eine Aufteilung vorgenommen wurde, wird für die Untergruppe von Daten die nächstbeste Aufteilung für diese Daten ermittelt. In diesem Beispiel besteht die Untergruppe aus Kunden, die eine Bewertung zum Thema Sicherheit abgegeben haben. Nach jeder Aufteilung berücksichtigt der Entscheidungsbaum auch, ob genügend Datenpunkte in dieser Gruppe vorhanden sind, um repräsentativ genug zu sein, um daraus ein Muster abzuleiten. Andernfalls handelt es sich um eine Anomalie in den Daten und nicht um ein echtes Segment. Ein weiterer statistischer Test wird angewendet, um die statistische Signifikanz des geteilten Zustands mit einem p-Wert von 0,05 zu überprüfen.
Nach der Ausführung der Entscheidungsstruktur werden aus allen Aufteilungen wie Feedback zum Thema Sicherheit und große Unternehmen Power BI-Filter erstellt. Diese Filter werden im Visual zu einem Segment kombiniert.
Warum werden bestimmte Faktoren zu Influencern oder hören auf, Influencer zu sein, wenn ich mehr Felder zu "Erklären durch" verschiebe?
Das Visual wertet alle erläuternden Faktoren zusammen aus. Ein Faktor kann allein ein Influencer sein, aber wenn er mit anderen Faktoren in Betracht gezogen wird, ist er möglicherweise nicht. Angenommen, Sie möchten analysieren, wodurch der Preis eines Hauses steigt und verwenden dabei die erläuternden Faktoren „Schlafzimmer“ und „Fläche“:
- Als einzelner Faktor kann die Anzahl der Schlafzimmer den Preis eines Hauses erhöhen.
- Unter Einbeziehung der Fläche in die Analyse wird untersucht, wie sich die Anzahl der Schlafzimmer bei konstanter Fläche des Hauses auswirkt.
- Wenn die Größe des Hauses auf 1.500 Quadratmeter festgelegt ist, ist es unwahrscheinlich, dass ein kontinuierlicher Anstieg der Anzahl der Schlafzimmer dramatisch den Hauspreis erhöht.
- Die Anzahl der Schlafzimmer stellt somit kein so wichtiger Faktor mehr dar wie vor der Berücksichtigung der Hausgröße.
Das Freigeben Ihres Berichts mit einem Power BI-Kollegen erfordert, dass Sie über einzelne Fabric- oder Power BI Pro-Lizenzen verfügen oder dass der Bericht in einer Premium-Kapazität gespeichert wird. Weitere Informationen finden Sie unter Freigeben von Berichten.