Bewährte Methoden für die Klassifizierung im Microsoft Purview-Governanceportal
Die Datenklassifizierung im Microsoft Purview-Governanceportal ist eine Möglichkeit, Datenressourcen zu kategorisieren, indem den Datenressourcen eindeutige logische Bezeichnungen oder Klassen zugewiesen werden. Die Klassifizierung basiert auf dem Geschäftskontext der Daten. Beispielsweise können Sie Ressourcen nach Reisepassnummer, Führerscheinnummer, Kreditkartennummer, SWIFT-Code, Name der Person usw. klassifizieren. Weitere Informationen zur Klassifizierung selbst finden Sie in unserem Artikel zur Klassifizierung.
In diesem Artikel werden bewährte Methoden beschrieben, die Sie beim Klassifizieren von Datenressourcen anwenden müssen, damit Ihre Überprüfungen effektiver sind und Sie über möglichst vollständige Informationen zu Ihrem gesamten Datenbestand verfügen.
Regelsatz überprüfen
Mithilfe eines Überprüfungsregelsatzes können Sie die relevanten Klassifizierungen konfigurieren, die auf die bestimmte Überprüfung für die Datenquelle angewendet werden sollen. Wählen Sie die relevanten Systemklassifizierungen aus, oder wählen Sie benutzerdefinierte Klassifizierungen aus, wenn Sie eine für die daten erstellt haben, die Sie überprüfen.
In der folgenden Abbildung werden beispielsweise nur die spezifischen ausgewählten System- und benutzerdefinierten Klassifizierungen auf die datenquelle angewendet, die Sie überprüfen (z. B. Finanzdaten).

Anmerkungsverwaltung
Während Sie sich entscheiden, welche Klassifizierungen angewendet werden sollen, empfehlen wir Folgendes:
Wechseln Sie zum Bereich DataMap-Anmerkungsverwaltung>>Klassifizierungen.
Überprüfen Sie die verfügbaren Systemklassifizierungen, die auf die zu überprüfenden Datenressourcen angewendet werden sollen. Die formalen Namen von Systemklassifizierungen haben ein MICROSOFT-Präfix .
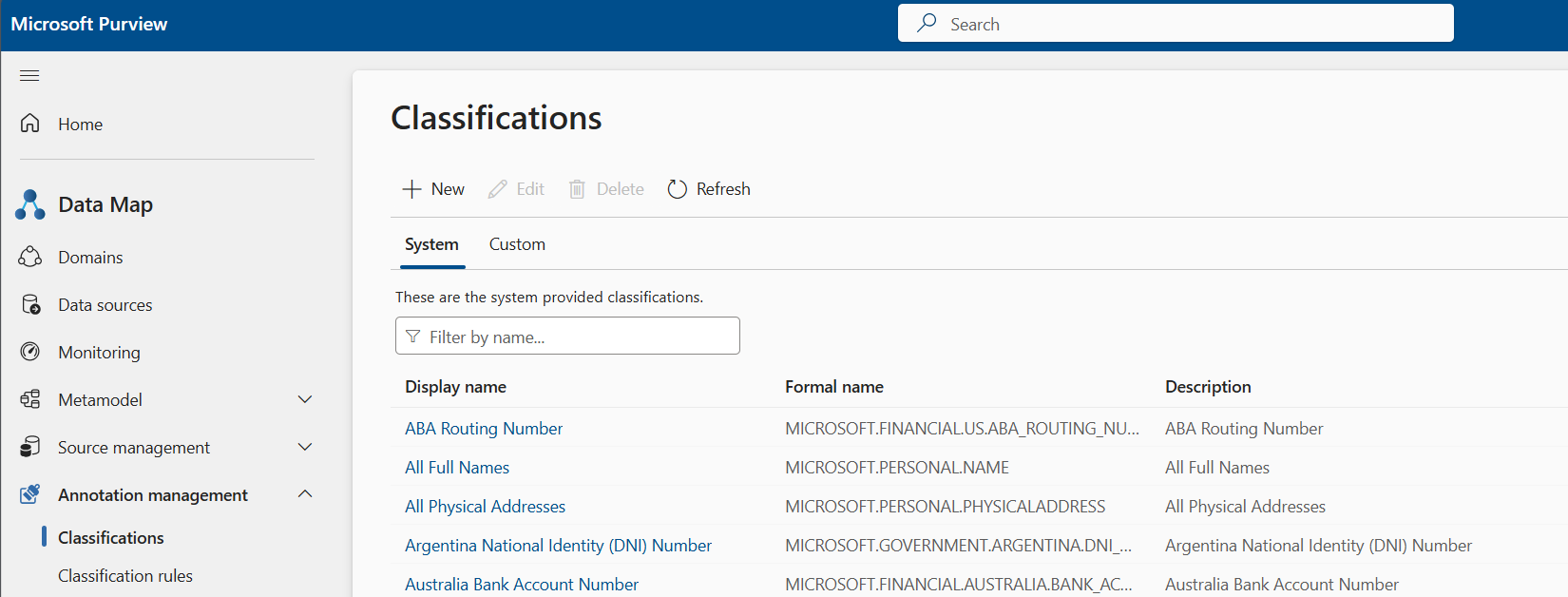
Erstellen Sie bei Bedarf einen benutzerdefinierten Klassifizierungsnamen. Beginnen Sie in diesem Bereich, und wechseln Sie dann zu DataMap-Anmerkungsverwaltung>>Klassifizierungsregeln. Hier können Sie die Klassifizierungsregel für den benutzerdefinierten Klassifizierungsnamen erstellen, den Sie im vorherigen Schritt erstellt haben.


Benutzerdefinierte Klassifizierungen
Erstellen Sie benutzerdefinierte Klassifizierungen nur, wenn die verfügbaren Systemklassifizierungen Nicht ihren Anforderungen entsprechen.
Für den Namen der benutzerdefinierten Klassifizierung empfiehlt es sich, eine Namespacekonvention (z<. B. Firmenname>) zu verwenden.<Geschäftseinheit>.<Name der> benutzerdefinierten Klassifizierung).
Beispiel: Für die benutzerdefinierte EMPLOYEE_ID Klassifizierung für das fiktive Unternehmen Contoso lautet der Name Ihrer benutzerdefinierten Klassifizierung CONTOSO.HR. EMPLOYEE_ID, und der Anzeigename wird im System als HR gespeichert. MITARBEITER-ID.

Gehen Sie beim Erstellen und Konfigurieren der Klassifizierungsregeln für eine benutzerdefinierte Klassifizierung wie folgt vor:
Wählen Sie den geeigneten Klassifizierungsnamen aus, für den die Klassifizierungsregel erstellt werden soll.
Das Microsoft Purview-Governanceportal unterstützt die folgenden beiden Methoden zum Erstellen benutzerdefinierter Klassifizierungsregeln:
Verwenden Sie die Methode regulärer Ausdruck (regex), wenn Sie das Datenelement konsistent mithilfe eines Musters für reguläre Ausdrücke ausdrücken oder das Muster mithilfe einer Datendatei generieren können. Stellen Sie sicher, dass die Beispieldaten die Auffüllung widerspiegeln.
Verwenden Sie die Dictionary-Methode nur, wenn die Liste der Werte in der Wörterbuchdatei alle möglichen Werte der zu klassifizierenden Daten darstellt und erwartet wird, dass sie einem bestimmten Satz von Daten entspricht (auch unter Berücksichtigung zukünftiger Werte).
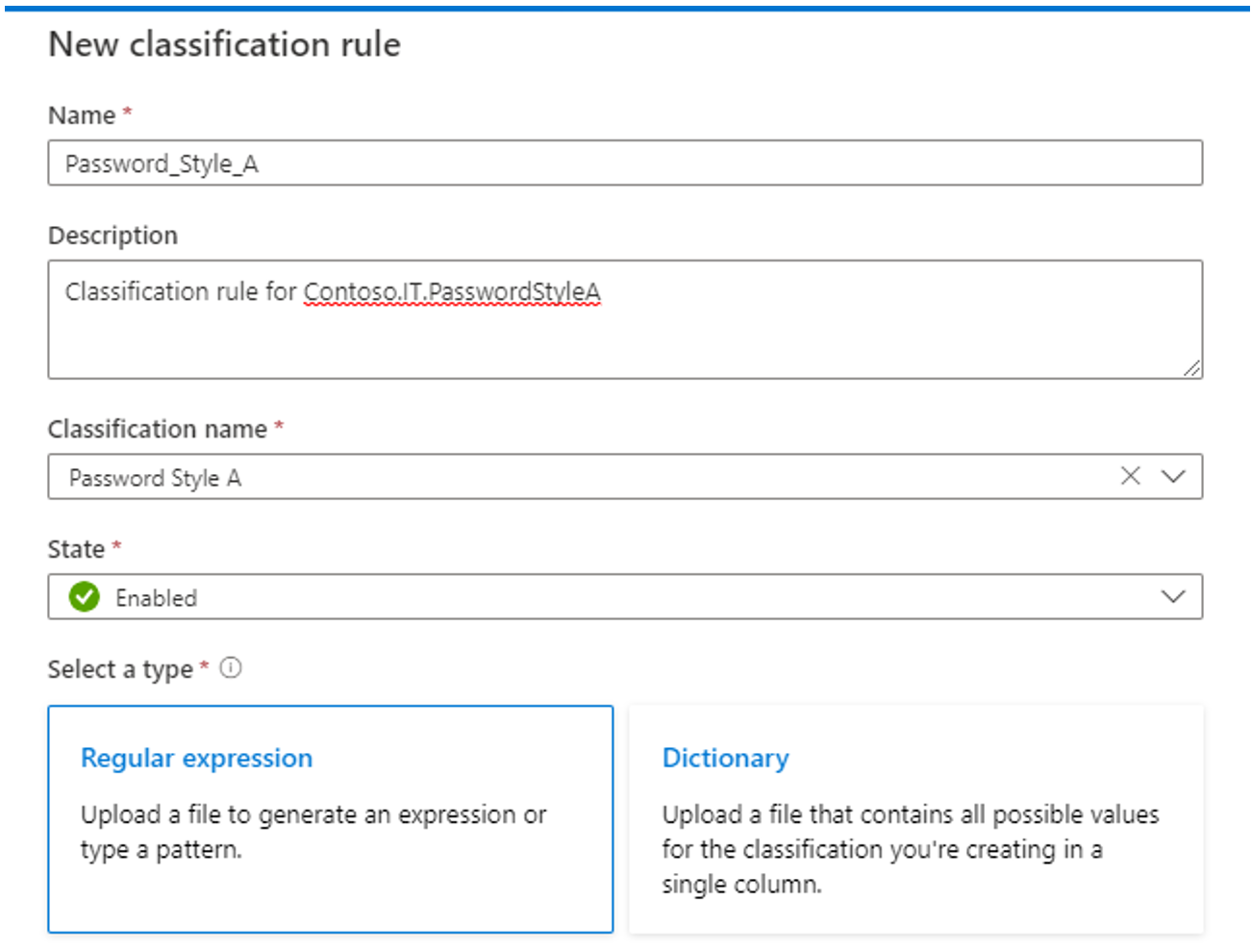
Verwenden der Methode regulärer Ausdrücke :
Konfigurieren Sie das RegEx-Muster für die zu klassifizierenden Daten. Stellen Sie sicher, dass das RegEx-Muster generisch genug ist, um die klassifizierten Daten zu erfüllen.
Microsoft Purview bietet auch ein Feature zum Generieren eines vorgeschlagenen RegEx-Musters. Nachdem Sie eine Beispieldatendatei hochgeladen haben, wählen Sie eines der vorgeschlagenen Muster aus, und wählen Sie dann Zu Mustern hinzufügen aus, um die vorgeschlagenen Daten- und Spaltenmuster zu verwenden. Sie können die vorgeschlagenen Muster ändern oder eigene Muster eingeben, ohne eine Datei hochladen zu müssen.
Sie können auch das Spaltennamenmuster für die zu klassifizierende Spalte konfigurieren, um falsch positive Ergebnisse zu minimieren.
Konfigurieren Sie den Schwellenwert für mindeste Übereinstimmung , der für Ihre Daten zulässig ist, die dem Datenmuster entsprechen, um die Klassifizierung anzuwenden. Die Schwellenwerte können zwischen 1 % und 100 % liegen. Wir empfehlen einen Wert von mindestens 60 % als Schwellenwert, um falsch positive Ergebnisse zu vermeiden. Sie können jedoch bei Bedarf für Ihre spezifischen Klassifizierungsszenarien konfigurieren. Ihr Schwellenwert kann beispielsweise so niedrig wie 1 % sein, wenn Sie eine Klassifizierung für einen beliebigen Wert in den Daten erkennen und anwenden möchten, wenn er mit dem Muster übereinstimmt.
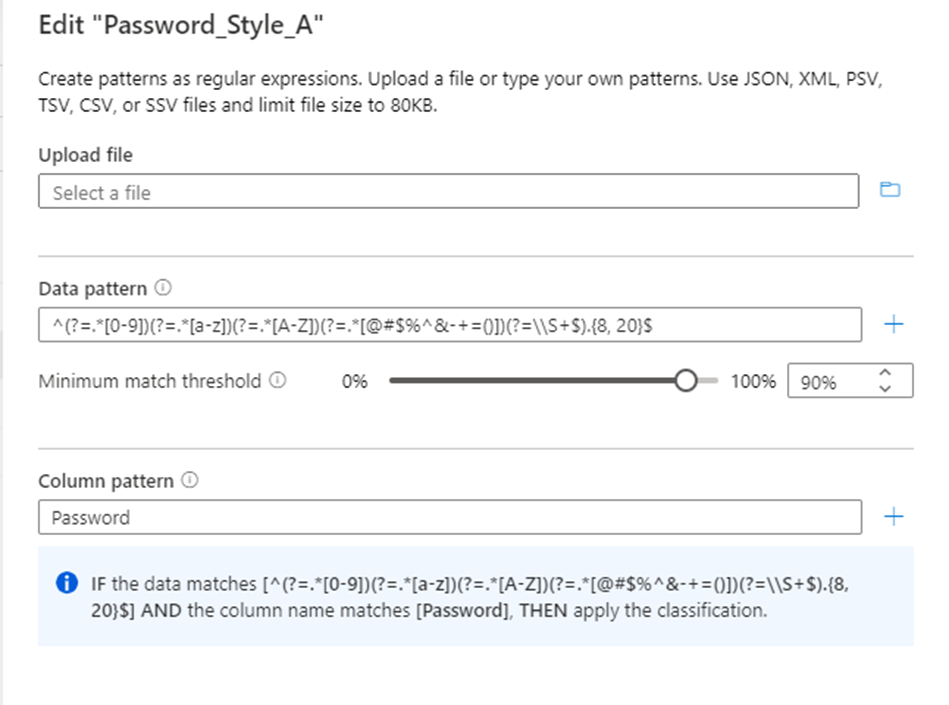
Die Option zum Festlegen einer Mindestvergleichsregel wird automatisch deaktiviert, wenn der Klassifizierungsregel mehr als ein Datenmuster hinzugefügt wird.
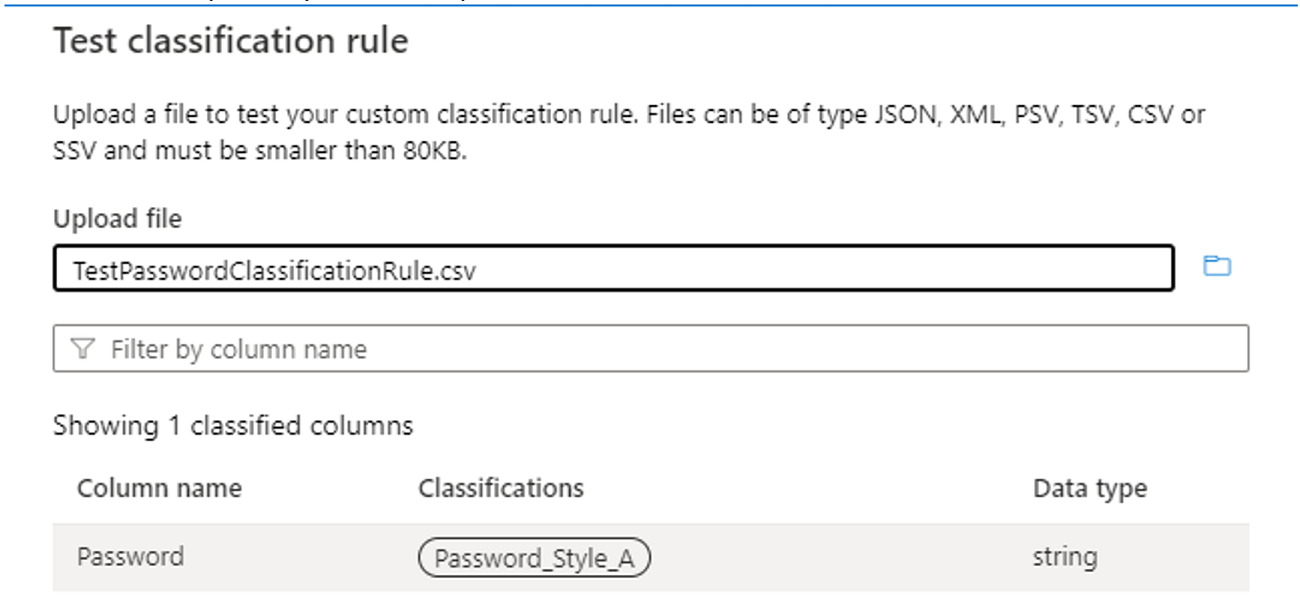
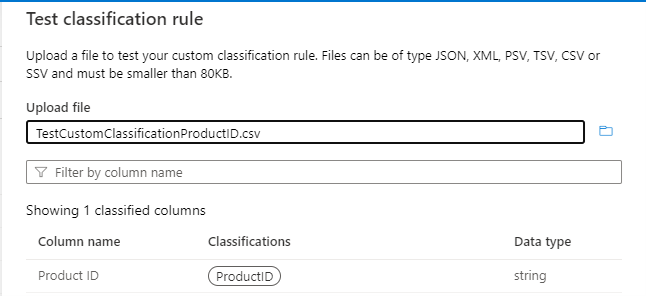
Verwenden Sie die Testklassifizierungsregel , und testen Sie mit Beispieldaten, um zu überprüfen, ob die Klassifizierungsregel wie erwartet funktioniert. Stellen Sie sicher, dass in den Beispieldaten (z. B. in einer .csv Datei) mindestens drei Spalten vorhanden sind, einschließlich der Spalte, auf die die Klassifizierung angewendet werden soll. Wenn der Test erfolgreich ist, sollte die Klassifizierungsbezeichnung in der Spalte angezeigt werden, wie in der folgenden Abbildung dargestellt:
Verwenden der Dictionary-Methode :
Sie können die Dictionary-Methode verwenden, um Enumerationsdaten anzupassen oder wenn die Wörterbuchliste der möglichen Werte verfügbar ist.
Diese Methode unterstützt .csv- und TSV-Dateien mit einer Dateigrößenbeschränkung von 30 Megabyte (MB).



Archetypen für benutzerdefinierte Klassifizierungen
Funktionsweise des Parameters "threshold" im regulären Ausdruck
Betrachten Sie die Beispielquelldaten in der folgenden Abbildung. Es gibt fünf Spalten, und die benutzerdefinierte Klassifizierungsregel sollte auf Spalten Sample_col1, Sample_col2 und Sample_col3 für das Datenmuster N{Digit}{Digit}{Digit}AN angewendet werden.
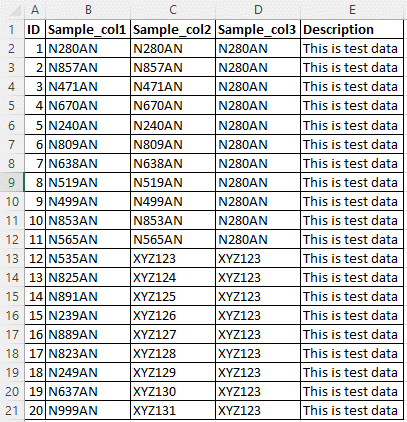
Die benutzerdefinierte Klassifizierung heißt NDDDAN.
Die Klassifizierungsregel (regex für das Datenmuster) lautet ^N[0-9]{3}AN$.
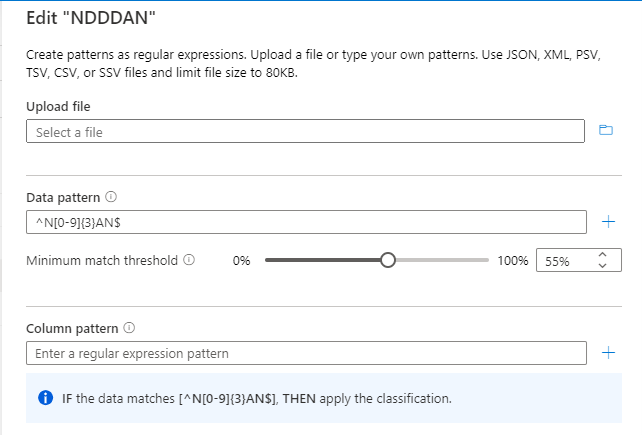
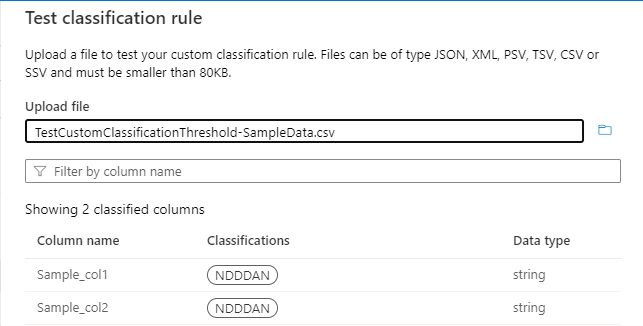
Der Schwellenwert wird für das Muster "^N[0-9]{3}AN$" berechnet, wie in der folgenden Abbildung dargestellt:

Bei einem Schwellenwert von 55 % werden nur Spalten Sample_col1 und Sample_col2 klassifiziert. Sample_col3 werden nicht klassifiziert, da sie das Schwellenwertkriterium von 55 % nicht erfüllt.




Verwenden von Daten- und Spaltenmustern
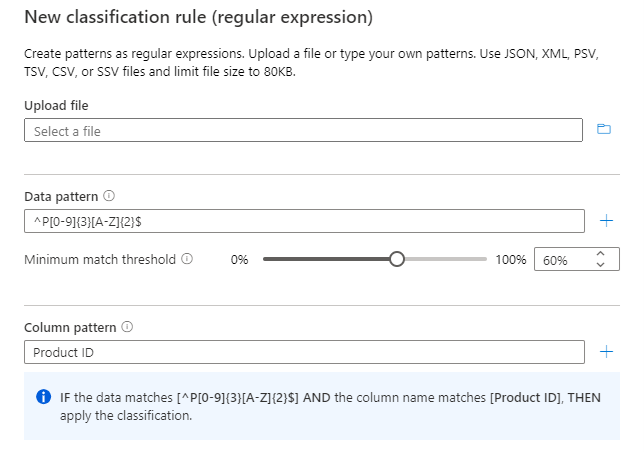
Für die angegebenen Beispieldaten, bei denen spalte B und Spalte C ähnliche Datenmuster aufweisen, können Sie spalte B basierend auf dem Datenmuster "^P[0-9]{3}[A-Z]{2}$" klassifizieren.
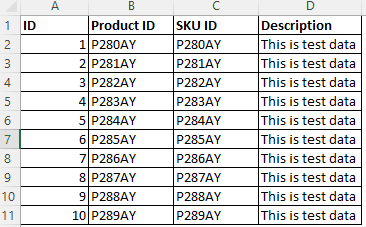
Verwenden Sie das Spaltenmuster zusammen mit dem Datenmuster, um sicherzustellen, dass nur die Spalte Produkt-ID klassifiziert wird.
Hinweis
Das Spaltenmuster wird als AND-Bedingung mit dem Datenmuster überprüft.
Verwenden Sie die Testklassifizierungsregel , und testen Sie mit Beispieldaten, um zu überprüfen, ob die Klassifizierungsregel wie erwartet funktioniert.



Verwenden mehrerer Spaltenmuster
Wenn mehrere Spaltenmuster für dieselbe Klassifizierungsregel klassifiziert werden müssen, verwenden Sie durch Striche getrennte Spaltennamen (|). Schreiben Sie beispielsweise für die Spalten Produkt-ID, Product_ID, ProductID usw. das Spaltenmuster, wie in der folgenden Abbildung gezeigt:

Weitere Informationen finden Sie unter RegEx-Alternation-Konstrukt.
Überlegungen zur Klassifizierung
Im Folgenden sind einige Überlegungen aufgeführt, die Sie beim Definieren von Klassifizierungen berücksichtigen sollten:
Um zu entscheiden, welche Klassifizierungen vor dem Scannen auf die Ressourcen angewendet werden müssen, überlegen Sie, wie Ihre Klassifizierungen verwendet werden sollen. Unnötige Klassifizierungsbezeichnungen können für Datenconsumer verrauscht und sogar irreführend aussehen. Sie können Klassifizierungen für Folgendes verwenden:
- Beschreiben Sie die Art der Daten, die in der Datenressource oder dem Schema vorhanden sind, die überprüft werden. Anders ausgedrückt: Klassifizierungen sollten es Kunden ermöglichen, den Inhalt der Datenressource oder des Schemas aus den Klassifizierungsbezeichnungen zu identifizieren, während sie den Katalog durchsuchen.
- Legen Sie Prioritäten fest, und entwickeln Sie einen Plan, um die Sicherheits- und Complianceanforderungen eines organization zu erfüllen.
- Beschreiben Sie die Phasen in den Datenaufbereitungsprozessen (rohe Zone, Zielzone usw.), und weisen Sie die Klassifizierungen bestimmten Ressourcen zu, um die Phase im Prozess zu markieren.
Sie können Klassifizierungen auf Ressourcen- oder Spaltenebene automatisch zuweisen, indem Sie relevante Klassifizierungen in die Überprüfungsregel aufnehmen, oder Sie können sie manuell zuweisen, nachdem Sie die Metadaten in der Microsoft Purview Data Map erfasst haben.
Informationen zur automatischen Zuweisung finden Sie unter Unterstützte Datenspeicher im Microsoft Purview-Governanceportal.
Bevor Sie Ihre Datenquellen im Microsoft Purview Data Map überprüfen, ist es wichtig, Ihre Daten zu verstehen und den entsprechenden Überprüfungsregelsatz dafür zu konfigurieren (z. B. durch Auswahl der relevanten Systemklassifizierung, benutzerdefinierten Klassifizierungen oder einer Kombination aus beidem), da dies sich auf Ihre Scanleistung auswirken könnte. Weitere Informationen finden Sie unter Unterstützte Klassifizierungen im Microsoft Purview-Governanceportal.
Der Microsoft Purview-Scanner wendet Datensamplingregeln für tiefe Scans (klassifizierungspflichtig) sowohl für Systemklassifizierungen als auch für benutzerdefinierte Klassifizierungen an. Die Samplingregel basiert auf dem Typ der Datenquellen. Weitere Informationen finden Sie im Abschnitt "Sampling in einer Datei" unter Unterstützte Datenquellen und Dateitypen in Microsoft Purview.
Hinweis
Eindeutiger Datenschwellenwert: Dies ist die Gesamtzahl der unterschiedlichen Datenwerte, die in einer Spalte gefunden werden müssen, bevor der Scanner das Datenmuster darauf ausführt. Der eindeutige Datenschwellenwert hat nichts mit dem Musterabgleich zu tun, ist aber eine Voraussetzung für den Musterabgleich. Systemklassifizierungsregeln erfordern, dass in jeder Spalte mindestens 8 unterschiedliche Werte vorhanden sind, um sie der Klassifizierung zu unterziehen. Das System erfordert diesen Wert, um sicherzustellen, dass die Spalte genügend Daten enthält, damit der Scanner sie genau klassifizieren kann. Beispielsweise wird eine Spalte, die mehrere Zeilen enthält, die alle den Wert 1 enthalten, nicht klassifiziert. Spalten, die eine Zeile mit einem Wert enthalten, und die restlichen Zeilen haben NULL-Werte, werden ebenfalls nicht klassifiziert. Wenn Sie mehrere Muster angeben, gilt dieser Wert für jedes muster.
Die Samplingregeln gelten auch für Ressourcensätze. Weitere Informationen finden Sie im Abschnitt "Stichprobenerstellung für Ressourcensatzdateien" unter Unterstützte Datenquellen und Dateitypen im Microsoft Purview-Governanceportal.
Benutzerdefinierte Klassifizierungen können nicht mithilfe benutzerdefinierter Klassifizierungsregeln auf Dokumenttypressourcen angewendet werden. Klassifizierungen für solche Typen können nur manuell angewendet werden.
Benutzerdefinierte Klassifizierungen sind in keinen Standardüberprüfungsregeln enthalten. Wenn daher eine automatische Zuweisung von benutzerdefinierten Klassifizierungen erwartet wird, müssen Sie eine benutzerdefinierte Überprüfungsregel bereitstellen und verwenden, die die benutzerdefinierte Klassifizierung enthält, um die Überprüfung auszuführen.
Wenn Sie Klassifizierungen manuell über das Microsoft Purview-Governanceportal anwenden, werden diese Klassifizierungen in nachfolgenden Überprüfungen beibehalten.
Nachfolgende Überprüfungen entfernen keine Klassifizierungen aus Ressourcen, wenn sie zuvor erkannt wurden, auch wenn die Klassifizierungsregeln nicht angewendet werden können.
Für verschlüsselte Quelldatenobjekte wählt Microsoft Purview nur Dateinamen, vollqualifizierte Namen, Schemadetails für strukturierte Dateitypen und Datenbanktabellen aus. Damit die Klassifizierung funktioniert, entschlüsseln Sie die verschlüsselten Daten, bevor Sie Scans ausführen.