Neugestaltung der Unternehmenssuchetopologie für bestimmte Leistungsanforderungen in SharePoint
GILT FÜR: 2013 2016 2019 Subscription Edition
2013 2016 2019 Subscription Edition  SharePoint in Microsoft 365
SharePoint in Microsoft 365
Wenn Ihre Suchumgebung bestimmte Leistungsanforderungen aufweist, die durch Befolgen der Anleitung unter Planen der Architektur der Unternehmenssuche in SharePoint Server 2016 nicht erfüllt werden, besteht die Lösung im Skalieren der Topologie Ihrer Architektur für die Unternehmenssuche.
Umgestalten der Topologie (dieser Artikel)
Implementieren der umgestalteten Topologie (Verwalten der Suchtopologie in SharePoint Server)
Kennen Sie die Komponenten des Suchsystems in SharePoint Server 2016, und wissen Sie, wie diese Komponenten miteinander interagieren? Bevor Sie dieses Projekt in Angriff nehmen, sollten Sie zunächst den Artikel Übersicht über die Sucharchitektur in SharePoint Server lesen und sich die PDF-Datei Search architectures for SharePoint Server 2016 (oder die Datei Sucharchitekturen für SharePoint Server 2013) ansehen, um sich mit den verschiedenen Sucharchitekturen und Suchkomponenten, den Suchdatenbanken und der Suchtopologie vertraut zu machen.
In diesem Artikel zeigen wir Ihnen, wie Sie Ihre Suchtopologie schrittweise umgestalten, um bestimmte Leistungsanforderungen zu erfüllen:
Schritt 1: Was sind die spezifischen Leistungsanforderungen?
Schritt 3: Auswählen, ob die Server physisch oder virtuell ausgeführt werden sollen
Schritt 4: Auf welchem Server soll welche Suchkomponente oder Datenbank gehostet werden?
Schritt 5: Welche Hardwareanforderungen muss ich berücksichtigen?
Nachdem Sie diese Schritte ausgeführt haben, werden Sie Folgendes wissen:
Die Anzahl der einzelnen Typen von Suchkomponenten und Suchdatenbanken, die Ihre Topologie benötigt.
Die Anwendungs- und Datenbankserver, auf denen die einzelnen Suchkomponenten bereitgestellt werden sollen.
Die Hardwareressourcen, die jeder Anwendungs- und Datenbankserver benötigt.
Schritt 1: Was sind die spezifischen Leistungsanforderungen?
Stellen Sie sicher, dass Sie die geschäftlichen Anforderungen hinter den spezifischen Leistungsanforderungen verstehen. Beispielsweise erfordern Nachrichten- und Finanzsuche neue Daten, die nahezu in Echtzeit indiziert werden, während Supportdienste für Rechtsstreitigkeiten die Erfassung von Datenbatches erfordern, die einmal indiziert werden. Geben Sie die Leistungsanforderungen auf eine oder mehrere der folgenden Arten zum Ausdruck:
Anzahl indizierter Elemente
Anzahl der Elemente, die die Suchlösung pro Sekunde durchforsten muss, samt Latenz
Anzahl der Abfragen, die die Suchlösung pro Sekunde erfüllen muss, samt Latenz
Zusätzlich zu diesen Leistungsanforderungen verfügt Ihre Umgebung möglicherweise auch über Anforderungen für die Relevanz von Abfrageergebnissen und die Redundantkeit der Suchtopologie. Manchmal haben Sie keine bestimmte Leistungsanforderung, aber Sie haben einen Engpass in der Sucharchitektur identifiziert, der sich auf die Leistung auswirken kann. Das werden wir auch behandeln.
Schritt 2: Welche Suchkomponenten sollte ich skalieren?
Zum Ermöglichen einer höheren Leistung oder Entfernen eines Engpasses können Sie weitere Suchkomponenten hinzufügen oder den Servern, die die Suchkomponenten hosten, mehr Ressourcen hinzufügen. Das Hinzufügen weiterer Suchkomponenten wird als horizontales Skalieren, das Hinzufügen weiterer Ressourcen zu Servern als vertikales Skalieren bezeichnet. Welche Suchkomponenten horizontal oder welche Server vertikal skaliert wenden sollten, hängt von der zu verbessernden Leistungsmetrik oder dem zu entfernenden Engpass ab. Es folgen einige Beispiele:
Wenn die Umgebung eine höhere Abfragerate benötigt und die CPU-Ressourcen zur Indizierung ein Engpass sind, fügen Sie jeder Indexpartition ein weiteres Indexreplikat hinzu. Dadurch können mehr Abfragen parallel verarbeitet werden.
Wenn die CPU-Ressourcen zum Verarbeiten durchforsteter Inhalte ein Engpass sind, skalieren Sie die Anzahl der Inhaltsverarbeitungskomponenten vertikal. Sie können diese Komponenten auch horizontal skalieren, indem Sie sie auf Servern mit mehr oder schnelleren CPUs ausführen. Bei beiden Arten der Skalierung stehen für die Verarbeitung von Inhalten mehr CPU-Ressourcen zur Verfügung.
Wenn die Analysekomponenten die Analysen nicht schnell genug bewerkstelligen, skalieren Sie die Prozessorressourcen, E/A-Leistung pro Sekunde der Datenträger oder Netzwerkbandbreite der Server, die als Hosts von Analysekomponenten dienen.
Beachten Sie, dass die vertikale Skalierung der Anzahl von Suchkomponenten oder Datenbanken nicht unbegrenzt unterstützt wird. Schlagen Sie unter Suchgrenzen die Höchstgrenzen nach, und halten Sie diese ein, um eine rasche und zuverlässige Kommunikation zwischen den Suchkomponenten und Datenbanken sicherzustellen. Senken Sie bei Bedarf die Kapazität Ihrer Sucharchitektur, indem Sie die Anzahl der Suchkomponenten verringern.
In den folgenden Abschnitten finden Sie Anleitungen dazu, welche Suchkomponenten oder Datenbanken zum Erfüllen der jeweiligen Anforderung skaliert werden müssen:
Verkürzen der Abfragelatenz und Erhöhen des Abfragedurchsatzes
Ermöglichen von Redundanz für Ihre Suchkomponenten und Datenbanken
Unterstützen von mehr Elementen im Index
Wenn die Menge indizierter Elemente zunimmt, während sich die indizierten Elemente mit derselben Rate wie zuvor ändern, erhöhen Sie die Kapazität Ihrer Suchtopologie, indem Sie diese Suchkomponenten und Datenbanken skalieren:
| Suchkomponente oder Datenbank | Anleitung |
|---|---|
| Indexkomponente | Verwenden Sie eine (1) Indexpartition je 20 Mio.1 indizierten Elemente. Jede Partition enthält ein oder mehrere Replikate der Partition. Alle Partitionen müssen die gleiche Anzahl von Replikaten haben. Eine Indexkomponente stellt ein Indexreplikat dar. Wenn Sie also zwei Replikate des Indexes wünschen, benötigen Sie zweimal so viele Indexkomponenten wie Indexpartitionen. Angenommen, ein redundanter Index mit 80 Mio.2 Elementen benötigt vier Partitionen. Wenn Sie pro Partition zwei Replikate verwenden, werden die vier Partitionen durch acht Indexkomponenten repräsentiert. |
| Durchforstungsdatenbank | Verwenden Sie eine Durchforstungsdatenbank für jeweils 20 Millionen Element im Inhaltskorpus. Ein Index mit 100 Millionen Elementen erfordert beispielsweise fünf Durchforstungsdatenbanken. Wenn die gestiegene Menge an indizierten Elementen zu einer höheren Durchforstungsrate führt, benötigen Sie auch eine höhere E/A-Leistung pro Sekunde, um die Durchforstungsdatenbanken zu unterstützen. Wenn Ihre Durchforstungsrate ein Dokument pro Sekunde ist, benötigt die Durchforstungsdatenbank etwa 10 E/A pro Sekunde. |
| Linkdatenbank | Verwenden Sie eine Linkdatenbank für jeweils 60 Millionen Elemente im Inhaltskorpus. Ein Index mit 100 Millionen Elementen erfordert beispielsweise zwei Linkdatenbanken. Wenn der hinzugefügte Inhalt zu einer höheren Durchforstungsrate führt, benötigen Sie ggf. auch eine höhere E/A-Leistung pro Sekunde, um die Linkdatenbanken zu unterstützen. |
| Analyseberichtsdatenbank | Wie viele Analyseberichtsdatenbanken Sie benötigen, hängt davon ab, wie und wie oft die Suchumgebung Analysen verwendet. Fügen Sie im Allgemeinen eine Analyseberichtsdatenbank hinzu, wenn die Analyseleistung abnimmt. Beispielsweise, wenn die nächtliche Aktualisierung der Datenbank mehr Zeit in Anspruch nimmt. Dies kann passieren, wenn die Datenbank eine Größe von 250 GB oder insgesamt 20 Millionen Zeilen erreicht oder wenn die Anzahl der Ansichten pro Tag 500.000 eindeutige Elemente erreicht. |
110 Millionen Elemente mit SharePoint Server 2013 oder sharePoint Server 2016, die mit weniger Ressourcen als 500 GB Speicher, 32 GB RAM und acht CPU-Kernen ausgeführt werden.
240 Millionen Elemente mit SharePoint Server 2013 oder sharePoint Server 2016, die mit weniger Ressourcen als 500 GB Speicher, 32 GB RAM und acht CPU-Kernen ausgeführt werden.
Erhöhen der Erfassungsrate und Aktualität von Ergebnissen
Es gibt einige Situationen, in denen Sie die Erfassungsrate erhöhen müssen. Ein Beispiel ist, wenn Ihre Umgebung sehr frische Ergebnisse erfordert und das Inhaltsvolumen nahe am oberen Elementgrenzwert für Ihre Sucharchitektur liegt oder sich der Inhalt häufig ändert. Inhalte können sich häufig ändern, wenn Personen Dateien auf einer Teamwebsite archiviert haben, aber jetzt speichern sie ihre Dateien auf OneDrive, während sie daran arbeiten. Die Suche indiziert alle Änderungen, die Personen an ihren Dateien vornehmen.
Es ist nützlich zu verstehen, welche Faktoren das Tempo der Erfassung von Elementen beeinflussen:
Wie schnell die Suche Elemente durchforsten kann. Dies hängt von Folgendem ab:
Der Geschwindigkeit der Verbindung zwischen den Durchforstungskomponenten und Inhaltsquellen
Dem Typ und der durchschnittlichen Größe der zu durchsuchenden Elemente
Der Leistung des Computers mit SQL Server mit den Durchforstungsdatenbanken
Der CPU-Leistung und den Arbeitsspeicherressourcen der Durchforstungskomponenten
Dem Aufwand der Inhaltsverarbeitung der einzelnen Elemente vor der Indizierung
Der Anzahl der Indexpartitionen. Je mehr Partitionen, desto besser die Lastverteilung für die Indizierung
Gehen Sie folgendermaßen vor:
Überprüfen Sie die Aktualität der Ergebnisse in Ihrer Farm, indem Sie sich die Altersverteilung der durchforsteten Elemente ansehen. Wechseln Sie in der die Website für die SharePoint-Zentraladministration zu Integritätsberichte für Durchforstung, und wählen Sie Durchforstungsaktualität. Welche Altersverteilung für Ihre Farm akzeptabel ist, hängt von Ihren Geschäftsanforderungen ab. Hier ein Beispiel: Wenn die Seite Durchforstungsaktualität angibt, dass die Indizierung von 90 % des Inhalts vier Stunden dauert, Ihre Anforderung jedoch 30 Minuten ist, erhöhen Sie die Erfassungsrate entsprechend.
Bestimmen Sie auf der Seite Durchforstungsaktualität, in welchen Phasen des Tages Ergebnisse nicht aktuell genug sind.
Befolgen Sie die Anleitungen zum Erhöhen der Erfassungsgeschwindigkeit zu diesen Zeiten.
Verbessern der Aktualität für eine bestimmte Inhaltsquelle
Prüfen Sie den Durchforstungszeitplan, und bestimmen Sie, welche Inhaltsquellen die Suchfunktion in den Zeiten durchforstet, in denen die Aktualität niedrig ist. Wenn die Aktualität für eine bestimmte Inhaltsquelle niedrig ist, erwägen Sie Folgendes:
Erhöhen Sie die Geschwindigkeit der Verbindung zwischen dem Server, der die Durchforstungskomponenten hostet, und dieser Inhaltsquelle. Es sind die Durchforstungsrate, das Herunterladen von Elementen aus Inhaltsquellen und das Übergeben der Elemente an die Inhaltsverarbeitungskomponente, die den Bedarf an Netzwerkbandbreite für die Durchforstungskomponente erhöhen.
Wenn SharePoint die Inhaltsquelle ist, benötigt diese Farm weitere und dedizierte Durchforstungsziele. Informationen zu Durchforstungszielen finden Sie unter Verwalten der Durchforstungslast (SharePoint Server 2010).
Verbessern Sie die Leistung der Inhaltsdatenbank. Informationen dazu finden Sie unter Bewährte Methoden für SQL Server in einer SharePoint Server-Farm.
Erhöhen der Verarbeitungsressourcen für die Durchforstung
Wenn die Durchforstungskomponente häufig 100 % der Prozessorressourcen verwendet, sollten Sie erwägen, eine weitere Durchforstungskomponente oder weitere Prozessorressourcen zu den Servern hinzuzufügen, die Durchforstungskomponenten hosten. Es sind die Durchforstungsrate, die Ermittlung von Links und die Verwaltung der Durchforstung, die den Bedarf an Prozessorressourcen antreiben. Normalerweise ist die Durchforstung schnell genug, wenn Sie zwei Durchforstungskomponenten in Sucharchitekturen wie den von Microsoft geschätzten kleinen und mittleren Beispielsucharchitekturen verwenden. Sucharchitekturen wie die großen und besonders großen Beispiele benötigen möglicherweise mehr als zwei Durchforstungskomponenten.
Erhöhen der Verarbeitungsressourcen für die Durchforstungsdatenbank
Prüfen Sie, ob die SQL Server-Computer, die die Durchforstungsdatenbanken hosten, über genügend Ressourcen verfügen. Weitere Informationen finden Sie unter Bewährte Methoden für SQL Server in einer SharePoint Server-Farm.
Wenn alle Durchforstungsdatenbanken viele Prozessorressourcen nutzen, erwägen Sie das Hinzufügen weiterer Prozessorressourcen zum Computer mit SQL Server, der die Datenbanken hostet, oder fügen Sie einen weiteren Computer mit SQL Server hinzu, der dieselbe Anzahl von Durchforstungsdatenbanken wie die vorhandenen Computer mit SQL Server aufweist. Wenn Sie beispielsweise zwei Computer mit SQL Server haben, die je drei Durchforstungsdatenbanken enthalten, fügen Sie einen weiteren Computer mit SQL Server mit drei Durchforstungsdatenbanken hinzu.
Wenn nur eine oder wenige Durchforstungsdatenbanken viele Prozessorressourcen verwenden, bedeutet dies, dass die Last in den Durchforstungsdatenbanken ungleichmäßig ist. Erwägen Sie, den Inhalt über alle Durchforstungsdatenbanken hinweg neu zu verteilen. Beachten Sie, dass während der Neuverteilung der Suche die Durchforstung anhält, sodass die Ergebnisse beim Neuausgleich weniger aktuell sind und bis die Durchforstung mit den Änderungen, die während der Pause vorgenommen wurden, aufgeholt wurde. Sie lösen die Neuverteilung mit der Schaltfläche Gleichgewicht auf der Seite Datenbanken aus. Wechseln Sie unter Suchverwaltung zu Durchforstungsprotokoll , und wählen Sie Datenbanken aus.
Erhöhen der Verarbeitungs- und Arbeitsspeicherressourcen für die Inhaltsverarbeitung
Wenn die Inhaltsverarbeitungskomponente nahezu 100 % der CPU-Ressourcen belegt, erwägen Sie das Hinzufügen weiterer Inhaltsverarbeitungskomponenten oder weiterer CPU-Ressourcen zu den Servern, die Inhaltsverarbeitungskomponenten hosten.
Wenn Sie feststellen, dass der Arbeitsspeicher oft neu startet, erwägen Sie das Vergrößern des Arbeitsspeichers auf Servern, die Inhaltsverarbeitungskomponenten hosten. Eine gute Faustregel sind 2 GB Arbeitsspeicher pro CPU-Kern.
Erhöhen der Anzahl der Indexpartitionen
Prüfen Sie die Inhaltsverarbeitungsaktivität. Wechseln Sie dazu zu Suchverwaltung, wählen Sie Integritätsberichte für Durchforstung und dann Inhaltsverarbeitungsaktivität aus. Wenn die Indizierung die Aktivität ist, die am längsten dauert, erwägen Sie das Aufteilen des Indexes in mehr Partitionen. Bei mehr Indexpartitionen kann die Suchfunktion die Last der Indizierung verteilen.
Wenn Sie einer aktiven Installation weitere Partitionen hinzufügen, partitioniert sich der Index selbst neu. Dieser Vorgang kann mehrere Stunden oder gar Tage dauern. Die genaue Dauer hängt zum Zustand der Farm zum Zeitpunkt der Neupartitionierung ab.
Verkürzen der Abfragelatenz und Erhöhen des Abfragedurchsatzes
Die Anzahl der Abfragen, die die Suchfunktion pro Sekunde erfüllen kann, wird als Abfragedurchsatz bezeichnet. Dieser hängt von der Zeit, die die Suchfunktion benötigt, um eine Abfrage zu verarbeiten, und den Wartezeiten der Abfrage ab, wenn eine Verarbeitungsressource nicht verfügbar ist. Die Summe aus Verarbeitungs- und Wartezeit wird als Abfragelatenz bezeichnet. Durch die Reduzierung der Abfragelatenz erhöht sich der Abfragedurchsatz. Befolgen Sie eine oder beide der folgenden Anleitungen, um die Abfragelatenz zu verkürzen:
| Anleitung |
|---|
| Verkürzen der Verarbeitungszeit von Abfragen |
| Verkürzen der Wartezeit von Abfragen |
Verkürzen der Verarbeitungszeit von Abfragen
Erwägen Sie das Hinzufügen weiterer Partitionen zum Index. Mehr Partitionen bedeuten weniger Elemente je Partition. Weniger Elemente bedeuten, dass jede Partition schneller auf Abfragen reagiert. Doch zu viele Partitionen sind auch nicht ideal. Da die Abfrageverarbeitungskomponente die Antworten der einzelnen Partitionen zum Generieren einer Antwort auf eine Abfrage zusammenführen muss, dauert das Zusammenführen länger, wenn der Index mehr Partitionen hat. Alle Partitionen müssen dieselbe Anzahl von Replikaten haben.
Wenn Sie einer aktiven Installation weitere Partitionen hinzufügen, partitioniert sich der Index selbst neu. Dieser Vorgang kann mehrere Stunden oder gar Tage dauern. Die genaue Dauer hängt zum Zustand der Farm zum Zeitpunkt der Neupartitionierung ab.
Verkürzen der Wartezeit von Abfragen
Erwägen Sie diese Aktionen:
Fügen Sie dem Index weitere Replikate hinzu. Wenn Sie weitere Replikate hinzufügen, verteilt die Suchfunktion die Abfrage auf die Replikate und arbeitet sie parallel ab. Eine Indexkomponente stellt ein Indexreplikat dar. Alle Partitionen müssen dieselbe Anzahl von Replikaten aufweisen, weshalb Sie jeder Indexpartition eine Indexkomponente hinzufügen müssen. Wenn Sie vorhandenen Partitionen einer aktiven Installation Indexkomponenten als Replikate hinzufügen, versieht die Suchfunktion die neuen Replikate automatisch mit Daten aus der Indexpartition. Es kann mehrere Stunden dauern, bis die neuen Replikate den Betrieb aufnehmen können.
Fügen Sie mehr Arbeitsspeicher den Servern hinzu, die Indexkomponenten hosten.
Wechseln Sie auf den Servern mit Indexkomponenten zu einem schnelleren Speicher für den Index, z. B. SSD-Laufwerken (Solid State Drives).
Fügen Sie mehr Prozessorressourcen den Servern hinzu, die Indexkomponenten hosten. Dann können die Komponenten mehr Abfragen pro Sekunde verarbeiten. Wenn der Server beispielsweise eine CPU mit 2 GHz hat, kann ein Kern Folgendes verarbeiten:
5 Abfragen pro Sekunde bei 1 Mio. Elementen im Index
2 Abfragen pro Sekunde bei 5 Mio. Elementen im Index
1 Abfrage pro Sekunde bei 10 Mio. Elementen im Index
Fügen Sie mehr Prozessorressourcen den Servern hinzu, die Abfrageverarbeitungskomponenten hosten. Dann verarbeiten die Komponenten mehr Abfragen pro Sekunde, insbesondere wenn Abfragen selten und komplex sind. Es sind die Abfragerate und die Anzahl der Abfragetransformationen, die den Bedarf an Prozessorressourcen für die Abfrageverarbeitungskomponente erhöhen. Eine Abfrageverarbeitungskomponente benötigt in der Regel einen CPU-Kern je vier Abfragen pro Sekunde.
Verkürzen der Verarbeitungszeit von Analysen
Die Analyseverarbeitung erfolgt über Nacht. Die Analyseverarbeitungskomponente speichert Zwischendaten auf dem Server, der die Komponente hostet, und die Ergebnisse der Analyse in der Analyseberichtsdatenbank. Wenn ein Fehler die Verarbeitung von Analysen verhindert, wirkt sich dies nicht auf die Durchforstung von Dokumenten oder Beantwortung von Abfragen aus. Doch die Abfrageergebnisse haben dann nicht die optimale Relevanz.
Erwägen Sie diese Aktionen:
Wenn Ihre Umgebung eine optimale Relevanz von Abfrageergebnissen erfordert und die Analyseverarbeitung dafür nicht schnell genug ist, fügen Sie weitere oder schnellere Datenträger hinzu.
Wenn die Analyseverarbeitung mehr Zeit als üblich in Anspruch nimmt, fügen Sie eine Analyseberichtsdatenbank hinzu. Ein solcher Anstieg kann auftreten, wenn die Datenbank eine Größe von 250 GB oder insgesamt 20 Millionen Zeilen erreicht oder wenn die Anzahl der Aufrufe pro Tag 500.000 eindeutige Elemente erreicht.
Wenn die Analyseverarbeitung mehr als 24 Stunden dauert, fügen Sie entweder mehr Analyseverarbeitungskomponenten oder den Servern, die die Analyseverarbeitungskomponenten hosten, mehr Prozessorressourcen hinzu. Es sind die Anzahl der Elemente im Index und die Aktivität auf der Website, die den Bedarf an Prozessorressourcen steigern.
Falls die Analyseverarbeitung nie endet oder Sie Integritätswarnungen für die Datenträger auf den Servern mit den Analysekomponenten erhalten, fügen Sie den Servern mehr Datenträgerspeicher hinzu. Damit die Analysekomponente die größere Menge an Zwischendaten schneller verarbeiten kann, erwägen Sie das Hinzufügen weiterer Analyseverarbeitungskomponenten oder weiterer Prozessorressourcen zum Server, der die Analyseverarbeitungskomponente hostet.
Ermöglichen von Redundanz für Ihre Suchkomponenten und Datenbanken
Ihre Sucharchitektur unterstützt hohe Verfügbarkeit, wenn Sie redundante Suchkomponenten und -datenbanken in separaten Fehlerdomänen hosten. Es wird empfohlen, Ihre Suchtopologie mit redundanten Suchdatenbanken und -komponenten zu entwerfen. Alle von Microsoft getesteten Beispielsucharchitekturen verfügen über redundante Suchkomponenten und Datenbanken. Möglicherweise finden Sie es hilfreich, diese Beispiele zu untersuchen, wenn Sie an Ihrer eigenen Topologie arbeiten (siehe Unternehmenssucharchitekturen für SharePoint 2016).
Befolgen Sie die nachstehenden Anleitungen:
Versehen des Indexes mit Redundanz
Ihr Index ist redundant, wenn er über zwei oder mehr Indexreplikate pro Indexpartition verfügt. Wenn ein Server, der ein Indexreplikat hostet, fehlschlägt, kann dies möglicherweise die Leistung beeinträchtigen, aber die Suche kann weiterhin Abfragen und Indexelemente bereitstellen. Wenn die Umgebung jedoch immer die gleiche Leistung erfordert, benötigt die Suche redundantere Indexkomponenten. Beispiel: Sie haben Ihre Suchtopologie mit zwei Replikaten pro Partition entworfen, um die Wartezeit für Abfragen zu verkürzen, und Ihre Umgebung erfordert immer eine kurze Wartezeit für Abfragen. Erhöhen Sie die Anzahl der Indexreplikate pro Partition.
Alle Partitionen müssen die gleiche Anzahl von Replikaten haben. Eine Indexkomponente stellt ein Indexreplikat dar. Wenn Sie also zwei Replikate des Indexes wünschen, benötigen Sie zweimal so viele Indexkomponenten wie Indexpartitionen. Beispielsweise erfordert ein redundanter SharePoint Server 2016-Index mit 80 Millionen Elementen vier Partitionen. Wenn Sie pro Partition zwei Replikate verwenden, werden die vier Partitionen durch acht Indexkomponenten repräsentiert.
Wenn Sie vorhandenen Partitionen einer aktiven Installation Indexkomponenten als Replikate hinzufügen, versieht die Suchfunktion die neuen Replikate automatisch mit Daten aus der Indexpartition. Es kann mehrere Stunden dauern, bis die neuen Replikate betriebsbereit sind.
Versehen der Durchforstungs-, Inhaltsverarbeitungs-, Abfrageverarbeitungs-, Analyseverarbeitungs- und Suchverwaltungskomponente mit Redundanz
Nehmen wir als Beispiel die Durchforstungskomponente. Wenn Sie einen der Server mit einer Durchforstungskomponente zu Wartungszwecken außer Betrieb nehmen, kann sich dadurch die Aktualität der Ergebnisse ändern, aber die Suchfunktion kann weiter alle Inhalte durchforsten. Doch wenn in der Umgebung stets dieselbe Aktualität von Ergebnissen erforderlich ist, benötigt die Suchfunktion mehr redundante Durchforstungskomponenten. Angenommen, Sie haben eine Suchtopologie mit drei Durchforstungskomponenten entworfen und wünschen dieselbe Aktualität von Ergebnissen, auch wenn zwei der Server mit den Durchforstungskomponenten ausfallen. Fügen Sie zwei weitere Durchforstungskomponenten hinzu.
Die Suchverwaltungskomponente ist eine Ausnahme von diesem Prinzip. Eine Suchverwaltungskomponente verfügt über genügend Kapazität für suchtopologien beliebiger Größe. Daher reichen zwei Suchverwaltungskomponenten für Redundanz aus.
Inhaltsverarbeitungskomponenten arbeiten mit gegenseitigem Lastenausgleich, sodass redundante Inhaltsverarbeitungskomponenten die Kapazität zum Verarbeiten von Elementen erhöhen.
Versehen der Suchdatenbanken mit Redundanz
Um Ihre Suchdatenbanken mit Redundanz zu versehen, verwenden Sie die von SQL Server bereitgestellten Hochverfügbarkeitsalternativen (siehe Erstellen einer Hochverfügbarkeitsarchitektur und -strategie für SharePoint Server).
Schritt 3: Auswählen, ob die Server physisch oder virtuell ausgeführt werden sollen
Bei der ursprünglichen Planung Ihrer Sucharchitektur haben Sie sich für den Einsatz von physischen Servern oder virtuellen Computern oder einer Kombination aus beidem entschieden. Prüfen Sie, ob diese Entscheidung noch gültig ist. Wenn Sie mittlerweile über wesentlich mehr Suchkomponenten verfügen, können Sie auch virtuelle Computer einsetzen, um die Verwaltung der Architektur zu erleichtern. Es ist beispielsweise einfacher, einen fehlerhaften virtuellen Computer zu ersetzen als einen physischen Computer. Beachten Sie jedoch, dass obwohl eine virtuelle Umgebung einfacher zu verwalten ist, ihr Leistungsgrad mitunter geringfügig niedriger ist als der einer physischen Umgebung ist. Auf einem physischen Server können mehr Suchkomponenten gehostet werden als auf einem virtuellen Server. Nützliche Anleitungen finden Sie unter Overview of farm virtualization and architectures for SharePoint 2013.
Schritt 4: Auf welchem Server soll welche Suchkomponente oder Datenbank gehostet werden?
Nachdem Sie Ihre Suchtopologie umgestaltet haben, ist der nächste Schritt das Zuweisen der Such- und Datenbankkomponenten zu physischen oder virtuellen Servern. Es gibt nicht den einen optimalen Weg, physischen oder virtuellen Computern Suchkomponenten zuzuweisen, doch wir stehen Ihnen mit Anleitungen zur Seite:
Ein Suchkomponententyp pro Server
Jeder physische Server oder virtuelle Computer kann nur eine Suchkomponente der einzelnen Typen hosten. Eine Ausnahme bildet die Indexkomponente. Physische Server oder virtuelle Computer können bis zu vier Indexkomponenten hosten. Weitere Informationen zu diesen Grenzwerten finden Sie unter Softwarebeschränkungen und -grenzen für SharePoint 2016.
Trennen Sie Massenverarbeitungs- und Echtzeitkomponenten voneinander
Vermeiden Sie das Kombinieren von Massenverarbeitungs- und Echtzeitverarbeitungssuchkomponenten auf demselben physischen Server oder virtuellen Computer. Durchforstungs-, Inhaltsverarbeitungs- und Analyseverarbeitungskomponenten führen eine Massenverarbeitung durch. Index- und Abfrageverarbeitungskomponenten führen eine Echtzeitverarbeitung durch.
Konkurrierende Suchkomponenten nicht mischen
Vermeiden Sie das Kombinieren von Suchkomponenten auf einem physischen Server oder Computer, wenn die Komponenten um dieselben Ressourcen konkurrieren. Es folgt eine Tabelle, die die relative Menge an Ressourcen veranschaulicht, die die einzelnen Komponenten benötigen.
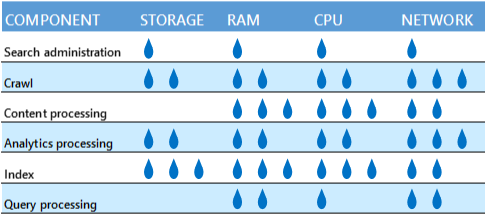
Es ist beispielsweise keine gute Idee, eine Durchforstungs- und eine Analyseverarbeitungskomponente auf demselben Server zu platzieren, da beide viel Netzwerkbandbreite belegen. Doch wenn der physische Server oder virtuelle Computer über genügend Netzwerkkapazität verfügt, treten die Komponenten nicht in Konkurrenz.
Ein weiteres Beispiel ist die extragroße Beispielsucharchitektur, die Microsoft geschätzt hat. Hier befinden sich die Durchforstungs- und Suchverwaltungskomponenten auf getrennten virtuellen Computern. Dies ist sinnvoll, um die Geschwindigkeit der Durchforstung nicht zu beeinträchtigen, da die beiden Komponenten andernfalls möglicherweise um die Prozessorressourcen konkurrieren.
Verwenden Sie Fehlerdomänen
Weisen Sie redundante Suchkomponenten Hosts in separaten Fehlerdomänen zu.
Schritt 5: Welche Hardwareanforderungen muss ich berücksichtigen?
Der nächste Schritt besteht in der Planung der benötigten Hardware:
Auswählen der Menge der Hardwareressourcen für die Hostserver
Auswählen, wie die Sucharchitektur hohe Verfügbarkeit unterstützt
Auswählen der Menge der Hardwareressourcen für die Hostserver
Jede Suchkomponente und Suchdatenbank benötigt eine Mindestmenge an Hardwareressourcen des Hostservers, um eine gute Leistung zu bieten. Deshalb gilt: Je mehr Hardwareressourcen, desto besser die Leistung Ihrer Sucharchitektur. Deshalb ist es ratsam, über mehr als nur die Mindestmenge an Hardwareressourcen zu verfügen. Die Ressourcen, die jede Suchkomponente benötigt, hängt von der Verarbeitungslast ab, die zumeist anhand der Durchforstungsrate, der Abfragerate und der Anzahl indizierter Elemente bestimmt wird.
Beispiel: Beim Hosten virtueller Computer unter Windows Server 2008 R2 Service Pack 1 (SP1) sind nicht mehr als vier CPU-Kerne pro virtuellem Computer möglich. Von Windows Server 2012 und höher werden acht und mehr CPU-Kerne pro virtuellem Computer unterstützt. Anschließend können Sie eine horizontale Skalierung mit mehr CPU-Kernen pro virtuellem Computer anstatt eine vertikale Skalierung mit mehr virtuellen Computern vornehmen. Richten Sie Server oder virtuelle Computer, die dieselben Suchkomponenten hosten, mit denselben Hardwareressourcen ein. Lassen Sie uns als Beispiel die Indexkomponente betrachten. Wenn Sie Indexpartitionen auf virtuellen Computern hosten, bestimmt der virtuelle Computer mit der schwächsten Leistung die Leistung der gesamten Sucharchitektur.
Allgemeiner Speicher
Stellen Sie sicher, dass auf jedem Hostserver genügend Speicherplatz für die Basisinstallation des Windows Server-Betriebssystems und die SharePoint Server 2016-Programmdateien zur Verfügung steht. Außerdem muss auf dem Hostserver freier Festplattenspeicher für Diagnosefunktionen wie Protokollierung und Debugging, für das Erstellen von Speicherabbildern, für tägliche Vorgänge sowie für die Auslagerungsdatei vorhanden sein. In der Regel reicht ein Speicherplatz von 80 GB für das Windows Server-Betriebssystem und für die SharePoint Server 2016-Programmdateien aus.
Fügen Sie auf jedem Datenbankserver Speicherplatz für den SQL-Protokollspeicher hinzu. Wenn Sie den Datenbankserver nicht so einrichten, dass die Datenbanken häufig gesichert werden, belegt der SQL-Protokollspeicher viel Speicherplatz. Weitere Informationen zur Planung von SQL-Datenbanken finden Sie unter Speicher- und SQL Server-Kapazitätsplanung und -Konfiguration (SharePoint Server).
Der Mindestspeicher, den die Analyseberichtsdatenbank benötigt, kann variieren. Der Grund ist, dass die Speichermenge von der Anzahl der Benutzer abhängt, die mit SharePoint Server 2016 interagieren. Wenn Benutzer häufig interagieren, sind meist mehr Ereignisse zu speichern. Prüfen Sie die Menge an Speicher, die Ihre derzeitige Sucharchitektur für die Analysedatenbank verwendet, und weisen Sie Ihrer umgestalteten Topologie mindestens diese Menge zu.
Mindestressourcen für die Indexkomponente
Dies sind die Mindestressourcen, die ein Server oder virtueller Computer haben muss, um eine Indexkomponente bzw. eine Indexkomponente und eine Abfrageverarbeitungskomponente zu hosten:
| Speicherplatz | Arbeitsspeicher | Prozessor | Netzwerkbandbreite |
| 500 GB für den Index1 | 32 GB1 | 64 Bit, mindestens 8 Kerne1, 2 | 2 Gbit/s |
1Bei SharePoint Server 2013 beträgt die Mindestmenge an Ressourcen 500 GB Speicher, 16 GB RAM und vier CPU-Kerne.
2 Bei Verwendung von SharePoint Server 2016 können Sie mit 16 GB RAM und vier Prozessorkernen arbeiten. Dann kann jedoch jede Indexkomponente maximal 10 Mio. Elemente enthalten (statt 20 Mio.Elementen).
Mindestressourcen für die Analyseverarbeitungskomponente
Dies sind die Mindestressourcen, die ein Server oder virtueller Computer zum Hosten einer Analyseverarbeitungkomponente benötigt:
| Speicherplatz | Arbeitsspeicher | Prozessor | Netzwerkbandbreite |
| 300 GB für die lokale Verarbeitung von Analysen | 8 GB | 64 Bit, mindestens 4 Prozessorkerne, doch 8 Prozessorkerne empfohlen. | 2 Gbit/s |
Wenn der Server eine Analyseverarbeitungskomponente sowie eine oder mehrere Massenverarbeitungskomponenten hostet, erhöhen Sie den Arbeitsspeicher auf 16 GB.
Mindestressourcen für die Durchforstungs-, Inhaltsverarbeitungs-, Abfrageverarbeitungs- und Suchverwaltungskomponente
Dies sind die Mindestressourcen, die ein Server oder virtueller Computer zum Hosten einer dieser Komponenten benötigt:
| Speicherplatz | Arbeitsspeicher | Prozessor | Netzwerkbandbreite |
| Nicht erforderlich | 8 GB | 64 Bit, mindestens 4 Prozessorkerne, doch 8 Prozessorkerne empfohlen. | 2 Gbit/s |
Wenn der Server zwei dieser Komponenten hostet, erhöhen Sie den Arbeitsspeicher auf 16 GB.
Die Abfrageverarbeitungskomponente benötigt ausreichend Netzwerkbandbreite. Es sind die Anzahl der Indexpartitionen und die Größe der Abfragen und Ergebnisse, die diesen Bedarf an Netzwerkbandbreite steigern. Beispiel: 20 Abfragen pro Sekunde pro Abfrageverarbeitungskomponente und ein Index mit 20 Indexpartitionen führt zu eingehendem Datenverkehr mit 200 Mbit/s und ausgehendem Datenverkehr mit 200 Mbit/s für den Server oder virtuellen Computer, der die Abfrageverarbeitungskomponente hostet.
Mindestressourcen für die Suchdatenbanken
Dies sind die Mindestressourcen, die ein Server oder virtueller Computer zum Hosten einer oder mehrerer Suchdatenbanken benötigt:
| Speicherplatz | Arbeitsspeicher | Prozessor | Netzwerkbandbreite |
| Der von der Analyseberichtsdatenbank benötigte Speicherplatz hängt davon ab, wie und wie häufig in der Suchumgebung Analysen erfolgen. Verwenden Sie die derzeitige Speichermenge als Leitfaden für die Analyseberichtsdatenbank. | 8 GB für kleine Bereitstellungen. 16 GB für mittlere Bereitstellungen |
64-Bit, 4 Kerne | 2 Gbit/s |
Planen der Speicherleistung
Die Speichergeschwindigkeit hat Einfluss auf die Suchleistung. Stellen Sie sicher, dass der von Ihnen verwendete Speicher schnell genug ist, um den Datenverkehr der Suchkomponenten und -datenbanken zu verarbeiten. Die Datenträgergeschwindigkeit wird in E/A-Vorgängen pro Sekunde (I/O Operations Per Second, IOPS) gemessen.
Die Art und Weise, in der Daten von den Suchkomponenten und vom Betriebssystem auf den Speicher verteilt werden, hat Einfluss auf die Suchleistung. Daher sind die folgenden Maßnahmen sinnvoll:
Teilen Sie die Systemdateien des Windows Server-Betriebssystems, die SharePoint Server 2016-Programmdateien und der Diagnoseprotokolle auf drei separate Speichervolumes oder Partitionen mit normaler Leistung auf.
Speichern Sie die Daten der Suchkomponenten auf einem separaten Speichervolume oder einer separaten Partition. Für Indexkomponenten muss dieser Speicher auch eine hohe Leistung haben.
Hinweis
[!HINWEIS] Sie können einen benutzerdefinierten Speicherort für Suchkomponentendaten festlegen, wenn Sie SharePoint Server 2016 auf einem Host installieren. Suchkomponenten auf dem Host, die Daten speichern müssen, speichern diese an diesem Speicherort. Wenn Sie diesen Speicherort später ändern möchten, müssen Sie SharePoint Server 2016 neu installieren.
Auswählen des Speichertyps
Eine Übersicht über Speicherarchitekturen und Datenträgertypen finden Sie unter Speicher- und SQL Server-Kapazitätsplanung und -Konfiguration (SharePoint Server 2016). Die Server, auf denen die Index-, Analyseverarbeitungs- und Suchverwaltungskomponenten oder Suchdatenbanken gehostet werden, erfordern einen Speicher, der geringe Wartezeiten und gleichzeitig genügend E/A-Vorgänge pro Sekunde (IOPS) ermöglicht. In den folgenden Tabellen wird angegeben, wie viele IOPS die einzelnen Suchkomponenten und -datenbanken erfordern.
Wenn Sie gemeinsam genutzten Speicher wie SAN/NAS bereitstellen, fällt die Spitzenauslastung einer Suchkomponente in der Regel mit der Spitzenauslastung einer anderen Suchkomponente zusammen. Zur Ermittlung der vom gemeinsam genutzten Speicher für die Suchkomponenten erforderlichen IOPS müssen Sie die IOPS-Anforderungen der einzelnen Komponenten addieren.
IOPS-Anforderungen der Suchkomponenten
| Komponentenname | Komponentendetails | IOPS-Anforderungen | Verwendung separater Speichervolumes/Partitionen |
|---|---|---|---|
| Indexkomponente | Verwendet den Speicher beim Zusammenführen des Indexes und beim Verarbeiten und Beantworten von Abfragen | 300 IOPS für zufällige Lesevorgänge (64 KB) 100 IOPS für zufällige Schreibvorgänge (256 KB) 200 MB/s für sequenzielle Lesevorgänge 200 MB/s für sequenzielle Schreibvorgänge |
Ja |
| Analysekomponente | Analysiert Daten lokal, Massenverarbeitung | Nein | Ja |
| Durchforstungskomponente | Speichert heruntergeladene Inhalte lokal, bevor sie an eine Inhaltsverarbeitungskomponente gesendet werden. Der Speicher wird durch die Netzwerkbandbreite begrenzt. | Nein | Ja |
IOPS-Anforderungen an die Suchdatenbanken
| Datenbankname | IOPS-Anforderungen | Standardauslastung des E/A-Subsystems |
|---|---|---|
| Durchforstungsdatenbank | Durchschnittliche bis viele IOPS | 10 IOPS bei einer Durchforstungsrate von 1 Dokument pro Sekunde (DPS) |
| Linkdatenbank | Durchschnittliche IOPS | 10 IOPS pro 1 Mio. Elemente im Suchindex |
| Suchverwaltungsdatenbank | Wenige IOPS | Nicht zutreffend |
| Analyseberichtsdatenbank | Durchschnittliche IOPS | Nicht zutreffend |
Auswählen der Unterstützung von hoher Verfügbarkeit durch die Sucharchitektur
Wenn Sie mit Strategien für Hochverfügbarkeit nicht vertraut sind, finden Sie hier einen Artikel zum Einstieg: Erstellen einer Hochverfügbarkeitsarchitektur und -strategie für SharePoint Server. Wenn Sie redundante Suchkomponenten und Datenbanken in separaten Fehlerdomänen hosten, fällt bei einem Ausfall eines Teils der Farm nicht der gesamte Dienst aus. Die Suchleistung wird hingegen beeinträchtigt, da die Suchkomponenten die Last nicht mehr teilen. Um die Chance des Ausfalls eines Einzelservers zu verkleinern, ist es ratsam, die lokale Redundanz zu verbessern. Gehen Sie bei jedem Hostserver in Ihrer Sucharchitektur wie folgt vor:
Verwenden Sie RAID-Speicher auf jedem Server.
Installieren Sie mehrere redundante Netzwerkverbindungen auf jedem Server.
Installieren Sie für jeden Server mehrere redundante Stromversorgungseinheiten mit stehender Verdrahtung oder eine unterbrechungsfreie Stromversorgung (USV).
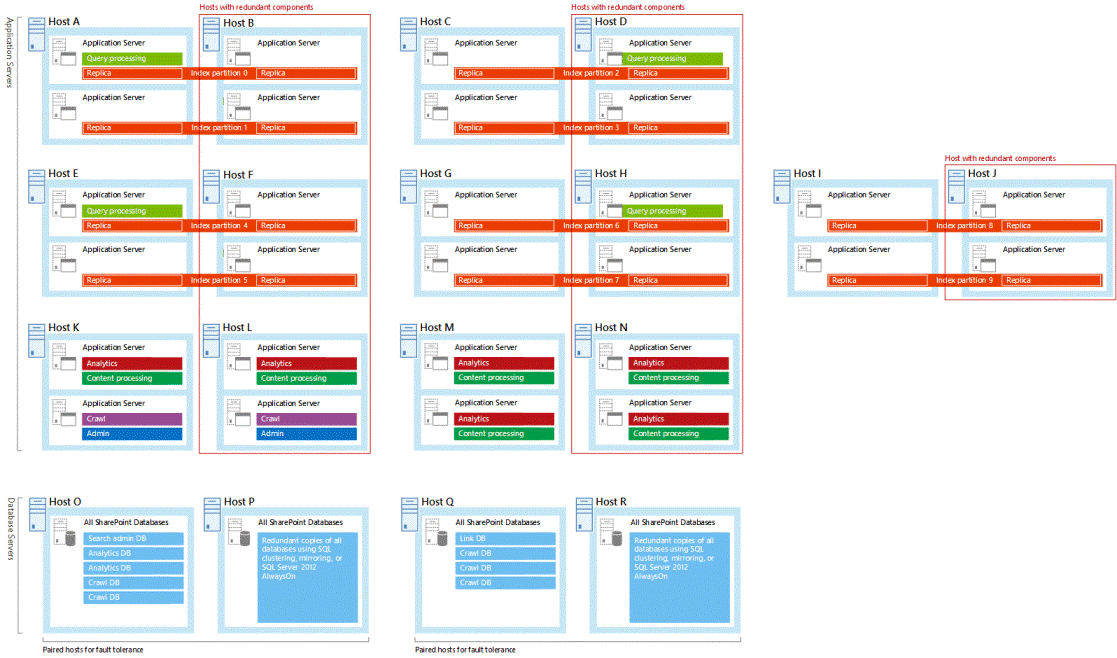
In allen Beispielsucharchitekturen werden redundante Suchkomponenten auf unabhängigen Servern gehostet. In diesen Architekturen ist der rechte Host in jedem Hostpaar redundant. Es folgt eine große Sucharchitektur mit hervorgehobenen redundanten Hosts: