Big Data-Optionen auf der Microsoft SQL Server-Plattform
Gilt für: ![]() SQL Server 2019 (15.x) und höhere Versionen
SQL Server 2019 (15.x) und höhere Versionen
Microsoft SQL Server 2019 Big Clusters ist ein Add-On für die SQL Server-Platform, mit dem Sie skalierbare Cluster von SQL Server-, Spark- und HDFS-Containern bereitstellen können, die unter Kubernetes ausgeführt werden. Diese Komponenten werden nebeneinander ausgeführt, sodass Sie Big Data mit Transact-SQL- oder Spark-Bibliotheken lesen, schreiben und verarbeiten können, während Sie Ihre wichtigen relationalen Daten problemlos mit einem hohen nicht relationalen Big Data-Volumen kombinieren und analysieren können. Big Data-Cluster ermöglichen Ihnen auch, Daten mit PolyBase zu virtualisieren, sodass Sie Daten aus externen SQL Server-, Oracle-, Teradata-, MongoDB-Datenbanken und anderen Datenquellen mithilfe externer Tabellen abfragen können. Das Microsoft SQL Server 2019 Big Clusters-Add-On bietet Hochverfügbarkeit für die SQL Server-Masterinstanz und alle Datenbanken mithilfe von Always On-Verfügbarkeitsgruppentechnologie.
Das SQL Server 2019-Big Data-Cluster-Add-On wird lokal und in der Cloud mithilfe der Kubernetes-Plattform für jede Standardbereitstellung von Kubernetes ausgeführt. Darüber hinaus lässt sich das SQL Server 2019-Big Data-Cluster-Add-On in Active Directory integrieren und umfasst die rollenbasierte Zugriffssteuerung, um die Sicherheits- und Complianceanforderungen Ihres Unternehmens zu erfüllen.
Außerbetriebnahme des SQL Server 2019-Big Data-Cluster-Add-Ons
Am 28. Februar 2025 werden wir SQL Server 2019 Big Data Clusters einstellen. Alle vorhandenen Benutzer von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag.
Änderungen an der PolyBase-Unterstützung in SQL Server
Die Außerbetriebnahme der SQL Server 2019-Big Data-Cluster betrifft auch einige Features zum Aufskalieren von Abfragen.
Das PolyBase-Erweiterungsgruppen-Feature von Microsoft SQL Server wurde eingestellt. Die Erweiterungsgruppen-Funktionalität ist in SQL Server 2022 (16.x) nicht mehr vorhanden. Die auf dem Markt verfügbaren Versionen von SQL Server 2019, SQL Server 2017 und SQL Server 2016 unterstützen die Funktionalität bis zum Ende der Lebensdauer dieser Produkte. Die PolyBase-Datenvirtualisierung wird in SQL Server weiterhin als Hochskalierungs-Feature vollständig unterstützt.
Externe Hadooop-Datenquellen für Cloudera (CDP) und Hortonworks (HDP) werden ebenfalls für alle auf dem Markt befindlichen Versionen von SQL Server eingestellt und sind nicht in SQL Server 2022 enthalten. Der Support für externe Datenquellen wird auf Produktversionen beschränkt, die vom jeweiligen Anbieter im Hauptsupport unterstützt werden. Sie sollten die neue Objektspeicherintegration verwenden, die in SQL Server 2022 (16.x) verfügbar ist.
In SQL Server 2022 (16.x) und höheren Versionen müssen Benutzer*innen ihre externen Datenquellen für die Verwendung neuer Connectors konfigurieren, wenn sie eine Verbindung mit Azure Storage herstellen. Die Änderungen sind in der folgenden Tabelle zusammengefasst:
| Externe Datenquelle | From | Beschreibung |
|---|---|---|
| Azure Blob Storage | wasb[s] |
abs |
| ADLS Gen2 | abfs[s] |
adls |
Hinweis
Azure Blob Storage (abs) erfordert die Verwendung der Shared Access Signature (SAS) für das SECRET in den Anmeldeinformationen des Datenbankbereichs. In SQL Server 2019 und früher hat der wasb[s]-Connector bei der Authentifizierung beim Azure Storage-Konto den Speicherkontoschlüssel mit datenbankbezogenen Anmeldeinformationen verwendet.
Grundlegendes zur Big Data Clusters-Architektur für Ersetzungs- und Migrationsoptionen
Um eine Ersatzlösung für ein Big Data-Speicher- und -Verarbeitungssystem zu erstellen, müssen Sie wissen, welche Möglichkeiten ein SQL Server 2019-Big Data-Cluster bietet, und seine Architektur kann Sie bei Ihren Entscheidungen unterstützen. Die Architektur eines Big Data-Clusters sieht wie folgt aus:

Diese Architektur bietet folgende Funktionalitätszuordnung:
| Komponente | Vorteil |
|---|---|
| Kubernetes | Open-Source-Orchestrator für die bedarfsgerechte Bereitstellung und Verwaltung containerbasierter Anwendungen. Bietet eine deklarative Methode zum Erstellen und Steuern von Resilienz, Redundanz und Portabilität für die gesamte Umgebung mit elastischer Skalierung. |
| Big Data-Cluster-Controller | Bietet Verwaltungs- und Sicherheitsfunktionen für den Cluster. Er enthält den Verwaltungsdienst, den Konfigurationsspeicher und andere Dienste auf Clusterebene wie Kibana, Grafana und Elasticsearch. |
| Computepool | Stellt Rechenressourcen für den Cluster bereit. Er enthält Knoten, auf denen Pods für SQL Server für Linux laufen. Die Pods im Computepool werden für bestimmte Verarbeitungsaufgaben in SQL-Computeinstanzen unterteilt. Diese Komponente bietet Datenvirtualisierung mithilfe von PolyBase, um externe Datenquellen abzufragen, ohne die Daten zu verschieben oder zu kopieren. |
| Datenpool | Stellt Datenpersistenz für den Cluster bereit. Der Datenpool besteht aus mindestens einem Pod, auf dem SQL Server für Linux ausgeführt wird. Er wird zum Erfassen von Daten aus SQL-Abfragen oder Spark-Aufträgen verwendet. |
| Speicherpool | Der Speicherpool besteht aus den Speicherpoolpods, bestehend aus SQL Server für Linux, Spark und HDFS. Alle Speicherknoten in einem Big Data-Cluster sind Mitglieder eines HDFS-Clusters. |
| App-Pool | Ermöglicht die Anwendungsbereitstellung in einem Big Data-Cluster durch Bereitstellen von Schnittstellen zum Erstellen, Verwalten und Ausführen von Anwendungen. |
Weitere Informationen diesen Funktionen finden Sie unter Einführung in SQL Server-Big Data-Cluster.
Optionen zum Ersetzen von Funktionen für Big Data und SQL Server
Die betriebsbereite Datenfunktion, die von SQL Server innerhalb von Big Data Clusters ermöglicht wird, kann durch SQL Server lokal in einer Hybridkonfiguration oder mithilfe der Microsoft Azure-Plattform ersetzt werden. Microsoft Azure bietet eine Auswahl vollständig verwalteter relationaler, NoSQL- und In-Memory-Datenbanken, die proprietäre und Open-Source-Engines umfassen, um die Anforderungen moderner App-Entwickler zu erfüllen. Die Infrastrukturverwaltung einschließlich Skalierbarkeit, Verfügbarkeit und Sicherheit ist automatisiert, spart Ihnen Zeit und Geld und ermöglicht Ihnen, sich auf die Erstellung von Anwendungen zu konzentrieren, während von Azure verwaltete Datenbanken Ihre Arbeit vereinfachen, indem Sie durch eingebettete Intelligenz, skalierungsfreie Skalierung und Verwaltung von Sicherheitsbedrohungen Einblicke in die Leistung gewinnen. Weitere Informationen finden Sie unter Datenbankoptionen in Azure.
Der nächste Entscheidungspunkt sind die Compute- und Datenspeicherorte für Analysen. Die beiden Architekturoptionen sind In-Cloud- und Hybridbereitstellungen. Die meisten analytischen Workloads können zur Microsoft Azure-Plattform migriert werden. Daten, die aus cloudbasierten Anwendungen stammen, sind die besten Kandidaten für diese Technologien, und Datenverschiebungsdienste können umfangreiche lokale Daten sicher und schnell migrieren. Weitere Informationen zu Datenverschiebungsoptionen finden Sie unter Auswählen einer Azure-Lösung für die Datenübertragung.
Microsoft Azure verfügt über Systeme und Zertifizierungen, die sichere Daten und eine sichere Datenverarbeitung in verschiedenen Tools ermöglichen. Weitere Informationen zu diesen Zertifizierungen finden Sie im Trust Center.
Hinweis
Die Microsoft Azure-Plattform bietet ein sehr hohes Maß an Sicherheit, mehrere Zertifizierungen für verschiedene Branchen und berücksichtigt die Datenhoheit für Behördenanforderungen. Microsoft Azure verfügt auch über eine dedizierte Cloudplattform für Behördenworkloads. Sicherheit allein sollte nicht der primäre Entscheidungspunkt für lokale Systeme sein. Sie sollten das Sicherheitsniveau von Microsoft Azure sorgfältig auswerten, bevor Sie sich dafür entscheiden, Ihre Big Data-Lösungen lokal beizubehalten.
Bei der Option In-Cloud-Architektur befinden sich alle Komponenten in Microsoft Azure. Sie tragen die Verantwortung für die Daten und den Code, die Sie für die Speicherung und Verarbeitung Ihrer Workloads erstellen. Diese Optionen werden in diesem Artikel noch genauer behandelt.
- Diese Option funktioniert am besten bei einer Vielzahl von Komponenten für die Speicherung und Verarbeitung von Daten, und wenn Sie sich auf Daten- und Verarbeitungskonstrukte statt auf die Infrastruktur konzentrieren möchten.
Bei den Optionen für die Hybridarchitektur werden einige Komponenten lokal beibehalten, während andere in einem Cloudanbieter platziert werden. Die Konnektivität zwischen den beiden ist für die optimale Platzierung der zu verarbeitender Daten konzipiert.
- Diese Option funktioniert am besten, wenn Sie beträchtliche Investitionen in lokale Technologien und Architekturen getätigt haben, aber die Angebote von Microsoft Azure nutzen möchten, oder wenn Sie entweder Verarbeitungs- und Anwendungsziele lokal oder für eine weltweite Zielgruppe haben.
Weitere Informationen zum Erstellen skalierbarer Architekturen finden Sie unter Erstellen eines skalierbaren Systems für große Datenvolumen.
In der Cloud
Azure SQL mit Synapse
Sie können die Funktionalität von SQL Server Big Data Clusters ersetzen, indem Sie mindestens eine Azure SQL-Datenbankoption für operative Daten und Microsoft Azure Synapse für Ihre Analyseworkloads verwenden.
Microsoft Azure Synapse ist ein Unternehmensanalysedienst zur schnelleren Gewinnung von Erkenntnissen aus Data Warehouses und Big Data-Systemen unter Verwendung verteilter Verarbeitungs- und Datenkonstrukte. In Azure Synapse sind SQL-Technologien vereint, die für Data Warehousing in Unternehmen, Spark-Technologien für Big Data, Pipelines für die Datenintegration und ETL/ELT sowie eine tiefe Integration in andere Azure-Dienste wie Power BI, Cosmos DB und Azure Machine Learning verwendet werden.
Verwenden Sie bei Bedarf Microsoft Azure Synapse als Ersatz für SQL Server 2019-Big Data-Cluster:
- Nutzen sowohl serverloser als auch dedizierter Ressourcenmodelle. Erstellen Sie dedizierte SQL-Pools zur Reservierung von Rechenleistung für in SQL-Tabellen gespeicherte Daten, um von planbarer Leistung und planbaren Kosten zu profitieren.
- Verarbeiten von ungeplanten oder „Burst“-Workloads, Zugreifen auf einen immer verfügbaren serverlosen SQL-Endpunkt.
- Nutzen integrierter Streamingfunktionen, um Daten aus Clouddatenquellen in SQL-Tabellen zu übertragen.
- Integrieren von KI in SQL mit Machine Learning-Modellen, um Daten per T-SQL-Vorhersagefunktion (PREDICT) zu bewerten.
- Nutzen von ML-Modellen mit SparkML-Algorithmen und Azure Machine Learning-Integration für Apache Spark 2.4 mit Unterstützung für Linux Foundation Delta Lake.
- Verwenden eines vereinfachten Ressourcenmodells, bei dem Sie sich nicht mehr mit der Verwaltung von Clustern auseinandersetzen müssen.
- Verarbeiten von Daten, die einen schnellen Spark-Start und eine aggressive automatische Skalierung erfordern.
- Verarbeiten von Daten mit .NET für Spark, sodass Sie Ihre C#-Kenntnisse und bereits vorhandenen .NET-Code in einer Spark-Anwendung wiederverwenden können.
- Arbeiten mit Tabellen, die auf Dateien im Data Lake definiert sind, nahtlos entweder von Spark oder Hive genutzt.
- Verwenden von SQL mit Spark zur direkten Erkundung und Analyse von im Data Lake gespeicherten Parquet-, CSV-, TSV- und JSON-Dateien.
- Aktivieren schnellen, skalierbaren Ladens von Daten zwischen SQL- und Spark-Datenbanken.
- Erfassen von Daten aus über 90 Datenquellen.
- Aktivieren von ETL ohne Programmieraufwand mit Datenflussaktivitäten.
- Orchestrieren von Notebooks, Spark-Aufträgen, gespeicherten Prozeduren, SQL-Skripts und mehr.
- Überwachen von Ressourcen, Nutzung und Benutzern in SQL und Spark.
- Verwenden der rollenbasierten Zugriffssteuerung zum Vereinfachen des Zugriffs auf Analyseressourcen.
- Schreiben von SQL- oder Spark-Code und Integrieren in CI/CD-Prozesse für Unternehmen.
Die Architektur von Microsoft Azure Synapse sieht wie folgt aus:

Weitere Informationen zu Microsoft Azure Synapse finden Sie unter Was ist Azure Synapse Analytics?
Azure SQL plus Azure Machine Learning
Sie können die Funktionalität von SQL Server Big Data Clusters ersetzen, indem Sie mindestens eine Azure SQL-Datenbankoption für operative Daten und Microsoft Azure Machine Learning für Ihre vorhergesagten Workloads verwenden.
Azure Machine Learning ist ein cloudbasierter Dienst, der für alle Arten maschinellen Lernens verwendet werden kann – von klassischem Machine Learning bis zu Deep Learning und für überwachtes und nicht überwachtes Lernen. Unabhängig davon, ob Sie das Schreiben von Python- oder R-Code mit dem SDK oder die Nutzung von Optionen ohne bzw. mit nur wenig Code in Studio bevorzugen, können Sie in einem Azure Machine Learning-Arbeitsbereich Machine Learning- und Deep Learning-Modelle erstellen, trainieren und nachverfolgen. Mit Azure Machine Learning können Sie auf Ihrem lokalen Computer mit dem Training beginnen und später die Vorteile der Cloud nutzen. Der Dienst kann auch zusammen mit beliebten Open-Source-Tools für Deep Learning und vertiefendes Lernen (etwa PyTorch, TensorFlow, scikit-learn und Ray RLlib) genutzt werden.
Verwenden Sie bei Bedarf Microsoft Azure Machine Learning als Ersatz für SQL Server 2019-Big Data-Cluster:
- Eine designerbasierte Webumgebung für Machine Learning: Fügen Sie Module per Drag & Drop ein, um Ihre Experimente zu erstellen, und stellen Sie anschließend Pipelines in einer Umgebung mit wenig Code bereit.
- Jupyter-Notebooks: Verwenden Sie unsere Beispielnotebooks, oder erstellen Sie Ihre eigenen Notebooks, um unsere SDK für Python-Beispiele für Ihre Machine Learning-Zwecke zu nutzen.
- R-Skripts oder Notebooks, in denen Sie das SDK für R zum Schreiben Ihres eigenen Codes verwenden (oder die R-Module im Designer).
- Der Solution Accelerator für viele Modelle basiert auf Azure Machine Learning und ermöglicht Ihnen Training, Betrieb und Verwaltung von Hunderten oder sogar Tausenden von Machine Learning-Modellen.
- Die Machine Learning-Erweiterungen für Visual Studio Code (Vorschauversion) bieten Ihnen eine Entwicklungsumgebung mit vollem Funktionsumfang zum Erstellen und Verwalten Ihrer Machine Learning-Projekte.
- Eine Machine Learning-Befehlszeilenschnittstelle (Command-Line Interface, CLI) ist eine Azure CLI-Erweiterung, die Befehle für die Verwaltung mit Azure Machine Learning-Ressourcen über die Befehlszeile bereitstellt.
- Integration in Open-Source-Frameworks wie PyTorch, TensorFlow, Scikit-learn und vieles mehr zum Trainieren, Bereitstellen und Verwalten des End-to-End-Prozesses für maschinelles Lernen
- Vertiefendes Lernen mit Ray RLlib
- MLflow zum Nachverfolgen von Metriken und Bereitstellen von Modellen oder Kubeflow zum Erstellen von End-to-End-Workflowpipelines.
Die Architektur einer Microsoft Azure Machine Learning-Bereitstellung sieht wie folgt aus:

Weitere Informationen zu Microsoft Azure Machine Learning finden Sie unter Was ist Azure Machine Learning?.
Azure SQL von Databricks
Sie können die Funktionalität von SQL Server Big Data Clusters ersetzen, indem Sie mindestens eine Azure SQL-Datenbankoption für operative Daten und Microsoft Azure Databricks für Ihre Analyseworkloads verwenden.
Azure Databricks ist eine Analyseplattform, die für die Microsoft Azure-Clouddienstplattform optimiert ist. Azure Databricks bietet zwei Umgebungen für die Entwicklung datenintensiver Anwendungen: Azure Databricks-SQL-Analyse und Azure Databricks-Arbeitsbereich.
Azure Databricks-SQL-Analyse stellt eine benutzerfreundliche Plattform für Analysten bereit, die SQL-Abfragen für ihren Data Lake erstellen, mehrere Visualisierungstypen zum Untersuchen von Abfrageergebnissen aus verschiedenen Perspektiven erstellen sowie Dashboards erstellen und freigeben möchten.
Der Azure Databricks-Arbeitsbereich bietet einen interaktiven Arbeitsbereich, der die Zusammenarbeit zwischen Data Engineers, Data Scientists und Machine Learning-Technikern ermöglicht. Für eine Big Data-Pipeline werden Rohdaten oder strukturierte Daten in Batches über Azure Data Factory in Azure erfasst oder mithilfe von Apache Kafka, Event Hubs oder IoT Hub nahezu in Echtzeit gestreamt. Diese Daten werden langfristig in einem Data Lake (Azure Blob Storage oder Azure Data Lake Storage) gespeichert. Verwenden Sie Azure Databricks im Rahmen Ihres Analyseworkflows, um Daten aus mehreren Datenquellen zu lesen und sie mithilfe von Spark in bahnbrechende Erkenntnisse umzuwandeln.
Verwenden Sie bei Bedarf Microsoft Azure Databricks als Ersatz für SQL Server 2019-Big Data-Cluster:
- Vollständig verwaltete Spark-Cluster mit Spark SQL und DataFrames.
- Streaming für die Echtzeitdatenverarbeitung und -analyse für analytische und interaktive Anwendungen, Integration in HDFS, Flume und Kafka.
- Zugriff auf die MLlib-Bibliothek mit gängigen Lernalgorithmen und Hilfsprogrammen – einschließlich Klassifizierung, Regression, Clustering, kombinierten Filtern und Reduktion der Anzahl von Dimensionen sowie zugrunde liegenden Optimierungsprimitiven.
- Dokumentation Ihres Fortschritts in Notebooks in R, Python, Scala oder SQL.
- Visualisierung von Daten in wenigen Schritten mit vertrauten Tools wie Matplotlib, ggplot oder d3.
- Interaktive Dashboards zum Erstellen dynamischer Berichte.
- GraphX für Diagramme und Diagrammberechnung für ein breites Spektrum von Anwendungsfällen – von kognitiven Analysen bis hin zu Datenuntersuchungen.
- Clustererstellung in Sekunden mit dynamischer automatischer Skalierung von Clustern, die teamübergreifend freigegeben werden.
- Programmgesteuerter Clusterzugriff mithilfe von REST-APIs.
- Sofortiger Zugriff auf die neuesten Apache Spark-Features mit jedem neuen Release.
- Eine Spark Core-API: Bietet Unterstützung für R, SQL, Python, Scala und Java.
- Interaktiver Arbeitsbereich zur Untersuchung und Visualisierung.
- Vollständig verwaltete SQL-Endpunkte in der Cloud.
- SQL-Abfragen, die auf vollständig verwalteten SQL-Endpunkten gemäß der Abfragewartezeit und der Anzahl von gleichzeitigen Benutzern ausgeführt werden.
- Integration in Microsoft Entra ID (früher Azure Active Directory).
- Rollenbasierter Zugriff für präzise Benutzerberechtigungen für Notebooks, Cluster, Aufträge und Daten.
- SLAs auf Unternehmensniveau.
- Mit Dashboards zum Freigeben von Erkenntnissen können Sie Visualisierungen und Text kombinieren, um aus Ihren Abfragen gewonnene Erkenntnisse freizugeben.
- Warnungen unterstützen Sie bei der Überwachung und Integration sowie bei Benachrichtigungen, wenn ein von einer Abfrage zurückgegebenes Feld einen Schwellenwert erreicht. Verwenden Sie Warnungen, um Ihr Unternehmen zu überwachen, oder kombinieren Sie sie mit Tools, um Workflows wie Supporttickets oder das Onboarding von Benutzern zu starten.
- Sicherheit für Unternehmen – einschließlich Microsoft Entra ID-Integration, rollenbasierter Zugriffssteuerung und SLAs zum Schutz Ihrer Daten und Ihres Unternehmens.
- Integration in Azure-Dienste und Azure-Datenbanken und -Speicher inklusive Synapse Analytics, Cosmos DB, Data Lake Store und Blobspeicher.
- Integration in Power BI und andere BI-Tools, z. B. Tableau Software.
Die Architektur einer Microsoft Azure Databricks-Bereitstellung sieht wie folgt aus:
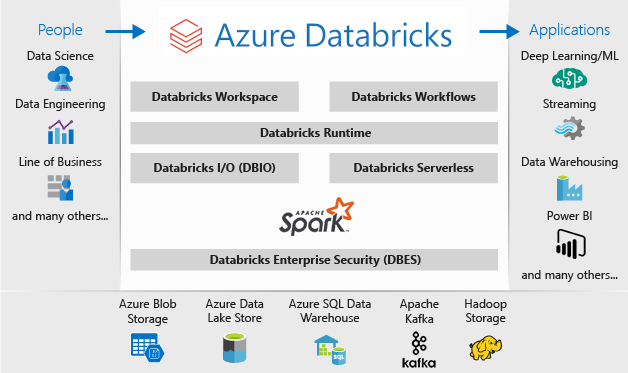
Weitere Informationen zu Microsoft Azure Databricks finden Sie unter Was ist Was ist Azure Databricks?.
Hybrid
Gespiegelte Datenbank in Fabric
Als Datenreplikationsumgebung ist Datenbankspiegelung in Fabric eine kostengünstige Lösung mit geringer Latenz, zum Zusammenbringen von Daten aus verschiedenen Systemen auf eine einzige Analyseplattform. Sie können Ihren vorhandenen Datenbestand kontinuierlich direkt in das OneLake von Fabric replizieren, einschließlich Daten aus Azure SQL-Datenbank, Snowflake und Cosmos DB.
Mit den aktuellsten Daten in einem abfragefähigen Format in OneLake können Sie jetzt alle verschiedenen Dienste in Fabric verwenden, z. B. Ausführung von Analysen mit Spark, Ausführung von Notebooks, Datentechnik, Visualisierung über Power BI-Berichte und vieles mehr.
Die Spiegelung in Fabric ermöglicht es, Erkenntnisse und Entscheidungen schneller zu nutzen und Datensilos zwischen Technologielösungen aufzuschlüsseln, ohne teure Prozesse für das Extrahieren, Transformieren und Laden (ETL) zum Verschieben von Daten zu entwickeln.
Mit der Spiegelung in Fabric vermeiden Sie, verschiedene Dienste von mehreren Anbietern kombinieren zu müssen. Stattdessen profitieren Sie von einem hochgradig integrierten, benutzerfreundlichen End-to-End-Produkt, das Ihre Analyseanforderungen vereinfacht und auf Offenheit und Zusammenarbeit zwischen Technologielösungen ausgelegt ist, die das Open-Source-Tabellenformat von Delta Lake lesen können.
Weitere Informationen finden Sie unter:
- In Microsoft Fabric gespiegelte Datenbanken
- Überwachen gespiegelter Datenbanken in Microsoft Fabric
- Durchsuchen von Daten in Ihrer gespiegelten Datenbank mithilfe von Microsoft Fabric
- Was ist Microsoft Fabric?
- Modellieren von Daten im standardmäßigen Power BI-Semantikmodell in Microsoft Fabric
- Was ist der SQL-Analyseendpunkt für ein Lakehouse?
- Direct Lake
Verwenden von SQL Server 2022 mit Azure Synapse Link für SQL
In SQL Server 2022 (16.x) wird ein neues Feature eingeführt, mit dem SQL Server-Tabellen mit der Microsoft Azure Synapse-Plattform verbunden werden können: Azure Synapse Link für SQL. Azure Synapse Link für SQL Server 2022 (16.x) bietet automatische Änderungsfeeds, die die Änderungen innerhalb von SQL Server erfassen und in Azure Synapse Analytics laden. Es bietet nahezu in Echtzeit Analysen sowie eine hybride Transaktions- und Analyseverarbeitung mit minimalen Auswirkungen auf Betriebssysteme. Sobald sich die Daten in Synapse befinden, können Sie sie unabhängig von ihrer Größe, Skalierung oder Ihrem Format mit vielen verschiedenen Datenquellen kombinieren, und sie können für alle Daten leistungsstarke Analysen wahlweise mit Azure Machine Learning, Spark oder Power BI ausführen. Da die automatisierten Änderungsfeeds nur Neuerungen oder Änderungen pushen, erfolgt die Datenübertragung viel schneller und ermöglicht jetzt Erkenntnisse in Quasi-Echtzeit und mit minimalen Auswirkungen auf die Leistung der Quelldatenbank in SQL Server 2022 (16.x).
Für Ihre operativen Arbeitsauslastungen und sogar für einen Großteil Ihrer Analysearbeitsauslastungen kann SQL Server enorme Datenbankgrößen bewältigen. Weitere Informationen zu Spezifikationen der maximalen Kapazität für SQL Server finden Sie unter Computekapazitätslimits nach SQL Server-Edition. Die Verwendung mehrerer SQL Server-Instanzen auf separaten Computern mit partitionierten T-SQL-Anforderungen ermöglicht eine Aufskalierungsumgebung für Anwendungen.
Mit PolyBase kann Ihre SQL Server-Instanz Daten mit T-SQL direkt aus Oracle, Teradata, MongoDB und Cosmos DB abfragen, ohne dass eine spezielle Software für Clientverbindungen installiert werden muss. Sie können auch den generischen ODBC-Connector auf einer Microsoft Windows-basierten Instanz verwenden, um eine Verbindung mit weiteren Anbietern über ODBC-Treiber von Drittanbietern herzustellen. PolyBase ermöglicht T-SQL-Abfragen, Daten aus externen Quellen mit relationalen Tabellen in einer Instanz von SQL Server zu verknüpfen. Dabei können die Daten ihren ursprünglichen Speicherort und ihr Format beibehalten. Diese externen Daten können über die SQL Server-Instanz virtualisiert werden, sodass sie wie in jeder anderen Tabelle in SQL Server abgefragt werden können. SQL Server 2022 (16.x) ermöglicht auch Ad-hoc-Abfragen und die Sicherung/Wiederherstellung über Hardware- oder Softwarespeicheroptionen mit Objektspeicher (über die S3-API).
Zwei allgemeine Referenzarchitekturen sind die Verwendung von SQL Server auf einem eigenständigen Server für strukturierte Datenabfragen und eine separate Installation eines nicht relationalen Aufskalierungssystems (z. B. Apache Hadoop oder Apache Spark) für die lokale Verknüpfung mit Synapse. Die andere Möglichkeit ist, eine Gruppe von Containern in einem Kubernetes-Cluster mit allen Komponenten für Ihre Lösung zu verwenden.
Microsoft SQL Server für Windows, Apache Spark und Objektspeicher lokal
Sie können SQL Server unter Windows oder Linux installieren und die Hardwarearchitektur hochskalieren, indem Sie die Abfragefunktion des Objektspeichers in SQL Server 2022 (16.x) und das PolyBase-Feature nutzen, um Abfragen für alle Daten in Ihrem System zu ermöglichen.
Das Installieren und Konfigurieren einer Aufskalierungsplattform wie Apache Hadoop oder Apache Spark ermöglicht das bedarfsgerechte Abfragen nicht relationaler Daten. Durch die Verwendung zentraler Objektspeichersysteme, die die S3-API unterstützen, kann sowohl SQL Server 2022 (16.x) als auch Spark systemübergreifend auf dieselben Daten zugreifen.
Der Microsoft Apache Spark-Connector für SQL Server und Azure SQL bietet außerdem die Möglichkeit, Daten direkt aus SQL Server mit Spark-Aufträgen abzufragen. Weitere Informationen zum Apache Spark-Connector für SQL Server und Azure SQL finden Sie unter Apache Spark-Connector: SQL Server und Azure SQL.
Sie können auch das Kubernetes-Containerorchestrierungssystem für Ihre Bereitstellung verwenden. Dies ermöglicht eine deklarative Architektur, die lokal oder in einer beliebigen Cloud ausgeführt werden kann, die Kubernetes oder die Red Hat OpenShift-Plattform unterstützt. Weitere Informationen zum Bereitstellen von SQL Server in einer Kubernetes-Umgebung finden Sie unter Bereitstellen eines SQL Server-Containerclusters in Azure oder Bereitstellen von SQL Server 2019 in Kubernetes.
Verwenden Sie bei Bedarf SQL Server und Hadoop/Spark lokal als Ersatz für SQL Server 2019-Big Data-Cluster:
- Beibehalten der gesamten lokalen Lösung
- Verwenden dedizierter Hardware für alle Teile der Lösung
- Zugreifen auf relationale und nicht relationale Daten aus derselben Architektur in beiden Richtungen
- Freigeben eines einzelnen Satzes von nicht relationalen Daten zwischen SQL Server und dem nicht relationalen Aufskalierungssystem
Durchführen der Migration
Nachdem Sie einen Speicherort (in der Cloud oder hybrid) für Ihre Migration festgelegt haben, sollten Sie Downtime und Kostenvektoren abwägen, um zu bestimmen, ob Sie ein neues System ausführen und die Daten aus dem vorherigen System in Echtzeit in das neue System verschieben (gleichzeitige Migration), oder eine Sicherung und Wiederherstellung ausführen oder einen Neustart des Systems aus vorhandenen Datenquellen (direkte Migration).
Als Nächstes müssen Sie entweder die aktuelle Funktionalität in Ihrem System mithilfe der neuen Architekturauswahl umschreiben oder so viel Code wie möglich in das neue System verschieben. Die erste Option kann zwar länger dauern, ermöglicht Ihnen aber, die neuen Methoden, Konzepte und Vorteile zu nutzen, die die neue Architektur bietet. In diesem Fall sind die Datenzugriffs- und Funktionszuordnungen die wichtigsten Planungsschritte, auf die Sie sich konzentrieren sollten.
Wenn Sie planen, das aktuelle System mit so wenig Codeänderung wie möglich zu migrieren, liegt der Schwerpunkt bei der Planung auf der Sprachkompatibilität.
Codemigration
Der nächste Schritt ist das Überwachen des Codes, den das aktuelle System verwendet, und der Änderungen, die für die Ausführung in der neuen Umgebung vorgenommen werden müssen.
Es gibt zwei primäre Vektoren für die Codemigration, die zu berücksichtigen sind:
- Quellen und Senken
- Funktionsmigration
Quellen und Senken
Die erste Aufgabe bei der Codemigration besteht darin, die Methoden, Zeichenfolgen oder APIs der Datenquellenverbindung zu identifizieren, die der Code für den Zugriff auf die importierten Daten, den Pfad und das endgültige Ziel verwendet. Dokumentieren Sie diese Quellen, und erstellen Sie eine Karte zu den Speicherorten der neuen Architektur.
- Wenn die aktuelle Lösung ein Pipelinesystem verwendet, um die Daten durch das System zu verschieben, ordnen Sie die neuen Architekturquellen, Schritte und Senken den Komponenten der Pipeline zu.
- Wenn die neue Lösung auch die Pipelinearchitektur ersetzt, behandeln Sie das System zu Planungszwecken als neue Installation, auch wenn Sie die Hardware oder Cloudplattform als Ersatz wiederverwenden.
Funktionsmigration
Die komplexeste Arbeit, die für eine Migration erforderlich ist, besteht im Verweisen auf, Aktualisieren oder Erstellen der Dokumentation der Funktionen des aktuellen Systems. Wenn Sie ein direktes Upgrade planen und versuchen, so wenig Code wie möglich umzuschreiben, nimmt dieser Schritt die meiste Zeit in Anspruch.
Eine Migration von einer vorherigen Technologie ist jedoch häufig ein optimaler Zeitpunkt, um sich über den neuesten technologischen Stand zu informieren und die verfügbaren Konstrukte zu nutzen. Häufig können Sie mehr Sicherheit, Leistung, Featureauswahl und sogar Kostenoptimierungen erzielen, indem Sie Ihr aktuelles System neu schreiben.
In beiden Fällen sind zwei Hauptfaktoren an der Migration beteiligt: der Code und die Sprachen, die das neue System unterstützt, und die Optionen für die Datenverschiebung. In der Regel sollten Sie Verbindungszeichenfolgen vom aktuellen Big Data-Cluster zur SQL Server-Instanz und Spark-Umgebung ändern können. Alle Datenverbindungsinformationen und das Codecutover sollten minimal sein.
Wenn Sie die aktuelle Funktionalität neu schreiben möchten, ordnen Sie die neuen Bibliotheken, Pakete und DLL-Dateien der Architektur zu, die Sie für Ihre Migration ausgewählt haben. Eine Liste der Bibliotheken, Sprachen und Funktionen, die die Lösungen jeweils bieten, finden Sie in den Dokumentationsverweisen der vorherigen Abschnitte. Ordnen Sie alle verdächtigen oder nicht unterstützten Sprachen zu, und planen Sie den Ersatz durch die ausgewählte Architektur.
Optionen für die Datenmigration
Es gibt zwei gängige Ansätze für die Datenverschiebung in einem großen Analysesystem. Der erste ist das Erstellen eines „Cutoverprozesses“, bei dem das ursprüngliche System die Verarbeitung von Daten fortsetzt und diese Daten in einen kleineren Satz aggregierter Berichtsdatenquellen aufgerollt werden. Das neue System beginnt dann mit neuen Daten und wird ab dem Migrationsdatum verwendet.
In einigen Fällen müssen alle Daten vom Legacysystem zum neuen System verschoben werden. In diesem Fall können Sie die ursprünglichen Dateispeicher aus SQL Server Big Data Clusters einbinden, wenn das neue System dies unterstützt, und die Daten dann stückweise in das neue System kopieren, oder Sie können eine physische Verschiebung erstellen.
Die Migration Ihrer aktuellen Daten von einem SQL Server 2019-Big Data-Cluster auf ein anderes System hängt in hohem Maße von zwei Faktoren ab: dem Speicherort Ihrer aktuellen Daten und dem Zielort, entweder lokal oder in der Cloud.
Lokale Datenmigration
Für Lokal-zu-lokal-Migrationen können Sie die SQL Server-Daten mit einer Sicherungs- und Wiederherstellungsstrategie migrieren oder die Replikation einrichten, um einige oder alle relationalen Daten zu verschieben. SQL Server Integration Services kann auch zum Kopieren von Daten aus SQL Server an einen anderen Speicherort verwendet werden. Weitere Informationen zum Verschieben von Daten mit SSIS finden Sie unter SQL Server Integration Services.
Der Standardansatz für HDFS-Daten in Ihrer aktuellen SQL Server-Big Data-Cluster-Umgebung ist das Einbinden der Daten in einen eigenständigen Spark-Cluster, und dann entweder den Objektspeicherprozess zu verwenden, um die Daten so zu verschieben, dass eine Instanz von SQL Server 2022 (16.x) darauf zugreifen kann, oder sie im aktuellen Zustand zu belassen und ihre Bearbeitung mit Spark-Aufträgen fortzusetzen.
Cloudinterne Datenmigration
Für Daten, die im Cloudspeicher oder lokal gespeichert sind, können Sie Azure Data Factory verwenden. Dort stehen mehr als 90 Connectors für eine vollständige Übertragungspipeline mit Planung, Überwachung, Warnungen und anderen Diensten zur Verfügung. Weitere Informationen zu Azure Data Factory finden Sie unter Was ist Azure Data Factory?.
Wenn Sie große Datenmengen sicher und schnell aus Ihrem lokalen Datenbereich in Microsoft Azure verschieben möchten, können Sie den Azure Import/Export-Dienst verwenden. Mit dem Azure Import/Export-Dienst können Sie große Datenmengen auf sichere Weise in Azure Blob Storage und Azure Files übertragen, indem Sie Festplattenlaufwerke an ein Azure-Rechenzentrum senden. Sie können diesen Dienst auch zum Übertragen von Daten aus Azure Blob Storage auf Festplattenlaufwerke und zum Versand an lokale Standorte nutzen. Daten von einem oder mehreren Datenträgern können in Azure Blob Storage oder in Azure Files importiert werden. Bei extrem großen Datenmengen kann die Verwendung dieses Diensts der schnellste Weg sein.
Wenn Sie Daten mit den von Microsoft bereitgestellten Datenträgern übermitteln möchten, können Sie mithilfe des Azure Data Box-Datenträgers Daten in Azure importieren. Weitere Informationen finden Sie unter Was ist der Azure Import/Export-Dienst?.
Weitere Informationen zu diesen Auswahlmöglichkeiten und den damit zu treffenden Entscheidungen finden Sie unter Verwenden von Azure Data Lake Storage Gen1 für Big Data-Anforderungen.