Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Databricks ist eine einheitliche, offene Analyseplattform zum Erstellen, Bereitstellung, Teilen und Verwalten von Daten, Analysen und KI-Lösungen der Unternehmensklasse in großem Maßstab. Die Databricks Data Intelligence-Plattform lässt sich in Ihrem Cloudkonto in Cloudspeicher und Sicherheit integrieren und übernimmt die Verwaltung und Bereitstellung der Cloudinfrastruktur für Sie.
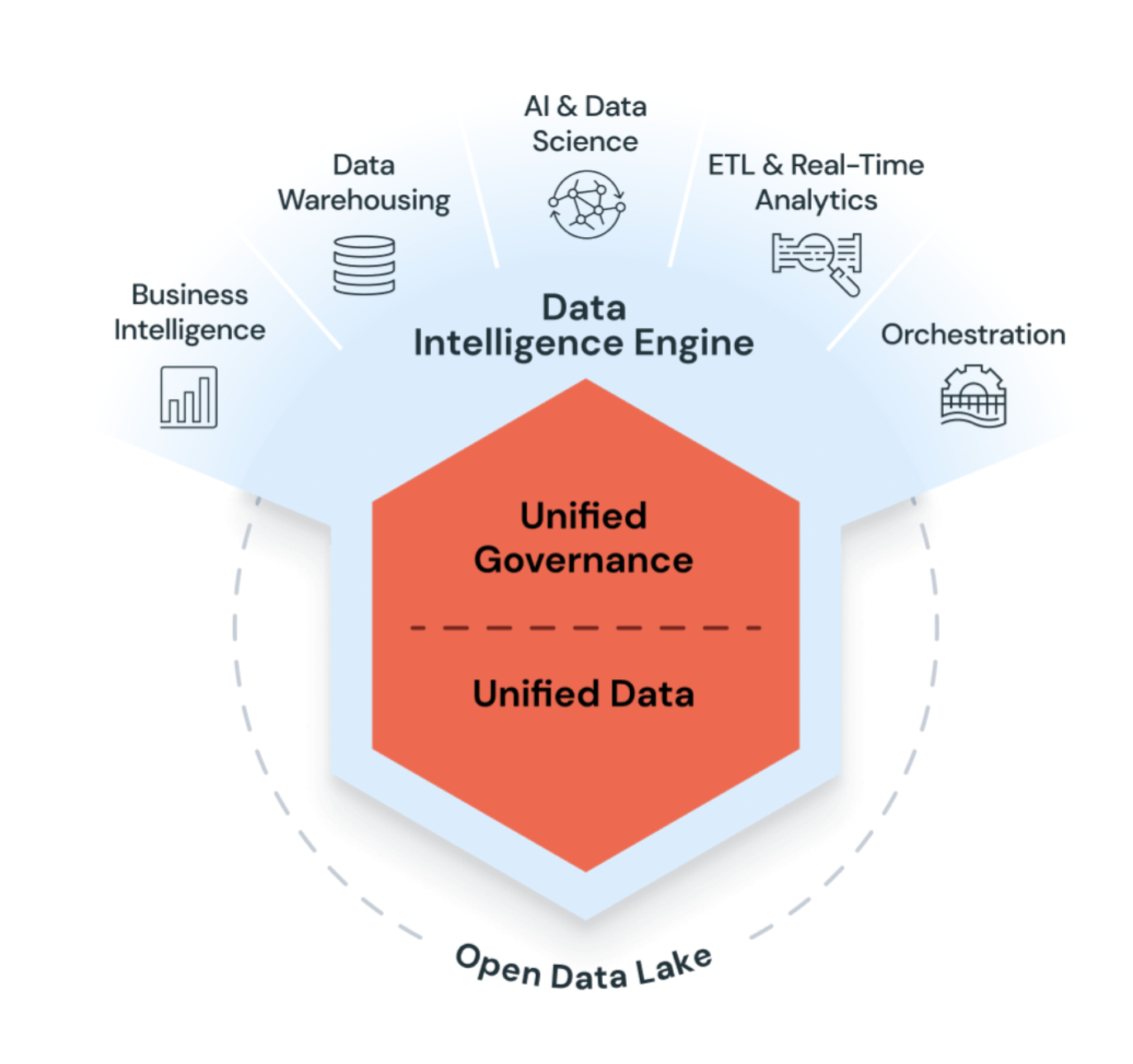
Azure Databricks verwendet generative KI mit dem Data Lakehouse, um die spezifische Semantik Ihrer Daten zu verstehen. Anschließend wird automatisch die Leistung optimiert und die Infrastruktur entsprechend Ihren geschäftlichen Anforderungen verwaltet.
Die Verarbeitung natürlicher Sprachen lernt die Sprache Ihres Unternehmens, sodass Sie Daten durchsuchen und ermitteln können, indem Sie eine Frage in Ihren eigenen Worten stellen. Die Unterstützung in natürlicher Sprache hilft Ihnen, Code zu schreiben, Fehler zu beheben und Antworten in der Dokumentation zu finden.
Verwaltete Open Source-Integration
Databricks setzt sich für die Open Source-Community ein und verwaltet Updates von Open Source-Integrationen mit den Databricks-Runtime-Versionen. Die folgenden Technologien sind Open Source-Projekte, die ursprünglich von Databricks-Mitarbeiter:innen erstellt wurden:
Gängige Anwendungsfälle
In den folgenden Anwendungsfällen werden einige der Möglichkeiten hervorgehoben, wie Kunden Azure Databricks verwenden, um Aufgaben auszuführen, die für die Verarbeitung, Speicherung und Analyse der Daten erforderlich sind, die wichtige Geschäftsfunktionen und Entscheidungen bewirken.
Erstellen eines Data Lakehouse für Unternehmen
Das Data Lakehouse kombiniert Enterprise Data Warehouses und Data Lakes, um Unternehmensdatenlösungen zu beschleunigen, zu vereinfachen und zu vereinheitlichen. Dateningenieure, Datenwissenschaftler, Analysten und Produktionssysteme können das Data Lakehouse als einzige Wahrheitsquelle nutzen, den Zugang zu konsistenten Daten ermöglichen und die Komplexität beim Aufbau, der Wartung und Synchronisierung vieler verteilter Datensysteme vereinfachen. Weitere Informationen finden Sie unter Was ist ein Data Lakehouse?.
ETL und Datentechnik
Ganz gleich, ob Sie Dashboards generieren oder Künstliche Intelligenz-Anwendungen nutzen, Datentechnik bietet das Rückgrat für datenorientierte Unternehmen, indem Sie sicherstellen, dass Daten verfügbar, sauber und in Datenmodellen gespeichert sind, um eine effiziente Ermittlung und Verwendung zu ermöglichen. Azure Databricks kombiniert die Leistungsfähigkeit von Apache Spark mit Delta und benutzerdefinierten Tools, um eine unvergleichliche ETL-Erfahrung zu bieten. Verwenden Sie SQL, Python und Scala, um ETL-Logik zu verfassen und geplante Auftragsbereitstellung mit wenigen Klicks zu koordinieren.
Lakeflow Declarative Pipelines vereinfacht ETL weiter, indem Abhängigkeiten zwischen Datasets intelligent verwaltet und die Produktionsinfrastruktur automatisch bereitgestellt und skaliert wird, um eine zeitnahe und genaue Datenübermittlung an Ihre Spezifikationen sicherzustellen.
Azure Databricks bietet Tools für die Datenaufnahme, einschließlich Auto Loader, ein effizientes und skalierbares Tool zum inkrementellen und idempotenten Laden von Daten aus Cloud-Objektspeichern und Datenseen in das Data Lakehouse.
Maschinelles Lernen, KI und Data Science
Maschinelles Lernen in Azure Databricks erweitert die Kernfunktionen der Plattform um eine Suite von Tools, die auf die Anforderungen von wissenschaftlichen Fachkräften für Daten und ML-Techniker zugeschnitten sind, darunter MLflow und Databricks Runtime für Machine Learning.
Große Sprachmodelle und generative KI
Databricks Runtime for Machine Learning umfasst Bibliotheken wie Hugging Face Transformers , mit denen Sie vorhandene vortrainierte Modelle oder andere Open Source-Bibliotheken in Ihren Workflow integrieren können. Die Databricks MLflow-Integration erleichtert die Verwendung des MLflow-Nachverfolgungsdiensts mit Transformatorpipelines, Modellen und Verarbeitungskomponenten. Integrieren Sie OpenAI-Modelle oder Lösungen von Partnern wie John Snow Labs in Ihre Databricks-Workflows.
Mit Azure Databricks können Sie ein LLM auf Ihre Daten für Ihre spezifische Aufgabe anpassen. Mit Unterstützung von Open Source-Tools wie Hugging Face und DeepSpeed können Sie effizient ein grundlegendes LLM erstellen und mit dem Training mit Ihren eigenen Daten beginnen, um größere Genauigkeit für Ihre Domäne und Workload zu erzielen.
Darüber hinaus bietet Azure Databricks KI-Funktionen, mit denen SQL-Datenanalysten direkt innerhalb ihrer Datenpipelines und Workflows auf LLM-Modelle zugreifen können (auch aus OpenAI). Siehe Anwenden von KI auf Daten mithilfe von Azure Databricks AI Functions.
Data Warehousing, Analyse und BI
Azure Databricks kombiniert benutzerfreundliche Benutzeroberflächen mit kostengünstigen Computeressourcen und unendlich skalierbarem, erschwinglichem Speicher, um eine leistungsstarke Plattform für die Ausführung von Analyseabfragen bereitzustellen. Administratoren konfigurieren skalierbare Computecluster als SQL-Warehouses, was Endbenutzern die Ausführung von Abfragen ermöglicht, ohne sie mit den komplexen Details des Arbeitens in der Cloud zu belasten. SQL-Benutzer können Abfragen auf Daten im Lakehouse mit dem SQL-Abfrage-Editor oder in Notebooks ausführen. Notebooks unterstützen über SQL hinaus Python, R und Scala und ermöglichen Benutzern und Benutzerinnen das Einbetten derselben Visualisierungen, die in Legacy-Dashboards zur Verfügung stehen, parallel zu Links, Bildern und in Markdown geschriebenen Kommentaren.
Datengovernance und sichere Datenfreigabe
Unity Catalog bietet ein einheitliches Daten-Governance-Modell für das Data Lakehouse. Cloudadministratoren konfigurieren und integrieren grobe Zugriffssteuerungsberechtigungen für Unity Catalog, und dann können Azure Databricks-Administratoren Berechtigungen für Teams und Einzelpersonen verwalten. Berechtigungen werden mit Zugriffssteuerungslisten (ACLs) mithilfe von benutzerfreundlichen Benutzeroberflächen oder SQL-Syntax verwaltet, was es für Datenbankadministratoren einfacher macht, den Zugriff auf Daten abzusichern, ohne auf cloudnative Verwaltung des Identitätszugriffs (IAM) und Netzwerke skalieren zu müssen.
Unity Catalog vereinfacht die Durchführung sicherer Analysen in der Cloud und bietet eine Rollenverteilung, die hilft, die notwendige Umschulung oder Weiterbildung für Administratoren und Endbenutzer der Plattform zu begrenzen. Siehe Was ist Unity Catalog?.
Durch das Lakehouse wird die Datenfreigabe in Ihrer Organisation so einfach wie das Erteilen des Abfragezugriffs auf eine Tabelle oder Ansicht. Für die Freigabe außerhalb Ihrer sicheren Umgebung bietet Unity Catalog eine verwaltete Version von Delta Sharing.
DevOps, CI/CD und Orchestrierung von Aufgaben
Die Entwicklungslebenszyklen für ETL-Pipelines, ML-Modelle und Analyse-Dashboards stellen jeweils eigene, einzigartige Herausforderungen dar. Azure Databricks ermöglicht es allen Benutzern, eine einzelne Datenquelle zu nutzen, wodurch doppelte Anstrengungen und nicht synchronisierte Berichte reduziert werden. Wenn Sie zusätzlich eine Reihe gängiger Tools für Versionsverwaltung, Automatisierung, Planung, Bereitstellung von Code und Produktionsressourcen bereitstellen, können Sie Ihren Mehraufwand für Überwachung, Orchestrierung und Betrieb vereinfachen.
Mit Aufträgen werden Azure Databricks-Notebooks, SQL-Abfragen und anderer beliebiger Code geplant. Databricks Asset Bundles ermöglichen Es Ihnen, Databricks-Ressourcen wie Aufträge und Pipelines programmgesteuert zu definieren, bereitzustellen und auszuführen. Git-Ordner ermöglichen Es Ihnen, Azure Databricks-Projekte mit einer Reihe beliebter Git-Anbieter zu synchronisieren.
Bewährte Methoden und Empfehlungen für CI/CD finden Sie unter Bewährte Methoden und empfohlenen CI/CD-Workflows auf Databricks. Eine vollständige Übersicht über Tools für Entwickler finden Sie unter Develop on Databricks.
Echtzeit- und Streaminganalysen
Azure Databricks nutzt Apache Spark Structured Streaming für die Arbeit mit Streamingdaten und inkrementellen Datenänderungen. Strukturiertes Streaming ist eng in Delta Lake integriert, und diese Technologien bieten die Grundlagen für Lakeflow Declarative Pipelines und Auto Loader. Siehe Konzepte des strukturierten Streamings.