Bereitstellen eines Big Data-Clusters für SQL Server mit einem Azure Data Studio-Notebook
Gilt für: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
SQL Server stellt eine Erweiterung für Azure Data Studio bereit, die Bereitstellungsnotebooks umfasst. Ein Bereitstellungsnotebook enthält Dokumentation und Code, die Sie in Azure Data Studio verwenden können, um Big Data-Cluster für SQL Server zu erstellen.
Notebooks, die ursprünglich als Open-Source-Projekt implementiert wurden, wurden in Azure Data Studio implementiert. Sie können Markdown für Text in den Textzellen und einen der verfügbaren Kernel verwenden, um Code in den Codezellen zu schreiben.
Sie können Notebooks für die Bereitstellung von Big Data-Cluster für SQL Server verwenden.
Voraussetzungen
Die folgenden Voraussetzungen müssen erfüllt sein, damit auch das Notebook gestartet werden kann:
- Installation der neuesten Version von Azure Data Studio Insiders-Build
Zusätzlich hierzu ist für die Bereitstellung eines Big Data-Clusters Folgendes erforderlich:
Starten des Notebooks
Starten Sie Azure Data Studio.
Wählen Sie auf der Registerkarte Verbindungen die Auslassungspunkte ( ... ) aus, und wählen Sie dann Deploy SQL Server... (SQL Server bereitstellen...) aus.
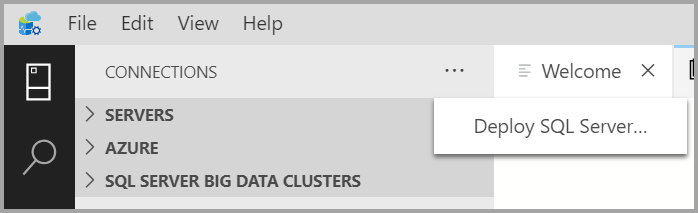
Wählen Sie unter den Bereitstellungsoptionen SQL Server Big Data-Cluster aus.
Wählen Sie in Bereitstellungsziel unter Optionen entweder Neuer Azure Kubernetes-Cluster oder Vorhandener Azure Kubernetes Service-Cluster aus.
Akzeptieren Sie die Datenschutz- und Lizenzbedingungen.
In diesem Dialogfeld wird außerdem überprüft, ob die erforderlichen Tools für den ausgewählten SQL-Bereitstellungstyp auf dem Host vorhanden sind. Die Schaltfläche Auswählen wird erst aktiviert, wenn die Überprüfung der Tools erfolgreich war.
Wählen Sie die Schaltfläche Auswählen aus. Mit dieser Aktion wird die Bereitstellung gestartet.
Festlegen einer Vorlage für die Bereitstellungskonfiguration
Sie können die Einstellungen des Bereitstellungsprofils anpassen, indem Sie die folgenden Anweisungen befolgen.
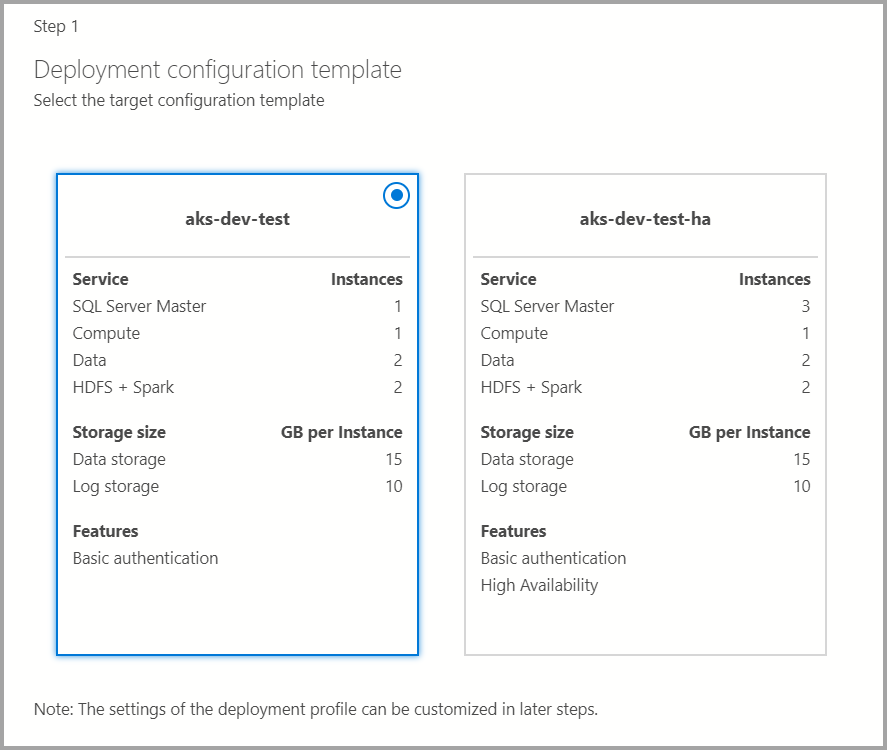
Vorlage für die Zielkonfiguration
Wählen Sie die Vorlage für die Zielkonfiguration aus den verfügbaren Vorlagen aus. Die verfügbaren Profile werden abhängig vom Typ des Bereitstellungsziels gefiltert, das im vorherigen Dialogfeld ausgewählt wurde.
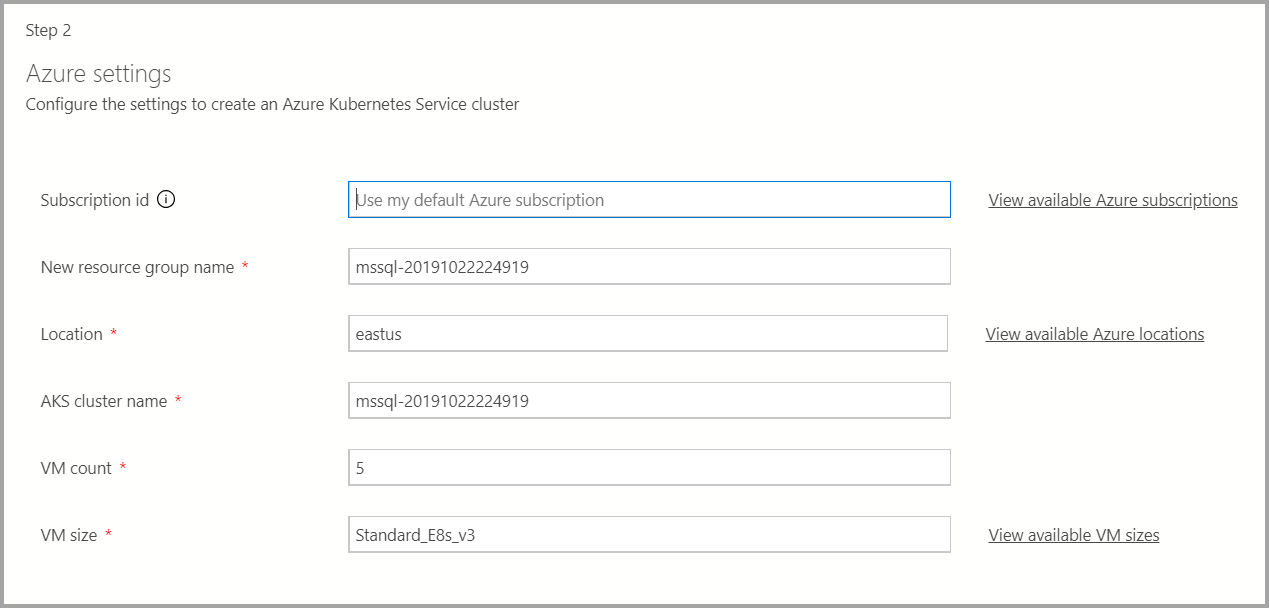
Azure-Einstellungen
Wenn als Bereitstellungsziel ein neuer AKS-Cluster (Azure Kubernetes Service) verwendet wird, werden zusätzliche Informationen wie die Azure-Abonnement-ID, die Ressourcengruppe, der AKS-Clustername, die Anzahl und Größe virtueller Computer sowie weitere zusätzliche Informationen benötigt, um den AKS-Cluster zu erstellen.
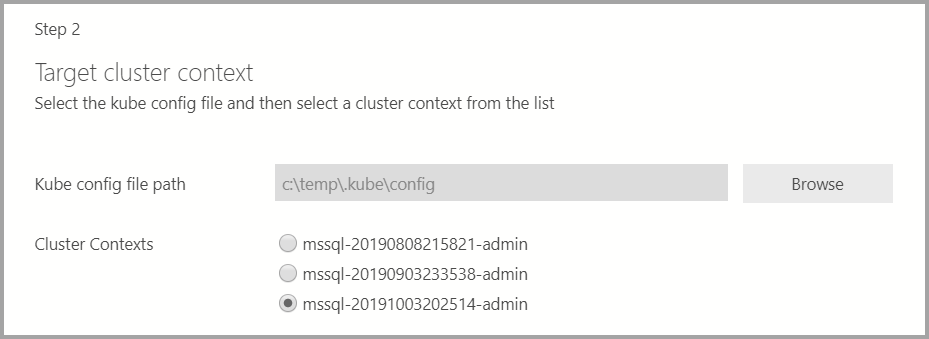
Wenn das Bereitstellungsziel ein vorhandener Kubernetes-Cluster ist, fordert der Assistent den Pfad zur Kube-Konfigurationsdatei zum Importieren der Kubernetes-Clustereinstellungen auf. Stellen Sie sicher, dass der entsprechende Clusterkontext ausgewählt ist, in dem der Big Data-Cluster für SQL Server 2019 bereitgestellt werden kann.
Einstellungen für Cluster, Docker und AD
Geben Sie den Clusternamen für den Big Data-Cluster, einen Administratorbenutzernamen und ein Kennwort ein. Dieses Konto wird auch für den Controller und SQL Server verwendet.
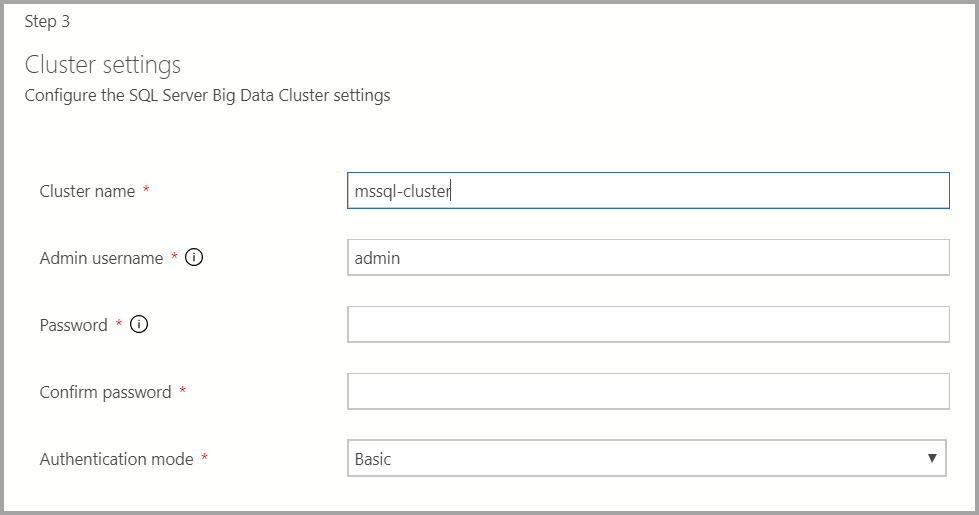
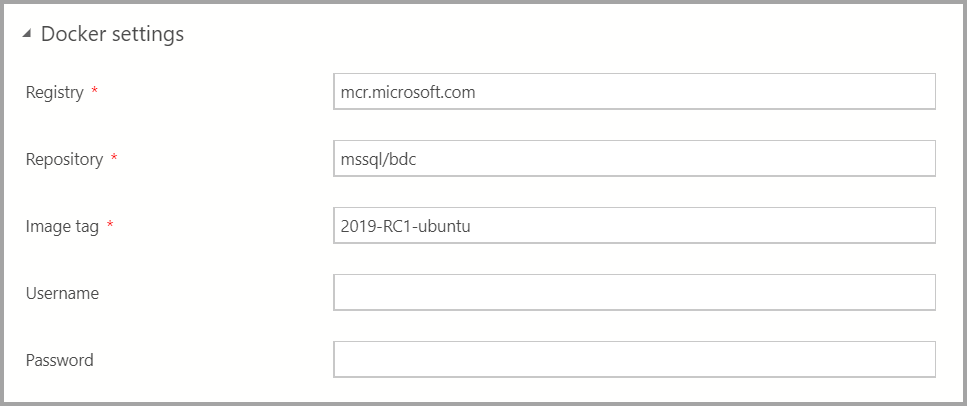
Geben Sie die entsprechenden Docker-Einstellungen ein.
Wichtig
Stellen Sie sicher, dass das Imagetagfeld aktuell ist: 2019-CU13-ubuntu-20.04.
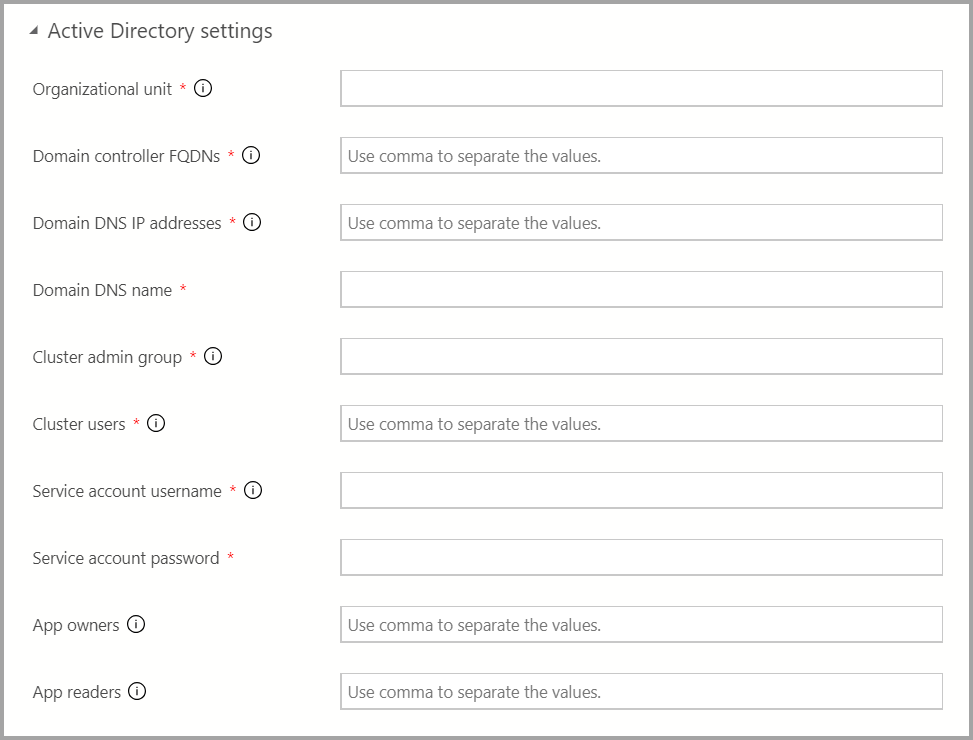
Falls die AD-Authentifizierung verfügbar ist, geben Sie die AD-Einstellungen ein.
Diensteinstellungen
Auf diesem Bildschirm können Sie verschiedene Einstellungen wie Skalierung, Endpunkte, Speicher und andere erweiterte Speichereinstellungen festlegen. Geben Sie die entsprechenden Werte ein, und klicken Sie auf Weiter.
Skalierungseinstellungen
Geben Sie die Anzahl der Instanzen der einzelnen Komponenten im Big Data-Cluster ein.
Eine Spark-Instanz kann zusammen mit HDFS eingeschlossen werden. Sie ist im Speicherpool oder eigenständig im Spark-Pool enthalten.
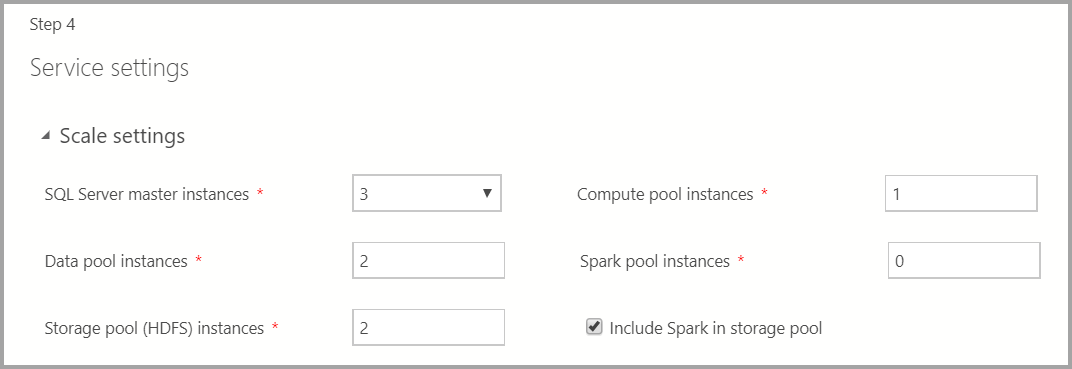
Weitere Informationen zu den einzelnen Komponenten finden Sie unter Masterinstanz, Datenpool, Speicherpool oder Computepool.
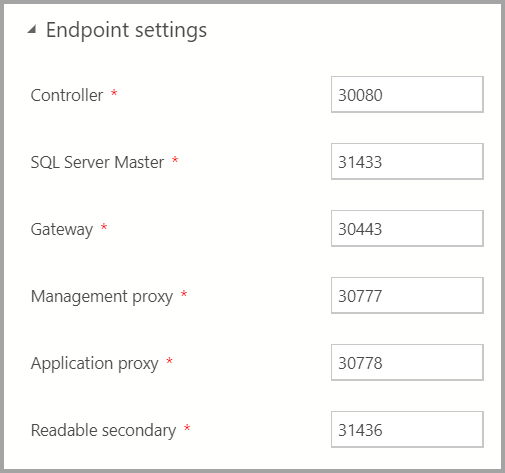
Endpunkteinstellungen
Die Standardendpunkte wurden vorab ausgefüllt. Sie können jedoch nach Bedarf geändert werden.
Speichereinstellungen
Die Speichereinstellungen umfassen die Speicherklasse und die Anspruchsgröße für Daten und Protokolle. Die Einstellungen können auf den Speicherpool, Datenpool und SQL Server-Masterpool angewendet werden.

Erweiterte Speichereinstellungen
Sie können unter Erweiterte Speichereinstellungen zusätzliche Speichereinstellungen hinzufügen.
Speicherpool (HDFS)
Datenpool
SQL Server Master

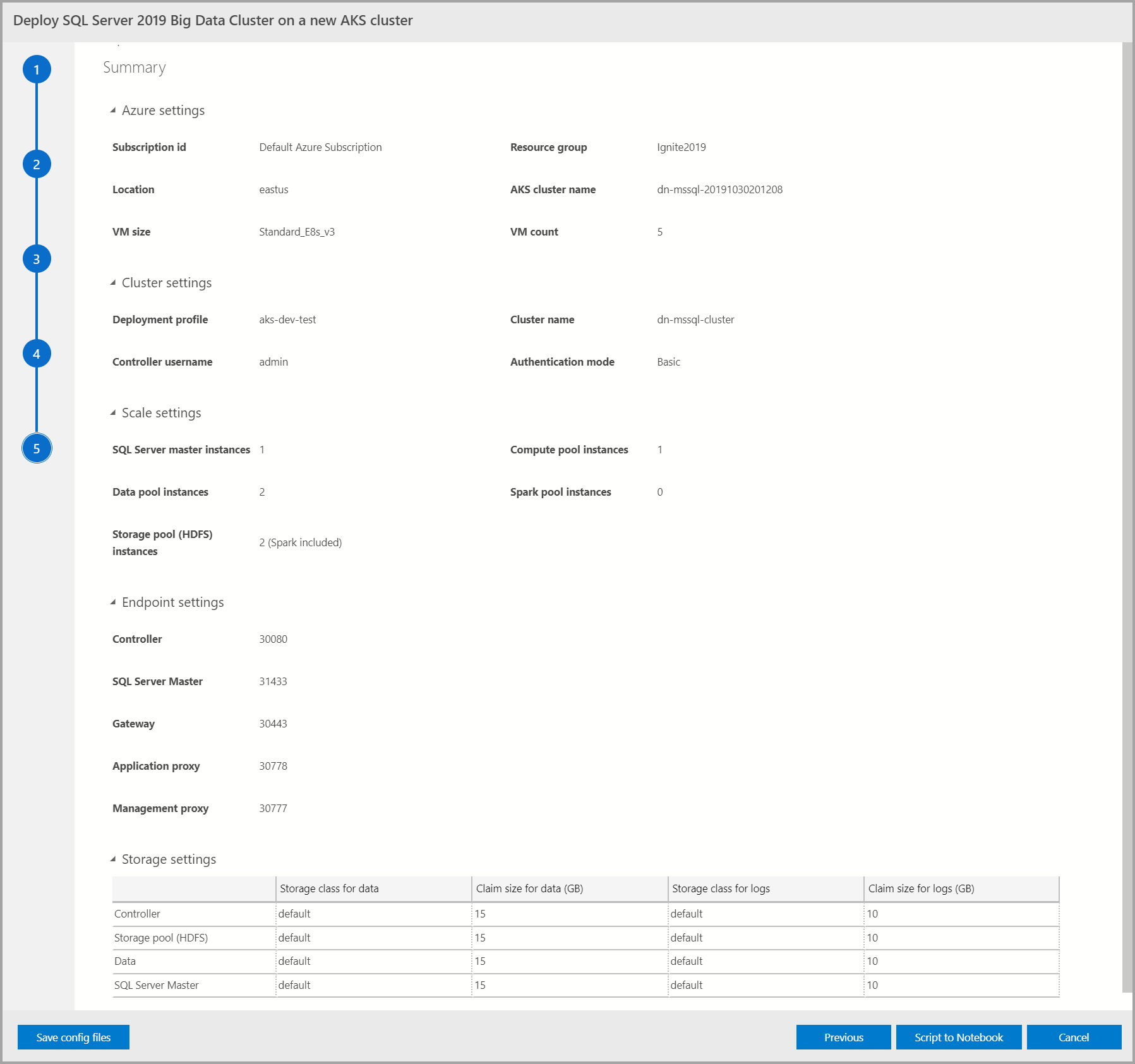
Zusammenfassung
Dieser Bildschirm enthält eine Zusammenfassung aller Daten, die für die Bereitstellung des Big Data-Clusters eingegeben wurden. Die Konfigurationsdateien können über die Schaltfläche Save config files (Konfigurationsdateien speichern) heruntergeladen werden. Wählen Sie Skript in Notebook schreiben aus, um ein Skript für die gesamte Bereitstellungskonfiguration in ein Notebook zu schreiben. Wenn das Notebook geöffnet ist, wählen Sie Zellen ausführen aus, um mit der Bereitstellung des Big Data-Clusters für das ausgewählte Ziel zu beginnen.
Nächste Schritte
Weitere Informationen zur Bereitstellung finden Sie unter Bereitstellen von Big Data-Cluster für SQL Server in Kubernetes.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für