Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server
SQL Server
In diesem Artikel werden Konzepte der Always On-Verfügbarkeitsgruppen vorgestellt, die beim Konfigurieren und Verwalten von einer oder mehreren Verfügbarkeitsgruppen in der Enterprise-Edition von SQL Server von großer Bedeutung sind. Lesen Sie für die Standard Edition die Informationen unter Always On-Basisverfügbarkeitsgruppen für einzelne Datenbanken.
Die Funktion Always On-Verfügbarkeitsgruppen ist eine Lösung für hohe Verfügbarkeit und Notfallwiederherstellung, die eine Alternative zur Datenbankspiegelung auf Unternehmensebene bietet. Always On-Verfügbarkeitsgruppen maximieren die Verfügbarkeit eines Satzes von Benutzerdatenbanken für ein Unternehmen. Eine Verfügbarkeitsgruppe unterstützt eine Failoverumgebung für einen diskreten Satz von Benutzerdatenbanken (als Verfügbarkeitsdatenbankenbezeichnet), die zusammen ein Failover ausführen. Eine Verfügbarkeitsgruppe unterstützt einen Satz primärer Datenbanken mit Lese-/Schreibzugriff und einen bis acht Sätze entsprechender sekundärer Datenbanken. Optional können sekundäre Datenbanken für schreibgeschützten Zugriff und/oder einige Sicherungsvorgänge verfügbar gemacht werden.
Mit SQL Server mit Azure Arc-Unterstützung können Sie im Azure-Portal Verfügbarkeitsgruppen anzeigen.
Übersicht
Eine Verfügbarkeitsgruppe unterstützt eine replizierte Umgebung für einen diskreten Satz von Benutzerdatenbanken (als Verfügbarkeitsdatenbankenbezeichnet). Sie können eine Verfügbarkeitsgruppe für Hochverfügbarkeit (HA) oder Leseskalierung einrichten. Eine HA-Verfügbarkeitsgruppe ist eine Gruppe von Datenbanken, die zusammen ein Failover ausführen. Eine Verfügbarkeitsgruppe zur Leseskalierung ist eine Gruppe von Datenbanken, die für eine schreibgeschützte Arbeitsauslastung in andere Instanzen von SQL Server kopiert werden. Eine Verfügbarkeitsgruppe unterstützt einen Satz primärer Datenbanken und einen bis acht Sätze entsprechender sekundärer Datenbanken. Sekundäre Datenbanken sind keine Backups. Führen Sie regelmäßige Sicherungen Ihrer Datenbanken und ihrer Transaktionsprotokolle durch.
Tipp
Von einer primären Datenbank können beliebige Sicherungstypen erstellt werden. Alternativ können Sie Protokollsicherungen und vollständige Kopiesicherungen von sekundären Datenbanken erstellen. Weitere Informationen finden Sie unter Auslagern unterstützter Backups auf sekundäre Replikate einer Verfügbarkeitsgruppe.
Jeder Satz von Verfügbarkeitsdatenbanken wird von einem Verfügbarkeitsreplikat gehostet. Es existieren zwei Arten von Verfügbarkeitsreplikaten: ein einzelnes primäres Replikat, das die primären Datenbanken hostet, und ein bis acht sekundäre Replikate, von denen jedes eine Gruppe sekundärer Datenbanken hostet und als potenzielle Failover-Ziele für die Verfügbarkeitsgruppe dient. Eine Verfügbarkeitsgruppe führt auf der Ebene eines Verfügbarkeitsreplikats ein Failover aus. Ein Verfügbarkeitsreplikat gewährleistet nur Redundanz auf Datenbankebene, und zwar für die in einer Verfügbarkeitsgruppe enthaltenen Datenbanken. Failover werden nicht durch Datenbankprobleme verursacht, z. B. wenn eine Datenbank aufgrund eines Verlusts einer Datendatei oder der Beschädigung eines Transaktionsprotokolls fehlerverdächtig wird.
Das primäre Replikat stellt die primären Datenbanken für Lese-/Schreibverbindungen von Clients bereit. Vom primären Replikat werden Transaktionsprotokoll-Datensätze jeder primären Datenbank an jede sekundäre Datenbank gesendet. Dieser auch als Datensynchronisierung bezeichnete Prozess findet auf Datenbankebene statt. Die Transaktionsprotokoll-Datensätze werden von jedem sekundären Replikat zwischengespeichert (das Protokoll wirdfestgeschrieben) und anschließend auf die entsprechende sekundäre Datenbank angewendet. Die Datensynchronisierung erfolgt zwischen der primären Datenbank und jeder verbundenen sekundären Datenbank unabhängig von den anderen Datenbanken. Daher kann eine sekundäre Datenbank fehlschlagen oder angehalten werden, ohne dass sich dies auf andere sekundäre Datenbanken auswirkt, und eine primäre Datenbank kann fehlschlagen oder angehalten werden, ohne dass sich dies auf andere primäre Datenbanken auswirkt.
Optional können Sie mindestens ein sekundäres Replikat konfigurieren, um schreibgeschützten Zugriff auf sekundäre Datenbanken zu unterstützen, und ein beliebiges sekundäres Replikat konfigurieren, um Sicherungen auf sekundären Datenbanken zuzulassen.
SQL Server 2017 (14.x) hat zwei verschiedene Architekturen für Verfügbarkeitsgruppen eingeführt. Always On-Verfügbarkeitsgruppen bieten hohe Verfügbarkeit, Notfallwiederherstellung und Lastausgleich für Lesevorgänge. Diese Verfügbarkeitsgruppen erfordern einen Cluster-Manager. Unter Windows wird der Cluster-Manager vom Failoverclustering-Feature bereitgestellt. Unter Linux können Sie Pacemaker verwenden. Die andere Architektur ist eine Verfügbarkeitsgruppe zur Leseskalierung. Eine Verfügbarkeitsgruppe zur Leseskalierung stellt Replikate für schreibgeschützte Workloads bereit, jedoch nicht für Hochverfügbarkeit. In einer Verfügbarkeitsgruppe mit Leseskalierung gibt es keinen Cluster-Manager, da das Failover nicht automatisch erfolgen kann.
Bei der Bereitstellung von Always On-Verfügbarkeitsgruppen für Hochverfügbarkeit unter Windows ist ein Windows Server-Failovercluster (WSFC) erforderlich. Jedes Verfügbarkeitsreplikat einer bestimmten Verfügbarkeitsgruppe muss sich in einem anderen Knoten desselben WSFC befinden. Die einzige Ausnahme besteht darin, dass sich eine Verfügbarkeitsgruppe während der Migration zu einem anderen WSFC-Cluster vorübergehend auf zwei Cluster erstrecken kann.
Hinweis
Weitere Informationen zu Verfügbarkeitsgruppen unter Linux finden Sie unter Verfügbarkeitsgruppen für SQL Server unter Linux.
In einer HA-Konfiguration wird eine Clusterrolle für jede Verfügbarkeitsgruppe erstellt. Der WSFC-Cluster überwacht diese Rolle, um den Zustand des primären Replikats auszuwerten. Das Quorum für Always On-Verfügbarkeitsgruppen basiert auf allen Knoten des WSFC-Clusters, unabhängig davon, ob ein bestimmter Clusterknoten Verfügbarkeitsreplikate hostet. Anders als bei der Datenbankspiegelung ist in Always On-Verfügbarkeitsgruppen keine Zeugenrolle verfügbar.
Hinweis
Weitere Informationen über die Beziehung der SQL Server Always On-Komponenten zum WSFC-Cluster finden Sie unter Windows Server Failover Clustering mit SQL Server.
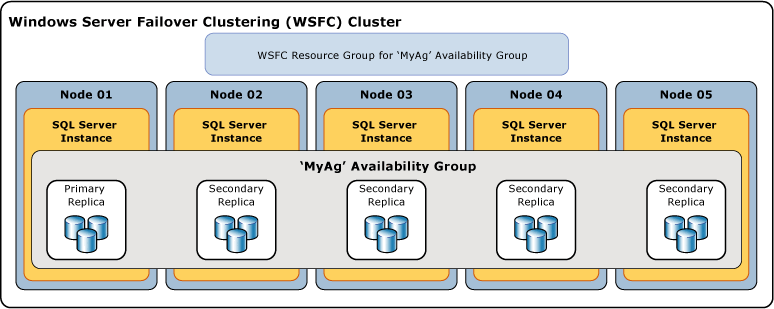
In der folgenden Abbildung ist eine Verfügbarkeitsgruppe dargestellt, die ein primäres Replikat und vier sekundäre Replikate enthält. Es werden bis zu acht sekundäre Replikate unterstützt, einschließlich eines primären Replikats und vier sekundärer Replikate mit synchronem Commit.
Konfigurieren der TLS 1.3-Verschlüsselung
SQL Server 2025 (17.x) führt tabellarische Datenstrom-Unterstützung 8.0 ein, mit der Sie die TLS 1.3-Verschlüsselung für die Kommunikation zwischen dem Windows Server-Failovercluster und Ihren AlwaysOn-Verfügbarkeitsgruppenreplikaten erzwingen können.
Weitere Informationen finden Sie unter TDS 8-Unterstützung in SQL Server 2025 weiter unten in diesem Artikel.
Überprüfen Sie zunächst die Verbindung mit strenger Verschlüsselung.
Begriffe und Definitionen
| Begriff | Beschreibung |
|---|---|
| Verfügbarkeitsgruppe | Ein Container für eine Gruppe von Datenbanken ( Verfügbarkeitsdatenbanken), für die zusammen ein Failover ausgeführt wird. |
| Verfügbarkeitsdatenbank | Eine Datenbank, die zu einer Verfügbarkeitsgruppe gehört. Für jede Verfügbarkeitsdatenbank verwaltet die Verfügbarkeitsgruppe eine einzelne Lese-/Schreibkopie (die primäre Datenbank) und eine bis acht schreibgeschützte Kopien (sekundäre Datenbanken). |
| primäre Datenbank | Die Lese-/Schreibkopie einer Verfügbarkeitsdatenbank. |
| sekundäre Datenbank | Eine schreibgeschützte Kopie einer Verfügbarkeitsdatenbank. |
| Verfügbarkeitsreplikat | Eine Instanziierung einer Verfügbarkeitsgruppe, die von einer spezifischen Instanz des SQL Servers gehostet wird und eine lokale Kopie jeder Verfügbarkeitsdatenbank verwaltet, die zur Verfügbarkeitsgruppe gehört. Zwei Typen von Verfügbarkeitsreplikaten sind vorhanden: ein einzelnes primäres Replikat und ein bis acht sekundäre Replikate. |
| primäre Replik | Das Verfügbarkeitsreplikat, das die primären Datenbanken für Lese-/Schreibverbindungen von Clients verfügbar macht und darüber hinaus Transaktionsprotokoll-Datensätze für jede primäre Datenbank an jedes sekundäre Replikat sendet. |
| sekundäre Replik | Ein Verfügbarkeitsreplikat, das eine sekundäre Kopie jeder Verfügbarkeitsdatenbank beibehält und als potenzielles Failoverziel für die Verfügbarkeitsgruppe dient. Optional kann ein sekundäres Replikat schreibgeschützten Zugriff auf sekundäre Datenbanken und das Erstellen von Sicherungen für sekundäre Datenbanken unterstützen. |
| Verfügbarkeitsgruppen-Listener | Ein Servername, mit dem Clients eine Verbindung herstellen können, um auf eine Datenbank in einem primären oder sekundären Replikat einer Always On-Verfügbarkeitsgruppe zuzugreifen. Verfügbarkeitsgruppenlistener leiten eingehende Verbindungen an das primäre Replikat oder ein schreibgeschütztes sekundäres Replikat weiter. |
Verfügbarkeitsdatenbanken
Zum Hinzufügen einer Datenbank zu einer Verfügbarkeitsgruppe muss die Datenbank eine Onlinedatenbank mit Lese-/Schreibzugriff auf der Serverinstanz sein, die das primäre Replikat hostet. Wenn Sie eine Datenbank hinzufügen, wird sie als primäre Datenbank mit der Verfügbarkeitsgruppe verknüpft, wobei sie für Clients verfügbar bleibt. Es ist keine entsprechende sekundäre Datenbank vorhanden, bis Sie Sicherungen der neuen primären Datenbank auf der Serverinstanz wiederherstellen, die das sekundäre Replikat hostet (mit RESTORE WITH NORECOVERY). Die neue sekundäre Datenbank befindet sich im RESTORING Status, bis sie der Verfügbarkeitsgruppe beigetreten ist. Weitere Informationen finden Sie unter Starten der Datenverschiebung für eine sekundäre Always On-Datenbank (SQL Server).
Durch das Verknüpfen wird die sekundäre Datenbank in den ONLINE Zustand versetzt und die Datensynchronisierung mit der entsprechenden primären Datenbank initiiert.
Daten-Synchronisierung ist der Prozess, bei dem Änderungen an einer primären Datenbank auf eine sekundäre Datenbank übertragen werden. Bei der Datensynchronisierung sendet die primäre Datenbank Transaktionsprotokoll-Datensätze an die sekundäre Datenbank.
Wichtig
Eine Verfügbarkeitsdatenbank wird in Transact-SQL-, PowerShell- und SQL Server Management Objects-Namen (SMO) manchmal als Datenbankreplikat bezeichnet. Der Begriff „Datenbankreplikat“ wird z.B. in den Namen der dynamischen Always On-Verwaltungssichten verwendet, die Informationen zu Verfügbarkeitsdatenbanken zurückgeben: sys.dm_hadr_database_replica_states und sys.dm_hadr_database_replica_cluster_states. In der SQL Server-Onlinedokumentation bezieht sich der Begriff "Replikat" jedoch in der Regel auf Verfügbarkeitsreplikate. Zum Beispiel sind mit "primäres Replikat" und "sekundäres Replikat" stets Verfügbarkeitsreplikate gemeint.
Verfügbarkeitsreplikate
Jede Verfügbarkeitsgruppe definiert einen Satz von zwei oder mehr Failoverpartnern, bekannt als Verfügbarkeitsreplikate. Verfügbarkeitsreplikate sind Komponenten der Verfügbarkeitsgruppe. Jedes Verfügbarkeitsreplikat hostet eine Kopie der Verfügbarkeitsdatenbanken in der Verfügbarkeitsgruppe. Für eine bestimmte Verfügbarkeitsgruppe müssen separate Instanzen von SQL Server, die sich auf verschiedenen Knoten eines WSFC-Clusters befinden, die Verfügbarkeitsreplikate hosten. Jede der Serverinstanzen muss für Always On aktiviert sein.
In SQL Server 2019 (15.x) wird die maximale Anzahl der synchronen Replikate von ehemals 3 in SQL Server 2017 (14.x) auf 5 erhöht. Sie können diese Gruppe aus fünf Replikaten für das automatische Failover in der Gruppe konfigurieren. Es gibt ein primäres Replikat sowie vier synchrone sekundäre Replikate.
Eine Instanz kann nur ein Verfügbarkeitsreplikat pro Verfügbarkeitsgruppe hosten. Sie können jedoch jede Instanz für viele Verfügbarkeitsgruppen verwenden. Eine Instanz kann entweder eine eigenständige Instanz oder eine SQL Server-Failoverclusterinstanz (FCI) sein. Falls Sie Redundanz auf Serverebene benötigen, verwenden Sie Failoverclusterinstanzen.
Jedem Verfügbarkeitsreplikat wird eine anfängliche Rolle zugewiesen – entweder die primäre Rolle oder die sekundäre Rolle, die die Verfügbarkeitsdatenbanken dieses Replikats erben. Die Rolle eines bestimmten Replikats legt fest, ob Datenbanken mit Lese-/Schreibzugriff oder schreibgeschützte Datenbanken gehostet werden. Einem als primäres Replikatbezeichneten Replikat wird die primäre Rolle zugewiesen. Es hostet Datenbanken mit Lese-/Schreibzugriff, die als primäre Datenbankenbezeichnet werden. Mindestens einem anderen Replikat, das als sekundäres Replikatbezeichnet wird, wird die sekundäre Rolle zugewiesen. Ein sekundäres Replikat hostet schreibgeschützte Datenbanken, sogenannte sekundäre Datenbanken.
Hinweis
Wenn die Rolle eines Verfügbarkeitsreplikats unbestimmt ist, z. B. während eines Failovers, befinden sich die Datenbanken vorübergehend in einem NOT SYNCHRONIZING Zustand. Ihre Rolle ist auf RESOLVING gesetzt, bis die Rolle des Verfügbarkeitsreplikats aufgelöst wird. Wird ein Verfügbarkeitsreplikat zur primären Rolle aufgelöst, werden seine Datenbanken zu primären Datenbanken. Wird ein Verfügbarkeitsreplikat zur sekundären Rolle aufgelöst, werden seine Datenbanken sekundäre Datenbanken.
Verfügbarkeitsmodi
Jedes Verfügbarkeitsreplikat verfügt über eine Verfügbarkeitsmoduseigenschaft. Der Verfügbarkeitsmodus bestimmt, ob das primäre Replikat wartet, um Transaktionen in einer Datenbank zu bestätigen, bis ein bestimmtes sekundäres Replikat die Transaktionsprotokolldatensätze auf den Datenträger schreibt (das Protokoll härtet). Always On-Verfügbarkeitsgruppen unterstützen zwei Verfügbarkeitsmodi: asynchroner Commit-Modus und synchroner Commit-Modus.
Asynchroner Commit-Modus
Ein Verfügbarkeitsreplikat, das diesen Verfügbarkeitsmodus verwendet, wird als Replikat mit asynchronem Commit bezeichnet. Im Modus für asynchrone Commits führt das primäre Replikat einen Commit für Transaktionen aus, ohne auf die Bestätigung von einem sekundären Replikat mit asynchronem Commit zu warten, um die Transaktionsprotokolle festzuschreiben. Im Modus für asynchrone Commits wird die Transaktionswartezeit auf den sekundären Datenbanken minimiert. Dabei liegen sie jedoch möglicherweise hinter den primären Datenbanken zurück, was Datenverluste zur Folge haben kann.
Synchronous-Commit-Modus
Ein Verfügbarkeitsreplikat, das diesen Verfügbarkeitsmodus verwendet, wird als Replikat mit synchronem Commitbezeichnet. Bevor Transaktionen festgeschrieben werden, wartet ein primäres Replikat im synchronen Commit-Modus darauf, dass ein sekundäres Replikat im synchronen Commit-Modus bestätigt, dass es das Protokoll erfolgreich gehärtet hat. Im Modus für synchrone Commits wird sichergestellt, dass Transaktionen, für die ein Commit ausgeführt wird, vollständig geschützt sind, sobald eine angegebene sekundäre Datenbank mit der primären Datenbank synchronisiert wird. Dieser Schutz führt jedoch zu einer erhöhten Transaktionswartezeit. Optional hat SQL Server 2017 (14.x) ein erforderliches Feature für synchronisierte Secondaries eingeführt, um bei Bedarf die Sicherheit zu erhöhen, allerdings auf Kosten der Latenz. Die
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITFunktion kann aktiviert werden, um eine bestimmte Anzahl synchroner Replikate zum Festschreiben einer Transaktion anzufordern, bevor ein primäres Replikat festschreiben darf.
Weitere Informationen finden Sie unter Unterschiede zwischen Verfügbarkeitsmodi für eine Always On-Verfügbarkeitsgruppe.
Failover-Arten
Im Kontext einer Sitzung zwischen dem primären Replikat und einem sekundären Replikat können die primären und sekundären Rollen in einem Prozess, der als Failover bezeichnet wird, wechseln. Während eines Failovers wechselt das sekundäre Zielreplikat zur primären Rolle und wird zum neuen primären Replikat. Das neue primäre Replikat schaltet seine Datenbanken als primäre Datenbanken online. Clientanwendungen können eine Verbindung mit ihnen herstellen. Wenn das vorherige primäre Replikat verfügbar ist, übernimmt es die Rolle eines Sekundärreplikats und wird zu einem sekundären Replikat. Die zuvor primären Datenbanken werden sekundäre Datenbanken, und die Datensynchronisierung wird fortgesetzt.
Eine Verfügbarkeitsgruppe führt auf der Ebene eines Verfügbarkeitsreplikats ein Failover aus. Failovers treten aufgrund von Datenbankproblemen nicht auf, z. B. aufgrund eines Ausfalls einer Datendatei, des Löschens einer Datenbank oder einer Beschädigung eines Transaktionsprotokolls.
Es gibt drei Arten von Failover: automatisch, manuell und erzwungen (mit möglichen Datenverlusten). Die Art oder Arten des Failovers, die von einem bestimmten sekundären Replikat unterstützt werden, hängen von seinem Verfügbarkeitsmodus ab. Bei synchronen Commit-Modus hängt sie auch vom Failovermodus des primären Replikats und des sekundären Zielreplikats wie folgt ab.
Der Synchron-Commit-Modus unterstützt zwei Arten von Failover: geplantes manuelles Failover und automatisches Failover, wenn das sekundäre Zielreplikat derzeit mit dem primären Replikat synchronisiert wird. Die Einstellung der Failovermoduseigenschaft für die Failoverpartner bestimmt die Unterstützung für diese Failoverformen. Wenn Sie den Failovermodus entweder für das primäre oder sekundäre Replikat manuell festlegen, unterstützt das sekundäre Replikat nur manuelles Failover. Wenn Sie den Failovermodus sowohl für primäre als auch für sekundäre Replikate automatisch festlegen, unterstützt das sekundäre Replikat sowohl das automatische als auch das manuelle Failover.
Geplantes manuelles Failover (ohne Datenverlust)
Ein manuelles Failover erfolgt, nachdem ein Datenbankadministrator einen Failoverbefehl ausgibt. Es führt dazu, dass ein synchronisiertes sekundäres Replikat zur primären Rolle wechselt (mit garantiertem Datenschutz) und das primäre Replikat zur sekundären Rolle übergeht. Ein manuelles Failover erfordert, dass sowohl das primäre Replikat als auch das sekundäre Zielreplikat im synchronen Commit-Modus ausgeführt werden, und das sekundäre Replikat muss bereits synchronisiert werden.
Automatisches Failover (ohne Datenverlust)
Ein automatisches Failover erfolgt als Reaktion auf einen Fehler. Es ermöglicht, dass ein synchronisiertes sekundäres Replikat zur primären Rolle wechselt (mit garantierter Datensicherheit). Wenn das frühere primäre Replikat verfügbar ist, wechselt es in die sekundäre Rolle. Für das automatische Failover muss sowohl das primäre Replikat als auch das sekundäre Zielreplikat im synchronen Commit-Modus ausgeführt werden, wobei der Failovermodus auf "Automatisch" festgelegt ist. Darüber hinaus muss das sekundäre Replikat bereits synchronisiert sein, über ein WSFC-Quorum verfügen und die in der flexiblen Failoverrichtlinie der Verfügbarkeitsgruppe angegebenen Bedingungen erfüllen.
Im Modus für asynchrone Commits ist die einzige Form des Failovers ein erzwungenes manuelles Failover (mit möglichem Datenverlust), das in der Regel als erzwungenes Failoverbezeichnet wird. Erzwungenes Failover ist eine Form des manuellen Failovers, da Sie es manuell initiieren müssen. Erzwungenes Failover ist eine Option zur Notfallwiederherstellung. Dies ist die einzige Form des Failovers, die möglich ist, wenn das sekundäre Zielreplikat nicht mit dem primären Replikat synchronisiert wird.
Weitere Informationen finden Sie unter Failover und Failovermodi (Always On-Verfügbarkeitsgruppen).
Wichtig
- SQL Server-Failoverclusterinstanzen (FCIs) unterstützen kein automatisches Failover durch Verfügbarkeitsgruppen, sodass Sie nur manuelles Failover für jedes Verfügbarkeitsreplikat konfigurieren können, das ein FCI hostet.
- Wenn Sie einen Befehl für ein erzwungenes Failover für ein synchronisiertes sekundäres Replikat ausgeben, verhält sich das sekundäre Replikat genauso wie bei einem geplanten manuellen Failover.
Vorteile
Always On-Verfügbarkeitsgruppen stellen ein breites Spektrum von Optionen bereit, durch die die Datenbankverfügbarkeit verbessert und eine optimale Ressourcenverwendung ermöglicht werden. Die wichtigsten Komponenten sind:
Unterstützt bis zu neun Verfügbarkeitsreplikate. Ein Verfügbarkeitsreplikat ist eine Instanz einer Verfügbarkeitsgruppe, die von einer bestimmten Instanz von SQL Server gehostet wird. Sie verwaltet eine lokale Kopie jeder Verfügbarkeitsdatenbank, die zur Verfügbarkeitsgruppe gehört. Jede Verfügbarkeitsgruppe unterstützt ein primäres Replikat und bis zu acht sekundäre Replikate. Weitere Informationen finden Sie unter Was ist eine Always On-Verfügbarkeitsgruppe?
Wichtig
Jedes Verfügbarkeitsreplikat muss sich in einem anderen Knoten eines einzelnen WSFC-Clusters (Windows Server-Failoverclustering) befinden. Weitere Informationen zu Voraussetzungen, Einschränkungen und Empfehlungen für Verfügbarkeitsgruppen finden Sie unter Voraussetzungen, Einschränkungen und Empfehlungen für Always On-Verfügbarkeitsgruppen.
Unterstützt die folgenden alternativen Verfügbarkeitsmodi:
Asynchroner Commit-Modus. Dieser Verfügbarkeitsmodus ist eine Lösung für die Notfallwiederherstellung, die gut funktioniert, wenn die Verfügbarkeitsreplikate über große Entfernungen verteilt sind.
Synchronous-Commit-Modus. Bei diesem Verfügbarkeitsmodus haben Hochverfügbarkeit und Datenschutz Vorrang vor Leistung, und dies hat eine höhere Transaktionslatenz zur Folge. Eine bestimmte Verfügbarkeitsgruppe kann bis zu fünf Verfügbarkeitsreplikate mit synchronem Commit (einschließlich des aktuellen primären Replikats) unterstützen.
Weitere Informationen finden Sie unter Unterschiede zwischen Verfügbarkeitsmodi für eine Always On-Verfügbarkeitsgruppe.
Unterstützt mehrere Arten von Verfügbarkeitsgruppenfailover: automatisches Failover, geplantes manuelles Failover (allgemein als manuelles Failover bezeichnet) und erzwungenes manuelles Failover (allgemein als erzwungenes Failover bezeichnet). Weitere Informationen finden Sie unter Failover und Failovermodi (Always On-Verfügbarkeitsgruppen).
Ermöglicht es Ihnen, ein angegebenes Verfügbarkeitsreplikat so zu konfigurieren, dass es entweder eines oder beide der folgenden Funktionen für aktive sekundäre Replikate unterstützt:
Lesezugriff, der es schreibgeschützten Verbindungen erlaubt, auf das Replikat zuzugreifen und dessen Datenbanken zu lesen, wenn es als sekundäres Replikat ausgeführt wird. Weitere Informationen finden Sie unter Auslagern von schreibgeschützten Workloads auf ein sekundäres Replikat einer Always On-Verfügbarkeitsgruppe.
Das Ausführen von Sicherungsvorgängen für seine Datenbanken, wenn es als sekundäres Replikat ausgeführt wird. Weitere Informationen finden Sie unter Auslagern unterstützter Backups auf sekundäre Replikate einer Verfügbarkeitsgruppe.
Durch die Verwendung aktiver sekundärer Replikate lassen sich durch die bessere Ressourcennutzung sekundärer Hardware die IT-Effizienz erhöhen und die Kosten reduzieren. Außerdem trägt das Auslagern reiner Lesevorgänge und Sicherungsaufträge auf sekundäre Replikate dazu bei, die Leistung auf dem primären Replikat zu verbessern.
Unterstützt einen Verfügbarkeitsgruppenlistener für jede Verfügbarkeitsgruppe. Ein Verfügbarkeitsgruppen-Listener ist ein Servername, mit dem sich Clients verbinden können, um auf eine Datenbank in einer primären oder sekundären Replik einer Always On-Verfügbarkeitsgruppe zuzugreifen. Verfügbarkeitsgruppenlistener leiten eingehende Verbindungen an das primäre Replikat oder ein schreibgeschütztes sekundäres Replikat weiter. Der Listener ermöglicht ein schnelles Anwendungsfailover, nachdem für eine Verfügbarkeitsgruppe ein Failover ausgeführt wurde. Weitere Informationen finden Sie unter Connect to an Always On availability group listener.
Unterstützt eine flexible Failoverrichtlinie, um größere Kontrolle über das Failover von Verfügbarkeitsgruppen zu erlangen. Weitere Informationen finden Sie unter Failover und Failovermodi (Always On-Verfügbarkeitsgruppen).
Unterstützt die automatische Seitenreparatur als Schutz vor Seitenbeschädigungen. Weitere Informationen finden Sie unter Automatische Seitenreparatur (Verfügbarkeitsgruppen: Datenbankspiegelung).
Unterstützt Verschlüsselung und Komprimierung, die einen sicheren, leistungsstarken Transport ermöglichen.
Stellt einen integrierten Satz von Tools bereit, um die Bereitstellung und Verwaltung von Verfügbarkeitsgruppen zu erleichtern. Dazu gehören:
Transact-SQL-DDL-Anweisungen zum Erstellen und Verwalten von Verfügbarkeitsgruppen. Weitere Informationen finden Sie unter Transact-SQL-Anweisungen für Always On-Verfügbarkeitsgruppen.
SQL Server Management Studio -Tools:
Mit dem Assistenten zum Erstellen neuer Verfügbarkeitsgruppen wird eine Verfügbarkeitsgruppe erstellt und konfiguriert. In einigen Umgebungen kann dieser Assistent auch die sekundären Datenbanken automatisch vorbereiten und die Datensynchronisierung für jede von ihnen starten. Weitere Informationen finden Sie unter Verwenden des Dialogfelds „Neue Verfügbarkeitsgruppe“ (SQL Server Management Studio).
Der Assistent zum Hinzufügen von Datenbanken zu Verfügbarkeitsgruppen fügt einer vorhandenen Verfügbarkeitsgruppe eine oder mehrere primäre Datenbanken hinzu. In einigen Umgebungen kann dieser Assistent auch die sekundären Datenbanken automatisch vorbereiten und die Datensynchronisierung für jede von ihnen starten. Weitere Informationen finden Sie unter Hinzufügen einer Datenbank zu einer AlwaysOn-Verfügbarkeitsgruppe mit dem Verfügbarkeitsgruppen-Assistenten.
Der Assistent zum Hinzufügen von Replikaten zu Verfügbarkeitsgruppen fügt einer vorhandenen Verfügbarkeitsgruppe ein oder mehrere sekundäre Replikate hinzu. In einigen Umgebungen kann dieser Assistent auch die sekundären Datenbanken automatisch vorbereiten und die Datensynchronisierung für jede von ihnen starten. Weitere Informationen finden Sie unter Hinzufügen eines Replikats zu Ihrer AlwaysOn-Verfügbarkeitsgruppe mithilfe des Verfügbarkeitsgruppen-Assistenten in SQL Server Management Studio.
Der Assistent für das Failover von Verfügbarkeitsgruppen initiiert ein manuelles Failover für eine Verfügbarkeitsgruppe. Abhängig von der Konfiguration und dem Zustand des sekundären Replikats, das Sie als Failoverziel angeben, kann der Assistent entweder ein geplantes oder ein erzwungenes manuelles Failover ausführen. Weitere Informationen finden Sie unter Verwenden des Assistenten für Failover-Verfügbarkeitsgruppen (SQL Server Management Studio).
Das Das Always On-Dashboard überwacht Always On-Verfügbarkeitsgruppen, -Verfügbarkeitsreplikate und -Verfügbarkeitsdatenbanken und wertet Ergebnisse für Always On-Richtlinien aus. Weitere Informationen finden Sie unter Verwenden Sie das Always On-Verfügbarkeitsgruppen-Dashboard (SQL Server Management Studio).
Der Detailbereich im Objekt-Explorer zeigt grundlegende Informationen zu vorhandenen Verfügbarkeitsgruppen an. Weitere Informationen finden Sie unter Verwenden der Object Explorer Details zur Überwachung von Verfügbarkeitsgruppen.
PowerShell-Cmdlets. Weitere Informationen finden Sie unter Übersicht über PowerShell-Cmdlets für Always On-Verfügbarkeitsgruppen.
Clientverbindungen
Sie können Clientkonnektivität für das primäre Replikat einer angegebenen Verfügbarkeitsgruppe bereitstellen, indem Sie einen Verfügbarkeitsgruppenlistener erstellen. Ein Verfügbarkeitsgruppenlistener stellt einen Satz von Ressourcen bereit, der an eine bestimmte Verfügbarkeitsgruppe angefügt wird, um Clientverbindungen an das entsprechende Verfügbarkeitsreplikat umzuleiten.
Ein Verfügbarkeitsgruppenlistener ist einem eindeutigen DNS-Namen, der als virtueller Netzwerkname (VNN) dient, mindestens einer virtuellen IP-Adresse (VIPs) und einer TCP-Portnummer zugeordnet. Weitere Informationen finden Sie unter Connect to an Always On availability group listener.
Wenn eine Verfügbarkeitsgruppe nur über zwei Verfügbarkeitsreplikate verfügt und nicht für den Lesezugriff auf das sekundäre Replikat konfiguriert ist, können Clients mithilfe einer Verbindungszeichenfolge für die Datenbankspiegelung eine Verbindung mit dem primären Replikat herstellen. Dieser Ansatz kann nach dem Migrieren einer Datenbank von der Datenbankspiegelung zu Always On-Verfügbarkeitsgruppen nützlich sein. Bevor Sie sekundäre Replikate hinzufügen, müssen Sie einen Verfügbarkeitsgruppenlistener für die Verfügbarkeitsgruppe erstellen und Ihre Anwendungen so aktualisieren, dass der Netzwerkname des Listeners verwendet wird.
TDS 8-Unterstützung in SQL Server 2025
SQL Server 2025 (17.x) führt die TDS 8.0-Unterstützung ein, die das Erzwingen der strengen TLS 1.3-Verschlüsselung für Verbindungen zu Ihren AlwaysOn-Verfügbarkeitsgruppenreplikaten und Listener ermöglicht.
Konfigurationsanforderungen:
-
Neue Verfügbarkeitsgruppen: Erstellen Sie die AG mit
Encrypt=Strictin derCLUSTER_CONNECTION_OPTIONSKlausel und führen Sie ein Failover durch, um die Einstellungen anzuwenden. -
Vorhandene Verfügbarkeitsgruppen: Ändern Sie die AG mit der
CLUSTER_CONNECTION_OPTIONS-Klausel, umEncrypt=Strictfestzulegen und die Einstellungen durch ein Failover anzuwenden. - Strenge Verschlüsselung erzwingen: Legen Sie diese Option in SQL Server Configuration Manager für jedes Replikat auf "Ja " fest, und starten Sie SQL Server-Replikate neu.
-
Zertifikatanforderungen: Wird
Encrypt=Strictfestgelegt,TrustServerCertificatewird ignoriert.
Überprüfen Sie zunächst die Verbindung mit strenger Verschlüsselung.
Aktive sekundäre Replikate
Always On-Verfügbarkeitsgruppen unterstützen aktive sekundäre Replikate. Die Funktionen für aktive sekundäre Replikate umfassen auch die Unterstützung für Folgendes:
Durchführen von Sicherungsoperationen auf sekundären Replikaten
Die sekundären Replikate unterstützen das Ausführen von Protokollsicherungen und Kopiesicherungen einer vollständigen Datenbank, Datei oder Dateigruppe. Sie können die Verfügbarkeitsgruppe konfigurieren, um eine Einstellung dafür anzugeben, wo Sicherungen ausgeführt werden sollen. Es ist wichtig zu verstehen, dass SQL Server die Einstellung nicht erzwingt, sodass sie keine Auswirkungen auf Ad-hoc-Sicherungen hat. Die Interpretation dieser Präferenz hängt von der Logik ab, die Sie, falls vorhanden, in Ihre Sicherungsaufträge für jede der Datenbanken in einer bestimmten Verfügbarkeitsgruppe einfügen. Für einzelne Verfügbarkeitsreplikate können Sie die Priorität für die Ausführung von Sicherungen auf diesem Replikat in Relation zu den anderen Replikaten in derselben Verfügbarkeitsgruppe angeben. Weitere Informationen finden Sie unter Auslagern unterstützter Backups auf sekundäre Replikate einer Verfügbarkeitsgruppe.
Schreibgeschützter Zugriff auf eine oder mehrere sekundäre Replikate (lesbare sekundäre Replikate)
Sie können jedes sekundäre Verfügbarkeitsreplikat so konfigurieren, dass nur schreibgeschützter Zugriff auf seine lokalen Datenbanken zulässig ist, obwohl einige Vorgänge nicht vollständig unterstützt werden. Diese Konfiguration verhindert Lese-/Schreibzugriffsversuche mit dem sekundären Replikat. Es ist auch möglich, schreibgeschützte Workloads auf dem primären Replikat zu verhindern, indem nur Lese-/Schreibzugriff zugelassen wird. Die Konfiguration verhindert, dass mit dem primären Replikat schreibgeschützte Verbindungen hergestellt werden. Weitere Informationen finden Sie unter Auslagern von schreibgeschützten Workloads auf ein sekundäres Replikat einer Always On-Verfügbarkeitsgruppe.
Wenn eine Verfügbarkeitsgruppe derzeit über einen Verfügbarkeitsgruppenlistener und ein oder mehrere lesbare sekundäre Replikate verfügt, kann SQL Server Leseabsichtsverbindungsanforderungen an eine von ihnen weiterleiten (schreibgeschütztes Routing). Weitere Informationen finden Sie unter Connect to an Always On availability group listener.
Sitzungstimeout
Der Sitzungs-Timeout ist eine Eigenschaft von Verfügbarkeitsreplikaten, die bestimmt, wie lange eine Verknüpfung mit einem anderen Verfügbarkeitsreplikat inaktiv bleiben kann, bevor die Verknüpfung geschlossen wird. Die primären und sekundären Replikate signalisieren einander mithilfe von Pingbefehlen, dass sie noch aktiv sind. Durch den Empfang eines Pings von einem anderen Replikat innerhalb des Timeoutzeitraums wird angegeben, dass die Verbindung weiterhin geöffnet ist und dass die Serverinstanzen miteinander kommunizieren. Beim Empfang eines Pings setzt ein Verfügbarkeitsreplikat seinen Sitzungstimeoutzähler für diese Verbindung zurück.
Das Sitzungstimeout verhindert, dass Replikate unbegrenzt auf ein Ping vom anderen Replikat warten. Wenn kein Ping aus dem anderen Replikat innerhalb des Sitzungstimeoutzeitraums empfangen wird, ist das Replikat timeout. Die Verbindung wird geschlossen, und das Timeout-Replikat wechselt in den DISCONNECTED Zustand. Selbst wenn ein getrenntes Replikat für den Modus „synchrones Commit“ konfiguriert ist, warten Transaktionen nicht darauf, dass dieses Replikat sich wieder verbindet und resynchronisiert.
Das Standardsitzungstimeout für alle Verfügbarkeitsreplikate liegt bei 10 Sekunden. Sie können diesen Wert konfigurieren, wobei ein Minimum von 5 Sekunden eingehalten wird. Behalten Sie im Allgemeinen den Timeoutzeitraum bei 10 Sekunden oder höher bei. Wenn Sie diesen Wert auf weniger als 10 Sekunden festlegen, kann ein stark ausgelastetes System einen falschen Fehler melden.
Hinweis
In der Rolle RESOLVING ist das Sitzungstimeout nicht gültig, da keine Pings ausgeführt werden.
Automatische Seitenreparatur
Jedes Verfügbarkeitsreplikat versucht, durch das Auflösen bestimmter Fehlertypen, die das Lesen einer Datenseite verhindern, beschädigte Seiten auf einer lokalen Datenbank automatisch wiederherzustellen. Wenn von einem sekundären Replikat eine Seite nicht gelesen werden kann, wird vom Replikat eine neue Kopie der Seite vom primären Replikat angefordert. Wenn das primäre Replikat eine Seite nicht lesen kann, überträgt das Replikat eine Anforderung für eine neue Kopie an alle sekundären Replikate und ruft die Seite von dem Replikat ab, das zuerst antwortet. Ist diese Anforderung erfolgreich, wird die nicht lesbare Seite durch die Kopie ersetzt. Dadurch kann der Fehler normalerweise behoben werden.
Weitere Informationen finden Sie unter Automatische Seitenreparatur (Verfügbarkeitsgruppen: Datenbankspiegelung).
Interoperabilität und Koexistenz mit anderen Datenbank-Engine-Features
AlwaysOn-Verfügbarkeitsgruppen funktionieren mit den folgenden Features oder Komponenten von SQL Server:
- Was ist Change Data Capture (CDC)?
- Über die Änderungsverfolgung (SQL Server)
- Enthaltene Datenbanken
- Transparente Datenverschlüsselung (TDE)
- Datenbankmomentaufnahmen mit AlwaysOn-Verfügbarkeitsgruppen (SQL Server)
- FILESTREAM (SQL Server)
- FileTables (SQL Server)
- Über das Protokollversand (SQL Server)
- Remote Blob Store (RBS) (SQL Server)
- SQL Server-Replikation
- Service Broker
- SQL Server-Agent
- Berichterstellungsdienste mit Always On-Verfügbarkeitsgruppen (SQL Server)
- Ressourcenkontrolle
- TDS 8.0 ab SQL Server 2025 (17.x)
Verwandte Tasks
- Voraussetzungen, Einschränkungen und Empfehlungen für Always On-Verfügbarkeitsgruppen
- Referenz für die Erstellung und Konfiguration von Always On-Verfügbarkeitsgruppen
- Verwaltung einer Verfügbarkeitsgruppe
- Tools zur Überwachung von Always On-Verfügbarkeitsgruppen
- Auslagern der schreibgeschützten Arbeitslast auf die sekundäre Replik einer Always On-Verfügbarkeitsgruppe
- Unterstützte Sicherungen auf sekundäre Replikate einer Verfügbarkeitsgruppe auslagern
- Mit einem Always On-Verfügbarkeitsgruppen-Listener verbinden
- Transact-SQL-Anweisungen für Always On-Verfügbarkeitsgruppen
- Übersicht über PowerShell-Cmdlets für Always On-Verfügbarkeitsgruppen
- SQL Server-Blog – Hohe Verfügbarkeit
- SQL Server-Blog
- Archiv: SQL Server Always On Team Blogs: Der offizielle SQL Server Always On Team Blog
- Archiv: CSS SQL Server Engineers Blogs
- Microsoft SQL Server Always On-Lösungen Leitfaden für Hochverfügbarkeit und Notfallwiederherstellung