Upgrade von Replikaten von Verfügbarkeitsgruppen
Gilt für: ![]() SQL Server
SQL Server
Wenn eine SQL Server-Instanz, die eine Always On-Verfügbarkeitsgruppe (AG) hostet, auf eine neue SQL Server-Version, ein neues SQL Server-Service Pack oder ein kumulatives Update upgegradet wird, oder wenn Sie ein neues Windows Service Pack oder ein kumulatives Update installieren, können Sie die Downtime des primären Replikats auf ein einziges manuelles Failover reduzieren, indem Sie ein paralleles Upgrade (oder zwei manuelle Failovers, falls Sie ein Failback auf das ursprüngliche primäre Replikat durchführen) durchführen.
Während des Upgradevorgangs steht ein sekundäres Replikat weder für ein Failover noch für schreibgeschützte Vorgänge zur Verfügung. Nach dem Upgrade kann es etwas dauern, bis das sekundäre Replikat auf dem gleichen Stand wie der primäre Replikatknoten ist. Dies ist vom Ausmaß der Aktivität auf dem primären Replikatknoten abhängig und kann zu einer hohen Netzwerkauslastung führen.
Beachten Sie außerdem, dass die Datenbanken in dieser Verfügbarkeitsgruppe nach dem ersten Failover auf ein sekundäres Replikat, auf dem eine neuere Version von SQL Server ausgeführt wird, einen Upgradeprozess durchlaufen, um sie auf die neueste Version zu aktualisieren. Währenddessen gibt es keine Lesereplikate für diese Datenbanken. Die Downtime nach dem ersten Failover hängt von der Anzahl von Datenbanken in der Verfügbarkeitsgruppe ab. Wenn Sie ein Failback auf das ursprüngliche Replikat durchführen möchten, wird dieser Schritt beim Failback nicht wiederholt.
Hinweis
In diesem Artikel wird nur das Upgraden von SQL Server behandelt. Das Upgraden des Betriebssystems, das den WSFC-Cluster (Windows Server Failover Clustering) beinhaltet, wird nicht behandelt. Das Upgraden des Windows-Betriebssystems, das den Failovercluster hostet, wird für ältere Betriebssysteme als Windows Server 2012 R2 nicht unterstützt. Weitere Informationen über das Upgraden eines Clusterknotens, der auf Windows Server 2012 R2 ausgeführt wird, finden Sie unter Cluster Operating System Rolling Upgrade(Paralleles Upgraden für Clusterbetriebssysteme).
Voraussetzungen
Lesen Sie die folgenden wichtigen Informationen, bevor Sie beginnen:
Unterstützte Versions- und Editionsupgrades: Überprüfen Sie, ob Sie von Ihrer Version des Windows-Betriebssystems und Ihrer Version von SQL Server auf die aktuelle Version von SQL Server upgraden können. Wenn Sie beispielsweise ein direktes Upgrade von einer SQL Server 2005-Instanz durchführen, wird der Datenbank-Kompatibilitätsgrad aktualisiert.
Auswählen einer Methode zum Upgraden der Datenbank-Engine: Wählen Sie die passende Upgrademethode und die passenden Schritte aus, die auf Ihrer Überprüfung der unterstützten Versions- und Editionsupgrades sowie auf den anderen Komponenten basieren, die in Ihrer Umgebung installiert sind, um das Upgrade in der richtigen Reihenfolge durchzuführen.
Planen und Testen des Upgradeplans für die Datenbank-Engine: Überprüfen Sie die Anmerkungen zu dieser Version, die bekannten Upgradeprobleme und die Prüfliste vor dem Upgrade. Entwickeln und testen Sie dann den Upgradeplan.
Hardware- und Softwareanforderungen für die Installation von SQL Server: Überprüfen Sie die Softwareanforderungen für die Installation von SQL Server. Falls zusätzliche Software erforderlich ist, installieren Sie diese auf jedem Knoten, bevor Sie mit dem Upgradevorgang beginnen, um die Downtime zu minimieren.
Überprüfen, ob Change Data Capture oder die Replikation für Datenbanken in Verfügbarkeitsgruppen verwendet wird: Wenn Datenbanken in der Verfügbarkeitsgruppe für Change Data Capture (CDC) aktiviert sind, folgen Sie diesen Anweisungen.
Hinweis
Das Mischen verschiedener SQL Server-Instanzen innerhalb einer Verfügbarkeitsgruppe wird außerhalb von parallelen Upgrades nicht unterstützt und sollten in diesem Zustand nicht länger bestehen, da das Upgrade schnell ausgeführt werden sollte. Alternativ können Sie auch eine verteilte Verfügbarkeitsgruppe verwenden, um SQL Server 2016 (13.x) und höhere Versionen upzugraden.
Hinweis
Die Verwendung des Windows-Features für clusterfähige Aktualisierung (Cluster Aware Updating, CAU) zum Aktualisieren von AlwaysOn-Verfügbarkeitsgruppen wird nicht unterstützt.
Grundlagen zu parallelen Upgrades für Verfügbarkeitsgruppen
Beachten Sie folgende Richtlinien, wenn Sie Serverupgrades oder -updates durchführen, um die Downtime und den Datenverlust Ihrer Verfügbarkeitsgruppen zu minimieren:
Bevor Sie das parallele Upgrade starten:
Führen Sie zu Übungszwecken ein manuelles Failover für mindestens eine der Replikatinstanzen mit synchronem Commit aus.
Schützen Sie Ihre Daten, indem Sie eine vollständige Datenbanksicherung für jede Verfügbarkeitsdatenbank ausführen.
Führen Sie
DBCC CHECKDBfür jede Verfügbarkeitsdatenbank aus.
Führen Sie das Upgrade zuerst immer für die sekundären Remotereplikatinstanzen und dann für die lokalen sekundären Replikatinstanzen und zuletzt für die primäre Replikatinstanz durch.
Von einer Datenbank, für die gerade ein Upgrade ausgeführt wird, kann keine Sicherung erstellt werden. Vor dem Aktualisieren der sekundären Replikate konfigurieren Sie die Voreinstellung für die automatisierte Sicherung, um Sicherungen nur auf dem primären Replikat auszuführen. Während eines Versionsupgrades sind Replikate nicht lesbar oder für Sicherungen verfügbar. Während eines Upgrades ohne Versionswechsel können Sie automatische Sicherungen konfigurieren, die auf den sekundären Replikaten ausgeführt werden, bevor das primäre Replikat upgegradet wird.
Während eines Versionsupgrades können lesbare sekundäre Replikate zwischenzeitlich nicht gelesen werden. Dieser Zeitraum der Nicht-Lesbarkeit beginnt, nachdem das Upgrade auf das sekundäre Replikat durchgeführt wurde, und hält an, bis für das primäre Replikat ein Failover auf ein upgegradetes sekundäres Replikat durchgeführt wurde oder das primäre Replikat selbst upgegradet wurde.
Damit für die Verfügbarkeitsgruppe während des Upgrades kein unbeabsichtigtes Failover ausgeführt wird, entfernen Sie das Verfügbarkeitsfailover zunächst von allen Replikaten mit synchronem Commit.
Führen Sie für die primäre Replikatinstanz kein Upgrade aus, bevor Sie für die Verfügbarkeitsgruppe ein Failover auf eine upgegradete Instanz mit einem sekundären Replikat ausgeführt haben. Andernfalls kann sich die Downtime von Clientanwendungen während des Upgrades auf der primären Replikatinstanz verlängern.
Führen Sie für die Verfügbarkeitsgruppe immer ein Failover auf eine sekundäre Replikatinstanz mit synchronem Commit aus. Falls Sie ein Failover auf eine sekundäre Replikatinstanz mit asynchronem Commit ausführen, werden die Datenbanken anfällig für Datenverluste, und die Datenverschiebung wird automatisch so lange angehalten, bis Sie den Vorgang manuell fortsetzen.
Führen Sie für die primäre Replikatinstanz kein Upgrade durch, bevor Sie nicht eine der anderen sekundären Replikatinstanzen upgegradet oder aktualisiert haben. Ein primäres Replikat, für das ein Upgrade ausgeführt wurde, kann keine Protokolle mehr an sekundäre Replikate versenden, deren SQL Server-Instanz noch nicht auf die gleiche Version aktualisiert wurde. Wenn eine Datenverschiebung zu einem sekundären Replikat angehalten wurde, kann für dieses Replikat kein automatisches Failover ausgeführt werden, und die Verfügbarkeitsdatenbanken sind anfällig für Datenverluste. Dies gilt auch für ein paralleles Upgrade, bei dem ein manuelles Failover von einem früheren zu einem neuen primären Replikat durchgeführt wird. Daher müssen Sie nach dem Upgrade des früheren primären Replikats möglicherweise die Synchronisierung fortsetzen.
Bevor Sie ein Failover für eine Verfügbarkeitsgruppe ausführen, sollten Sie überprüfen, ob der Synchronisierungsstatus des Failoverziels
SYNCHRONIZEDlautet.Warnung
Die Installation einer neuen Instanz oder neuen Version von SQL Server auf einem Server mit einer älteren SQL Server-Version kann unbeabsichtigt zu einem Ausfall aller Verfügbarkeitsgruppen, die von der älteren SQL Server-Version gehostet werden, führen. Dies liegt daran, dass während der Installation der Instanz oder Version von SQL Server das Hochverfügbarkeitsmodul von SQL Server (RHS.EXE) aktualisiert wird. Dadurch werden Ihre vorhandenen Verfügbarkeitsgruppen in der primären Rolle auf dem Server vorübergehend unterbrochen. Es wird daher dringend empfohlen, dass Sie einen der folgenden Schritte ausführen, wenn Sie eine neuere SQL Server-Version in einem System installieren möchten, das bereits eine ältere Version von SQL Server mit einer Verfügbarkeitsgruppe hostet:
Installieren der neuen Version von SQL Server während eines Wartungsfensters.
Durchführen eines Failovers der Verfügbarkeitsgruppe auf ein sekundäres Replikat, damit sie während der Installation der neuen SQL Server-Instanz nicht in der primären Rolle ist.
Prozess des parallelen Upgrades
Die genauen Schritte hängen von Faktoren wie der Bereitstellungstopologie Ihrer Verfügbarkeitsgruppen und dem Commitmodus der einzelnen Replikate ab. Im einfachsten Szenario ist ein paralleles Upgrade jedoch ein mehrstufiger Prozess, der in seiner einfachsten Form aus den folgenden Schritten besteht:
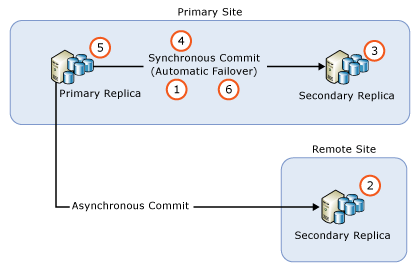
- Deaktivieren des automatischen Failovers für alle Replikate mit synchronem Commit
- Durchführen von Upgrades für alle Instanzen von sekundären Replikaten mit asynchronem Commit
- Durchführen von Upgrades für alle Remoteinstanzen von sekundären Replikaten mit synchronem Commits
- Durchführen von Upgrades für alle lokalen Instanzen von sekundären Replikaten mit synchronem Commits
- Ausführen eines manuellen Failovers der Verfügbarkeitsgruppe auf ein (neu aktualisiertes) lokales sekundäres Replikat mit synchronem Commit
- Durchführen eines Upgrades oder Updates der lokalen Replikatinstanz, in der zuvor das primäre Replikat gehostet wurde
- Konfigurieren automatischer Failoverpartner nach Bedarf
Bei Bedarf können Sie ein zusätzliches manuelles Failover ausführen, um die ursprüngliche Konfiguration der Verfügbarkeitsgruppe wiederherzustellen.
Hinweis
Wenn Sie ein Upgrade für ein Replikat mit synchronem Commit durchführen und es offline schalten, werden die Transaktionen des primären Replikats nicht verzögert. Sobald die Verbindung des sekundären Replikats getrennt wurde, werden die Transaktionen des primären Replikats committet, ohne dass darauf gewartet wird, dass die Protokolle des sekundären Replikats festgeschrieben werden.
Wenn REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT auf 1 oder 2 festgelegt ist, ist das primäre Replikat möglicherweise nicht für Lese-/Schreibvorgänge verfügbar, wenn eine entsprechende Anzahl von sekundären Synchronisierungsreplikaten während des Updatevorgangs nicht verfügbar ist.
Hinweis
Wenn Sie ein direktes Upgrade einer sekundären Replik auf eine neuere Version von SQL Server durchführen, verbleibt die Datenbank innerhalb der Verfügbarkeitsgruppe im Status Synchronisieren/In Wiederherstellung oder Synchronisiert/In Wiederherstellung, bis für die Verfügbarkeitsgruppe manuell ein Failover ausgeführt wird, wodurch die Wiederherstellung abgeschlossen ist und die Datenbank aktualisiert wird. Eine aktualisierte primäre Replik kann keine Protokolle mehr an eine sekundäre Replik mit einer niedrigeren Version übermitteln. Die Datenverschiebung wird gestoppt und es kann kein automatisches Failover für diese Replik stattfinden, so dass Ihre Verfügbarkeitsdatenbanken anfällig für Datenverluste sind. Nachdem Sie die alte Primärdatei aktualisiert haben, müssen Sie möglicherweise die Synchronisierung wieder aufnehmen. Es wird empfohlen, alle sekundären Replikate zu aktualisieren, bevor Sie auf ein Replikat mit der neuen Version umsteigen. Auf diese Weise haben Sie die Möglichkeit, ein Failover durchzuführen, nachdem die Datenbank(en) auf das neue Format aktualisiert wurden.
Verfügbarkeitsgruppe mit einem sekundären Remotereplikat
Wenn Sie eine Verfügbarkeitsgruppe ausschließlich zur Notfallwiederherstellung bereitgestellt haben, müssen Sie für die Verfügbarkeitsgruppe möglicherweise ein Failover auf ein sekundäres Replikat mit asynchronem Commit ausführen. Diese Konfiguration wird in der folgenden Abbildung dargestellt:
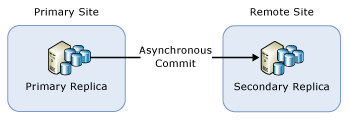
In diesem Fall müssen Sie für die Verfügbarkeitsgruppe während des parallelen Upgrades ein Failover auf das sekundäre Replikat mit asynchronem Commit ausführen. Ändern Sie den Commitmodus zur Vermeidung von Datenverlusten in den synchronen Commitmodus, und warten Sie mit dem Failover der Verfügbarkeitsgruppe, bis das sekundäre Replikat synchronisiert ist. Der Prozess zum Durchführen eines parallelen Upgrades kann somit folgendermaßen aussehen:
- Upgraden der sekundären Replikatinstanz am Remotestandort
- Ändern des Commitmodus in den synchronen Commitmodus
- Warten, bis der Synchronisierungsstatus
SYNCHRONIZEDlautet - Ausführen eines Failovers der Verfügbarkeitsgruppe an ein sekundäres Replikat am Remotestandort
- Upgraden oder Aktualisieren der lokalen (am primären Standort) Replikatinstanz
- Ausführen eines Failovers der Verfügbarkeitsgruppe zurück auf den primären Standort
- Ändern des Commitmodus in den asynchronen Commitmodus
Der synchrone Commitmodus ist für die Datensynchronisierung mit einem Remotestandort nicht zu empfehlen. Nachdem die Einstellung geändert wurde, verzeichnen die Clientanwendungen möglicherweise einen sofortigen Anstieg der Datenbanklatenz. Darüber hinaus führt ein Failover dazu, dass alle unbestätigten Protokollmeldungen verworfen werden. Die Anzahl der verworfenen Protokollmeldungen kann aufgrund hoher Netzwerklatenz zwischen den beiden Standorten deutlich erhöht sein, was auf den Clients zu einer hohen Rate von Transaktionsfehlern führt. Sie können die Auswirkungen auf die Clientanwendungen mithilfe der folgenden Maßnahmen minimieren:
Festlegen des Wartungsfensters auf Zeiten mit geringem Clientdatenverkehr
Ändern Sie den Verfügbarkeitsmodus während des Upgradens oder Aktualisierens von SQL Server am primären Standort zurück in den asynchronen Commitmodus, und kehren Sie zu synchronen Commits zurück, wenn Sie wieder bereit für ein Failover auf den primären Standort sind.
Verfügbarkeitsgruppe mit Failoverclusterinstanz-Knoten
Falls eine Verfügbarkeitsgruppe Failoverclusterinstanz-Knoten (Failover Cluster Instance, FCI) enthält, sollten Sie die inaktiven Knoten vor den aktiven Knoten upgraden. In der folgenden Abbildung ist ein gängiges Szenario für Verfügbarkeitsgruppen mit FCIs dargestellt. Es basiert auf FCIs, die auf lokale Hochverfügbarkeit und asynchrone Commits zur Remotenotfallwiederherstellung ausgelegt sind, und veranschaulicht die Schritte zum Ausführen des Upgrades.
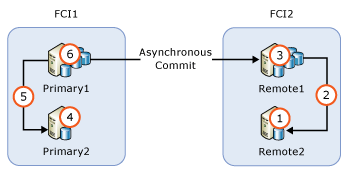
- Upgraden oder Aktualisieren von
REMOTE2 - Failover von FCI2 auf
REMOTE2 - Upgraden oder Aktualisieren von
REMOTE1 - Upgraden oder Aktualisieren von
PRIMARY2 - Failover von FCI1 auf
PRIMARY2 - Upgraden oder Aktualisieren von
PRIMARY1
Upgraden oder Aktualisieren von SQL Server-Instanzen mit mehreren Verfügbarkeitsgruppen
Falls Sie mehrere Verfügbarkeitsgruppen mit primären Replikaten auf verschiedenen Serverknoten ausführen (eine Aktiv/Aktiv-Konfiguration), umfasst der Upgradepfad zusätzliche Failoverschritte, um die Hochverfügbarkeit während des Vorgangs sicherzustellen. Es wird angenommen, dass Sie wie in der folgenden Tabelle dargestellt drei Verfügbarkeitsgruppen auf drei Serverknoten ausführen, bei denen sich alle Replikate im synchronen Commitmodus befinden:
| Verfügbarkeitsgruppe | Knoten1 | Knoten2 | Knoten3 |
|---|---|---|---|
| VG1 | Primär | ||
| VG2 | Primär | ||
| VG3 | Primär |
In diesem Fall kann es von Vorteil sein, ein paralleles Upgrade mit Lastenausgleich in der folgenden Reihenfolge durchzuführen:
- Failover von VG2 auf
Node3(umNode2freizugeben) - Upgraden oder Aktualisieren von
Node2 - Failover von VG1 auf
Node2(umNode1freizugeben) - Upgraden oder Aktualisieren von
Node1 - Failover sowohl von VG2 als auch von VG3 auf
Node1(umNode3freizugeben) - Upgraden oder Aktualisieren von
Node3 - Failover von VG3 auf
Node3
Bei dieser Art von Upgrade beträgt die durchschnittliche Downtime weniger als zwei Failovers pro Verfügbarkeitsgruppe. Die daraus resultierende Konfiguration ist in der folgenden Tabelle dargestellt.
| Verfügbarkeitsgruppe | Knoten1 | Knoten2 | Knoten3 |
|---|---|---|---|
| VG1 | Primär | ||
| VG2 | Primär | ||
| VG3 | Primär |
Je nach Ihrer spezifischen Implementierung kann der Upgradepfad abweichen. Das Gleiche gilt für die Downtime der Clientanwendungen.
Hinweis
In vielen Fällen wird nach Fertigstellung des parallelen Upgrades ein Failback auf das primäre Replikat durchgeführt.
Paralleles Upgrade einer verteilten Verfügbarkeitsgruppe
Wenn Sie ein paralleles Upgrade für eine verteilte Verfügbarkeitsgruppe durchführen möchten, müssen Sie zunächst alle sekundären Replikate upgraden. Führen Sie anschließend ein Failover für die Weiterleitung durch, und upgraden Sie die letzte verbleibende Instanz der sekundären Verfügbarkeitsgruppe. Sobald ein Upgrade für alle Replikate durchgeführt wurde, führen Sie ein Failover für das globale primäre Replikat durch, und upgraden Sie die letzte verbleibende Instanz der primären Verfügbarkeitsgruppe. Im Folgenden finden Sie eine Tabelle, in der die Schritte dargestellt werden.
Je nach Ihrer spezifischen Implementierung kann der Upgradepfad abweichen. Das Gleiche gilt für die Downtime der Clientanwendungen.
Hinweis
In vielen Fällen wird nach Fertigstellung des parallelen Upgrades ein Failback auf das primäre Replikat durchgeführt.
Allgemeine Schritte für das Upgrade einer verteilten Verfügbarkeitsgruppe
- Sichern Sie alle Datenbanken, einschließlich Systemdatenbanken und der Datenbanken, die an der Verfügbarkeitsgruppe beteiligt sind.
- Führen Sie ein Upgrade für alle sekundären Replikate der sekundären Verfügbarkeitsgruppe durch (der Downstream), und starten Sie sämtliche sekundären Replikate neu.
- Führen Sie ein Upgrade für alle sekundären Replikate der primären Verfügbarkeitsgruppe durch (der Upstream), und starten Sie sämtliche sekundären Replikate neu.
- Führen Sie ein Failover für das primäre Replikat der Weiterleitung auf ein aktualisiertes sekundäres Replikat der sekundären Verfügbarkeitsgruppe durch.
- Warten Sie, bis die Daten synchronisiert wurden. Die Datenbanken sollten auf allen Replikaten mit synchronem Commit als synchronisiert angezeigt werden, und das globale primäre Replikat sollte mit der Weiterleitung synchronisiert sein.
- Upgraden Sie die letzte verbleibende Instanz der sekundäre Verfügbarkeitsgruppe, und starten Sie diese Instanz neu.
- Führen Sie ein Failover für das globale primäre Replikat auf eine aktualisiertes sekundäre Replikat der primären Verfügbarkeitsgruppe durch.
- Upgraden Sie die letzte verbleibende Instanz der primären Verfügbarkeitsgruppe.
- Starten Sie den Server, für den das Upgrade gerade durchgeführt wurde.
- (optional) Führen Sie ein Failover für beide Verfügbarkeitsgruppen zu deren ursprünglichen primären Replikaten zurück durch.
Wichtig
Überprüfen Sie die Synchronisierung zwischen jedem Schritt. Bevor Sie mit dem nächsten Schritt fortfahren, sollten Sie sicherstellen, dass Ihre Replikate für synchronen Commit mit der Verfügbarkeitsgruppe synchronisiert sind und dass Ihr globales primäres Replikat mit der Weiterleitung in der verteilten Verfügbarkeitsgruppe synchronisiert ist.
Empfehlung: Aktualisieren Sie den Datenbankknoten und den Knoten der verteilten Verfügbarkeitsgruppe in SQL Server Management Studio bei jeder Überprüfung der Synchronisierung. Wenn alles synchronisiert wurde, sollten Sie einen Screenshot speichern, auf dem der Status jedes Replikats angezeigt wird. Dadurch können Sie nachverfolgen, in welchem Schritt Sie sich befinden und sichergehen, dass alle Komponenten vor dem nächsten Schritt ordnungsgemäß ausgeführt wurden. Wenn ein Fehler auftritt, können Sie den Screenshot zur Problembehandlung verwenden.
Beispieltabelle für ein paralleles Upgrade einer verteilten Verfügbarkeitsgruppe
| Verfügbarkeitsgruppe | Primäres Replikat | Sekundäres Replikat |
|---|---|---|
| VG1 | NODE1\SQLAG |
NODE2\SQLAG |
| VG2 | NODE3\SQLAG |
NODE4\SQLAG |
| Verteilte Verfügbarkeitsgruppe | AG1 (global) | AG2 (Weiterleitung) |
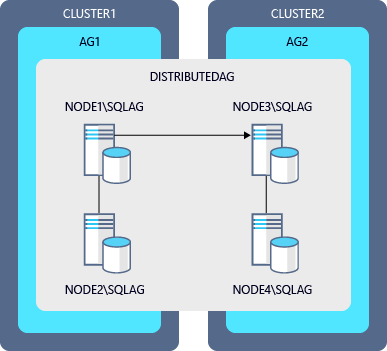
Folgende Schritte für das Upgrade der Instanzen sind in dieser Tabelle enthalten:
- Sichern Sie alle Datenbanken, einschließlich Systemdatenbanken und der Datenbanken, die an der Verfügbarkeitsgruppe beteiligt sind.
- Upgraden Sie
NODE4\SQLAG(sekundäres Replikat von AG2), und starten Sie den Server neu. - Upgraden Sie
NODE2\SQLAG(sekundäres Replikat von AG1), und starten Sie den Server neu. - Führen Sie ein Failover für AG2 von
NODE3\SQLAGaufNODE4\SQLAGdurch. - Upgraden Sie
NODE3\SQLAG, und starten Sie den Server neu. - Führen Sie ein Failover für AG1 von
NODE1\SQLAGaufNODE2\SQLAGdurch. - Upgraden Sie
NODE1\SQLAG, und starten Sie den Server neu. - (optional) Führen Sie ein Failback auf die ursprünglichen primären Replikate durch.
- Führen Sie ein Failover für AG2 von
NODE4\SQLAGzurück aufNODE3\SQLAGdurch. - Führen Sie ein Failover für AG1 von
NODE2\SQLAGzurück aufNODE1\SQLAGdurch.
- Führen Sie ein Failover für AG2 von
Wenn ein drittes Replikat in jeder Verfügbarkeitsgruppe vorhanden wäre, würde für dieses vor NODE3\SQLAG und NODE1\SQLAG ein Upgrade durchgeführt werden.
Wichtig
Überprüfen Sie die Synchronisierung zwischen jedem Schritt. Bevor Sie mit dem nächsten Schritt fortfahren, sollten Sie sicherstellen, dass Ihre Replikate für synchronen Commit mit der Verfügbarkeitsgruppe synchronisiert sind und dass Ihr globales primäres Replikat mit der Weiterleitung in der verteilten Verfügbarkeitsgruppe synchronisiert ist.
Empfehlung: Immer, wenn Sie die Synchronisierung überprüfen, sollten Sie den Datenbankknoten und den Knoten der verteilten Verfügbarkeitsgruppe in SQL Server Management Studio aktualisieren. Wenn alles synchronisiert wurde, sollten Sie einen Screenshot speichern. Dadurch können Sie nachverfolgen, in welchem Schritt Sie sich befinden und sichergehen, dass alle Komponenten vor dem nächsten Schritt ordnungsgemäß ausgeführt wurden. Wenn ein Fehler auftritt, können Sie den Screenshot zur Problembehandlung verwenden.
Spezielle Schritte für Change Data Capture oder die Replikation
Abhängig vom angewendeten Update können zusätzliche Schritte für Replikatdatenbanken von Verfügbarkeitsgruppen erforderlich sein, die für Change Data Capture oder die Replikation aktiviert sind. Lesen Sie die Anmerkungen zu dieser Version des Updates, um zu bestimmen, ob folgende Schritte erforderlich sind:
Upgraden Sie jedes sekundäre Replikat.
Führen Sie ein Failover der Verfügbarkeitsgruppe auf eine upgegradete Instanz durch, nachdem alle sekundären Replikate upgegradet wurden.
Führen Sie folgenden Transact-SQL-Befehl auf der Instanz aus, die das primäre Replikat hostet:
EXECUTE [master].[sys].[sp_vupgrade_replication];Hinweis
Die Ausführung dieses Befehls kann einige Minuten in Anspruch nehmen. Überspringen Sie diesen Schritt, wenn Sie mit SQL Server 2019 CU1 oder höher arbeiten. Weitere Informationen finden Sie unter KB4530283.
Führen Sie ein Upgrade für die Instanz aus, bei der es sich um das ursprüngliche primäre Replikat handelt.
Weitere Informationen finden Sie unter CDC functionality may break after upgrading to the latest CU (Die CDC-Funktion funktioniert nach dem Upgrade auf das aktuelle kumulative Update nicht mehr).