Azure Feature Pack für Integration Services (SSIS)
Gilt für: ![]() SQL Server
SQL Server ![]() SSIS Integration Runtime in Azure Data Factory
SSIS Integration Runtime in Azure Data Factory
Das SQL Server Integration Services-Feature Pack (SSIS) für Azure ist eine Erweiterung, die die auf dieser Seite für SSIS aufgelisteten Komponenten für Verbindungen mit Azure-Diensten, für die Übertragung von Daten zwischen Azure und lokalen Datenquellen und für die Verarbeitung der in Azure gespeicherten Daten bereitstellt.
 Herunterladen des SSIS-Feature Packs für Azure
Herunterladen des SSIS-Feature Packs für Azure
- Für SQL Server 2022 – Microsoft SQL Server 2022 Integration Services-Feature Pack für Azure
- Für SQL Server 2019 – Microsoft SQL Server 2019 Integration Services-Feature Pack für Azure
- Für SQL Server 2017 – Microsoft SQL Server 2017 Integration Services-Feature Pack für Azure
- Für SQL Server 2016 – Microsoft SQL Server 2016 Integration Services-Feature Pack für Azure
- Für SQL Server 2014 – Microsoft SQL Server 2014 Integration Services-Feature Pack für Azure
- Für SQL Server 2012 – Microsoft SQL Server 2012 Integration Services-Feature Pack für Azure
Die Downloadseiten enthalten auch Informationen zu erforderlichen Komponenten. Stellen Sie sicher, dass Sie SQL Server installieren, bevor Sie Azure Feature Pack auf einem Server installieren, andernfalls sind die Komponenten im Feature Pack womöglich nicht verfügbar, wenn Sie Pakete für die SSIS-Katalogdatenbank (SSISDB) auf dem Server bereitstellen.
Komponenten im Feature Pack
Verbindungs-Manager
Aufgaben
Datenflusskomponenten
Azure Blob, Azure Data Lake Store und Data Lake Storage Gen2-Datei-Enumerator. Siehe Foreach Loop Container (Foreach-Schleifencontainer).
Verwenden von TLS 1.2
Die vom Azure Feature Pack verwendete TLS-Version folgt den .NET Framework-Einstellungen.
Wenn Sie TLS 1.2 verwenden möchten, fügen Sie einen REG_DWORD-Wert mit dem Namen SchUseStrongCrypto für „data“ (Daten) unter den folgenden zwei Registrierungsschlüsseln 1 hinzu.
HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Microsoft\.NETFramework\v4.0.30319HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\.NETFramework\v4.0.30319
Abhängigkeit von Java
Java ist erforderlich, um ORC-/Parquet-Dateiformate mit Azure Data Lake Store/flexiblen Dateiconnectors zu verwenden.
Die Architektur (32 oder 64 Bit) des Java-Builds muss mit der zu verwendenden SSIS-Runtime übereinstimmen.
Die folgenden Java-Builds wurden getestet.
Einrichten von OpenJDK für Zulu
- Laden Sie das ZIP-Paket für die Installation herunter, und extrahieren Sie es.
- Führen Sie über die Eingabeaufforderung
sysdm.cplaus. - Klicken Sie auf der Registerkarte Erweitert auf Umgebungsvariablen.
- Klicken Sie im Abschnitt Systemvariablen auf Neu.
- Geben Sie
JAVA_HOMEfür den Variablennamen ein. - Klicken Sie auf Verzeichnis durchsuchen, navigieren Sie zum extrahierten Ordner, und wählen Sie den Unterordner
jreaus. Wählen Sie anschließend OK aus. Daraufhin wird der Variablenwert automatisch aufgefüllt. - Klicken Sie auf OK, um das Dialogfeld New System Variable (Neue Systemvariable) zu schließen.
- Klicken Sie auf OK, um das Dialogfeld Umgebungsvariablen zu schließen.
- Klicken Sie auf OK, um das Dialogfeld Systemeigenschaften zu schließen.
Tipp
Wenn Sie das Parquet-Format verwenden und die Fehlermeldung "An error occurred when invoking java, message: java.lang.OutOfMemoryError:Java heap space" (Beim Aufrufen von Java ist ein Fehler aufgetreten. Meldung: java.lang.OutOfMemoryError:Java heap space) auftritt, können Sie die Umgebungsvariable _JAVA_OPTIONS hinzufügen, um die minimale/maximale Heapgröße für JVM anzupassen.
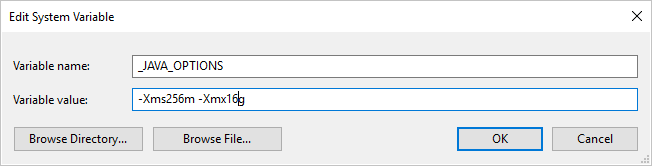
Beispiel: Legen Sie für die Variable _JAVA_OPTIONS den Wert -Xms256m -Xmx16g fest. Das Flag „Xms“ gibt den anfänglichen Speicherzuweisungspool für eine Java Virtual Machine (JVM) an, während Xmx den maximalen Speicherzuweisungspool angibt. Das bedeutet, dass die JVM mit einer Speichergröße von Xms gestartet wird und eine maximale Speichergröße von Xmx verwenden kann. Die Standardwerte sind mindestens 64 MB und maximal 1 GB.
Einrichten des Zulu OpenJDK in Azure-SSIS Integration Runtime
Dies sollte über eine benutzerdefinierte Setupschnittstelle für Azure-SSIS Integration Runtime erfolgen.
Angenommen, es wird zulu8.33.0.1-jdk8.0.192-win_x64.zip verwendet.
Der Blobcontainer könnte wie folgt organisiert werden.
main.cmd
install_openjdk.ps1
zulu8.33.0.1-jdk8.0.192-win_x64.zip
Als Einstiegspunkt löst main.cmd die Ausführung des PowerShell-Skripts install_openjdk.ps1 aus, welches wiederum zulu8.33.0.1-jdk8.0.192-win_x64.zip extrahiert und JAVA_HOME entsprechend festlegt.
main.cmd
powershell.exe -file install_openjdk.ps1
Tipp
Wenn Sie das Parquet-Format verwenden und die Fehlermeldung "An error occurred when invoking java, message: java.lang.OutOfMemoryError:Java heap space" (Beim Aufrufen von Java ist ein Fehler aufgetreten. Meldung: java.lang.OutOfMemoryError:Java heap space) auftritt, können Sie einen Befehl in main.cmd hinzufügen, um die minimale/maximale Heapgröße für JVM anzupassen. Beispiel:
setx /M _JAVA_OPTIONS "-Xms256m -Xmx16g"
Das Flag „Xms“ gibt den anfänglichen Speicherzuweisungspool für eine Java Virtual Machine (JVM) an, während Xmx den maximalen Speicherzuweisungspool angibt. Das bedeutet, dass die JVM mit einer Speichergröße von Xms gestartet wird und eine maximale Speichergröße von Xmx verwenden kann. Die Standardwerte sind mindestens 64 MB und maximal 1 GB.
install_openjdk.ps1
Expand-Archive zulu8.33.0.1-jdk8.0.192-win_x64.zip -DestinationPath C:\
[Environment]::SetEnvironmentVariable("JAVA_HOME", "C:\zulu8.33.0.1-jdk8.0.192-win_x64\jre", "Machine")
Einrichten von Oracle Java SE Runtime Environment
- Laden Sie das EXE-Installationsprogramm herunter, und führen Sie es aus.
- Führen Sie die Installationsanweisungen aus, um das Setup abzuschließen.
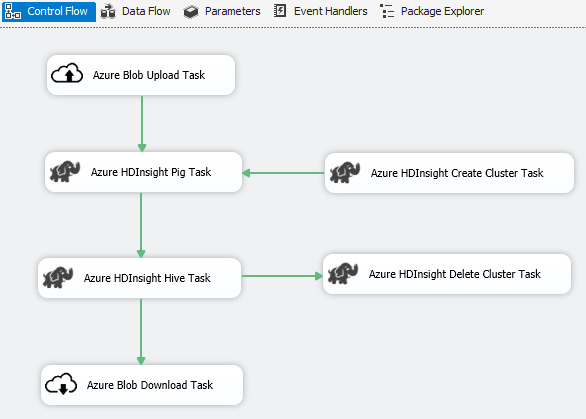
Szenario: Verarbeitung großer Datenmengen
Verwenden Sie den Azure Connector zum Ausführen der folgenden Big Data-Verarbeitungsaufgaben:
Verwenden Sie den Azure Blob Upload-Task zum Hochladen von Eingabedaten in den Azure BLOB-Speicher.
Verwenden Sie den Azure HDInsight Create Cluster-Task zum Erstellen eines Azure HDInsight-Clusters. Dieser Schritt ist optional, wenn Sie einen eigenen Cluster verwenden möchten.
Verwenden Sie den Azure HDInsight Hive-Task oder Azure HDInsight Pig-Task zum Aufrufen eines Pig- oder Hive-Auftrags auf dem Azure HDInsight-Cluster.
Verwenden Sie den Azure HDInsight Delete Cluster-Task zum Löschen des HDInsight-Clusters nach der Verwendung, wenn Sie in Schritt 2 einen HDInsight-Bedarfscluster erstellt haben.
Verwenden Sie den Azure HDInsight Blob Download-Task zum Herunterladen der Pig/Hive-Ausgabedaten vom Azure BLOB-Speicher.
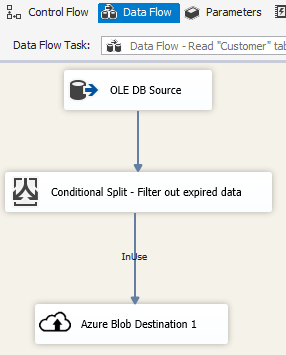
Szenario: Verwalten von Daten in der Cloud
Verwenden Sie das Azure BLOB-Ziel in einem SSIS-Paket, um Ausgabedaten in einen Azure BLOB-Speicher zu schreiben, oder verwenden Sie die Azure Blob-Quelle zum Lesen von Daten aus einem Azure BLOB-Speicher.
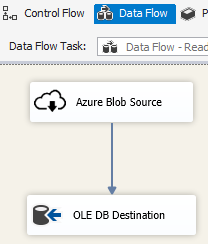
Verwenden Sie den Foreach-Schleifencontainer mit dem Azure Blob-Enumerator, um Daten in mehreren BLOB-Dateien zu verarbeiten.
Versionsinformationen
Version 1.21.0
Verbesserungen
- Log4j wurde von Version 1.2.17 auf 2.17.1 aktualisiert.
Version 1.20.0
Verbesserungen
- Die Zielversion von .NET Framework wurde von 4.6 auf 4.7.2 aktualisiert.
- Der „Azure SQL DW-Uploadtask“ wurde in „Azure Synapse Analytics-Task“ umbenannt.
Fehlerbehebungen
- Wenn der Computer, der SSIS ausführt, beim Zugriff auf Azure Blob Storage nicht das Gebietsschema „en-US“ aufweist, schlägt die Paketausführung mit der Fehlermeldung „String not recognized as a valid DateTime value“ (Die Zeichenfolge wurde nicht als gültiger DateTime-Wert erkannt) fehl.
- Für den Azure Storage-Verbindungs-Manager ist ein Geheimnis erforderlich (das nicht verwendet wird), selbst wenn eine verwaltete Data Factory-Identität für die Authentifizierung verwendet wird.
Version 1.19.0
Verbesserungen
- Azure Storage-Verbindungs-Manager wurde Unterstützung für SAS-Authentifizierung (Shared Access Signature) hinzugefügt.
Version 1.18.0
Verbesserungen
- Für flexible Dateitasks wurden drei Verbesserungen eingeführt: (1) Es wurde Unterstützung für Platzhalter bei Kopier-/Löschvorgängen hinzugefügt. (2) Der Benutzer kann die rekursive Suche bei Löschvorgängen aktivieren/deaktivieren. (3) Der Name der Zieldatei kann bei Kopiervorgängen leer bleiben, um den Namen der Quelldatei beizubehalten.
Version 1.17.0
Hierbei handelt es sich um eine ausschließlich für SQL Server 2019 veröffentlichte Hotfixversion.
Fehlerbehebungen
- Beim Ausführen in Visual Studio 2019 mit SQL Server 2019 als Ziel kann es bei flexiblen Dateitasks/Quellen/Zielen zu folgender Fehlermeldung kommen:
Attempted to access an element as a type incompatible with the array. - Beim Ausführen in Visual Studio 2019 mit SQL Server 2019 als Ziel kann es bei flexiblen Dateitasks/Zielen bei Verwendung des ORC-/Parquet-Formats zu folgender Fehlermeldung kommen:
Microsoft.DataTransfer.Common.Shared.HybridDeliveryException: An unknown error occurred. JNI.JavaExceptionCheckException.(Microsoft.DataTransfer.Common.Shared.HybridDeliveryException: Unbekannter Fehler. JNI.JavaExceptionCheckException.).
Version 1.16.0
Fehlerbehebungen
- In bestimmten Fällen meldet die Paketausführung „Fehler: Die Datei oder Assembly ‚Newtonsoft.Json, Version=11.0.0.0, Culture=neutral, PublicKeyToken=30ad4fe6b2a6aeed‘ oder eine ihrer Abhängigkeiten konnte nicht gefunden werden.“
Version 1.15.0
Verbesserungen
- Vorgang zum Löschen eines Ordners bzw. einer Datei zum flexiblen Dateitask hinzugefügt
- Funktion zum Konvertieren des externen bzw. Ausgabedatentyps zur flexiblen Dateiquelle hinzugefügt
Fehlerbehebungen
- In bestimmten Fällen treten Fehler beim Testen der Verbindung für Data Lake Storage Gen2 auf, und die Fehlermeldung „Es wurde versucht, auf ein Element zuzugreifen, dessen Typ mit dem Array nicht kompatibel ist“ wird angezeigt.
- Unterstützung für den Azure-Speicheremulator wieder verfügbar
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für