Anzeigen von Histogrammen in Python
Gilt für: ![]() SQL Server
SQL Server ![]() Azure SQL-Datenbank
Azure SQL-Datenbank ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
In diesem Artikel wird beschrieben, wie Sie Daten mithilfe des Python-Pakets pandas'.hist() darstellen können. Eine SQL-Datenbank ist die Quelle, die verwendet wird, um die Histogrammdatenintervalle zu visualisieren, die über aufeinanderfolgende, nicht überlappende Werte verfügen.
Voraussetzungen
SQL Server Management Studio zum Wiederherstellen der Beispieldatenbank in Azure SQL Managed Instance
Azure Data Studio. Informationen zur Installation finden Sie unter Azure Data Studio.
Wiederherstellen einer Data Warehouse-Beispieldatenbank, um die in diesem Artikel verwendeten Beispieldaten zu erhalten
Überprüfen der wiederhergestellten Datenbank
Sie können überprüfen, ob die wiederhergestellte Datenbank vorhanden ist, indem Sie die Tabelle Person.CountryRegion abfragen:
USE AdventureWorksDW;
SELECT * FROM Person.CountryRegion;
Installieren von Python-Paketen
Laden Sie Azure Data Studio herunter, und führen Sie die Installation durch.
Installieren Sie die folgenden Python-Pakete:
pyodbcpandassqlalchemymatplotlib
Installieren Sie diese Pakete wie folgt:
- Klicken Sie in Ihrem Azure Data Studio-Notebook auf die Option Pakete verwalten.
- Klicken Sie dann im Bereich Manage Packages (Pakete verwalten) auf die Registerkarte Add new (Neue hinzufügen).
- Geben Sie für jedes der folgenden Pakete den jeweiligen Paketnamen ein, wählen Sie Suchen und dann Installieren.
Anzeigen des Histogramms
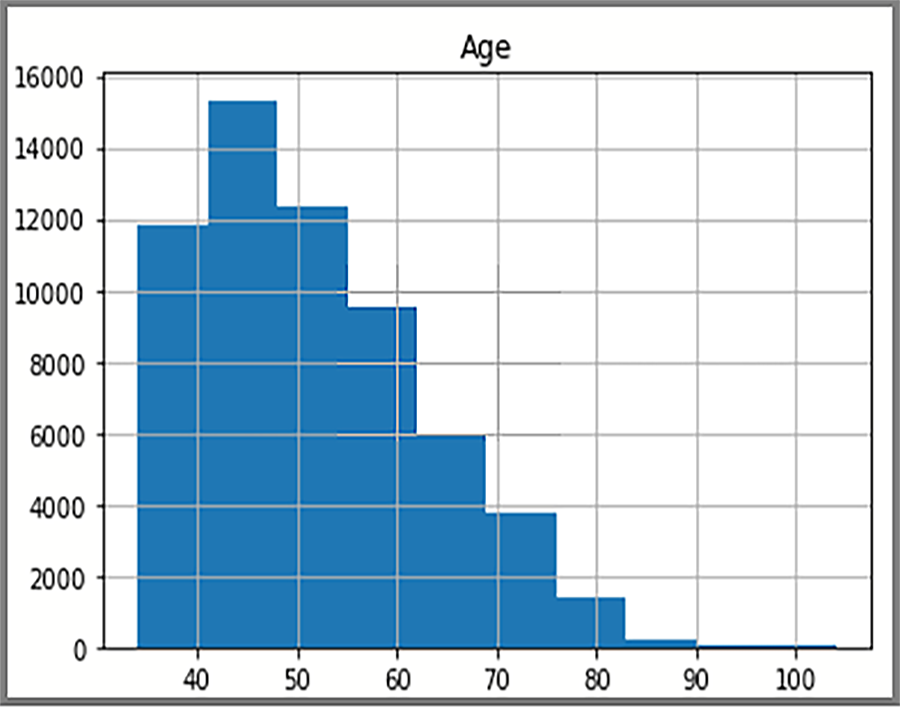
Die im Histogramm angezeigten verteilten Daten basieren auf einer SQL-Abfrage von AdventureWorksDW2022. Im Histogramm werden Daten und die Häufigkeit von Datenwerten visualisiert.
Bearbeiten Sie die Verbindungszeichenfolgenvariablen „server“, „database“, „username“ und „password“, um eine Verbindung mit der SQL Server-Datenbank herzustellen.
So erstellen Sie ein neues Notebook
- Klicken Sie in Azure Data Studio auf Datei und dann auf Neues Notebook.
- Wählen Sie im Notebook den Kernel Python3 aus, und klicken Sie dann auf +code.
- Fügen Sie den Code in das Notebook ein, und klicken Sie auf Alle ausführen.
import pyodbc
import pandas as pd
import matplotlib
import sqlalchemy
from sqlalchemy import create_engine
matplotlib.use('TkAgg', force=True)
from matplotlib import pyplot as plt
# Some other example server values are
# server = 'localhost\sqlexpress' # for a named instance
# server = 'myserver,port' # to specify an alternate port
server = 'servername'
database = 'AdventureWorksDW2022'
username = 'yourusername'
password = 'databasename'
url = 'mssql+pyodbc://{user}:{passwd}@{host}:{port}/{db}?driver=SQL+Server'.format(user=username, passwd=password, host=server, port=port, db=database)
engine = create_engine(url)
sql = "SELECT DATEDIFF(year, c.BirthDate, GETDATE()) AS Age FROM [dbo].[FactInternetSales] s INNER JOIN dbo.DimCustomer c ON s.CustomerKey = c.CustomerKey"
df = pd.read_sql(sql, engine)
df.hist(bins=50)
plt.show()
Die Anzeige zeigt die Altersverteilung von Kunden in der FactInternetSales-Tabelle an.