Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server
SQL Server
Die Datenerkennung und -klassifizierung fügt Funktionen zum Erkennen, Klassifizieren, Bezeichnen sowie für die Berichterstellung für vertrauliche Daten in Ihren Datenbanken hinzu. Dies kann über T-SQL oder mit SQL Server Management Studio (SSMS) erfolgen. Das Ermitteln und Klassifizieren Ihrer sensibelsten Daten (Geschäft, Finanzwesen, Gesundheitswesen usw.) kann eine zentrale Rolle für den Informationsschutz Ihrer Organisation spielen. Sie kann für Folgendes als Infrastruktur gelten:
- Unterstützung bei der Einhaltung von Datenschutzstandards.
- Überwachen des Zugriffs auf Datenbanken/Spalten, die streng vertrauliche Daten enthalten.
Hinweis
Datenermittlung & Die Klassifizierung wird für SQL Server 2012 und höher
Übersicht
Datenermittlung & Klassifizierung bildet ein neues Informationsschutzparadigma für SQL-Datenbank, SQL Managed Instance und Azure Synapse, das darauf abzielt, die Daten und nicht nur die Datenbank zu schützen. Derzeit werden die folgenden Funktionen unterstützt:
- Ermittlung und Empfehlungen: Die Klassifizierungsengine überprüft Ihre Datenbank und identifiziert Spalten, die möglicherweise sensible Daten enthalten. Dann besteht die einfache Möglichkeit zum Überprüfen und Anwenden der geeigneten Empfehlungen zur Klassifizierung und zum manuellen Klassifizieren von Spalten.
- Bezeichnung: Bezeichnungen zur Vertraulichkeitsklassifizierung können Spalten dauerhaft zugewiesen werden.
- Sichtbarkeit: Der Klassifizierungsstatus der Datenbank kann in einem detaillierten Bericht angezeigt werden, der zwecks Konformität und Überprüfung ausgedruckt oder exportiert werden kann.
Ermitteln, Klassifizieren und Bezeichnen von sensiblen Spalten
Im folgenden Abschnitt werden die Schritte zum Ermitteln, Klassifizieren und Bezeichnen von Spalten mit sensiblen Daten in Ihrer Datenbank sowie das Anzeigen des aktuellen Klassifizierungsstatus Ihrer Datenbank und das Exportieren von Berichten beschrieben.
Die Klassifizierung umfasst zwei Metadatenattribute:
- Bezeichnungen: Die wichtigsten Klassifizierungsattribute zum Definieren der Vertraulichkeitsstufe der in der Spalte gespeicherten Daten.
- Informationstypen: bieten zusätzliche Granularität beim Typ der in der Spalte gespeicherten Daten.
Um Ihre SQL Server Datenbank zu klassifizieren:
Stellen Sie in SQL Server Management Studio (SSMS) eine Verbindung mit dem SQL Server her.
Wählen Sie im SSMS Objekt-Explorer die Datenbank aus, die Sie klassifizieren möchten, und wählen Sie Tasks>Datenermittlung und Klassifizierung>Classify Data... .
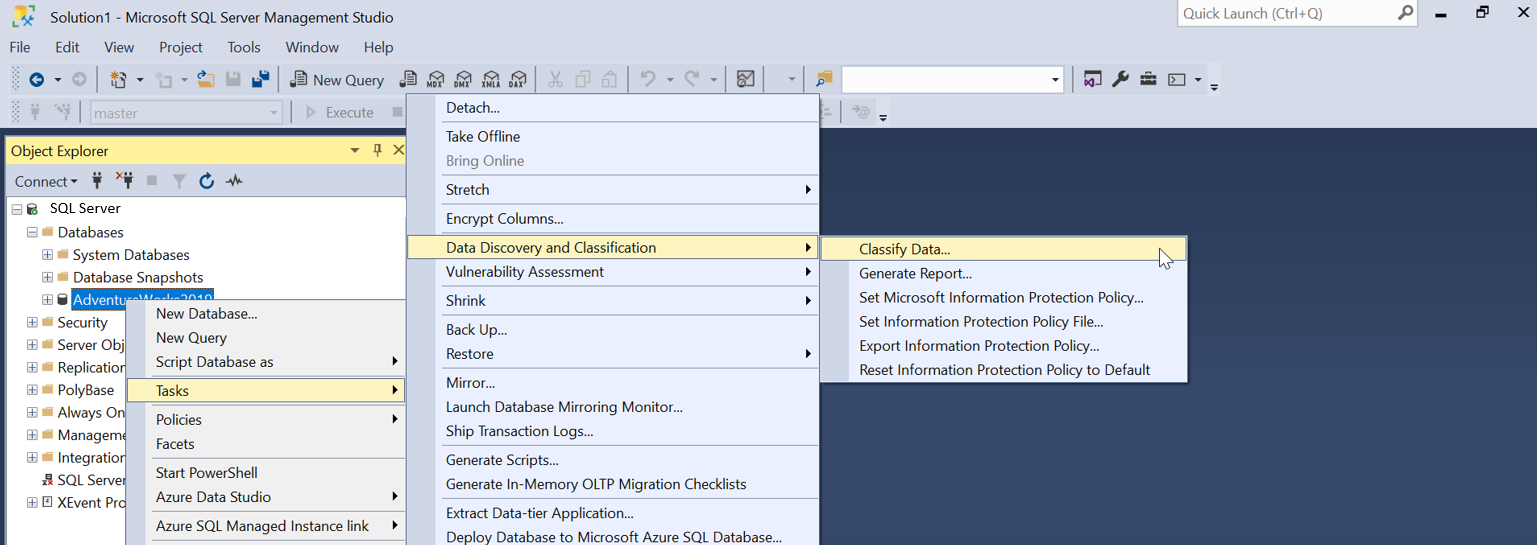
Die Klassifizierungs-Engine überprüft die Datenbank auf Spalten (ausschließlich nach dem Spaltennamen), die potenziell vertrauliche Daten enthalten, und erstellt eine Liste der empfohlenen Spaltenklassifizierungen:
Wählen Sie das Benachrichtigungsfeld für die Empfehlungen am oberen Rand des Fensters oder den Bereich für Empfehlungen am unteren Rand des Fensters aus, um eine Liste der empfohlenen Spaltenklassifizierungen anzuzeigen:


Überprüfen Sie die Liste der Empfehlungen:
Zum Akzeptieren einer Empfehlung für eine bestimmte Spalte aktivieren Sie das Kontrollkästchen in der linken Spalte der entsprechenden Zeile. Sie können auch alle Empfehlungen als akzeptiert markieren, indem Sie das Kontrollkästchen im Tabellenkopf der Empfehlungen aktivieren.
Sie können auch den empfohlenen Informationstyp und die Vertraulichkeitsbezeichnung mithilfe der Dropdownfelder ändern.
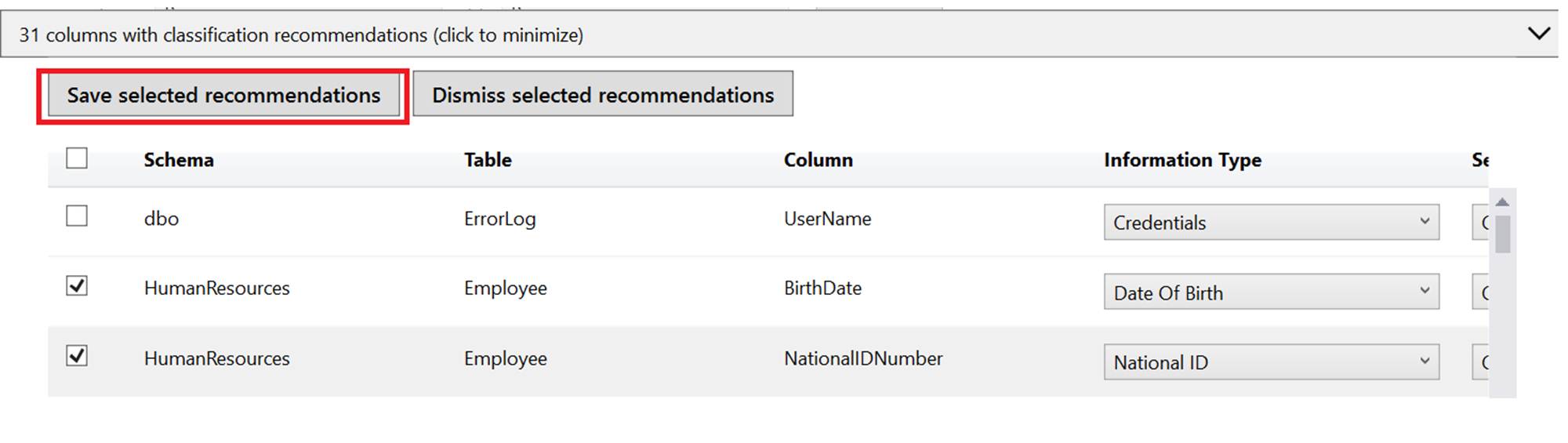
Wählen Sie zum Anwenden der ausgewählten Empfehlungen die Option Ausgewählte Empfehlungen speichern aus.

Hinweis
Der Empfehlungmechanismus, der die automatische Datenentdeckung durchführt und Empfehlungen für sensible Spalten bereitstellt, wird deaktiviert, wenn der Richtlinienmodus von Microsoft Purview Information Protection verwendet wird.
Um die klassifizierten Spalten anzuzeigen, wählen Sie in der Dropdownliste das entsprechende Schema und die entsprechende Tabelle und dann Spalten laden aus.
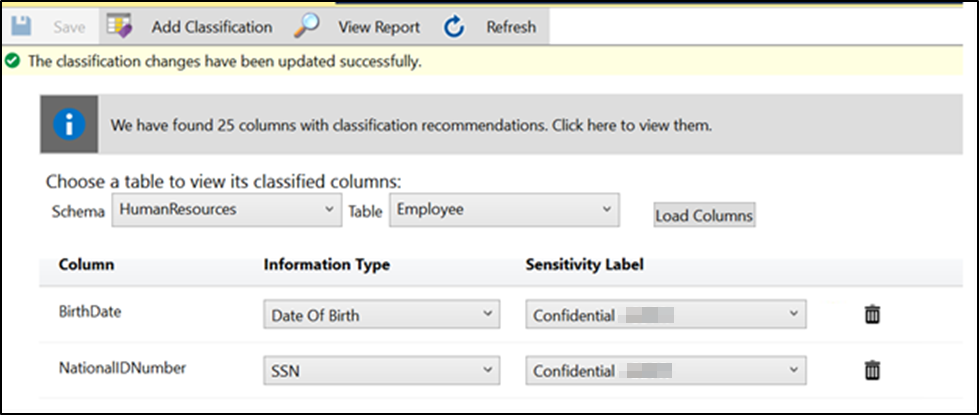
Alternativ oder zusätzlich zur empfehlungsbasierten Klassifizierung können Sie Spalten auch manuell klassifizieren:
Wählen Sie im oberen Menü des Fensters Klassifizierung hinzufügen aus.

Wählen Sie im daraufhin geöffneten Kontextfenster den Spaltennamen, den Sie klassifizieren möchten, den Informationstyp und die Vertraulichkeitsbezeichnung aus. Schema und Tabelle werden basierend auf den Einträgen auf der Hauptseite ausgewählt.
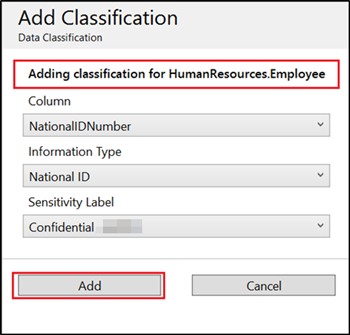
Wenn Sie in einem einzigen Versuch eine Klassifizierung für alle nicht klassifizierten Spalten für eine bestimmte Tabelle hinzufügen möchten, wählen Sie in der Dropdownliste Spalte der Seite Klassifizierung hinzufügen die Option Alle nicht klassifiziert aus.
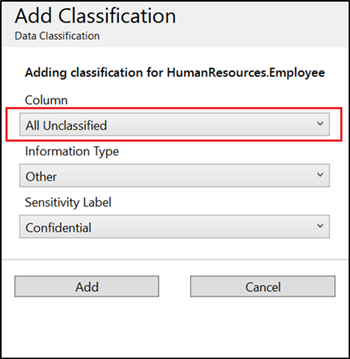
Wählen Sie im oberen Menü des Fensters die Schaltfläche Speichern aus, um Ihre Klassifizierung abzuschließen und die Datenbankspalten dauerhaft mit den neuen Klassifizierungsmetadaten (Tags) zu bezeichnen.

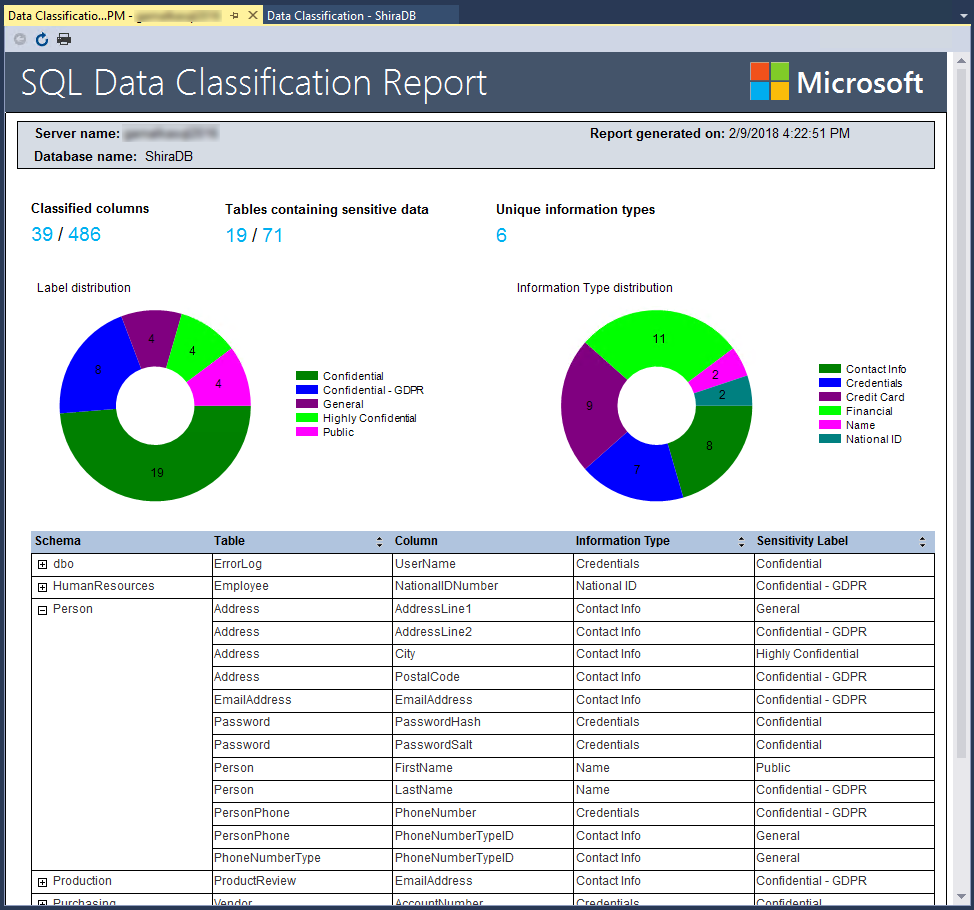
Wählen Sie im oberen Menü des Fensters Bericht anzeigen aus, um einen Bericht mit einer vollständigen Zusammenfassung des Klassifizierungsstatus der Datenbank zu generieren. (Sie können auch über SSMS einen Bericht erstellen. Wählen Sie mit der rechten Maustaste die Datenbank aus, in der der Bericht erstellt werden soll, und wählen Sie Aufgaben>Datenerkennung und -klassifizierung>Bericht generieren… aus.)

Klassifizieren Sie Ihre Datenbank mithilfe von Microsoft Purview Information Protection Richtlinien
Hinweis
Microsoft Information Protection ( abgekürzt als MIP) wurde als Microsoft Purview Information Protection umbenannt. Sowohl die Begriffe MIP als auch Microsoft Purview Information Protection werden in diesem Dokument häufig austauschbar verwendet, aber beide beziehen sich auf dasselbe Konzept.
Microsoft Purview Information Protection Bezeichnungen bieten Ihren Benutzern eine einfache und einheitliche Möglichkeit, vertrauliche Daten in SQL Server zu klassifizieren. MIP-Vertraulichkeitsbezeichnungen werden im Microsoft 365 Compliance Center [als Microsoft Purview Complianceportal umbenannt] erstellt und verwaltet. Informationen zum Erstellen und Veröffentlichen von MIP-Vertraulichkeitsbezeichnungen im Microsoft Purview-Complianceportal finden Sie im Artikel Vertraulichkeitsbezeichnungen für Microsoft Information Protection.
Jetzt können Sie SSMS verwenden, um Daten an der Quelle (SQL Server) mithilfe von Microsoft Purview Information Protection Bezeichnungen zu klassifizieren, die in Power BI, Office und anderen Microsoft-Produkten verwendet werden. Diese Vertraulichkeitsbezeichnungen werden auf Spaltenebene in einer Datenbank angewendet, identisch mit der SQL-Information Protection-Richtlinie.
Power BI-Datasets oder Berichte, die eine Verbindung mit Daten mit Vertraulichkeitsbezeichnung in unterstützten Datenquellen herstellen, können diese Bezeichnungen automatisch erben, damit die Daten bei der Erfassung in Power BI und dem Export in Downstreamanwendungen klassifiziert bleiben. Die Verfügbarkeit der MIP-Richtlinie in SSMS ermöglicht Ihnen, eine unternehmensweite End-to-End-Klassifizierungslösung zu erreichen.
Schritte zum Konfigurieren der Microsoft Purview Information Protection-Richtlinie
Stellen Sie in SQL Server Management Studio (SSMS) eine Verbindung mit dem SQL Server her.
Wählen Sie im SSMS-Objekt-Explorer die Datenbank aus, die Sie klassifizieren möchten, und wählen Sie Tasks>Datenermittlung und -klassifizierung>Set Microsoft Information Protection Policy
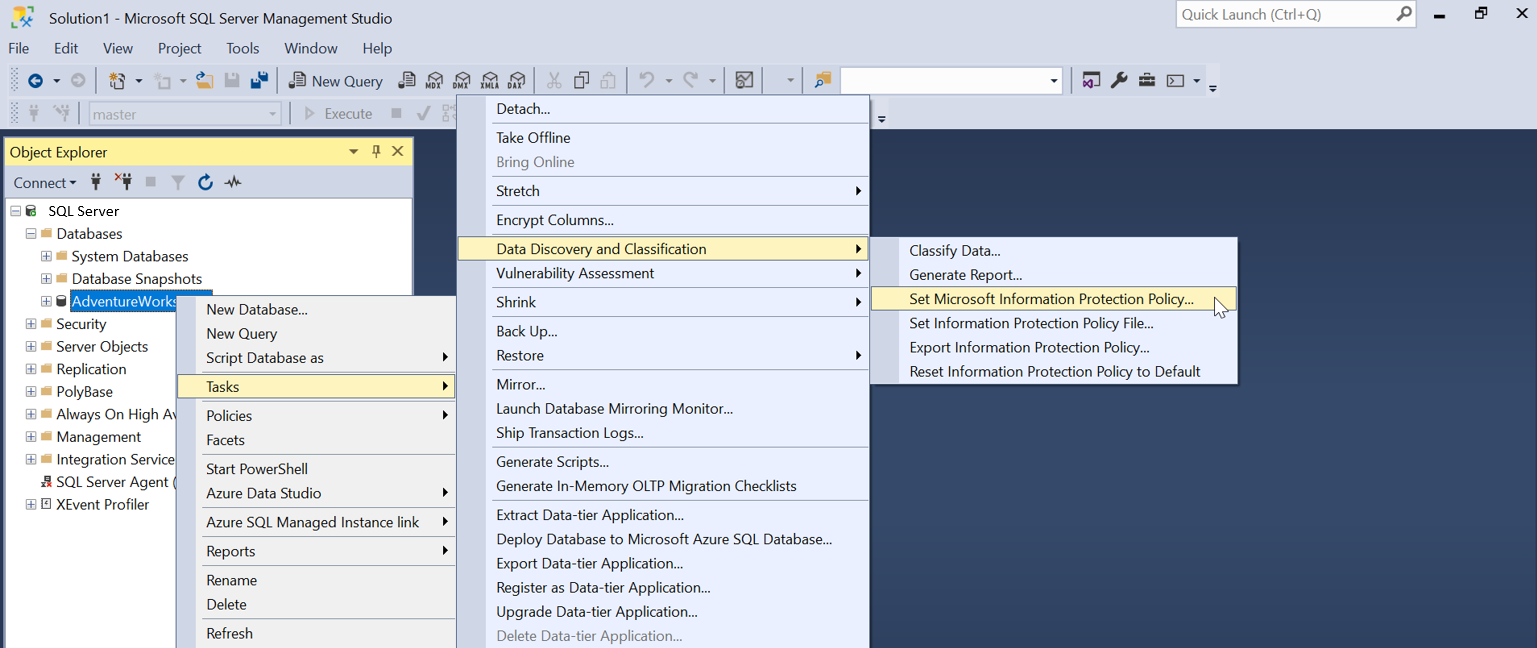
Ein Authentifizierungsfenster für Microsoft 365 zum Festlegen der Microsoft Information Protection-Richtlinie wird angezeigt. Wählen Sie Sign in aus, und geben Sie eine gültige Benutzeranmeldeinformationen ein, um sich bei Ihrem Microsoft 365 Mandanten zu authentifizieren.
Wenn die Authentifizierung erfolgreich ist, wird ein Popupfenster mit dem Status Erfolg angezeigt.
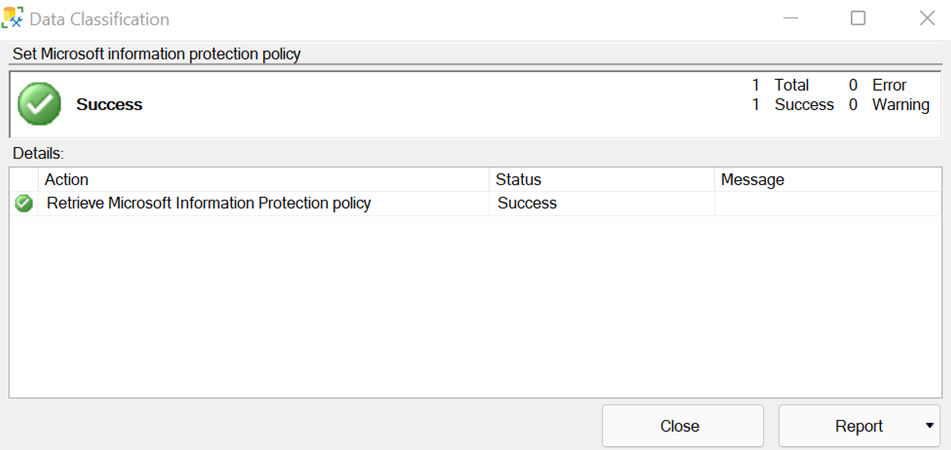
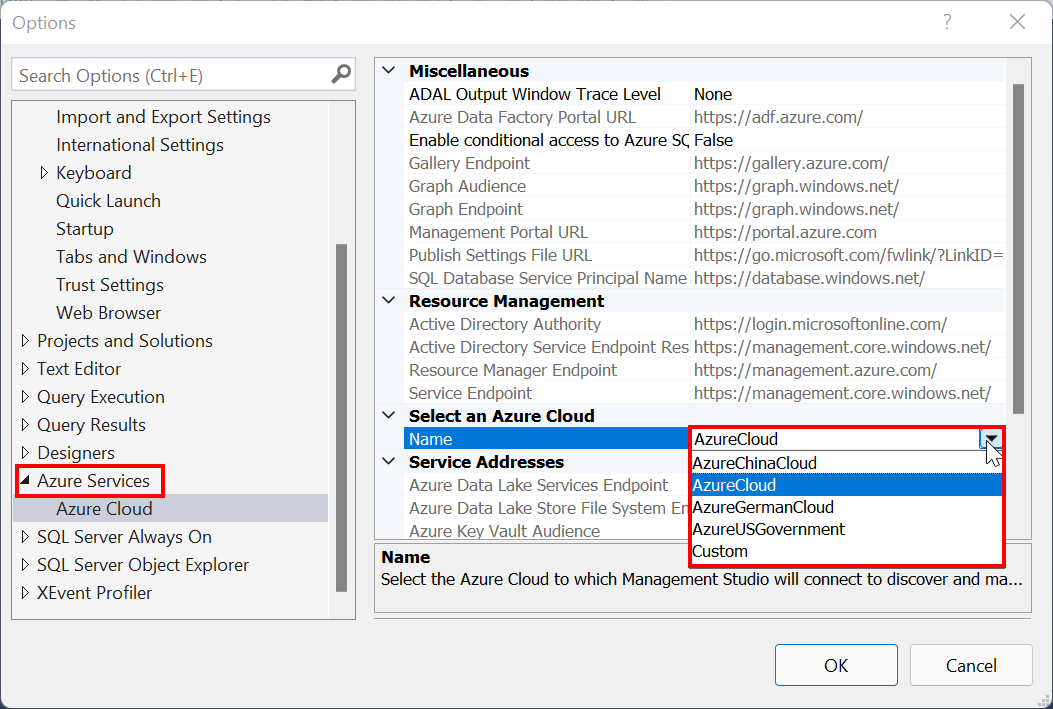
Optional – Wenn Sie sich bei einer der Microsoft-Souveränen Clouds anmelden möchten, um sich bei Microsoft 365 zu authentifizieren, wechseln Sie zu SSMS >Tools>Options>Azure Services>Azure Cloud und ändern Sie den Name in die relevante Microsoft-Souveräne Cloud.
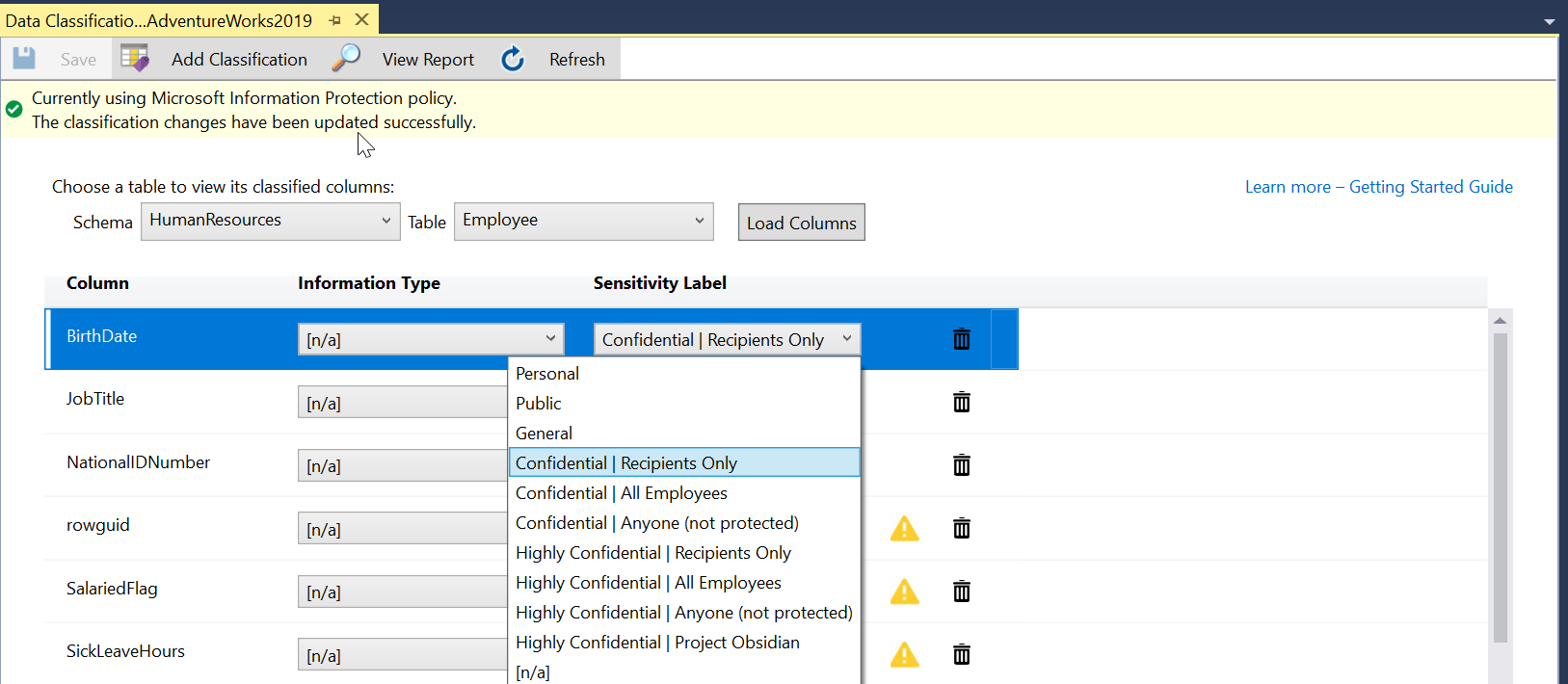
Im SSMS-fenster Objekt-Explorer Klicken Sie mit der rechten Maustaste auf die Datenbank, die Sie klassifizieren möchten, und wählen Sie Tasks>Data Discovery and Classification>Classify Data aus. Sie können jetzt neue Klassifizierungen mithilfe von MIP-Vertraulichkeitsbezeichnungen hinzufügen, die in Ihrem Microsoft 365 Mandanten definiert sind, und diese Bezeichnungen verwenden, um Spalten in SQL Server zu klassifizieren.
Die automatische Datenermittlung und -empfehlung ist im Microsoft Information Protection-Richtlinienmodus deaktiviert. Es ist derzeit nur im SQL-Information Protection-Richtlinienmodus verfügbar.
Um die Information Protection-Richtlinie auf standard- oder SQL-Information Protection zurückzusetzen, wechseln Sie zum SSMS Objekt-Explorer, klicken Sie mit der rechten Maustaste auf die Datenbank, und wählen Sie Tasks>Data Discovery and Classification>Reset Information Protection Richtlinie auf "Standard. Dadurch wird die Standard- oder SQL-Information Protection-Richtlinie angewendet, und Sie können die Daten mithilfe von SQL-Vertraulichkeitsbezeichnungen anstelle von MIP-Bezeichnungen klassifizieren.
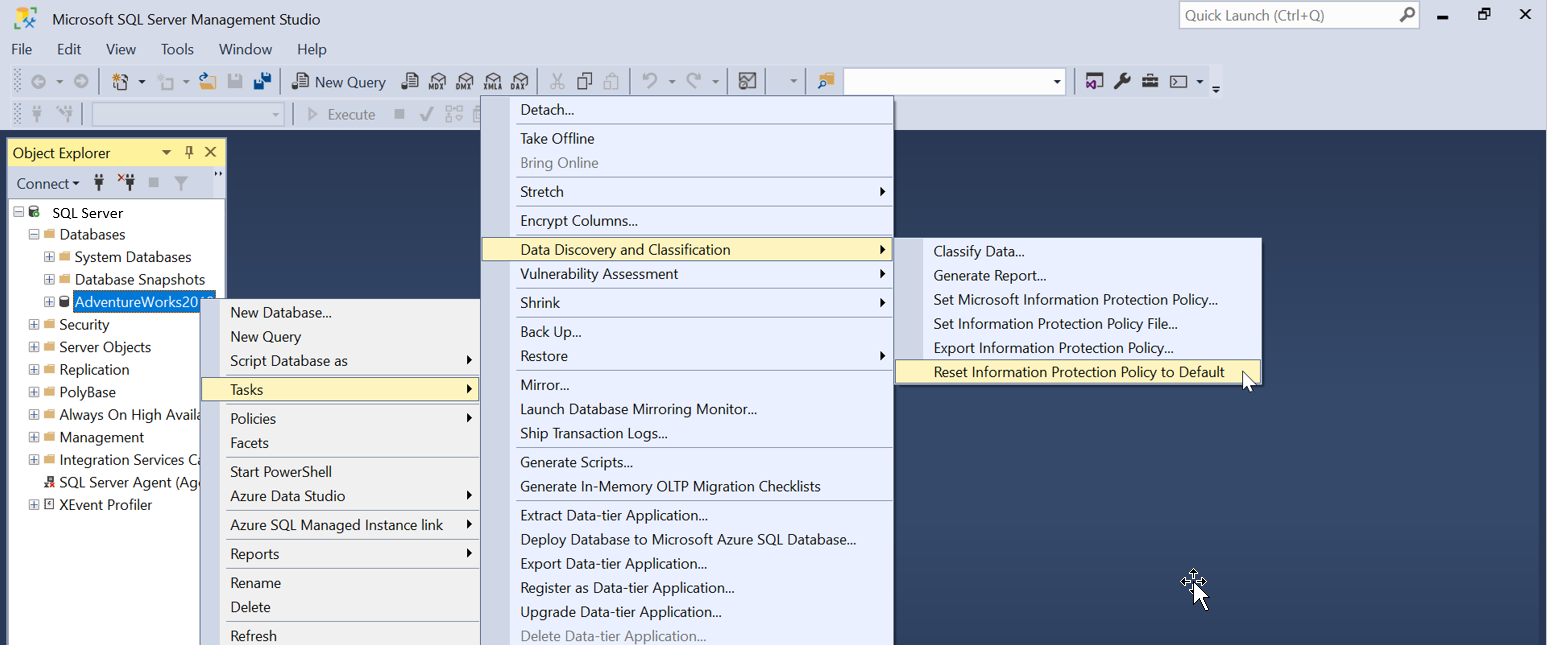
So aktivieren Sie die Information Protection-Richtlinie von einer benutzerdefinierten JSON-Datei, gehen Sie zum SSMS Objekt-Explorer, klicken Sie mit der rechten Maustaste auf die Datenbank und wählen Sie Tasks>Datenermittlung und -klassifizierung>Information Protection-Richtliniendatei festlegen.
Hinweis
Ein Warnsymbol gibt an, dass die Spalte zuvor mit einer anderen Information Protection Richtlinie als dem aktuell ausgewählten Richtlinienmodus klassifiziert wurde. Wenn Sie sich z. B. derzeit im Microsoft Informationsschutzmodus befinden und eine der Spalten zuvor mithilfe der SQL-Informationsschutzrichtlinie oder einer Informationsschutzrichtlinie aus einer benutzerdefinierten Richtliniendatei klassifiziert wurde, wird ein Warnsymbol gegen diese Spalte angezeigt. Sie können entscheiden, ob Sie die Klassifizierung der Spalte in eine der Vertraulichkeitsbezeichnungen ändern möchten, die im aktuellen Richtlinienmodus verfügbar sind, oder ob Sie sie so belassen möchten.
![]()
Verwaltung der Informationsschutzrichtlinie mit SSMS
Sie können die Information Protection-Richtlinie mit der neuesten Version von
Stellen Sie in SQL Server Management Studio (SSMS) eine Verbindung mit dem SQL Server her.
Wählen Sie im SSMS-Objekt-Explorer eine Ihrer Datenbanken aus, und wählen Sie Tasks>Datenermittlung und -klassifizierung aus.
Mit den folgenden Menüoptionen können Sie die Information Protection-Richtlinie verwalten:
Set Microsoft Information Protection Policy: Setzt die Information Protection Policy auf die Microsoft Purview Information Protection Policy.
Information Protection-Richtliniendatei festlegen: verwendet die SQL Information Protection-Richtlinie wie in der ausgewählten JSON-Datei definiert (Weitere Informationen finden Sie unter Information Protection-Richtliniendatei.)
Export der Information Protection-Richtlinie: Exportiert die Information Protection-Richtlinie in eine JSON-Datei.
Informationsschutzrichtlinie zurücksetzen: Setzt die Informationsschutzrichtlinie auf die SQL-Informationsschutz-Standardrichtlinie zurück.
Wichtig
Die Informationsschutzrichtliniendatei wird nicht im SQL Server gespeichert. SSMS verwendet eine Information Protection-Standardrichtlinie. Wenn eine benutzerdefinierte Informationsschutzrichtlinie fehlschlägt, kann SSMS die Standardrichtlinie nicht verwenden. Die Datenklassifizierung schlägt fehl. Um das Problem zu beheben, klicken Sie auf Information-Schutzrichtlinie zurücksetzen, um die Standardrichtlinie zu verwenden und die Datenklassifizierung erneut zu aktivieren.
Zugriff auf Klassifizierungsmetadaten
SQL Server 2019 führt sys.sensitivity_classifications Systemkatalogansicht ein. Diese Ansicht gibt Informationstypen und Vertraulichkeitsbezeichnungen zurück.
Führen Sie eine Abfrage auf Instanzen von SQL Server 2019 sys.sensitivity_classifications aus, um alle klassifizierten Spalten mit ihren entsprechenden Klassifizierungen einzusehen. Zum Beispiel:
SELECT
schema_name(O.schema_id) AS schema_name,
O.NAME AS table_name,
C.NAME AS column_name,
information_type,
label,
rank,
rank_desc
FROM sys.sensitivity_classifications sc
JOIN sys.objects O
ON sc.major_id = O.object_id
JOIN sys.columns C
ON sc.major_id = C.object_id AND sc.minor_id = C.column_id
Vor SQL Server 2019 sind die Klassifizierungsmetadaten für Informationstypen und Vertraulichkeitsbezeichnungen in den folgenden erweiterten Eigenschaften enthalten:
sys_information_type_namesys_sensitivity_label_name
Für Instanzen von SQL Server 2017 und früher gibt das folgende Beispiel alle klassifizierten Spalten mit ihren entsprechenden Klassifizierungen zurück:
SELECT
schema_name(O.schema_id) AS schema_name,
O.NAME AS table_name,
C.NAME AS column_name,
information_type,
sensitivity_label
FROM
(
SELECT
IT.major_id,
IT.minor_id,
IT.information_type,
L.sensitivity_label
FROM
(
SELECT
major_id,
minor_id,
value AS information_type
FROM sys.extended_properties
WHERE NAME = 'sys_information_type_name'
) IT
FULL OUTER JOIN
(
SELECT
major_id,
minor_id,
value AS sensitivity_label
FROM sys.extended_properties
WHERE NAME = 'sys_sensitivity_label_name'
) L
ON IT.major_id = L.major_id AND IT.minor_id = L.minor_id
) EP
JOIN sys.objects O
ON EP.major_id = O.object_id
JOIN sys.columns C
ON EP.major_id = C.object_id AND EP.minor_id = C.column_id
Berechtigungen
Auf SQL Server 2019-Instanzen ist zum Anzeigen von Klassifizierungen die Berechtigung VIEW ANY SENSITIVITY CLASSIFICATION erforderlich. Weitere Informationen finden Sie unter Metadata Visibility Configuration.
Vor SQL Server 2019 kann auf die Metadaten über die Katalogansicht „Erweiterte Eigenschaften“ sys.extended_properties zugegriffen werden.
Für die Verwaltung der Klassifizierung ist ALTER ANY-Berechtigung SENSITIVITY CLASSIFICATION erforderlich. Die Berechtigung ALTER ANY SENSITIVITY CLASSIFICATION ist in der Datenbankberechtigung ALTER oder der Serverberechtigung CONTROL SERVER enthalten.
Verwalten von Klassifizierungen
Mit T-SQL können Sie Spaltenklassifizierungen hinzufügen oder entfernen sowie alle Klassifizierungen für die gesamte Datenbank abrufen.
- Hinzufügen/Aktualisieren der Klassifizierung einer oder mehrerer Spalten: ADD SENSITIVITY CLASSIFICATION
- Entfernen Sie die Klassifizierung aus einer oder mehreren Spalten: DROP SENSITIVITY CLASSIFICATION
Nächste Schritte
Informationen zu Azure SQL-Datenbank finden Sie unter
Ziehen Sie in Betracht, Ihre sensiblen Spalten durch Anwenden von Sicherheitsmechanismen auf der Spaltenebene zu schützen:
- Dynamische Datenmaskierung zum Verbergen der verwendeten sensiblen Spalten.
- Always Encrypted zum Verschlüsseln vertraulicher Spalten im Ruhezustand.