Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server
SQL Server![]() Azure SQL-Datenbank
Azure SQL-Datenbank![]() Verwaltete Azure SQL-Instanz
Verwaltete Azure SQL-Instanz![]() SQL-Datenbank in Microsoft Fabric
SQL-Datenbank in Microsoft Fabric
Das Entwerfen effizienter Indizes ist entscheidend, um eine gute Datenbank- und Anwendungsleistung zu erzielen. Fehlende Indizes, Überindizierungen oder schlecht gestaltete Indizes sind die wichtigsten Quellen von Problemen mit der Datenbankleistung.
In diesem Leitfaden werden die Indexarchitektur und die Grundlagen beschrieben und bewährte Methoden bereitgestellt, mit denen Sie effektive Indizes entwerfen können, um die Anforderungen Ihrer Anwendungen zu erfüllen.
Weitere Informationen zu verfügbaren Indextypen finden Sie unter "Indizes".
Dieses Handbuch behandelt folgende Typen von Indizes:
| Primäres Speicherformat | Indextyp |
|---|---|
| Datenträgerbasierter Rowstore | |
| Clustered | |
| Nonclustered | |
| Unique | |
| Filtered | |
| Columnstore | |
| Gruppierter Spaltenspeicher | |
| Nicht gruppierter Columnstore | |
| Memory-optimized | |
| Hash | |
| Speicheroptimierte nicht gruppierte |
Informationen über XML-Indizes finden Sie unter XML-Indizes (SQL Server) und Selektive XML-Indizes (SXI).
Weitere Informationen zu räumlichen Indizes finden Sie unter Übersicht über räumliche Indizes.
Informationen zu Volltextindizes finden Sie unter Auffüllen von Volltextindizes.
Indexgrundlagen
Am Ende eines guten Sachbuchs befindet sich meist ein Index, über den bestimmte Informationen schnell und zielsicher innerhalb des Buchs ausfindig gemacht werden können. Ein Index ist eine sortierte Liste von Schlüsselwörtern, neben denen jeweils eine oder mehrere Seitenzahlen auf die Seiten verweisen, auf denen das jeweilige Schlüsselwort gefunden werden kann.
Ein Rowstore-Index ist ähnlich: Es handelt sich um eine sortierte Liste von Werten und für jeden Wert gibt es Zeiger auf die Datenseiten , auf denen sich diese Werte befinden. Der Index selbst wird auch auf Seiten gespeichert, die als Indexseiten bezeichnet werden. Wenn sich der Index in einem regulären Buch über mehrere Seiten erstreckt und Sie Zeiger auf alle Seiten suchen müssen, die das Wort SQL enthalten, müssen Sie vom Anfang des Indexes blättern, bis Sie die Seite finden, die das Schlüsselwort SQL enthält. Von dort gelangen Sie dann über die Zeiger zu den angegebenen Buchseiten. Dies ließe sich durch Hinzufügen einer Seite vor dem Index optimieren, auf der die Seitenzahlen für die einzelnen Buchstaben des Alphabets angegeben werden. Zum Beispiel: „A bis D: Seite 121“, „E bis G: Seite 122“ usw. Mit dieser weiteren Seite entfiele der Schritt, den Index nach dem Ausgangspunkt durchsuchen zu müssen. Eine solche Seite existiert in einem normalen Buch meist nicht, in einem Rowstore-Index jedoch schon. Sie wird als Stammseite des Index bezeichnet. Die Stammseite ist die Startseite der Baumstruktur, die von einem Index verwendet wird. Folgt man der Baumanalogie, so werden die Seiten mit den Zeigern auf die jeweiligen Daten als „Blattseiten“ der Baumstruktur bezeichnet.
Ein Index ist eine Struktur auf dem Datenträger oder im Arbeitsspeicher, die einer Tabelle oder einer Sicht zugeordnet ist und durch die das Abrufen von Zeilen aus der Tabelle oder Sicht beschleunigt wird. Ein Rowstore-Index enthält Schlüssel, die aus den Werten in einer oder mehreren Spalten in der Tabelle oder Ansicht erstellt wurden. Bei Zeilenladung-Indizes werden diese Schlüssel in einer Baumstruktur (B+ Baum) gespeichert, mit der das Datenbankmodul schnell und effizient die Zeilen finden kann, die den Schlüsselwerten zugeordnet sind.
Ein Zeilenspeicherindex speichert Daten logisch als Tabelle mit Zeilen und Spalten und wird physisch in einem zeilenweisen Datenformat namens Rowstore1 gespeichert. Es gibt eine alternative Möglichkeit, Daten spaltenweise zu speichern, genannt Columnstore.
Der Entwurf der richtigen Indizes für eine Datenbank und deren Workload ist ein komplexer Ausgleich zwischen Abfragegeschwindigkeit, Indexaktualisierungskosten und Speicherkosten. Schmale datenträgerbasierte Rowstore-Indizes oder Indizes mit wenigen Spalten im Indexschlüssel erfordern weniger Speicherplatz und einen geringeren Updateaufwand. Breite Indizes hingegen können mehr Abfragen verbessern. Möglicherweise müssen Sie mit mehreren verschiedenen Designs experimentieren, bevor Sie den effizientesten Satz von Indizes finden. Während sich die Anwendung weiterentwickelt, müssen sich Indizes möglicherweise ändern, um eine optimale Leistung zu gewährleisten. Indizes können hinzugefügt, geändert und entfernt werden, ohne dass sich dies auf das Datenbankschema oder den Anwendungsentwurf auswirkt. Daher sollten Sie in jedem Fall mit verschiedenen Indizes experimentieren.
Der Abfrageoptimierer im Datenbankmodul wählt in der Regel die effektivsten Indizes aus, um eine Abfrage auszuführen. Um zu sehen, welche Indizes der Abfrageoptimierer für eine bestimmte Abfrage verwendet, wählen Sie in SQL Server Management Studio im Menü "Abfrage " die Option "Geschätzten Ausführungsplan anzeigen " oder "Ist-Ausführungsplan einschließen" aus.
Setzen Sie Indexverwendung aber nicht stets mit gutem Leistungsverhalten bzw. gute Leistung mit effizienter Indexverwendung gleich. Würde durch die Verwendung eines Indexes in jedem Fall die beste Leistung erzielt, so wäre die Arbeit des Abfrageoptimierers sehr einfach. Tatsächlich kann die Auswahl eines falschen Indexes eine Leistung bewirken, die nicht optimal ist. Daher besteht die Aufgabe des Abfrageoptimierrs darin, einen Index oder eine Kombination aus Indizes auszuwählen, nur wenn die Leistung verbessert wird, und um den indizierten Abruf zu vermeiden, wenn die Leistung beeinträchtigt wird.
Ein häufiger Entwurfsfehler besteht darin, viele Indizes spekulativ zu erstellen, um "den Optimierer auswahlmöglichkeiten zu geben". Die resultierende Überindizierung verlangsamt Datenänderungen und kann Parallelitätsprobleme verursachen.
1 Rowstore stellte die herkömmliche Vorgehensweise beim Speichern von Daten aus relationalen Tabellen dar. Rowstore bezieht sich auf eine Tabelle, in der das zugrunde liegende Datenspeicherformat ein Heap, eine B+-Struktur (gruppierter Index) oder eine speicheroptimierte Tabelle ist. Datenträgerbasierter Rowstore schließt speicheroptimierte Tabellen aus.
Aufgaben beim Indexentwurf
Die folgenden Aufgaben stellen die empfohlene Strategie zum Entwerfen von Indizes dar:
Grundlegendes zu den Merkmalen der Datenbank und der Anwendung.
In einer OLTP-Datenbank (Online Transaction Processing) mit häufigen Datenänderungen, die einen hohen Durchsatz gewährleisten müssen, wäre ein paar schmale Rowstoreindizes, die für die wichtigsten Abfragen vorgesehen sind, ein guter anfänglicher Indexentwurf. Für extrem hohen Durchsatz sollten Sie speicheroptimierte Tabellen und Indizes in Betracht ziehen, die ein design mit weder Sperren noch Latches bieten. Weitere Informationen finden Sie in diesem Handbuch unter speicheroptimierte, nicht gruppierte Indexentwurfsrichtlinien und Hashindex-Entwurfsrichtlinien .
Umgekehrt wäre für eine OlAP-Datenbank (Analytics or Data Warehouse), die sehr große Datasets schnell verarbeiten muss, besonders geeignet, gruppierte Columnstore-Indizes zu verwenden. Weitere Informationen finden Sie unter Columnstore-Indizes: Übersicht oder Columnstore-Indexarchitektur in diesem Handbuch.
Grundlegendes zu den Merkmalen der am häufigsten verwendeten Abfragen.
Wenn Sie beispielsweise wissen, dass eine häufig verwendete Abfrage zwei oder mehr Tabellen verknüpft, können Sie die Indizes für diese Tabellen ermitteln.
Verstehen der Datenverteilung in den Spalten, die in den Abfrage-Prädikaten verwendet werden.
Beispielsweise kann ein Index für Spalten mit vielen unterschiedlichen Datenwerten nützlich sein, aber weniger für Spalten mit vielen doppelten Werten. Bei Spalten mit vielen NULLs oder Spalten mit klar definierten Teilmengen von Daten können Sie einen gefilterten Index verwenden. Weitere Informationen finden Sie unter Richtlinien für den Entwurf gefilterter Indizes in diesem Handbuch.
Bestimmen Sie, welche Indexoptionen die Leistung verbessern können.
Beispielsweise könnte das Erstellen eines gruppierten Indexes für eine vorhandene große Tabelle von der
ONLINEIndexoption profitieren. DieONLINE-Option ermöglicht, dass gleichzeitige Aktivitäten für die zugrunde liegenden Daten fortgesetzt werden können, während der Index erstellt oder neu erstellt wird. Die Verwendung der Datenkomprimierung von Zeilen- oder Seitendaten kann die Leistung verbessern, indem der E/A-Speicherbedarf des Indexes reduziert wird. Weitere Informationen finden Sie unter CREATE INDEX.Untersuchen Sie vorhandene Indizes in der Tabelle, um zu verhindern, dass doppelte oder sehr ähnliche Indizes erstellt werden.
Häufig ist es besser, einen vorhandenen Index zu ändern, als einen neuen, aber meist doppelten Index zu erstellen. Erwägen Sie z. B. das Hinzufügen von mindestens zwei zusätzlichen Spalten zu einem vorhandenen Index, anstatt einen neuen Index mit diesen Spalten zu erstellen. Dies ist besonders relevant, wenn Sie nicht gruppierte Indizes mit fehlenden Indexvorschlägen optimieren oder wenn Sie den Datenbankmoduloptimierungsratgeber verwenden, wo Sie möglicherweise ähnliche Variationen von Indizes in derselben Tabelle und Spalten anbieten.
Allgemeine Richtlinien für den Indexentwurf
Wenn Sie die Merkmale Ihrer Datenbank, Abfragen und Tabellenspalten verstehen, können Sie zunächst optimale Indizes entwerfen und den Entwurf ändern, während sich Ihre Anwendungen entwickeln.
Überlegungen zur Datenbank
Beachten Sie beim Entwerfen eines Indexes die folgenden Datenbankrichtlinien:
Eine große Anzahl von Indizes in einer Tabelle wirkt sich auf die Leistung von
INSERT,UPDATE,DELETEundMERGE-Anweisungen aus, da sich die Daten in den Indizes möglicherweise ändern müssen, wenn sich die Daten in der Tabelle ändern. Wenn beispielsweise eine Spalte in mehreren Indizes verwendet wird und Sie eineUPDATEAnweisung ausführen, die die Daten dieser Spalte ändert, muss jeder Index, der diese Spalte enthält, ebenfalls aktualisiert werden.Vermeiden Sie die zu starke Indizierung häufig aktualisierter Tabellen, und halten Sie die Indizes schmal, d. h., verwenden Sie so wenig Spalten wie möglich.
Sie können mehr Indizes für Tabellen haben, die nur wenige Datenänderungen, aber große Datenmengen aufweisen. Bei solchen Tabellen kann eine Vielzahl von Indizes die Abfrageleistung unterstützen, während der Indexaktualisierungsaufwand akzeptabel bleibt. Erstellen Sie jedoch keine Indizes spekulativ. Überwachen sie die Indexverwendung, und entfernen Sie nicht verwendete Indizes im Laufe der Zeit.
Die Indizierung kleiner Tabellen ist möglicherweise nicht optimal, da das Datenbankmodul länger für die Durchsuchung des Indexes nach Daten benötigen kann als für das Scannen der Basistabelle. Daher können Indizes für kleine Tabellen niemals verwendet werden, müssen aber trotzdem aktualisiert werden, da die Daten in der Tabelle aktualisiert werden.
Indizes für Ansichten können erhebliche Leistungssteigerungen bieten, wenn die Ansicht Aggregationen und/oder Verknüpfungen enthält. Weitere Informationen finden Sie unter Erstellen von indizierten Ansichten.
Datenbanken auf primären Replikaten in Azure SQL-Datenbank generieren automatisch Database Advisor-Empfehlungen zur Leistung für Indizes. Sie können optional die automatische Indexoptimierung aktivieren.
Der Abfragespeicher hilft beim Identifizieren von Abfragen mit suboptimaler Leistung und bietet einen Verlauf der Abfrageausführungspläne , mit denen Sie die vom Optimierer ausgewählten Indizes sehen können. Sie können diese Daten verwenden, um Ihre Indexoptimierungsänderungen am wirkungsvollsten zu gestalten, indem Sie sich auf die am häufigsten verwendeten und ressourcenaufwendigen Abfragen konzentrieren.
Überlegungen zur Abfrage
Beachten Sie beim Entwerfen eines Indexes die folgenden Abfragerichtlinien:
Erstellen Sie nicht gruppierte Indizes für die Spalten, die häufig in Prädikaten verwendet werden, und verbinden Sie Ausdrücke in Abfragen. Dies sind Ihre SARGable Spalten. Sie sollten jedoch vermeiden, unnötige Spalten zu Indizes hinzuzufügen. Das Hinzufügen zu vieler Indexspalten kann sich negativ auf speicherplatz- und Indexaktualisierungsleistung auswirken.
Der Begriff SARGable in relationalen Datenbanken bezieht sich auf ein SarchARGumentfähiges Prädikat, das einen Index verwenden kann, um die Ausführung der Abfrage zu beschleunigen. Weitere Informationen finden Sie in der SQL Server- und Azure SQL-Indexarchitektur und im Entwurfshandbuch.
Tip
Stellen Sie immer sicher, dass die von Ihnen erstellten Indizes tatsächlich von der Abfrageworkload verwendet werden. Nicht verwendete Indizes ablegen.
Indexverwendungsstatistiken sind in sys.dm_db_index_usage_stats und sys.dm_db_index_operational_stats verfügbar.
Abdeckende Indizes können die Abfrageleistung steigern, weil alle Daten im Index selbst enthalten sind, die die Anforderungen der Abfrage erfüllen. Auf diese Weise muss nur auf die Indexseiten und nicht auf die Datenseiten der Tabelle oder des gruppierten Indexes verwiesen werden, um die abgefragten Daten abzurufen, wodurch der Umfang der E/A-Operationen des Datenträgers verringert wird. Beispielsweise kann eine Abfrage der Spalten
AundBfür eine Tabelle, die über einen für die SpaltenA,BundCerstellten zusammengesetzten Index verfügt, die angegebenen Daten ausschließlich aus dem Index abrufen.Note
Ein verdeckter Index ist ein nicht gruppierter Index , der den gesamten Datenzugriff durch eine Abfrage direkt ohne Zugriff auf die Basistabelle erfüllt.
Solche Indizes weisen alle erforderlichen SARGable-Spalten im Indexschlüssel und nicht SARG-fähige Spalten als eingefügte Spalten auf. Dies bedeutet, dass alle Spalten, die von der Abfrage benötigt werden, entweder in den
WHERE,JOINundGROUP BYKlauseln oder in denSELECTOder-KlauselnUPDATE, im Index vorhanden sind.Es kann deutlich weniger Eingabe/Ausgabe erforderlich sein, um die Abfrage auszuführen, wenn der Index im Vergleich zu den Zeilen und Spalten der Tabelle hinreichend schmal ist, was bedeutet, dass er eine kleine Teilmenge aller Spalten darstellt.
Erwägen Sie, Indizes beim Abrufen eines kleinen Teils einer großen Tabelle zu behandeln und dort, wo dieser kleine Teil durch ein festes Prädikat definiert wird.
Vermeiden Sie das Erstellen eines deckenden Indexes mit zu vielen Spalten, da dadurch der Nutzen verringert wird, während datenbankspeicher, E/A und Speicherbedarf aufgeblasen werden.
Schreiben Sie Abfragen, die möglichst viele Zeilen in einer einzigen Anweisung einfügen oder ändern, anstatt mehrere Abfragen zum Aktualisieren der gleichen Zeilen zu verwenden. Dadurch wird der Aufwand für die Indexaktualisierung reduziert.
Überlegungen zur Spalte
Beachten Sie beim Entwerfen eines Indexes die folgenden Spaltenrichtlinien:
Halten Sie die Länge des Indexschlüssels kurz, insbesondere für gruppierte Indizes.
Spalten, die den Datentyp "ntext", "text", " image", "varchar(max)", "nvarchar(max)", "varbinary(max)", "json" und " vector " aufweisen, können nicht als Indexschlüsselspalten angegeben werden. Spalten mit diesen Datentypen können jedoch einem nicht gruppierten Index als nicht schlüsselbasierte (eingeschlossene) Indexspalten hinzugefügt werden. Weitere Informationen finden Sie im Abschnitt "Verwenden von enthaltenen Spalten in nicht gruppierten Indizes in diesem Handbuch".
Überprüfen Sie die Eindeutigkeit der Spalten. Ein eindeutiger Index anstelle eines nicht eindeutigen Indexes in denselben Schlüsselspalten stellt zusätzliche Informationen für den Abfrageoptimierer bereit, der den Index nützlicher macht. Weitere Informationen finden Sie unter Richtlinien zum Entwerfen eindeutiger Indizes in diesem Handbuch.
Überprüfen Sie die Datenverteilung in der Spalte. Das Erstellen eines Indexes für eine Spalte mit vielen Zeilen, aber wenigen unterschiedlichen Werten könnte die Abfrageleistung möglicherweise nicht verbessern, selbst wenn der Index vom Abfrageoptimierer verwendet wird. Analog dazu löst ein physisches Telefonverzeichnis, das alphabetisch nach Familiennamen sortiert ist, nicht die Suche nach einer Person aus, wenn alle Personen in der Stadt Smith oder Jones genannt werden. Weitere Informationen zur Datenverteilung finden Sie unter Statistics.
Erwägen Sie die Verwendung gefilterter Indizes für Spalten mit klar definierten Teilmengen, z. B. Spalten mit vielen NULLs, Spalten mit Wertekategorien und Spalten mit unterschiedlichen Wertebereichen. Ein gut durchdachter gefilterter Index kann die Abfrageleistung verbessern, die Kosten für Indexaktualisierungen reduzieren und Speicherkosten reduzieren, indem eine kleine Teilmenge aller Zeilen in der Tabelle gespeichert wird, wenn diese Teilmenge für viele Abfragen relevant ist.
Berücksichtigen Sie die Reihenfolge der Indexschlüsselspalten, wenn der Schlüssel mehrere Spalten enthält. Die Spalte, die im Abfrage-Prädikat in einem Gleichheitsausdruck (
=), Ungleichheitsausdruck (>,>=,<,<=,BETWEEN) verwendet wird oder an einem Join teilnimmt, sollte zuerst stehen. Die Reihenfolge zusätzlicher Spalten sollte basierend auf dem Grad ihrer Eindeutigkeit, d. h. von der eindeutigsten Spalte absteigend zu der am wenigsten eindeutigen Spalte, ausgewählt werden.Wenn der Index z. B. als
LastName,FirstNamedefiniert ist, ist der Index nützlich, wenn das Abfrageprädikat in derWHERE-KlauselWHERE LastName = 'Smith'oderWHERE LastName = Smith AND FirstName LIKE 'J%'lautet. Der Abfrageoptimierer würde jedoch nicht den Index für eine Abfrage verwenden, für die nurWHERE FirstName = 'Jane'gesucht wurde, oder der Index würde die Leistung einer solchen Abfrage nicht verbessern.Erwägen Sie die Indizierung berechneter Spalten, wenn sie in Abfrage-Prädikate enthalten sind. Weitere Informationen finden Sie unter Indexes on Computed Columns.
Indexmerkmale
Wenn sich herausgestellt hat, dass ein Index für eine Abfrage geeignet ist, können Sie den Indextyp auswählen, der für die jeweilige Situation am besten geeignet ist. Zu den Indexmerkmalen gehören:
- Gruppiert oder nicht gruppiert
- Eindeutig oder nicht eindeutig
- Einzelne Spalte oder mehrspaltig
- Aufsteigende oder absteigende Reihenfolge für die Schlüsselspalten im Index
- Alle Zeilen oder gefiltert, für nicht-geclusterte Indizes
- Columnstore oder Rowstore
- Hash oder nicht gruppiert für speicheroptimierte Tabellen
Indexplatzierung in Dateigruppen oder Partitionsschemas
Bei der Entwicklung einer Indexentwurfsstrategie sollten Sie die Platzierung der Indizes in den Dateigruppen berücksichtigen, die der Datenbank zugeordnet sind.
Indizes werden standardmäßig in derselben Dateigruppe wie die Basistabelle (gruppierter Index oder Heap) gespeichert, auf der der Index erstellt wird. Andere Konfigurationen sind möglich, darunter:
Erstellen Sie nicht gruppierte Indizes in einer anderen Dateigruppe als der Dateigruppe der Basistabelle.
Partitionieren von gruppierten und nicht gruppierten Indizes, damit diese mehrere Dateigruppen umfassen.
Bei nicht partitionierten Tabellen ist der einfachste Ansatz in der Regel am besten: Erstellen Sie alle Tabellen in derselben Dateigruppe, und fügen Sie der Dateigruppe so viele Datendateien hinzu, wie erforderlich, um den gesamten verfügbaren physischen Speicher zu nutzen.
Komplexere Indexplatzierungsansätze können berücksichtigt werden, wenn mehrstufiger Speicher verfügbar ist. Sie können beispielsweise eine Dateigruppe für häufig verwendete Tabellen mit Dateien auf schnelleren Datenträgern und eine Dateigruppe für Archivtabellen auf langsameren Datenträgern erstellen.
Sie können eine Tabelle mit einem gruppierten Index aus einer Dateigruppe in eine andere verschieben, indem Sie den gruppierten Index ablegen und ein neues Dateigruppen- oder Partitionsschema in der MOVE TO Klausel der DROP INDEX Anweisung angeben oder die Anweisung mit der CREATE INDEXDROP_EXISTING Klausel verwenden.
Partitionierten Indizes
Sie können auch erwägen, festplattenbasierte Heaps, gruppierte und nicht gruppierte Indizes über mehrere Dateigruppen hinweg zu partitionieren. Partitionierte Indizes werden horizontal (zeilenweise) basierend auf einer Partitionsfunktion gegliedert. Die Partitionsfunktion definiert, wie jede Zeile einer Partition zugeordnet wird, basierend auf den Werten einer bestimmten Spalte, die Sie festlegen, als Partitionierungsspalte bezeichnet wird. Ein Partitionsschema gibt die Zuordnung einer Gruppe von Partitionen zu einer Dateigruppe an.
Das Partitionieren eines Indexes kann die folgenden Vorteile bieten:
Sorgen Sie dafür, dass große Datenbanken besser verwaltbar sind. OLAP-Systeme können z. B. partitionsfähige ETL implementieren, die das Hinzufügen und Entfernen von Daten in Massen erheblich vereinfacht.
Sorgen Sie dafür, dass bestimmte Arten von Abfragen, wie lang laufende analytische Abfragen, schneller ausgeführt werden. Wenn Abfragen einen partitionierten Index verwenden, kann das Datenbankmodul mehrere Partitionen gleichzeitig verarbeiten und Partitionen überspringen (entfernen), die von der Abfrage nicht benötigt werden.
Warnung
Die Partitionierung verbessert selten die Abfrageleistung in OLTP-Systemen, kann aber einen erheblichen Aufwand verursachen, wenn eine Transaktionsabfrage auf viele Partitionen zugreifen muss.
Weitere Informationen finden Sie unter partitionierte Tabellen und Indizes.
Entwurfsrichtlinien zur Sortierreihenfolge von Indizes
Berücksichtigen Sie beim Definieren von Indizes, ob jede Indexschlüsselspalte in aufsteigender oder absteigender Reihenfolge gespeichert werden soll. Die Standardeinstellung ist aufsteigend. Die Syntax der CREATE INDEX, CREATE TABLE und ALTER TABLE-Anweisungen unterstützt die Schüsselwörter ASC (aufsteigend) und DESC (absteigend) für einzelne Spalten in Indizes und Einschränkungen.
Das Angeben der Reihenfolge, in der die Schlüsselwerte in einem Index gespeichert werden, ist sinnvoll, wenn Abfragen, die auf die Tabelle verweisen, über ORDER BY-Klauseln verfügen, die verschiedene Richtungen für die Schlüsselspalten in dem entsprechenden Index angeben. In diesen Fällen kann der Index die Notwendigkeit eines Sortieroperators im Abfrageplan entfernen.
Die Mitarbeiter der Einkaufsabteilung von Adventure Works Cycles müssen beispielsweise die Qualität der Produkte, die sie von den Anbietern kaufen, bewerten. Die Käufer sind am meisten daran interessiert, Produkte zu finden, die von Anbietern mit einer hohen Ablehnungsrate gesendet werden.
Wie in der folgenden Abfrage für die AdventureWorks-Beispieldatenbank gezeigt, muss zum Abrufen der Daten, die diese Kriterien erfüllen, die RejectedQty-Spalte in der Purchasing.PurchaseOrderDetail-Tabelle in absteigender Reihenfolge (von groß nach klein) und die ProductID-Spalte in aufsteigender Reihenfolge (von klein nach groß) sortiert werden.
SELECT RejectedQty,
((RejectedQty / OrderQty) * 100) AS RejectionRate,
ProductID,
DueDate
FROM Purchasing.PurchaseOrderDetail
ORDER BY RejectedQty DESC, ProductID ASC;
Der folgende Ausführungsplan für diese Abfrage zeigt, dass der Abfrageoptimierer einen Sortieroperator verwendet hat, um das Resultset in der durch die ORDER BY Klausel angegebenen Reihenfolge zurückzugeben.

Wenn ein datenträgerbasierter Rowstore-Index mit Schlüsselspalten erstellt wird, die denen in der ORDER BY Abfrage entsprechen, wird der Sortieroperator im Abfrageplan eliminiert, wodurch der Abfrageplan effizienter wird.
CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail
(RejectedQty DESC, ProductID ASC, DueDate, OrderQty);
Nachdem die Abfrage erneut ausgeführt wurde, zeigt der folgende Ausführungsplan an, dass der Sortieroperator nicht mehr vorhanden ist und der neu erstellte nicht gruppierte Index verwendet wird.
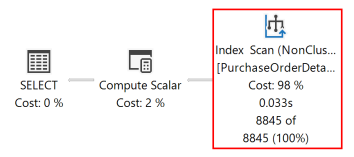
Das Datenbankmodul kann einen Index in beide Richtungen scannen. Ein Index, der als RejectedQty DESC, ProductID ASC definiert ist, kann weiterhin für eine Abfrage verwendet werden, in der die Sortierrichtungen der Spalten in der ORDER BY-Klausel umgekehrt sind. Beispielsweise kann eine Abfrage mit der ORDER BY Klausel ORDER BY RejectedQty ASC, ProductID DESC denselben Index verwenden.
Die Sortierreihenfolge kann nur für die Schlüsselspalten im Index angegeben werden. Die sys.index_columns Katalogansicht meldet, ob eine Indexspalte in aufsteigender oder absteigender Reihenfolge gespeichert ist.
Richtlinien für das Design von gruppierten Indizes
Der gruppierte Index speichert alle Zeilen und alle Spalten einer Tabelle. Zeilen werden in der Reihenfolge der Indexschlüsselwerte sortiert. Pro Tabelle kann nur ein gruppierter Index vorhanden sein.
Die Basistabelle bezieht sich entweder auf einen gruppierten Index oder auf einen Heap. Ein Heap ist eine unsortierte Datenstruktur auf dem Datenträger, die alle Zeilen und alle Spalten einer Tabelle enthält.
Mit wenigen Ausnahmen sollte jede Tabelle über einen gruppierten Index verfügen. Die wünschenswerten Eigenschaften des gruppierten Indexes sind:
| Eigentum | Description |
|---|---|
| Schmal | Der gruppierte Indexschlüssel ist Teil eines nicht gruppierten Indexes in derselben Basistabelle. Ein schmaler Schlüssel oder ein Schlüssel, bei dem die Gesamtlänge der Schlüsselspalten klein ist, reduziert den Speicher-, E/A- und Speicheraufwand aller Indizes einer Tabelle. Um die Schlüssellänge zu berechnen, addieren Sie die Speichergrößen für die Datentypen, die von Schlüsselspalten verwendet werden. Weitere Informationen finden Sie unter "Datentypkategorien". |
| Einzigartig | Wenn der gruppierte Index nicht eindeutig ist, wird dem Indexschlüssel automatisch eine interne 4-Byte-Eindeutigkeitsspalte hinzugefügt, um die Eindeutigkeit sicherzustellen. Durch das Hinzufügen einer vorhandenen eindeutigen Spalte zum gruppierten Indexschlüssel wird der Speicher-, E/A- und Arbeitsspeicheraufwand durch die Uniqueifier-Spalte in allen Indizes einer Tabelle vermieden. Darüber hinaus kann der Abfrageoptimierer effizientere Abfragepläne generieren, wenn ein Index eindeutig ist. |
| Immer größer | In einem immer größer werdenden Index werden daten immer auf der letzten Seite des Indexes hinzugefügt. Dadurch werden Seitenaufteilungen in der Mitte des Indexes vermieden, wodurch die Seitendichte reduziert und die Leistung verringert wird. |
| Unveränderbar | Der gruppierte Indexschlüssel ist Teil eines nicht gruppierten Indexes. Wenn eine Schlüsselspalte eines gruppierten Indexes geändert wird, muss auch eine Änderung in allen nicht gruppierten Indizes vorgenommen werden, wodurch ein CPU-, Protokollierungs-, E/A- und Speicheraufwand hinzugefügt wird. Der Aufwand wird vermieden, wenn die Schlüsselspalten des gruppierten Indexes unveränderlich sind. |
| Hat nur nicht-nullbare Spalten. | Wenn eine Zeile nullfähige Spalten enthält, muss sie eine interne Struktur enthalten, die als NULL-Block bezeichnet wird, wodurch 3 bis 4 Byte Speicher pro Zeile in einem Index hinzugefügt werden. Wenn sie alle Spalten des gruppierten Indexes nicht nullfähig machen, wird dieser Aufwand vermieden. |
| Hat nur Spalten mit fester Breite | Spalten mit Datentypen mit variabler Breite, z. B. varchar oder nvarchar , verwenden im Vergleich zu Datentypen mit fester Breite zusätzliche 2 Bytes pro Wert. Die Verwendung von Datentypen mit fester Breite wie int vermeidet diesen Aufwand in allen Indizes in der Tabelle. |
Die Erfüllung so vieler dieser Eigenschaften wie möglich beim Entwerfen eines gruppierten Indexes macht nicht nur den gruppierten Index, sondern auch alle nicht gruppierten Indizes auf derselben Tabelle effizienter. Die Leistung wird verbessert, indem Speicheroverheads, Ein-/Ausgabe- und Speicherverbrauch vermieden werden.
Beispielsweise weist ein gruppierter Indexschlüssel mit einer einzelnen Int- oder BigInt-Spalte, die nicht nullfähig ist, alle diese Eigenschaften auf, wenn er durch eine IDENTITY Klausel oder eine Standardeinschränkung unter Nutzung einer Sequenz aufgefüllt wird und nach dem Einfügen einer Zeile nicht mehr aktualisiert wird.
Umgekehrt ist ein gruppierter Indexschlüssel mit einer einzigen eindeutigen Identifikationsspalte breiter, da er 16 Bytes Speicher anstelle von 4 Bytes für int und 8 Bytes für Bigint verwendet und die immer größer werdende Eigenschaft nicht erfüllt, es sei denn, die Werte werden sequenziell generiert.
Tip
Wenn Sie eine PRIMARY KEY Einschränkung erstellen, wird automatisch ein eindeutiger Index erstellt, der die Einschränkung unterstützt. Standardmäßig ist dieser Index gruppiert. Wenn dieser Index jedoch nicht die gewünschten Eigenschaften des gruppierten Indexes erfüllt, können Sie die Einschränkung als nicht gruppiert erstellen und stattdessen einen anderen gruppierten Index erstellen.
Wenn Sie keinen gruppierten Index erstellen, wird die Tabelle als Heap gespeichert, was im Allgemeinen nicht empfohlen wird.
Architektur gruppierter Indizes
Rowstore-Indizes sind als B+-Strukturen organisiert. Jede Seite der B+-Struktur eines Indexes wird als Indexknoten bezeichnet. Der oberste Knoten der B+-Struktur wird als Stammknoten bezeichnet. Die unteren Knoten im Index werden als Blattknoten bezeichnet. Alle anderen Indexebenen zwischen dem Stamm- und den Blattknoten werden zusammenfassend als Zwischenebenen bezeichnet. In einem gruppierten Index enthalten die Blattknoten die Datenseiten der zugrunde liegenden Tabelle. Die Stamm- und Zwischenebenenknoten enthalten Indexseiten, in denen Indexzeilen enthalten sind. Jede Indexzeile enthält einen Schlüsselwert und einen Zeiger auf eine Seite einer Zwischenebene in der B+-Struktur oder auf eine Datenzeile in der Blattebene des Indexes. Die Seiten auf jeder Ebene des Indexes sind durch eine doppelt verknüpfte Liste miteinander verknüpft.
Gruppierte Indizes haben eine Zeile in sys.partitions für jede Partition, die vom Index verwendet wird, mit index_id = 1. Standardmäßig besitzt ein gruppierter Index eine Partition. Wenn ein gruppierter Index über mehrere Partitionen verfügt, verfügt jede Partition über eine separate B+-Struktur, die die Daten für diese bestimmte Partition enthält. Wenn ein gruppierter Index beispielsweise vier Partitionen aufweist, gibt es vier B+-Strukturstrukturen, eine in jeder Partition.
Abhängig von den Datentypen im gruppierten Index weist jede gruppierte Indexstruktur eine oder mehrere Zuordnungseinheiten auf, in denen die Daten für eine bestimmte Partition gespeichert und verwaltet werden. Jeder gruppierte Index weist mindestens eine IN_ROW_DATA-Zuordnungseinheit pro Partition auf. Der gruppierte Index verfügt auch über eine LOB_DATA Zuordnungseinheit pro Partition, wenn sie große Objektspalten (LOB) enthält, z. B. nvarchar(max). Sie verfügt auch über eine ROW_OVERFLOW_DATA Zuordnungseinheit pro Partition, wenn sie Spalten mit variabler Länge enthält, die den Grenzwert für die Zeilengröße von 8.060 Byte überschreiten.
Die Seiten in der B+-Baumstruktur werden nach dem Wert des gruppierten Indexschlüssels sortiert. Alle Einfügungen werden auf der Seite vorgenommen, auf der der Schlüsselwert in der eingefügten Zeile in die Sortierreihenfolge zwischen vorhandenen Seiten passt. Innerhalb einer Seite werden Zeilen nicht unbedingt in einer physischen Reihenfolge gespeichert. Die Seite verwaltet jedoch eine logische Reihenfolge von Zeilen mithilfe einer internen Struktur, die als Slotarray bezeichnet wird. Einträge im Slotarray werden in der Indexschlüsselreihenfolge beibehalten.
Die folgende Abbildung veranschaulicht die Struktur eines gruppierten Indexes in einer einzelnen Partition.

Entwurfsrichtlinien nicht gruppierter Indizes
Der Hauptunterschied zwischen einem gruppierten und einem nicht gruppierten Index besteht darin, dass ein nicht gruppierter Index eine Teilmenge der Spalten in der Tabelle enthält, in der Regel anders sortiert als der gruppierte Index. Optional kann ein nicht gruppierter Index gefiltert werden, was bedeutet, dass er eine Teilmenge aller Zeilen in der Tabelle enthält.
Ein festplattenbasierter nicht gruppierter Zeilen-Index enthält die Zeilenlocatoren, die auf den Speicherort der Zeile in der Basistabelle verweisen. Sie können mehrere nicht gruppierte Indizes für eine Tabelle oder eine indizierte Sicht erstellen. Im Allgemeinen sollten nicht gruppierte Indizes entwickelt werden, um die Leistung häufig verwendeter Abfragen zu verbessern, die andernfalls die Basistabelle scannen müssen.
Vergleichbar mit der Art und Weise wie Sie einen Index in einem Buch verwenden, sucht der Abfrageoptimierer nach einem Datenwert, indem er den nicht gruppierten Index durchsucht, um so den Speicherort des Datenwerts in der Tabelle zu ermitteln. Anschließend werden die Daten direkt von diesem Speicherort abgerufen. Aus diesem Grund sind nicht gruppierte Indizes optimal für Abfragen geeignet, die nach genauen Übereinstimmungen suchen, da der Index Einträge enthält, die in der Tabelle den genauen Speicherort der Datenwerte beschreiben, die in den Abfragen gesucht werden.
Um z. B. die HumanResources.Employee Tabelle für alle Mitarbeiter abzufragen, die einem bestimmten Vorgesetzten melden, kann der Abfrageoptimierer den nicht gruppierten Index IX_Employee_ManagerIDverwenden. Dies hat ManagerID die erste Schlüsselspalte. Da die ManagerID Werte im nicht gruppierten Index sortiert sind, kann der Abfrageoptimierer schnell alle Einträge im Index finden, die dem angegebenen ManagerID Wert entsprechen. Jeder Indexeintrag verweist auf die genaue Seite und Zeile in der Basistabelle, in der die entsprechenden Daten aus allen anderen Spalten abgerufen werden können. Nachdem der Abfrageoptimierer alle Einträge im Index gefunden hat, kann er direkt zur genauen Seite und Zeile wechseln, um die Daten abzurufen, anstatt die gesamte Basistabelle zu scannen.
Architektur nicht gruppierter Indizes
Festplattenbasierte Rowstore-nicht-clustered-Indizes haben dieselbe B+-Baumstruktur wie geclusterte Indizes, mit den folgenden Unterschieden:
Ein nicht gruppierter Index enthält nicht unbedingt alle Spalten und Zeilen der Tabelle.
Die Blattebene eines nicht gruppierten Indexes besteht aus Indexseiten anstelle von Datenseiten. Die Indexseiten auf der Blattebene eines nicht gruppierten Indexes enthalten Schlüsselspalten. Optional können sie auch eine Teilmenge anderer Spalten in der Tabelle als eingeschlossene Spalten enthalten, um zu vermeiden, dass sie aus der Basistabelle abgerufen werden.
Die Zeilenlocatoren in nicht gruppierten Indexzeilen sind entweder ein Zeiger auf eine Zeile oder ein gruppierter Indexschlüssel für eine Zeile, wie folgt beschrieben:
Wenn die Tabelle einen gruppierten Index besitzt oder der Index für eine indizierte Sicht erstellt wurde, ist der Zeilenlokator der Schlüssel des gruppierten Indexes für die Zeile.
Wenn es sich bei der Tabelle um einen Heap handelt (d. h. sie hat keinen gruppierten Index), entspricht der Zeilenlokator einem Zeiger auf die Zeile. Der Zeiger setzt sich aus dem Dateibezeichner (ID), der Seitennummer und der Nummer der Zeile auf der Seite zusammen. Der ganze Zeiger wird als Zeilen-ID (RID) bezeichnet.
Zeilenlocators stellen auch die Eindeutigkeit für nicht gruppierte Indexzeilen sicher. In der folgenden Tabelle wird beschrieben, wie der Datenbank-Engine nicht gruppierten Indizes Zeilenlocators hinzufügt:
| Basistabellentyp | Nicht gruppierter Indextyp | Zeilenlocator |
|---|---|---|
| Heap | ||
| Nonunique | RID zu Schlüsselspalten hinzugefügt | |
| Unique | RID zu eingeschlossenen Spalten hinzugefügt | |
| Eindeutiger gruppierter Index | ||
| Nonunique | Gruppierte Indexschlüssel zu Schlüsselspalten hinzugefügt | |
| Unique | Gruppierte Indexschlüssel zu eingeschlossenen Spalten hinzugefügt | |
| Nicht eindeutiger gruppierter Index | ||
| Nonunique | Gruppierte Indexschlüssel und Uniqueifier (falls vorhanden) zu Schlüsselspalten hinzugefügt | |
| Unique | Gruppierte Indexschlüssel und Uniqueifier (falls vorhanden) zu eingeschlossenen Spalten hinzugefügt |
Das Datenbankmodul speichert niemals eine bestimmte Spalte mehr als einmal in einem nicht gruppierten Index. Die vom Benutzer beim Erstellen eines nicht gruppierten Indexes angegebene Indexreihenfolge wird immer berücksichtigt: Alle Zeilenlocatorspalten, die dem Schlüssel eines nicht gruppierten Indexes hinzugefügt werden müssen, werden am Ende des Schlüssels nach den in der Indexdefinition angegebenen Spalten hinzugefügt. Indizierte Zeilenzeiger von einem gruppierten Index in einem nicht gruppierten Index können bei der Abfrageverarbeitung verwendet werden, unabhängig davon, ob sie explizit in der Indexdefinition angegeben oder implizit hinzugefügt werden.
Die folgenden Beispiele zeigen, wie Zeilenlocators in nicht gruppierten Indizes implementiert werden:
| Gruppierter Index | Definition eines nicht gruppierten Index | Definition eines nicht gruppierten Index mit Zeilenlocators | Explanation |
|---|---|---|---|
Eindeutiger gruppierter Index mit Schlüsselspalten (A, B, C) |
Nicht eindeutiger und nicht gruppierter Index mit Schlüsselspalten (B, A) und eingeschlossenen Spalten (E, G) |
Schlüsselspalten (B, A, C) und eingeschlossene Spalten (E, G) |
Der nicht gruppierte Index ist nicht eindeutig, sodass der Zeilenlocator in den Indexschlüsseln vorhanden sein muss. Die Spalten B und A aus dem Zeilenlocator sind bereits vorhanden, sodass nur die Spalte C hinzugefügt wird. Die Spalte C wird am Ende der Schlüsselspaltenliste hinzugefügt. |
Eindeutiger gruppierter Index mit Schlüsselspalte (A) |
Nicht eindeutiger und nicht gruppierter Index mit Schlüsselspalten (B, C) und eingeschlossener Spalte (A) |
Schlüsselspalten (B, C, A) |
Der nicht gruppierte Index ist nicht eindeutig, sodass der Zeilenlocator dem Schlüssel hinzugefügt wird. Die Spalte A ist noch nicht als Schlüsselspalte angegeben und wird daher am Ende der Schlüsselspaltenliste hinzugefügt. Die Spalte A befindet sich jetzt im Schlüssel, sodass sie nicht als eingeschlossene Spalte gespeichert werden muss. |
Eindeutiger gruppierter Index mit Schlüsselspalte (A, B) |
Eindeutiger, nicht gruppierter Index mit Schlüsselspalten (C) |
Schlüsselspalte (C) und eingeschlossene Spalten (A, B) |
Der nicht gruppierte Index ist eindeutig, sodass der Zeilenlocator den eingeschlossenen Spalten hinzugefügt wird. |
Nicht gruppierte Indizes haben eine Zeile in sys.partitions für jede Partition, die vom Index verwendet wird, mit index_id > 1. Standardmäßig besitzen nicht gruppierte Indizes nur eine Partition. Wenn ein nicht gruppierter Index mehrere Partitionen umfasst, weist jede Partition eine B+-Struktur auf, die die Indexzeilen der spezifischen Partition enthält. Wenn beispielsweise ein nicht gruppierter Index vier Partitionen aufweist, gibt es vier B+-Strukturstrukturen, eine in jeder Partition.
Abhängig von den Datentypen des nicht gruppierten Indexes erhält jede Struktur mindestens eine Zuordnungseinheit, in der die Daten einer bestimmten Partition gespeichert und verwaltet werden. Mindestens verfügt jeder nicht gruppierte Index über eine IN_ROW_DATA Zuordnungseinheit pro Partition, die die Index-B+-Strukturseiten speichert. Der nicht gruppierte Index weist auch eine LOB_DATA Zuordnungseinheit pro Partition auf, wenn er spalten mit großen Objekten (LOB) wie nvarchar(max)enthält. Darüber hinaus verfügt sie über eine ROW_OVERFLOW_DATA Zuordnungseinheit pro Partition, wenn sie Spalten mit variabler Länge enthält, die den Grenzwert für die Zeilengröße von 8.060 Byte überschreiten.
Die folgende Abbildung veranschaulicht die Struktur eines gruppierten Indexes einer einzigen Partition.

Verwenden von eingeschlossenen Spalten in nicht gruppierten Indizes
Zusätzlich zu Schlüsselspalten kann ein nicht gruppierter Index auch Nichtschlüsselspalten enthalten, die auf der Blattebene gespeichert sind. Diese nicht schlüsselfreien Spalten werden als eingeschlossene Spalten bezeichnet und in der INCLUDE Klausel der CREATE INDEX Anweisung angegeben.
Ein Index mit eingeschlossenen nicht schlüsselfreien Spalten kann die Abfrageleistung erheblich verbessern, wenn sie die Abfrage abdeckt, d. h., wenn sich alle spalten, die in der Abfrage verwendet werden, entweder als Schlüssel- oder nichtschlüsselspalten im Index befinden. Leistungsgewinne werden erzielt, da das Datenbankmodul alle Spaltenwerte innerhalb des Indexes finden kann; auf die Basistabelle wird nicht zugegriffen, was zu weniger Datenträger-E/A-Vorgängen führt.
Wenn eine Spalte von einer Abfrage abgerufen werden muss, aber nicht in den Abfrage-Prädikaten, Aggregationen und Sortierungen verwendet wird, fügen Sie sie als eingeschlossene Spalte und nicht als Schlüsselspalte hinzu. Dies hat die folgenden Vorteile:
Eingeschlossene Spalten können Datentypen verwenden, die nicht als Indexschlüsselspalten zulässig sind.
Eingeschlossene Spalten werden beim Berechnen der Anzahl der Indexschlüsselspalten oder der Indexschlüsselgröße nicht vom Datenbankmodul berücksichtigt. Bei eingeschlossenen Spalten sind Sie nicht auf die maximale Größe von 900 Byte-Schlüsseln beschränkt. Sie können breitere Indizes erstellen, die weitere Abfragen abdecken.
Wenn Sie eine Spalte aus dem Indexschlüssel in eingeschlossene Spalten verschieben, dauert der Indexbuild weniger Zeit, da der Indexsortierungsvorgang schneller wird.
Wenn die Tabelle über einen gruppierten Index verfügt, werden die im gruppierten Indexschlüssel definierten Spalten automatisch jedem nicht eindeutigen nicht gruppierten Index der Tabelle hinzugefügt. Es ist nicht erforderlich, sie entweder im nicht gruppierten Indexschlüssel oder als eingeschlossene Spalten anzugeben.
Richtlinien für Indizes mit enthaltenen Spalten
Beachten Sie die folgenden Richtlinien, wenn Sie nicht gruppierte Indizes mit eingeschlossenen Spalten entwerfen:
Eingeschlossene Spalten können nur in nicht gruppierten Indizes für Tabellen oder indizierte Ansichten definiert werden.
Mit Ausnahme von text, ntextund imagesind alle Datentypen zulässig.
Bei berechneten Spalten, die deterministisch und präzise oder unpräzise sind, kann es sich um eingeschlossene Spalten handeln. Weitere Informationen finden Sie unter Indexes on Computed Columns.
Wie bei Schlüsselspalten können berechnete Spalten, die von den Datentypen image, ntext und text abgeleitet sind, als eingeschlossene Spalten verwendet werden, solange der Datentyp der berechneten Spalte in einer eingeschlossenen Spalte zulässig ist.
Spaltennamen dürfen nicht sowohl in der
INCLUDE-Liste als auch in der Schlüsselspaltenliste angegeben werden.Spaltennamen können nicht in der
INCLUDE-Liste wiederholt werden.Mindestens eine Schlüsselspalte muss in einem Index definiert werden. Die maximale Anzahl der enthaltenen Spalten beträgt 1.023. Dies ist die maximale Anzahl der Tabellenspalten minus 1.
Unabhängig vom Vorhandensein eingeschlossener Spalten müssen Indexschlüsselspalten die vorhandenen Einschränkungen für die Indexgröße von maximal 16 Schlüsselspalten und eine Gesamtgröße von 900 Byte entsprechen.
Designempfehlungen für Indizes mit enthaltenen Spalten
Erwägen Sie die Neugestaltung von nicht gruppierten Indizes mit einer großen Indexschlüsselgröße, sodass nur Spalten, die in Abfrage-Prädikaten, Aggregationen und Sortierungen verwendet werden, Schlüsselspalten sind. Erklären Sie alle anderen Spalten, die die Abfrage abdecken, zu eingeschlossenen Nichtschlüsselspalten. Auf diese Weise sind alle Spalten vorhanden, die zum Abdecken der Abfrage erforderlich sind, der Indexschlüssel selbst ist jedoch klein und effizient.
Angenommen, Sie möchten z. B. einen Index entwerfen, der die folgende Abfrage abdeckt:
SELECT AddressLine1,
AddressLine2,
City,
StateProvinceID,
PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N'98000' AND N'99999';
Damit die Abfrage abgedeckt wird, muss jede Spalte im Index definiert werden. Sie könnten zwar alle Spalten als Schlüsselspalten definieren, die Schlüsselgröße würde dann aber 334 Byte betragen. Da die einzige Spalte, die als Suchkriterium verwendet wird, die PostalCode -Spalte mit einer Länge von 30 Byte ist, definiert der bessere Indexentwurf PostalCode als Schlüsselspalte und schließt alle anderen Spalten als Nichtschlüsselspalten ein.
Die folgende Anweisung erstellt einen Index mit eingeschlossenen Spalten, um die Abfrage abzudecken:
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
Um zu überprüfen, ob der Index die Abfrage abdeckt, erstellen Sie den Index, und zeigen Sie dann den geschätzten Ausführungsplan an. Wenn der Ausführungsplan einen Index seek-Operator für den IX_Address_PostalCode Index anzeigt, wird die Abfrage vom Index abgedeckt.
Leistungsüberlegungen für Indizes mit eingeschlossenen Spalten
Vermeiden Sie das Erstellen von Indizes mit einer sehr großen Anzahl eingeschlossener Spalten. Obwohl der Index möglicherweise für mehr Abfragen abgedeckt wird, wird sein Leistungsvorteil verringert, da:
Es passen weniger Indexzeilen auf eine Seite. Dadurch wird die Datenträger-E/A erhöht und die Cacheeffizienz reduziert.
Zum Speichern des Indexes ist eine größere Menge an Speicherplatz erforderlich. Insbesondere das Hinzufügen von varchar(max), nvarchar(max), varbinary(max)- oder XML-Datentypen in enthaltenen Spalten kann den Speicherplatzbedarf erheblich erhöhen. Der Grund liegt darin, dass die Spaltenwerte in die Blattebene des Indexes kopiert werden. Daher werden sie sowohl im Index als auch in der Basistabelle gespeichert.
Die Leistung der Datenänderung verringert sich, da viele Spalten sowohl in der basierten Tabelle als auch im nicht gruppierten Index geändert werden müssen.
Sie müssen ermitteln, ob die Vorteile der Abfrageleistung den Rückgang der Datenänderungsleistung und die Erhöhung der Speicherplatzanforderungen überwiegen.
Entwurfsrichtlinien für eindeutige Indizes
Ein eindeutiger Index garantiert, dass der Indexschlüssel keine doppelten Werte enthält. Das Erstellen eines eindeutigen Indexes ist nur möglich, wenn die Eindeutigkeit ein Merkmal der Daten selbst ist. Wenn Sie z. B. sicherstellen möchten, dass die Werte in der NationalIDNumber -Spalte der HumanResources.Employee -Tabelle eindeutig sind, wenn der Primärschlüssel EmployeeIDentspricht, erstellen Sie eine UNIQUE-Einschränkung für die NationalIDNumber-Spalte. Die Einschränkung lehnt alle Versuche ab, Zeilen mit doppelten nationalen ID-Nummern einzuführen.
Durch eindeutige Indizes für mehrere Spalten stellt der Index sicher, dass jede Kombination der Werte in der indizierten Spalte eindeutig ist. Wenn beispielsweise ein eindeutiger Index in einer Kombination von LastName, FirstNameund MiddleName Spalten erstellt wird, könnten in der Tabelle keine zwei Zeilen dieselben Werte für diese Spalten aufweisen.
Sowohl gruppierte als auch nicht gruppierte Indizes können eindeutig sein. Sie können einen eindeutigen gruppierten Index und mehrere eindeutige nicht gruppierte Indizes in derselben Tabelle erstellen.
Zu den Vorteilen eindeutiger Indizes gehören:
- Geschäftsregeln, die die Eindeutigkeit von Daten erfordern, werden erzwungen.
- Es werden zusätzliche, für den Abfrageoptimierer hilfreiche Informationen bereitgestellt.
Durch das Erstellen einer PRIMARY KEY- oder einer UNIQUE-Einschränkung wird automatisch ein eindeutiger Index für die angegebenen Spalten erstellt. Es gibt keine deutlichen Unterschiede zwischen dem Erstellen einer UNIQUE-Einschränkung und dem Erstellen eines eindeutigen Indexes unabhängig von einer Einschränkung. Die Datenüberprüfung erfolgt auf dieselbe Weise, und der Abfrageoptimierer macht keinen Unterschied zwischen einem durch eine Einschränkung erstellten eindeutigen Index und einem manuell erstellten Index. Sie sollten jedoch eine UNIQUE Oder PRIMARY KEY Einschränkung für die Spalte erstellen, wenn die Durchsetzung von Geschäftsregeln das Ziel ist. Dadurch ist das Ziel des Indexes klar.
Überlegungen zu eindeutigen Indexen
Ein eindeutiger Index, die
UNIQUE-Einschränkung oder diePRIMARY KEY-Einschränkung kann nicht erstellt werden, wenn in den Daten doppelte Schlüsselwerte vorhanden sind.Wenn die Daten eindeutig sind und Sie die Eindeutigkeit erzwingen wollen, werden durch das Erstellen eines eindeutigen Indexes anstelle eines nicht eindeutigen Indexes für dieselbe Spaltenkombination zusätzliche Informationen für den Abfrageoptimierer bereitgestellt, mit deren Hilfe effizientere Ausführungspläne erstellt werden können. Das Erstellen einer
UNIQUEEinschränkung oder eines eindeutigen Indexes wird in diesem Fall empfohlen.Ein eindeutiger, nicht gruppierter Index kann eingeschlossene Nichtschlüsselspalten enthalten. Weitere Informationen finden Sie unter Verwenden von eingeschlossenen Spalten in nicht gruppierten Indizes.
Im Gegensatz zu einer
PRIMARY KEY-Einschränkung kann eineUNIQUE-Einschränkung oder ein eindeutiger Index mit einer nullable Spalte im Indexschlüssel erstellt werden. Für die Zwecke der Eindeutigkeitserzwingung gelten zwei NULLs als gleich. Dies bedeutet beispielsweise, dass die Spalte in einem einspaltigen eindeutigen Index nur für eine Zeile in der Tabelle NULL sein kann.
Entwurfsrichtlinien für gefilterte Indizes
Ein gefilterter Index ist ein optimierter nicht gruppierter Index, der insbesondere für Abfragen geeignet ist, die eine kleine Teilmenge von Daten in der Tabelle erfordern. Es verwendet ein Filter-Prädikat in der Indexdefinition, um einen Teil der Zeilen in der Tabelle zu indizieren. Ein gut gestalteter gefilterter Index kann die Abfrageleistung verbessern, die Kosten für Indexaktualisierungen reduzieren und die Indexspeicherkosten im Vergleich zu einem Volltabellenindex reduzieren.
Gefilterte Indizes können gegenüber Tabellenindizes folgende Vorteile bieten:
Verbesserte Abfrageleistung und Planqualität
Ein gut gestalteter gefilterter Index verbessert die Qualität der Abfrageleistung und des Ausführungsplans, da er kleiner als ein nicht gruppierter Volltabellenindex ist. Ein gefilterter Index hat gefilterte Statistiken, die genauer als Volltabellenstatistiken sind, da sie nur die Zeilen im gefilterten Index abdecken.
Reduzierte Kosten für Die Indexaktualisierung
Ein Index wird nur aktualisiert, wenn Anweisungen der Datenmanipulationssprache (DML) die Daten im Index beeinflussen. Ein gefilterter Index reduziert die Kosten für die Indexaktualisierung im Vergleich zu einem nicht gruppierten Index, da er kleiner ist und nur aktualisiert wird, wenn die Daten im Index betroffen sind. Eine große Anzahl von gefilterten Indizes ist insbesondere dann von Vorteil, wenn diese Daten enthalten, die nur selten beeinflusst werden. Wenn ein gefilterter Index nur die häufig betroffenen Daten enthält, reduziert die kleinere Größe des Index die Kosten für die Aktualisierung von Statistiken.
Reduzierter Aufwand bei der Indexspeicherung
Ein gefilterter Index kann den Speicherplatzbedarf von nicht gruppierten Indizes reduzieren, wenn ein Tabellenindex nicht erforderlich ist. Möglicherweise können Sie einen nicht gruppierten Volltabellenindex durch mehrere gefilterte Indizes ersetzen, ohne die Speicheranforderungen erheblich zu erhöhen.
Gefilterte Indizes sind nützlich, wenn Spalten klar definierte Teilmengen von Daten enthalten. Beispiele sind:
Spalten, die viele NULLs enthalten.
Heterogene Spalten, die Datenkategorien enthalten.
Spalten, die Wertebereiche wie Mengen, Uhrzeit und Datumsangaben enthalten.
Reduzierte Aktualisierungskosten für gefilterte Indizes sind am deutlichsten, wenn die Anzahl der Zeilen im Index im Vergleich zu einem Volltabellenindex klein ist. Wenn der gefilterte Index die meisten Zeilen in der Tabelle einschließt, ist der Verwaltungsaufwand möglicherweise größer als bei einem Tabellenindex. In diesem Fall sollten Sie anstelle eines gefilterten Index einen Tabellenindex verwenden.
Gefilterte Indizes werden für eine Tabelle definiert und unterstützen nur einfache Vergleichsoperatoren. Wenn Sie einen Filterausdruck benötigen, der komplexe Logik enthält oder auf mehrere Tabellen verweist, sollten Sie eine indizierte berechnete Spalte oder eine indizierte Ansicht erstellen.
Überlegungen zum Gefilterten Indexentwurf
Wenn Sie effektive gefilterte Indizes entwerfen möchten, müssen Sie wissen, welche Abfragen von Ihrer Anwendung verwendet werden und wie diese mit Teilmengen Ihrer Daten in Beziehung stehen. Einige Beispiele für Daten mit klar definierten Teilmengen sind Spalten mit vielen NULLs, Spalten mit heterogenen Kategorien von Werten und Spalten mit unterschiedlichen Wertebereichen.
Die folgenden Entwurfsüberlegungen geben mehrere Szenarien für den Fall, dass ein gefilterter Index Vorteile gegenüber Volltabellenindizes bieten kann.
Gefilterte Indizes für Datenteilmengen
Wenn eine Spalte nur wenig relevante Werte für Abfragen aufweist, können Sie für die Teilmenge der Werte einen gefilterten Index erstellen. Wenn die Spalte beispielsweise hauptsächlich NULL ist und die Abfrage nur Nicht-NULL-Werte erfordert, können Sie einen gefilterten Index erstellen, der die Nicht-NULL-Zeilen enthält.
Die AdventureWorks-Beispieldatenbank verfügt beispielsweise über eine Production.BillOfMaterials-Tabelle mit 2.679 Zeilen. Die EndDate Spalte enthält nur 199 Zeilen, die einen Wert ungleich NULL enthalten, und die anderen 2480 Zeilen enthalten NULL. Der folgende gefilterte Index behandelt Abfragen, die die im Index definierten Spalten zurückgeben und nur Zeilen mit einem Wert ungleich NULL erfordern.EndDate
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials (ComponentID, StartDate)
WHERE EndDate IS NOT NULL;
Der gefilterte Index FIBillOfMaterialsWithEndDate ist für die folgende Abfrage gültig.
Zeigen Sie den geschätzten Ausführungsplan an, um zu bestimmen, ob der Abfrageoptimierer den gefilterten Index verwendet hat.
SELECT ProductAssemblyID,
ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL
AND ComponentID = 5
AND StartDate > '20080101';
Weitere Informationen zum Erstellen von gefilterten Indizes und zum Definieren des Prädikatausdrucks für gefilterte Indizes finden Sie unter Create Filtered Indexes.
Gefilterte Indizes für heterogene Daten
Wenn eine Tabelle heterogene Datenzeilen enthält, können Sie einen gefilterten Index für eine oder mehrere Datenkategorien erstellen.
Zum Beispiel wird jedes Produkt, das in der Production.Product -Tabelle aufgelistet ist, einer ProductSubcategoryIDzugewiesen, die wiederum den Produktkategorien Fahrräder, Bauteile, Bekleidung oder Zubehör zugeordnet wird. Diese Kategorien sind heterogen, da ihre Spaltenwerte in der Production.Product -Tabelle nicht eng zueinander in Beziehung stehen. Beispielsweise besitzen die Spalten Color, ReorderPoint, ListPrice, Weight, Classund Style eindeutige Merkmale für jede Produktkategorie. Angenommen, es werden häufig Abfragen für Zubehör mit Unterkategorien zwischen 27 und 36 einschließlich ausgeführt. Sie können die Abfrageleistung für Zubehör verbessern, indem Sie einen gefilterten Index für die Unterkategorien von Zubehör erstellen, wie im folgenden Beispiel veranschaulicht.
CREATE NONCLUSTERED INDEX FIProductAccessories
ON Production.Product (ProductSubcategoryID, ListPrice)
INCLUDE (Name)
WHERE ProductSubcategoryID >= 27 AND ProductSubcategoryID <= 36;
Der gefilterte Index FIProductAccessories deckt die folgende Abfrage ab, da die Abfrageergebnisse im Index enthalten sind und der Abfrageplan keinen Zugriff auf die Basistabelle erfordert. Der Abfrageprädikatausdruck ProductSubcategoryID = 33 ist z. B. eine Teilmenge der gefilterten Indexprädikate ProductSubcategoryID >= 27 und ProductSubcategoryID <= 36, die Spalten ProductSubcategoryID und ListPrice im Abfrageprädikat sind beides Schlüsselspalten im Index, und der Name wird in der Blattebene des Indexes als einbezogene Spalte gespeichert.
SELECT Name,
ProductSubcategoryID,
ListPrice
FROM Production.Product
WHERE ProductSubcategoryID = 33
AND ListPrice > 25.00;
Schlüssel und eingeschlossene Spalten in gefilterten Indizes
Es empfiehlt sich, eine kleine Anzahl von Spalten in einer gefilterten Indexdefinition hinzuzufügen, nur bei Bedarf für den Abfrageoptimierer, um den gefilterten Index für den Abfrageausführungsplan auszuwählen. Der Abfrageoptimierer kann einen gefilterten Index für die Abfrage auswählen, unabhängig davon, ob dieser die Abfrage abdeckt oder nicht. Der Abfrageoptimierer wählt jedoch eher einen gefilterten Index aus, der die Abfrage abdeckt.
In einigen Fällen deckt ein gefilterter Index die Abfrage ab, ohne die Spalten im gefilterten Indexausdruck als Schlüsselspalten oder eingeschlossene Spalten in der Definition des gefilterten Indexes einzuschließen. Die folgenden Richtlinien erläutern, wann eine Spalte im gefilterten Indexausdruck eine Schlüsselspalte oder eingeschlossene Spalte in der Definition des gefilterten Indexes sein sollte. Die Beispiele beziehen sich auf den gefilterten Index FIBillOfMaterialsWithEndDate , der zuvor erstellt wurde.
Eine Spalte im gefilterten Indexausdruck muss in der Definition des gefilterten Indexes keine Schlüsselspalte oder eingeschlossene Spalte sein, wenn der gefilterte Indexausdruck dem Abfrageprädikat entspricht und die Abfrage die Spalte im gefilterten Indexausdruck mit den Abfrageergebnissen nicht zurückgibt. Zum Beispiel deckt FIBillOfMaterialsWithEndDate die folgende Abfrage ab, da das Abfrageprädikat dem Filterausdruck entspricht und EndDate nicht mit den Abfrageergebnissen zurückgegeben wird. Der FIBillOfMaterialsWithEndDate Index benötigt EndDate keinen Schlüssel und keine eingeschlossene Spalte in der Definition des gefilterten Index.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Eine Spalte im gefilterten Indexausdruck sollte in der Definition des gefilterten Indexes eine Schlüsselspalte oder eingeschlossene Spalte sein, wenn das Abfrageprädikat die Spalte in einem Vergleich verwendet, der nicht dem gefilterten Indexausdruck entspricht. Zum Beispiel ist FIBillOfMaterialsWithEndDate für die folgende Abfrage gültig, da damit aus dem gefilterten Index eine Teilmenge von Zeilen ausgewählt wird. Damit wird jedoch nicht die folgende Abfrage abgedeckt, da EndDate im Vergleich EndDate > '20040101'verwendet wird, der nicht dem gefilterten Indexausdruck entspricht. Der Abfrageprozessor kann diese Abfrage nicht ausführen, ohne die Werte von EndDate prüfen zu müssen. Deshalb sollte EndDate eine Schlüsselspalte oder eingeschlossene Spalte in der Definition des gefilterten Indexes darstellen.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate > '20040101';
Eine Spalte im gefilterten Indexausdruck sollte in der Definition des gefilterten Indexes eine Schlüsselspalte oder eingeschlossene Spalte sein, wenn die Spalte im Abfrageresultset enthalten ist. Zum Beispiel deckt FIBillOfMaterialsWithEndDate die folgende Abfrage nicht ab, da damit die EndDate -Spalte in den Abfrageergebnissen zurückgegeben wird. Deshalb sollte EndDate eine Schlüsselspalte oder eingeschlossene Spalte in der Definition des gefilterten Indexes darstellen.
SELECT ComponentID,
StartDate,
EndDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Der Schlüssel des gruppierten Indexes für die Tabelle muss in der Definition des gefilterten Indexes keine Schlüsselspalte oder eingeschlossene Spalte sein. Der Schlüssel des gruppierten Indexes ist automatisch in allen nicht gruppierten Indizes enthalten, wozu auch gefilterte Indizes zählen.
Datenkonvertierungsoperatoren im Filterprädikat
Wenn der im gefilterten Indexausdruck der gefilterten Indexergebnisse angegebene Vergleichsoperator eine implizite oder explizite Datenkonvertierung ergibt, kommt es zu einem Fehler, wenn die Konvertierung auf der linken Seite eines Vergleichsoperators auftritt. Eine mögliche Lösung besteht darin, den gefilterten Indexausdruck mit dem Datenkonvertierungsoperator (CAST oder CONVERT) auf die rechte Seite des Vergleichsoperators zu schreiben.
Im folgenden Beispiel wird eine Tabelle mit Spalten unterschiedlicher Datentypen erstellt.
CREATE TABLE dbo.TestTable
(
a INT,
b VARBINARY(4)
);
In der folgenden gefilterten Indexdefinition wird die Spalte b implizit in einen ganzzahligen Datentyp konvertiert, um sie mit der Konstante 1 zu vergleichen. Dadurch wird die Fehlermeldung 10611 erzeugt, da die Konvertierung auf der linken Seite des Operators im gefilterten Prädikat auftritt.
CREATE NONCLUSTERED INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = 1;
Wie im folgenden Beispiel gezeigt, besteht die Lösung darin, die Konstante auf der rechten Seite zu konvertieren, damit diese vom gleichen Typ ist wie Spalte b:
CREATE INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = CONVERT (VARBINARY(4), 1);
Durch das Verschieben der Datenkonvertierung von der linken Seite auf die rechte Seite eines Vergleichsoperators wird möglicherweise die Bedeutung der Konvertierung geändert. Im vorherigen Beispiel wurde beim Hinzufügen des CONVERT Operators zur rechten Seite der Vergleich von einem Int-Vergleich zu einem varbinären Vergleich geändert.
Architektur von Columnstore-Indizes
Ein Columnstore-Index ist eine Technologie zum Speichern, Abrufen und Verwalten von Daten mithilfe eines Spaltendatenformats, das als Columnstore bezeichnet wird. Weitere Informationen finden Sie unter Columnstore-Indizes: Übersicht.
Informationen zur Version und Informationen dazu, was neu ist, finden Sie unter Neuigkeiten bei den Columnstore-Indizes.
Wenn Sie diese Grundlagen kennen, ist es einfacher, andere Columnstore-Artikel zu verstehen, in denen erläutert wird, wie diese Technologie effektiv verwendet wird.
Datenspeicherung verwendet Spaltenspeicher und Zeilenspeicher
Im Zusammenhang mit Columnstore-Indizes werden die Begriffe Rowstore und Columnstore verwendet, um das Format für die Datenspeicherung zu bezeichnen. Columnstore-Indizes verwenden beide Arten der Datenspeicherung.

Ein Columnstore enthält Daten, die logisch als Tabelle mit Zeilen und Spalten organisiert und physisch in einem Spaltendatenformat gespeichert sind.
Ein Columnstore-Index speichert die meisten Daten physisch im Columnstore-Format. Im Columnstore-Format werden die Daten als Spalten komprimiert und dekomprimiert. Es ist nicht erforderlich, andere Werte in jeder Zeile zu dekomprimieren, die nicht von der Abfrage angefordert werden. Das schnelle Scannen einer ganzen Spalte einer großen Tabelle wird dadurch erleichtert.
Ein Rowstore enthält Daten, die logisch als Tabelle mit Zeilen und Spalten organisiert und anschließend physisch in einem Zeilendatenformat gespeichert sind. Dies war die herkömmliche Möglichkeit, relationale Tabellendaten wie einen geclusterten B+-Baum-Index oder einen Heap zu speichern.
Ein Columnstore-Index speichert auch einige Zeilen in einem Rowstore-Format, das als Deltastore bezeichnet wird. Beim Deltastore, auch Delta-Zeilengruppe genannt, handelt es sich um einen Aufbewahrungsort für Zeilen, die eine zu geringe Anzahl darstellen, um in den Columnstore komprimiert zu werden. Jede Delta-Zeilengruppe wird als gruppierter B+-Tree-Index implementiert, bei dem es sich um einen Rowstore handelt.
Vorgänge werden für Zeilengruppen und Spaltensegmente ausgeführt
Der Columnstore-Index gruppiert Zeilen in verwaltbare Einheiten. Diese Einheiten werden jeweils als eine Zeilengruppe bezeichnet. Um eine optimale Leistung zu erzielen, ist die Anzahl der Zeilen in einer Zeilengruppe groß genug, um das Komprimierungsverhältnis und klein genug zu verbessern, um von Speichervorgängen zu profitieren.
Der Columnstore-Index führt diese Vorgänge z.B. auf Zeilengruppen aus:
Komprimiert Zeilengruppen in den Columnstore. Die Komprimierung wird für jedes Spaltensegment innerhalb einer Zeilengruppe ausgeführt.
Führt Zeilengruppen während eines
ALTER INDEX ... REORGANIZEVorgangs zusammen, einschließlich des Entfernens gelöschter Daten.Erstellt alle Zeilengruppen während eines
ALTER INDEX ... REBUILD-Vorgangs neu.Meldet Zeilengruppen-Integrität und Fragmentierung in dynamischen Verwaltungsansichten (DMVs).
Der Deltastore besteht aus mindestens einer Zeilengruppe, die Delta-Zeilengruppen genannt werden. Jede Delta-Zeilengruppe ist ein gruppierter B+-Strukturindex, der kleine Massenlasten speichert und einfügt, bis die Zeilengruppe 1.048.576 Zeilen enthält, wobei ein Prozess, der als Tupel-Mover bezeichnet wird, automatisch eine geschlossene Zeilengruppe in den Columnstore komprimiert.
Weitere Informationen zu Zeilengruppenzuständen finden Sie unter sys.dm_db_column_store_row_group_physical_stats.
Tip
Zu viele kleine Zeilengruppen verschlechtern die Qualität des Columnstore-Index. Ein Neuorganisierungsvorgang führt kleinere Zeilengruppen zusammen, wobei eine interne Schwellenwertrichtlinie eingehalten wird, die bestimmt, wie gelöschte Zeilen entfernt und die komprimierten Zeilengruppen kombiniert werden. Nach einer Zusammenführung wird die Indexqualität verbessert.
In SQL Server 2019 (15.x) und höheren Versionen wird der Tupel-Mover von einem Hintergrund-Merge-Task unterstützt, der automatisch kleinere geöffnete Delta-Zeilengruppen komprimiert, die seit einiger Zeit existieren und durch einen internen Schwellenwert festgelegt wurden. Außerdem werden komprimierte Zeilengruppen zusammengeführt, aus denen eine große Anzahl von Zeilen gelöscht worden ist.
Jede Spalte weist einige ihrer Werte in jeder Zeilengruppe auf. Diese Werte werden als Spaltensegmente bezeichnet. Jede Zeilengruppe enthält ein Spaltensegment für jede Spalte in der Tabelle. Jede Spalte besitzt ein Spaltensegment in jeder Zeilengruppe.

Wenn der Columnstore-Index eine Zeilengruppe komprimiert, wird jedes Spaltensegment separat komprimiert. Um eine ganze Spalte zu dekomprimieren, muss der Columnstore-Index nur ein Spaltensegment von jeder Zeilengruppe dekomprimieren.
Kleine Ladungen und Einfügungen werden im Deltastore gespeichert
Ein Columnstore-Index verbessert die Columnstore-Komprimierung und Leistung durch das Komprimieren von mindestens 102.400 Zeilen gleichzeitig in den Columnstore-Index. Um Zeilen in einem Sammelvorgang zu komprimieren, sammelt der Columnstore-Index kleine Lasten, und fügt diese im Deltastore ein. Die Deltastore-Vorgänge werden im Hintergrund ausgeführt. Um Abfrageergebnisse zurückzugeben, kombiniert der gruppierte Columnstore-Index Abfrageergebnisse aus dem Columnstore und dem Deltastore.
Zeilen werden im Deltastore aufgenommen wenn sie:
Mit der
INSERT INTO ... VALUES-Anweisung eingefügt werden.Am Ende eines Massenladevorgangs angelangt sind und ihre Anzahl weniger als 102.400 ist.
Updated. Jedes Update wird als Delete und Insert implementiert.
Der Deltastore speichert auch eine Liste von IDs für gelöschte Zeilen, die als gelöscht markiert, aber noch nicht physisch aus dem Columnstore entfernt wurden.
Wenn Delta-Zeilengruppen voll sind, werden sie in den Columnstore komprimiert
Gruppierte Columnstore-Indizes erfassen bis zu 1.048.576 Zeilen in jeder Delta-Zeilengruppe, bevor die Zeilengruppe in den Delta-Store komprimiert wird. Dies verbessert die Komprimierung des Columnstore-Index. Wenn eine Deltazeilengruppe die maximale Zeilenanzahl erreicht, ändert sich ihr Zustand von OPEN in CLOSED. Ein Hintergrundprozess namens Tupelverschiebungsvorgang überprüft auf geschlossene Zeilengruppen. Wenn der Prozess eine geschlossene Zeilengruppe findet, wird diese komprimiert und im Columnstore-Index gespeichert.
Wenn eine Deltazeilengruppe komprimiert wurde, ändert sich der Zustand der vorhandenen Deltazeilengruppe in TOMBSTONE, damit sie später im Tupelverschiebungsvorgang entfernt wird, wenn nicht auf sie verwiesen wird. Die neue komprimierte Zeilengruppe wird als COMPRESSED gekennzeichnet.
Weitere Informationen zu Zeilengruppenzuständen finden Sie unter sys.dm_db_column_store_row_group_physical_stats.
Mit ALTER INDEX können Delta-Zeilengruppen in den Columnstore gezwungen werden, um den Index neu zu erstellen oder zu organisieren. Bei zu wenig verfügbarem Arbeitsspeicher während des Komprimiervorgangs reduziert der Columnstore-Index möglicherweise die Anzahl der Zeilen in der komprimierten Zeilengruppe.
Jede Tabellenpartition verfügt über eigene Zeilengruppen und Delta-Zeilengruppen
Das Konzept der Partitionierung ist in einem gruppierten Index, einem Heap und einem Spaltenspeicherindex identisch. Das Partitionieren einer Tabelle teilt die Tabelle in kleinere Gruppen von Zeilen, gemäß einer Reihe von Spaltenwerten. Es wird häufig für die Verwaltung der Daten verwendet. Sie können z. B. eine Partition für jedes Jahr mit Daten erstellen und dann den Partitionswechsel verwenden, um alte Daten auf weniger kostspieligen Speicher zu archivieren.
Zeilengruppen werden immer in einer Spalten-Partition definiert. Wenn ein Columnstore-Index partitioniert ist, besitzt jede Partition seine eigenen komprimierten Zeilengruppen und Delta-Zeilengruppen. Eine nicht partitionierte Tabelle enthält eine Partition.
Tip
Sie sollten die Verwendung der Tabellenpartitionierung in Betracht ziehen, wenn Daten aus dem Columnstore entfernt werden müssen. Das Wechseln und Abschneiden von Partitionen, die nicht mehr benötigt werden, ist eine effiziente Strategie zum Löschen von Daten, ohne eine Fragmentierung im Columnstore einzuführen.
Jede Partition kann über mehrere Delta-Zeilengruppen verfügen
Jede Partition kann über mehrere Delta-Zeilengruppen verfügen. Wenn der Columnstore-Index Daten zu einer Delta-Zeilengruppe hinzufügen muss und die Delta-Zeilengruppe durch eine andere Transaktion gesperrt ist, versucht der Columnstore-Index, eine Sperre für eine andere Delta-Zeilengruppe abzurufen. Wenn keine Delta-Zeilengruppen verfügbar sind, wird der Columnstore-Index eine neue Delta-Zeilengruppe erstellen. Beispielsweise könnte eine Tabelle mit 10 Partitionen problemlos über mindestens 20 Delta-Zeilengruppen verfügen.
Kombinieren der Columnstore und Rowstore-Indizes für dieselbe Tabelle
Der nicht gruppierte Index enthält eine Kopie eines Teils oder aller Zeilen und Spalten der zugrundeliegenden Tabelle. Der Index ist als eine oder mehrere Spalte(n) der Tabelle definiert und weist eine optionale Bedingung auf, die zum Filtern der Zeilen dient.
Sie können einen aktualisierbaren, nicht gruppierten Columnstore-Index für eine Rowstore-Tabelle erstellen. Der Columnstore-Index speichert eine Kopie der Daten, sodass Sie keinen zusätzlichen Speicher benötigen. Die Daten im Columnstore-Index werden jedoch auf eine viel kleinere Größe komprimiert als in der Rowstore-Tabelle erforderlich ist. Auf diese Weise können Sie Analysen für den Columnstore-Index und OLTP-Workloads gleichzeitig im Rowstore-Index ausführen. Der Spaltenspeicher wird aktualisiert, wenn sich die Daten in der Rowstore-Tabelle ändern, daher arbeiten beide Indizes auf den gleichen Daten.
Eine Rowstore-Tabelle kann über einen nicht gruppierten Columnstore-Index verfügen. Weitere Informationen finden Sie unter Columnstore-Indizes – Entwurfsleitfaden.
Sie können einen oder mehrere nicht gruppierte Rowstore-Indizes in einer gruppierten Columnstore-Tabelle haben. Auf diese Weise können effiziente Tabellensuchvorgänge im zugrundeliegenden Columnstore ausgeführt werden. Auch weitere Optionen werden dadurch verfügbar. Sie können beispielsweise die Eindeutigkeit erzwingen, indem Sie eine UNIQUE Einschränkung für die Rowstore-Tabelle verwenden. Wenn ein nicht eindeutiger Wert nicht in die Rowstore-Tabelle eingefügt werden kann, fügt das Datenbankmodul den Wert auch nicht in den Columnstore ein.
Überlegungen zur Leistung des nicht gruppierten Columnstores
Die Definition von nicht gruppierten Columnstore-Indizes unterstützt gefilterte Bedingungen. Um den Leistungseffekt des Hinzufügens eines Columnstore-Index zu minimieren, verwenden Sie einen Filterausdruck, um einen nicht gruppierten Spaltenspeicherindex nur für die Teilmenge der daten zu erstellen, die für Analysen erforderlich sind.
Eine speicheroptimierte Tabelle kann einen Spaltenspeicherindex aufweisen. Sie können es erstellen, wenn die Tabelle erstellt wird, oder es später mit ALTER TABLE hinzufügen.
Weitere Informationen finden Sie unter Columnstore-Indizes – Abfrageleistung.
Entwurfsrichtlinien für speicheroptimierte Hashindexe
Bei Verwendung vonIn-Memory OLTP müssen alle speicheroptimierten Tabellen mindestens einen Index aufweisen. Für eine speicheroptimierte Tabelle ist jeder Index auch speicheroptimiert. Hashindizes zählen zu den möglichen Typen von Indizes in einer speicheroptimierten Tabelle. Weitere Informationen zu finden Sie unter Indizes in speicheroptimierten Tabellen.
Speicheroptimierte Hashindexarchitektur
Ein Hashindex besteht aus einem Array von Zeigern. Jedes Element des Arrays wird als Hashbucket bezeichnet.
- Jeder Bucket umfasst 8 Bytes, die zum Speichern der Arbeitsspeicheradresse einer Linkliste von Schlüsseleinträgen verwendet werden.
- Jeder Eintrag ist ein Wert für einen Indexschlüssel zuzüglich der Adresse für die entsprechende Zeile in der zugrunde liegenden speicheroptimierten Tabelle.
- Jeder Eintrag verweist in einer Linkliste von Einträgen – alle mit dem aktuellen Bucket verkettet – auf den nächsten Eintrag.
Die Anzahl der Buckets muss zur Indexerstellungszeit angegeben werden:
- Je geringer das Verhältnis von Buckets zu Tabellenzeilen oder eindeutigen Werten, desto länger wird die durchschnittliche Bucketlinkliste.
- Kurze Linklisten können schneller verarbeitet werden als lange Linklisten.
- Die maximale Anzahl von Buckets in einem Hashindex beträgt 1.073.741.824.
Tip
Informationen, wie Sie den richtigen BUCKET_COUNT -Wert für Ihre Daten ermitteln, finden Sie unter Konfigurieren der Hashindex-Bucketanzahl.
Die Hashfunktion wird auf die Indexschlüsselspalten angewendet. Durch das Ergebnis dieser Funktion wird bestimmt, welchem Bucket dieser Schlüssel zugeordnet wird. Jeder Bucket verfügt über einen Zeiger zu den Zeilen, deren Hashschlüsselwerte diesem Bucket zugeordnet sind.
Die Hashfunktion, die für Hashindizes verwendet wird, weist die folgenden Merkmale auf:
- Der Datenbank-Engine verfügt über eine Hashfunktion, die für alle Hashindizes verwendet wird.
- Die Hashfunktion ist deterministisch. Der gleiche Eingabeschlüsselwert wird immer demselben Bucket im Hashindex zugeordnet.
- Mehrere Indexschlüssel können dem gleichen Hashbucket zugeordnet werden.
- Die Hashfunktion ist ausgeglichen. Dies bedeutet, dass die Verteilung der Indexschlüsselwerte auf Hashbuckets üblicherweise nicht einer flachen linearen Verteilung entspricht, sondern einer Poisson- oder Glockenkurvenverteilung.
- Eine Poisson-Verteilung ist keine gleichmäßige Verteilung. Indexschlüsselwerte werden in die Hashbuckets nicht gleichmäßig verteilt.
- Wenn zwei Indexschlüssel dem gleichen Hashbucket zugeordnet werden, kommt es zu einem Hashkonflikt. Eine große Anzahl von Hashkonflikten kann die Leistung von Lesevorgängen beeinträchtigen. Ein realistisches Ziel ist es, dass 30 Prozent der Buckets zwei verschiedene Schlüsselwerte enthalten.
Die Interaktion zwischen dem Hashindex und den Buckets wird im folgenden Bild zusammengefasst.

Konfigurieren der Hashindex-Bucketanzahl
Die Bucketanzahl des Hashindexes wird während der Indexerstellung angegeben und kann mit der Syntax ALTER TABLE...ALTER INDEX REBUILD geändert werden.
In den meisten Fällen sollte die Bucketanzahl zwischen dem 1- bis 2-fachen der Anzahl unterschiedlicher Werte im Indexschlüssel liegen.
Möglicherweise können Sie nicht immer vorhersagen, wie viele Werte ein bestimmter Indexschlüssel hat. Die Leistung ist in der Regel dennoch gut, falls der BUCKET_COUNT-Wert im Rahmen des 10-fachen der tatsächlichen Anzahl der Schlüsselwerte liegt, und die Überschätzung ist im Allgemeinen besser als die Unterschätzung.
Zu wenige Buckets können die folgenden Nachteile haben:
- Mehr Hashkonflikte von eindeutigen Schlüsselwerten.
- Jeder eindeutige Wert wird gezwungen, denselben Bucket mit einem anderen eindeutigen Wert zu nutzen.
- Die durchschnittliche Kettenlänge pro Bucket nimmt zu.
- Je länger die Bucketkette ist, desto langsamer ist die Gleichheitssuche im Index.
Zu viele Buckets können die folgenden Nachteile haben:
- Bei einer zu hohen Bucketanzahl können möglicherweise mehr leere Buckets auftreten.
- Leere Buckets beeinträchtigen die Leistung der vollständigen Indexscans. Wenn Scans regelmäßig ausgeführt werden, erwägen Sie eine Bucketanzahl, die annähernd der Anzahl eindeutiger Indexschlüsselwerte entspricht.
- Leere Buckets belegen Speicher, wobei jeder Bucket allerdings nur 8 Bytes belegt.
Note
Das Hinzufügen von weiteren Buckets trägt nichts zur Reduzierung der Verkettung von Einträgen bei, die sich einen duplizierten Wert teilen. Die Häufigkeit der Wertduplizierung wird verwendet, um zu entscheiden, ob ein Hashindex oder ein nicht gruppierter Index der geeignete Indextyp ist, nicht um die Bucketanzahl zu berechnen.
Leistungsaspekte von Hash-Indizes
Die Leistung eines Hash-Indexes ist:
- Ausgezeichnet, wenn das Prädikat der
WHERE-Klausel einen genauen Wert für jede Spalte im Hashindexschlüssel angibt. Ein Hashindex wird mit einem Ungleichheitsprädikat auf einen Scan wiederhergestellt. - Schlecht, wenn das Prädikat der
WHERE-Klausel im Indexschlüssel nach einem Wertebereich sucht. - Schlecht, wenn das Prädikat der
WHERE-Klausel einen bestimmten Wert für die erste Spalte eines Hashindexschlüssels mit zwei Spalten festlegt, aber keinen Wert für die anderen Spalten des Schlüssels.
Tip
Das Prädikat muss alle Spalten im Hashindexschlüssel enthalten. Der Hashindex erfordert den gesamten Schlüssel, um in den Index zu suchen.
Wenn ein Hashindex verwendet wird und die Anzahl eindeutiger Indexschlüssel mehr als 100 Mal kleiner als die Zeilenanzahl ist, sollten Sie entweder eine größere Bucketanzahl erhöhen, um große Zeilenketten zu vermeiden oder stattdessen einen nicht gruppierten Index zu verwenden.
Erstellen eines Hashindexes
Berücksichtigen Sie beim Erstellen eines Hashindex Folgendes:
- Ein Hashindex kann nur für eine speicheroptimierte Tabelle vorhanden sein. Er kann nicht in einer datenträgerbasierten Tabelle vorhanden sein.
- Ein Hashindex ist standardmäßig nicht eindeutig, kann aber als eindeutig deklariert werden.
Im folgenden Beispiel wird ein eindeutiger Hashindex erstellt:
ALTER TABLE MyTable_memop ADD INDEX ix_hash_Column2
UNIQUE HASH (Column2) WITH (BUCKET_COUNT = 64);
Zeilenversionen und Garbage Collection in speicheroptimierten Tabellen
Wenn eine Zeile von einer UPDATE Anweisung betroffen ist, erstellt die Tabelle in einer speicheroptimierten Tabelle eine aktualisierte Version der Zeile. Während der Updatetransaktion können andere Sitzungen möglicherweise die ältere Version der Zeile lesen und so den Leistungsabfall vermeiden, der mit einer Zeilensperre einhergeht.
Der Hashindex kann möglicherweise auch verschiedene Versionen seiner Einträge haben, um das Update zu berücksichtigen.
Wenn die älteren Versionen später nicht mehr erforderlich sind, durchsucht ein Thread der automatischen Speicherbereinigung (GC, Garbage Collection) die Buckets und Verknüpfung, um alte Einträge zu beseitigen. Der GC-Thread bietet eine bessere Leistung, wenn die Kettenlängen kurz sind. Weitere Informationen finden Sie unter In-Memory-OLTP-Garbage Collection.
Memory-Optimized Nonclustered Index Design Guideline (Richtlinien zum Entwerfen von speicheroptimierten, nicht gruppierten Indizes)
Neben Hashindizes sind nicht gruppierte Indizes die anderen möglichen Indextypen in einer speicheroptimierten Tabelle. Weitere Informationen zu finden Sie unter Indizes in speicheroptimierten Tabellen.
Speicheroptimierte nicht gruppierte Indexarchitektur
Nicht gruppierte Indizes für speicheroptimierte Tabellen werden mithilfe einer Datenstruktur namens Bw-Struktur implementiert, die ursprünglich von Microsoft Research 2011 geplant und beschrieben wurde. Bei einer Bw-Struktur handelt es sich um eine Variante der B-Struktur, die keine Sperren oder Latches aufweist. Weitere Informationen finden Sie unter The Bw-Tree: A B-tree for New Hardware Platforms (Die Bw-Struktur: eine B-Struktur für neue Hardwareplattformen).
Auf hoher Ebene kann der Bw-Baum als eine Zuordnung der Seiten nach Seiten-ID (PidMap), eine Einrichtung zur Zuweisung und Wiederverwendung von Seiten-IDs (PidAlloc) und eine Reihe von Seiten verstanden werden, die in der Seiten-ID-Zuordnung und miteinander verknüpft sind. Diese drei allgemeinen Unterkomponenten bilden zusammen die grundlegende interne Struktur einer Bw-Struktur.
Die Struktur ähnelt einer normalen B-Struktur in Bezug auf die folgenden Aspekte: Jede Seite umfasst mehrere sortierte Schlüsselwerte, es gibt Ebenen im Index, die jeweils auf eine niedrigere Ebene zeigen, und die Blattebenen zeigen auf eine Datenzeile. Es gibt jedoch einige Unterschiede.
Genau wie bei Hashindizes können mehrere Datenzeilen miteinander verknüpft werden, um die Versionsverwaltung zu unterstützen. Bei den Seitenzeigern zwischen den Ebenen handelt es sich um logische Seiten-IDs, die Offsets zu einer Seitenzuordnungstabelle darstellen, die wiederum die physische Adresse für jede Seite enthält.
Es gibt keine direkten Updates für Indexseiten. Deshalb werden neue Änderungsseiten eingeführt.
- Latches oder Sperren sind für Seitenupdates nicht erforderlich.
- Indexseiten verfügen nicht über eine festgelegte Größe.
Der Schlüsselwert auf jeder Seite der nicht-blattförmigen Ebene ist der höchste Wert, den das Kind enthält, auf das es zeigt, und jede Zeile enthält auch die logische Seiten-ID. Auf den Seiten auf Blattebene ist neben dem Schlüsselwert die physische Adresse der Datenzeile enthalten.
Punktsuchvorgänge ähneln B-Bäumen, mit der Ausnahme, dass Seiten nur in einer Richtung verknüpft sind. Daher folgt das Datenbankmodul rechten Seitenzeigern, wobei jede nicht-Blatt-Seite den höchsten Wert ihres Kindes und nicht den niedrigsten Wert wie in einem B-Baum aufweist.
Wenn sich eine Seite auf Blattebene ändern muss, ändert das Datenbankmodul die Seite selbst nicht. Stattdessen erstellt das Datenbankmodul einen Delta-Datensatz, der die Änderung beschreibt, und fügt ihn an die vorherige Seite an. Anschließend wird ebenfalls die Tabellenadresse der Seitenzuordnung für die vorherige Seite aktualisiert. Die aktualisierte Adresse entspricht der des Änderungsdatensatzes, die nun die physische Adresse für diese Seite darstellt.
Es gibt drei verschiedene Vorgänge, die für das Verwalten der Struktur einer Bw-Struktur erforderlich sein können: Konsolidierung, Teilung und Merge.
Deltakonsolidierung
Eine lange Kette von Delta-Datensätzen kann letztlich die Suchleistung beeinträchtigen, da bei der Suche in einem Index eine lange Kette durchlaufen werden muss. Wenn ein neuer Änderungsdatensatz zu einer Kette hinzugefügt wird, die bereits über 16 Elemente verfügt, werden die Änderungen in den Änderungsdatensätzen in die Indexseite konsolidiert, auf die verwiesen wird. Die Seite wird dann neu erstellt und enthält Änderungen, die vom neuen Änderungsdatensatz angegeben werden, der die Konsolidierung ausgelöst hat. Die neu erstellte Seite besitzt die gleiche Seiten-ID, aber eine neue Speicheradresse.

Geteilte Seite
Eine Indexseite in einer Bw-Struktur wächst je nach Bedarf, beginnend bei der Speicherung einer einzelnen Zeile bis hin zu einer Speicherung von maximal 8 KB. Sobald die Indexseite 8 KB erreicht, bewirkt das Einfügen einer einzelnen Seite die Teilung der Indexseite. Bei einer internen Seite bedeutet dies, dass kein Platz zum Hinzufügen eines weiteren Schlüsselwerts oder Zeigers verfügbar ist. Bei einer Blattseite bedeutet dies, dass die Zeile nach dem Integrieren aller Änderungsdatensätze zu groß ist, um auf die Seite zu passen. Die statistischen Informationen im Seitenkopf einer Blattseite verfolgen, wie viel Speicherplatz erforderlich ist, um die Änderungsdatensätze zu konsolidieren. Diese Informationen werden angepasst, wenn jeder neue Delta-Datensatz hinzugefügt wird.
Ein Teilungsvorgang wird in zwei unteilbaren Schritten ausgeführt. Gehen Sie im folgenden Diagramm davon aus, dass eine Blattseite eine Teilung erzwingt, da ein Schlüssel mit dem Wert 5 eingefügt wird und eine Seite auf der inneren Knotenebene vorhanden ist, die auf das Ende der aktuellen Seite auf Blattebene zeigt (Schlüsselwert 4).

Schritt 1: Ordnen Sie zwei neue Seiten namens P1 und P2 zu, und teilen Sie die Zeilen der alten Seite namens P1, einschließlich der neu eingefügten Zeile, auf diese neuen Seiten auf. Ein neuer Slot in der Seitenzuordnungstabelle wird verwendet, um die physische Adresse der Seite P2 zu speichern. Seiten P1 und P2 sind noch nicht für gleichzeitige Vorgänge zugänglich. Darüber hinaus wird der logische Zeiger von P1 auf P2 festgelegt. Aktualisieren Sie die Seitenzuordnungstabelle anschließend in einem unteilbaren Schritt, um den Zeiger von der alten Seite P1 auf die neue Seite P1 zu ändern.
Schritt 2: Die Seite auf der inneren Knotenebene zeigt auf P1, es gibt jedoch keinen direkten Zeiger von einer Seite auf der inneren Knotenebene zu P2.
P2 ist nur über P1 erreichbar. Zum Erstellen eines Zeigers von einer Seite auf der inneren Knotenebene zu P2, ordnen Sie eine neue Seite auf der inneren Knotenebene zu (interne Indexseite), kopieren Sie alle Zeilen von der alten Seite auf der inneren Knotenebene, und fügen Sie eine neue Zeile hinzu, um auf P2 zu zeigen. Sobald dieser Vorgang abgeschlossen ist, aktualisieren Sie die Seitenzuordnungstabelle in einem unteilbaren Schritt, um den Zeiger von der alten Seite auf der inneren Knotenebene zur neuen Seite auf der inneren Knotenebene zu ändern.
Seite zusammenführen
Wenn ein DELETE Vorgang zu einer Seite führt, die weniger als 10 Prozent der maximalen Seitengröße (8 KB) oder mit einer einzelnen Zeile enthält, wird diese Seite mit einer zusammenhängenden Seite zusammengeführt.
Wenn eine Zeile aus einer Seite gelöscht wird, wird ein Änderungsdatensatz für den Löschvorgang hinzugefügt. Darüber hinaus wird eine Überprüfung durchgeführt, um zu ermitteln, ob die Indexseite (Nicht-Blatt-Seite) für die Zusammenführung qualifiziert ist. Dadurch wird überprüft, ob der verbleibende Speicherplatz nach dem Löschen der Zeile weniger als 10 Prozent der maximalen Seitengröße entspricht. Wenn dies der Fall ist, erfolgt die Zusammenführung in drei atomaren Schritten.
Gehen Sie im folgenden Bild davon aus, dass ein DELETE-Vorgang den Schlüsselwert 10 löscht.

Schritt 1: Eine Änderungsseite, die den Schlüsselwert 10 darstellt, (blaues Dreieck) wird erstellt, und deren Zeiger auf die Seite Pp1 auf der inneren Knotenebene wird auf die neue Änderungsseite festgelegt. Darüber hinaus wird eine besondere Änderungsseite für den Merge (orangefarbenes Dreieck) erstellt und mit dem Zeiger zur Änderungsseite verknüpft. Zu diesem Zeitpunkt sind beide Seiten (die Änderungsseite und die Änderungsseite für den Merge) nicht für gleichzeitige Transaktionen sichtbar. In einem unteilbaren Schritt wird der Zeiger zur Seite P1 auf Blattebene in der Seitenzuordnungstabelle aktualisiert, damit dieser auf die Änderungsseite für den Merge zeigt. Nach diesem Schritt zeigt der Eintrag für den Schlüsselwert 10 in Pp1 auf die Änderungsseite für den Merge.
Schritt 2: Auf der Seite 7 auf der inneren Knotenebene muss die Zeile entfernt werden, die den Schlüsselwert Pp1 enthält, und der Eintrag für den Schlüsselwert 10 muss aktualisiert werden, damit dieser auf P1 zeigt. Hierfür wird eine neue Seite namens Pp2 auf der inneren Knotenebene zugeordnet, und alle Zeilen von Pp1 (mit Ausnahme der Zeile, die den Schlüsselwert 7 enthält) werden kopiert. Anschließend wird die Zeile für den Schlüsselwert 10 aktualisiert, damit diese auf die Seite P1 zeigt. Sobald dieser Vorgang abgeschlossen ist, wird der Eintrag der Seitenzuordnungstabelle aktualisiert, der auf Pp1 zeigt, damit dieser auf Pp2 zeigt.
Pp1 ist nicht mehr erreichbar.
Schritt 3: Die Seiten P2 und P1 auf Blattebene werden zusammengeführt, und die Änderungsseiten werden entfernt. Hierfür wird die neue Seite P3 zugeordnet, die Zeilen von P2 und P1 werden zusammengeführt, und die Änderungen durch die Änderungsseite werden in die neue Seite P3 integriert. Anschließend wird der Eintrag der Seitenzuordnungstabelle, der auf P1 zeigt, in einem unteilbaren Schritt aktualisiert, um auf die Seite P3 zu zeigen.
Leistungsüberlegungen für speicheroptimierte nicht gruppierte Indizes
Die Leistung eines nicht gruppierten Indexes ist besser als bei Hashindizes beim Abfragen einer speicheroptimierten Tabelle mit Ungleichheits-Prädikaten.
Eine Spalte in einer speicheroptimierten Tabelle kann Teil eines Hashindexes und des nicht gruppierten Indexes sein.
Wenn eine Schlüsselspalte in einem nicht gruppierten Index viele doppelte Werte aufweist, kann die Leistung bei Updates, Einfügungen und Löschungen abnehmen. Eine Möglichkeit, die Leistung in dieser Situation zu verbessern, besteht darin, eine Spalte mit besserer Selektivität in den Indexschlüssel aufzunehmen.
Index-Metadaten
Verwenden Sie die folgenden Systemansichten, um Indexmetadaten wie Indexdefinitionen, Eigenschaften und Datenstatistiken zu untersuchen:
- sys.objects
- sys.indexes
- sys.index_columns
- sys.columns
- sys.types
- sys.partitions
- sys.internal_partitions
- sys.dm_db_index_usage_stats
- sys.dm_db_partition_stats
- sys.dm_db_index_operational_stats
Die vorherigen Ansichten gelten für alle Indextypen. Verwenden Sie für Spaltenspeicherindizes zusätzlich die folgenden Ansichten:
- sys.column_store_row_groups
- sys.column_store_segments
- sys.column_store_dictionaries
- sys.dm_column_store_object_pool
- sys.dm_db_column_store_row_group_operational_stats
- sys.dm_db_column_store_row_group_physical_stats
Bei Columnstore-Indizes werden alle Spalten in den Metadaten als eingeschlossene Spalten gespeichert. Der Columnstore-Index hat keine Schlüsselspalten.
Verwenden Sie für Indizes für speicheroptimierte Tabellen zusätzlich die folgenden Ansichten:
- sys.hash_indexes
- sys.dm_db_xtp_hash_index_stats
- sys.dm_db_xtp_index_stats
- sys.dm_db_xtp_nonclustered_index_stats
- sys.dm_db_xtp_object_stats
- sys.dm_db_xtp_table_memory_stats
- sys.memory_optimized_tables_internal_attributes
Verwandte Inhalte
- CREATE INDEX (Transact-SQL)
- Optimale Wartung von Indizes zum Verbessern der Leistung und Verringern der Ressourcenauslastung
- Partitionierte Tabellen und Indizes
- Indizes für speicheroptimierte Tabellen
- Columnstore-Indizes: Übersicht
- Indizes in berechneten Spalten
- Optimieren nicht gruppierter Indizes mit Vorschlägen für fehlende Indizes