Speichern extrahierter Informationen in einem Wissensspeicher
Während der Index als die primäre Ausgabe eines Indizierungsprozesses betrachtet werden kann, können die angereicherten Daten, die er enthält, auch auf andere Weise nützlich sein. Beispiel:
- Da der Index im Wesentlichen eine Sammlung von JSON-Objekten ist, die jeweils einen indizierten Datensatz darstellen, kann es hilfreich sein, die Objekte als JSON-Dateien für die Integration in einen Daten-Orchestrierungsprozess zum Extrahieren, Transformieren und Laden (ETL) zu exportieren.
- Sie können die Indexdatensätze in ein relationales Schema von Tabellen zur Analyse und Berichterstellung normalisieren.
- Nachdem Sie während des Indizierungsvorgangs eingebettete Bilder aus den Dokumenten extrahiert haben, möchten Sie diese Bilder möglicherweise als Dateien speichern.
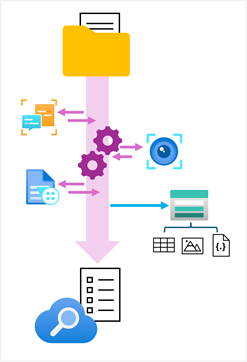
Azure KI-Suche unterstützt diese Szenarien, indem es Ihnen ermöglicht, einen Wissensspeicher im Skillset zu definieren, der Ihre Anreicherungspipeline kapselt. Der Wissensspeicher besteht aus Projektionen der angereicherten Daten, bei denen es sich um JSON-Objekte, Tabellen oder Bilddateien handeln kann. Wenn ein Indexer die Pipeline ausführt, um einen Index zu erstellen oder zu aktualisieren, werden die Projektionen generiert und im Wissensspeicher dauerhaft gespeichert.
Tipp
Weitere Informationen zur Verwendung eines Wissensspeichers finden Sie im Wissensspeicher in Azure AI Search in der Azure AI Search-Dokumentation.