Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Note
Wissensspeicher sind sekundärer Speicher, der in Azure Storage vorhanden ist und die Ausgaben von Azure AI Search-Skillsets enthält. Sie sind von Wissensquellen und Wissensdatenbanken getrennt, die in agentischen Abrufworkflows verwendet werden.
Der Wissensspeicher ist ein sekundärer Speicher für KI-angereicherte Inhalte, das von einem Skillset erstellt wurde in Azure AI Search. In Azure KI-Suche sendet ein Indizierungsauftrag immer die Ausgabe an einen Suchindex. Wenn Sie jedoch ein Skillset an einen Indexer anfügen, können Sie optional auch KI-angereicherte Ausgaben an einen Container oder eine Tabelle in Azure Storage senden. Ein Wissensspeicher kann für unabhängige Analysen oder nachgeschaltete Verarbeitung in Nicht-Suchszenarien wie Knowledge Mining verwendet werden.
Diese beiden Ausgaben der Indizierung – Suchindex und Wissensspeicher – sind sich gegenseitig ausschließende Produkte derselben Pipeline. Sie sind aus denselben Eingaben abgeleitet und enthalten dieselben Daten, aber ihre Inhalte werden in unterschiedlichen Anwendungen strukturiert, gespeichert und verwendet.

Physisch betrachtet handelt es sich bei einem Wissensspeicher um Azure Storage (Azure Table Storage, Azure Blob Storage oder beides). Jedes Tool und jeder Prozess, das bzw. der eine Verbindung mit Azure Storage herstellen kann, kann die Inhalte eines Wissensspeichers nutzen. Es gibt keine Abfrageunterstützung in Azure KI-Suche zum Abrufen von Inhalten aus einem Wissensspeicher.
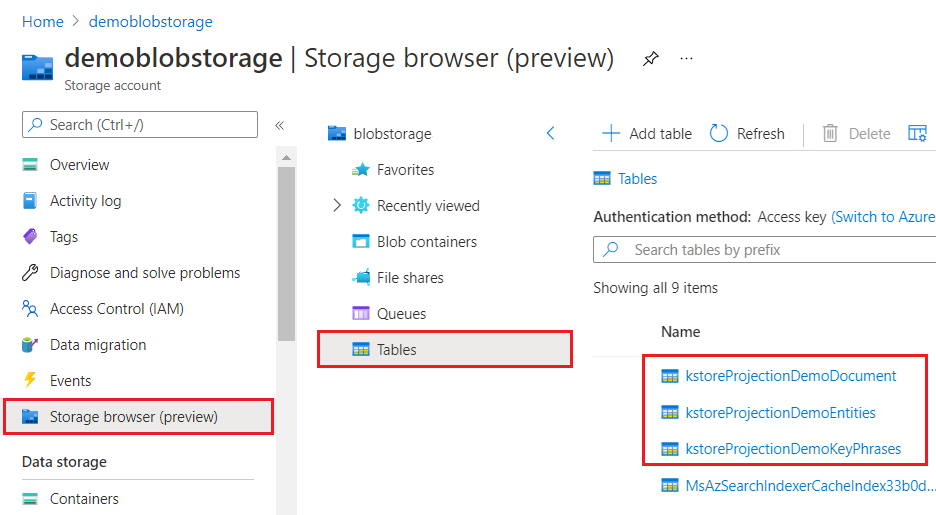
In der Ansicht des Azure-Portals sieht ein Wissensspeicher wie jede andere Sammlung von Tabellen, Objekten oder Dateien aus. Der folgende Screenshot zeigt einen aus drei Tabellen bestehenden Wissensspeicher. Sie können eine Benennungskonvention anwenden, z. B. ein kstore -Präfix, um die Inhalte zusammenzuhalten.
Vorteile von Wissensspeichern
Die Hauptvorteile eines Wissensspeichers sind der flexible Zugriff auf Inhalte und die Fähigkeit, Daten zu strukturieren.
Im Gegensatz zu einem Suchindex, auf den nur über Abfragen in Azure KI-Suche zugegriffen werden kann, kann von jedem Tool, jeder App oder jedem Prozess, der Verbindungen zu Azure Storage unterstützt, auf einen Wissensspeicher zugegriffen werden. Diese Flexibilität eröffnet neue Szenarien für die Nutzung der analysierten und angereicherten Inhalte, die von einer Anreicherungspipeline erzeugt werden.
Das gleiche Skillset, das Daten anreichert, kann auch zum Strukturieren von Daten verwendet werden. Einige Tools wie Power BI funktionieren besser mit Tabellen, während eine Data Science-Workload möglicherweise eine komplexe Datenstruktur in einem Blobformat erfordert. Das Hinzufügen einer Shaper-Skill zu einem Skillset gibt Ihnen die Kontrolle über die Strukturierung Ihrer Daten. Sie können diese Strukturierungen dann an Projektionen übergeben, bei denen es sich entweder um Tabellen oder Blobs handelt, um physische Datenstrukturen zu erstellen, die der beabsichtigten Verwendung der Daten entsprechen.
Im folgenden Video werden diese und weitere Vorteile erläutert.
Definition des Wissensspeichers
Ein Wissensspeicher wird in einer Skillsetdefinition definiert und besteht aus zwei Komponenten:
Eine Verbindungszeichenfolge für Azure Storage
Projektionen, die bestimmen, ob der Wissensspeicher aus Tabellen, Objekten oder Dateien besteht. Das Projektionselement ist ein Array. Sie können mehrere Sätze von Tabellenobjekt-Datei-Kombinationen innerhalb eines Wissensspeichers erstellen.
"knowledgeStore": { "storageConnectionString":"<YOUR-AZURE-STORAGE-ACCOUNT-CONNECTION-STRING>", "projections":[ { "tables":[ ], "objects":[ ], "files":[ ] } ] }
Der Typ der Projektion, den Sie in dieser Struktur angeben, bestimmt den vom Wissensspeicher verwendeten Speichertyp, aber nicht seine Struktur. Felder in Tabellen, Objekten und Dateien werden durch die Shaper-Qualifikationsausgabe bestimmt, wenn Sie den Wissensspeicher programmgesteuert oder durch den Importdaten-Assistenten erstellen, wenn Sie das Azure-Portal verwenden.
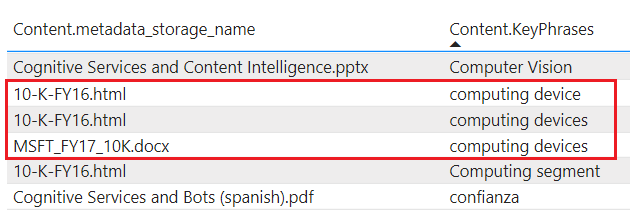
tablesprojizieren angereicherte Inhalte in Table Storage. Definieren Sie eine Tabellenprojektion, wenn Sie tabellarische Berichtsstrukturen für Eingaben in Analysetools benötigen oder als Datenrahmen in andere Datenspeicher exportieren müssen. Sie können mehreretables-Objekte in derselben Projektionsgruppe angeben, um eine Teilmenge oder einen Querschnitt angereicherter Dokumente zu erhalten. Tabellenbeziehungen innerhalb derselben Projektionsgruppe bleiben erhalten, sodass Sie mit allen arbeiten können.Projizierter Inhalt wird nicht aggregiert oder normalisiert. Der folgende Screenshot zeigt eine nach Schlüsselbegriffen sortierte Tabelle mit dem übergeordneten Dokument, das in der angrenzenden Spalte angegeben ist. Im Gegensatz zur Datenerfassung während der Indizierung gibt es keine linguistische Analyse oder Aggregation von Inhalten. Pluralformen und Unterschiede bei der Groß-/Kleinschreibung werden als eindeutige Instanzen betrachtet.
objectsprojizieren JSON-Dokumente in Blob Storage. Die physische Darstellung einesobjectist eine hierarchische JSON-Struktur, die ein angereichertes Dokument darstellt.filesprojizieren Bilddateien in den Blob-Speicher. Bei einerfilehandelt es sich um ein aus einem Dokument extrahiertes Bild, das intakt in Blob Storage übertragen wurde. Obwohl es als "Dateien" bezeichnet wird, wird es in Blob Storage und nicht im Dateispeicher angezeigt.
Erstellen von Wissensspeichern
Verwenden Sie das Azure-Portal, REST-APIs oder ein Azure SDK-Paket, um einen Wissensspeicher zu erstellen. Alle Methoden erfordern Azure Storage, ein Skillset und einen Indexer. Da Indexer einen Suchindex benötigen, müssen Sie auch eine Indexdefinition angeben.
REST-APIs und SDKs bieten volle Kontrolle über Projektionen: Tabellen, Objekte und Dateien. Das Azure-Portal erstellt automatisch einen Wissensspeicher als Teil des multimodalen RAG-Workflows, der auf Dateiprojektionen für extrahierte Bilder beschränkt ist.
Der Assistent zum Importieren von Daten erstellt einen Wissensspeicher nur für das multimodale RAG-Szenario. Informationen zu den ersten Schritten finden Sie in der Schnellstartanleitung: Multimodale Suche im Azure-Portal.
Herstellen einer Verbindung mit Apps
Sobald angereicherte Inhalte im Speicher vorhanden sind, können diese mit beliebigen Tools oder Technologien, die über eine Verbindung mit Azure Storage verfügen, untersucht, analysiert oder genutzt werden. Die folgende Liste gibt einen ersten Einblick:
Storage-Explorer oder Speicherbrowser im Azure-Portal zum Anzeigen der Struktur und Inhalte angereicherter Dokumente. Nutzen Sie dies als Ihr Basistool zum Anzeigen des Inhalts von Wissensspeichern.
Nutzen Sie Power BI für die Berichterstellung und Analyse.
Verwenden Sie Azure Data Factory für die weiterführende Bearbeitung.
Inhaltslebenszyklus
Bei jeder Ausführung des Indexers und des Skillsets wird der Wissensspeicher aktualisiert, wenn sich das Skillset oder die zugrunde liegenden Quelldaten geändert haben. Alle vom Indexer übernommenen Änderungen werden über den Anreicherungsprozess an die Projektionen im Wissensspeicher weitergegeben, um sicherzustellen, dass Ihre projizierten Daten eine aktuelle Darstellung des Inhalts in der ursprünglichen Datenquelle sind.
Note
Während Sie die Daten in den Projektionen bearbeiten können, werden alle Änderungen beim nächsten Pipelineaufruf überschrieben, vorausgesetzt, das Dokument in den Quelldaten wird aktualisiert.
Änderungen an Quelldaten
Für Datenquellen, die die Änderungsnachverfolgung unterstützen, verarbeitet ein Indexer neue und geänderte Dokumente und umgeht vorhandene Dokumente, die bereits verarbeitet wurden. Zeitstempelinformationen variieren je nach Datenquelle, aber in einem Blobcontainer untersucht der Indexer das lastmodified-Datum, um zu bestimmen, welche Blobs erfasst werden müssen.
Änderungen an einem Skillset
Wenn Sie Änderungen an einem Skillset vornehmen, sollten Sie das Zwischenspeichern angereicherter Dokumente aktivieren, um vorhandene Anreicherungen nach Möglichkeit wiederzuverwenden.
Ohne inkrementelles Zwischenspeichern verarbeitet der Indexer Dokumente immer in der Reihenfolge des hohen Grenzwerts, ohne rückwärts zu gehen. Blobs verarbeitet der Indexer nach lastModified sortiert, unabhängig von Änderungen an den Indexereinstellungen oder am Skillset. Wenn Sie ein Skillset ändern, werden zuvor verarbeitete Dokumente nicht aktualisiert, um das neue Skillset widerzuspiegeln. Dokumente, die nach der Änderung des Skillsets verarbeitet werden, verwenden das neue Skillset, was dazu führt, dass Indexdokumente eine Mischung aus alten und neuen Skillsets sind.
Beim inkrementellen Zwischenspeichern und nach einer Aktualisierung des Skillsets verwendet der Indexer erneut alle Anreicherungen, die von der Änderung des Skillsets nicht betroffen sind. Upstreamanreicherungen werden aus dem Cache abgerufen, ebenso wie alle Anreicherungen, die unabhängig und von der geänderten Qualifikation isoliert sind.
Deletions
Ein Indexer kann zwar Strukturen und Inhalte in Azure Storage erstellen und aktualisieren, aber nicht löschen. Projektionen sind auch dann weiterhin vorhanden, wenn Indexer oder Skillset gelöscht wird. Als Besitzer des Speicherkontos sollten Sie eine Projektion löschen, wenn sie nicht mehr benötigt wird.
Nächste Schritte
Ein Wissensspeicher ermöglicht die Aufbewahrung angereicherter Dokumente, was bei der Entwicklung eines Skillsets hilfreich ist, sowie die Erstellung neuer Strukturen und Inhalte zur Nutzung durch beliebige Clientanwendungen, die auf ein Azure Storage-Konto zugreifen können.
Der einfachste Ansatz zum programmgesteuerten Erstellen von erweiterten Dokumenten ist die Verwendung von REST-APIs.