Maschinelles Lernen für maschinelles Sehen
Die Möglichkeit, Filter zum Anwenden von Effekten auf Bilder zu verwenden, ist nützlich bei Bildverarbeitungsaufgaben, wie Sie sie beispielsweise mit Bildbearbeitungssoftware durchführen können. Das Ziel des maschinellen Sehens ist es jedoch oft, Bedeutung, oder zumindest umsetzbare Erkenntnisse aus Bildern, zu extrahieren; dies erfordert die Erstellung von Machine Learning-Modellen, die darauf trainiert werden, Merkmale basierend auf großen Mengen vorhandener Bilder zu erkennen.
Tipp
In dieser Lektion wird davon ausgegangen, dass Sie mit den Grundlegenden Prinzipien des maschinellen Lernens vertraut sind und dass Sie über konzeptionelle Kenntnisse von Deep Learning mit neuronalen Netzen verfügen. Wenn Sie noch keine Erfahrung mit maschinellem Lernen haben, sollten Sie die das Modul Grundlagen des maschinelles Lernens in Microsoft Learn abschließen.
Convolutional Neural Networks (CNNs)
Eine der am häufigsten verwendeten Machine Learning-Modellarchitekturen für maschinelles Sehen ist ein konvolutionales neuronales Netzwerk (Convolutional Neural Network, CNN). CNNs verwenden Filter, um numerische Merkmalszuordnungen aus Bildern zu extrahieren und dann die Merkmalswerte in ein Deep Learning-Modell zu übertragen, um eine Bezeichnungsvorhersage zu generieren. In einem Bildklassifizierungsszenario stellt die Bezeichnung z. B. das Hauptthema des Bilds dar (anders gesagt, was zeigt das Bild?). Sie können ein CNN-Modell mit Bildern verschiedener Arten von Obst (z. B. Apfel, Banane und Orange) trainieren, damit die vorhergesagte Bezeichnung die Art von Obst in einem bestimmten Bild ist.
Während des Trainingsprozesses für ein CNN werden Filterkerne zunächst mithilfe von zufällig generierten Gewichtungswerten definiert. Wenn der Trainingsprozess voranschreitet, werden die Modellvorhersagen anhand bekannter Bezeichnungswerte ausgewertet, und die Filtergewichte werden angepasst, um die Genauigkeit zu verbessern. Schließlich verwendet das trainierte Obst-Bildklassifizierungsmodell die Filtergewichte, die am besten Merkmale zur Identifizierung verschiedener Arten von Obst extrahieren.
Das folgende Diagramm veranschaulicht, wie ein CNN für ein Bildklassifizierungsmodell funktioniert:
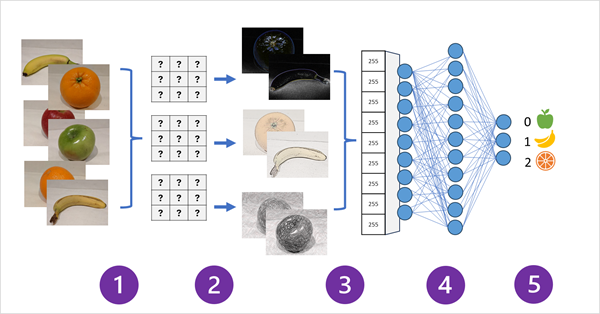
- Bilder mit bekannten Bezeichnungen (z. B. 0: Apfel, 1: Banane oder 2: Orange) werden in das Netzwerk eingespeist, um das Modell zu trainieren.
- Eine oder mehrere Ebenen von Filtern werden verwendet, um Merkmale aus jedem Bild zu extrahieren, während es in das Netzwerk eingespeist wird. Die Filterkerne beginnen mit zufällig zugewiesenen Gewichtungen und generieren Arrays numerischer Werte, die als Merkmalszuordnungen bezeichnet werden.
- Die Merkmalszuordnungen werden in ein einzelnes dimensionales Array mit Merkmalswerten abgeflacht.
- Die Merkmalswerte werden in ein vollständig verbundenes neuronales Netz eingespeist.
- Die Ausgabeschicht des neuronalen Netzes verwendet eine Softmax- oder ähnliche Funktion, um ein Ergebnis zu erzeugen, das einen Wahrscheinlichkeitswert für jede mögliche Klasse enthält, z. B. [0,2, 0,5, 0,3].
Während des Trainings werden die Ausgabewahrscheinlichkeiten mit der tatsächlichen Klassenbezeichnung verglichen, z. B. sollte ein Bild einer Banane (Klasse 1) den Wert [0,0, 1,0, 0,0] aufweisen. Der Unterschied zwischen den vorhergesagten und tatsächlichen Klassenergebnissen wird verwendet, um den Verlust im Modell zu berechnen, und die Gewichte im vollständig verbundenen neuronalen Netz und die Filterkerne in den Merkmalsextraktionsschichten werden geändert, um den Verlust zu verringern.
Der Trainingsprozess wiederholt sich über mehrere Epochen, bis eine optimale Reihe von Gewichten gelernt wurde. Anschließend werden die Gewichtungen gespeichert, und das Modell kann verwendet werden, um Bezeichnungen für neue Bilder vorherzusagen, für die die Bezeichnung unbekannt ist.
Hinweis
CNN-Architekturen enthalten in der Regel mehrere konvolutionale Filterebenen und zusätzliche Ebenen, um die Größe von Merkmalszuordnungen zu verringern, die extrahierten Werte einzuschränken und die Merkmalswerte anderweitig zu manipulieren. Diese Ebenen wurden in diesem vereinfachten Beispiel weggelassen, um sich auf das Schlüsselkonzept zu konzentrieren, d. h., dass Filter verwendet werden, um numerische Merkmale aus Bildern zu extrahieren, die dann in einem neuronalen Netz verwendet werden, um Bildbezeichnungen vorherzusagen.
Transformer und multimodale Modelle
CNNs stehen seit vielen Jahren im Mittelpunkt von Lösungen für maschinelles Sehen. Sie werden zwar häufig verwendet, um Bildklassifizierungsprobleme wie zuvor beschrieben zu lösen, sie sind aber auch die Grundlage für komplexere Modelle für maschinelles Sehen. Beispielsweise kombinieren Objekterkennungsmodelle CNN-Merkmalsextraktionsebenen mit der Identifizierung von relevanten Bereichen in Bildern, um mehrere Objektklassen im selben Bild zu finden.
Transformatoren
Die meisten Fortschritte beim maschinellen Sehen im Laufe der Jahrzehnte wurden durch Verbesserungen in CNN-basierten Modellen angetrieben. In einer anderen KI-Disziplin, linguistischer Datenverarbeitung (Natural Language Processing, NLP), hat jedoch eine andere Art von neuronaler Netzarchitektur, die als Transformer bezeichnet wird, die Entwicklung anspruchsvoller Modelle für Sprache ermöglicht. Transformer arbeiten durch die Verarbeitung gewaltiger Datenmengen und codieren Sprach-Token (die einzelne Wörter oder Ausdrücke darstellen) als vektorbasierte Einbettungen (Arrays numerischer Werte). Sie können sich eine Einbettung als Darstellung einer Reihe von Dimensionen vorstellen, die jeweils ein semantisches Attribut des Tokens darstellen. Die Einbettungen werden so erstellt, dass Token, die häufig im selben Kontext verwendet werden, dimensional näher beieinander sind als nicht verwandte Wörter.
Als einfaches Beispiel zeigt das folgende Diagramm einige Wörter, die als dreidimensionale Vektoren kodiert und in einen 3D-Raum eingezeichnet sind:
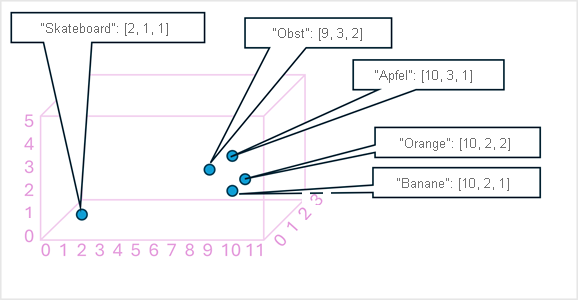
Token, die semantisch ähnlich sind, werden an ähnlichen Positionen codiert und erstellen so ein semantisches Sprachmodell, das es ermöglicht, anspruchsvolle NLP-Lösungen für Textanalyse, Übersetzung, Sprachgenerierung und andere Aufgaben zu erstellen.
Hinweis
Wir haben nur drei Dimensionen verwendet, da dies einfach zu visualisieren ist. In Wirklichkeit erstellen Encoder in Transformernetzwerken Vektoren mit vielen weiteren Dimensionen und definieren komplexe semantische Beziehungen zwischen Token basierend auf linearen algebraischen Berechnungen. Die beteiligte Mathematik ist komplex, ebenso wie die Architektur eines Transformermodells. Unser Ziel ist es hier, nur ein konzeptionelles Verständnis dafür zu bieten, wie die Codierung ein Modell erstellt, das Beziehungen zwischen Entitäten kapselt.
Multimodale Modelle
Der Erfolg von Transformern als Möglichkeit zum Erstellen von Sprachmodellen hat KI-Forscher dazu geführt, zu überlegen, ob derselbe Ansatz für Bilddaten effektiv wäre. Das Ergebnis ist die Entwicklung von multimodalen Modellen, bei denen das Modell mit einem großen Volumen von beschrifteten Bildern trainiert wird, ohne feste Bezeichnungen. Ein Bild-Encoder extrahiert basierend auf Pixelwerten Merkmale aus Bildern und kombiniert sie mit Texteinbettungen, die von einem Sprach-Encoder erstellt wurden. Das allgemeine Modell kapselt Beziehungen zwischen Token-Einbettungen in natürlicher Sprache und Bildmerkmalen, wie hier gezeigt:
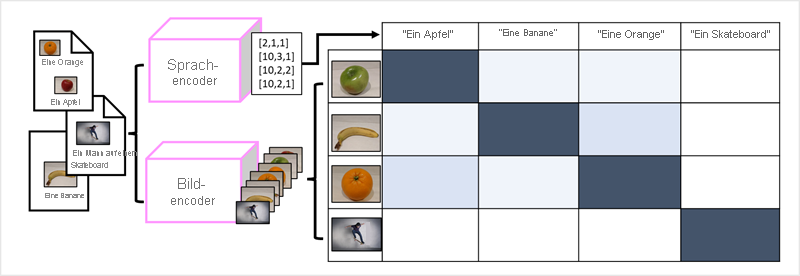
Das Microsoft Florence-Modell ist nur ein solches Modell. Trainiert mit gewaltigen Mengen von beschrifteten Bildern aus dem Internet, enthält es sowohl einen Sprach-Encoder als auch einen Bild-Encoder. Florence ist ein Beispiel für ein Foundation-Modell. Mit anderen Worten, ein vortrainiertes allgemeines Modell, auf dessen Grundlage Sie mehrere adaptive Modelle für spezialisierte Aufgaben erstellen können. Beispielsweise können Sie Florence als Foundation-Modell für adaptive Modelle verwenden, die folgendes ausführen:
- Bildklassifizierung: Identifizieren, zu welcher Kategorie ein Bild gehört.
- Objekterkennung: Lokalisieren einzelner Objekte innerhalb eines Bilds.
- Beschriftung: Generieren geeigneter Beschreibungen von Bildern.
- Tagging: Kompilieren einer Liste relevanter Texttags für ein Bild.
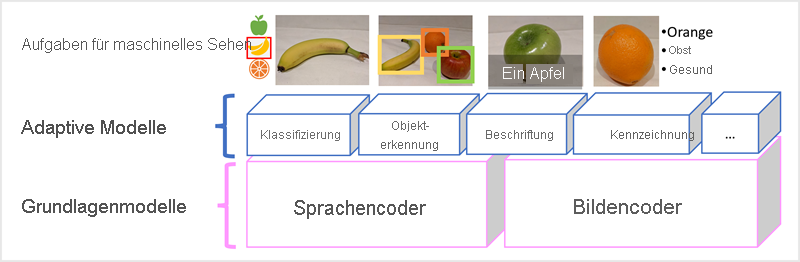
Multimodale Modelle wie Florence sind im Allgemeinen auf dem neuesten Stand von maschinellem Sehen und KI im Allgemeinen, und es wird erwartet, dass sie Fortschritte in den Arten von Lösungen bringen werden, die KI möglich macht.