Automatische Skalierung in der Cloud
Cloudadministratoren können manuell zentral oder horizontal hochskalieren, um die steigende Nachfrage zu verarbeiten, oder zentral oder horizontal herunterskalieren, um die Kosten zu senken. Beispielsweise kann ein aufmerksamer Administrator erkennen, dass die Nachfrage zunimmt, und die von Clouddienstanbietern bereitgestellten Tools verwenden, um zusätzliche VMs online zu schalten (horizontales Hochskalieren) oder vorhandene VMs durch größere VMs zu ersetzen, die über mehr CPU und mehr Arbeitsspeicher verfügen (zentrales Hochskalieren). Das Schlüsselwort ist „aufmerksam“. Wenn die Nachfrage ihren Höchstwert erreicht und dies von niemandem bemerkt wird, kann das System als Ganzes für Endbenutzer langsam werden oder sogar überhaupt nicht mehr reagieren. Wenn Sie dagegen zentral oder horizontal hochskalieren, um größere Auslastungen zu bewältigen, und bei einem Rückgang der Auslastung nicht zurückskalieren, bezahlen Sie letztendlich für Ressourcen, die Sie nicht benötigen.
Daher bieten beliebte Cloudplattformen Mechanismen für eine automatische Skalierung an, um Ressourcen als Reaktion auf den schwankenden Bedarf ohne menschliches Eingreifen zu skalieren. Die automatische Skalierung besteht aus zwei primären Ansätzen:
Zeitbasiert: Skalieren Sie Ressourcen nach einem vordefinierten Zeitplan. Wenn beispielsweise die Website Ihrer Organisation die höchsten Auslastungen während der Arbeitszeiten hat, konfigurieren Sie die automatische Skalierung so, dass die Ressourcen jeden Morgen um 08:00 Uhr hochskaliert und jeden Nachmittag um 17:00 Uhr herunterskaliert werden. Die zeitbasierte Skalierung wird mitunter als geplante Skalierung bezeichnet.
Metrikbasiert: Wenn die Auslastungen weniger vorhersagbar sind, skalieren Sie Ressourcen basierend auf vordefinierten Metriken wie der CPU-Auslastung, Speicherauslastung oder durchschnittlichen Anforderungswartezeit. Wenn beispielsweise die durchschnittliche CPU-Auslastung 70 % erreicht, schalten Sie automatisch zusätzliche VMs online, und wenn sie auf 30 % zurückgeht, heben Sie die Bereitstellung der zusätzlichen VMs auf.
Unabhängig davon, ob Sie auf der Grundlage von Zeit oder Metriken oder beidem skalieren, basiert die automatische Skalierung auf Skalierungsregeln oder Skalierungsrichtlinien von einem Cloudadministrator. Moderne Cloudplattformen unterstützen Skalierungsregeln, die von einfachen Regeln, wie z. B. der Erweiterung von zwei auf vier Instanzen täglich um 08:00 Uhr und der Wiederherstellung auf zwei Instanzen um 17:00 Uhr, bis hin zu komplexen Regeln reichen. Erhöhen Sie beispielsweise die VM-Anzahl um eins, wenn die maximale CPU-Auslastung 70 % überschreitet oder die durchschnittliche Anforderungswartezeit 5 Sekunden erreicht. Der Cloudadministrator muss in der Regel etwas experimentieren, um die richtige Kombination von Regeln zu finden.
Alle großen Clouddienstanbieter, einschließlich Amazon, Microsoft und Google, unterstützen die automatische Skalierung. AWS Auto Scaling kann auf EC2-Instanzen, DynamoDB-Tabellen und ausgewählten anderen AWS-Clouddienste angewendet werden. Azure stellt Optionen für die automatische Skalierung für wichtige Dienste bereit, einschließlich App Service und Virtual Machines. Google macht dasselbe für Google Compute Engine und Google App Engine.
Im Allgemeinen skalieren Dienste mit automatischer Skalierung horizontal anstatt zentral hoch und herunter, da das zentrale Hoch- und Herunterskalieren erfordert, dass eine Instanz durch eine andere ersetzt wird und unweigerlich zu einer Ausfallzeit führt, wenn neue Instanzen erstellt und online geschaltet werden.
Zeitbasierte automatische Skalierung
Die zeitbasierte automatische Skalierung ist geeignet, wenn die Auslastung in vorhersagbarer Weise schwankt. Beispielsweise haben die IT-Systeme vieler Unternehmen die höchste Auslastung während den Arbeitszeiten, während es in den früher Morgenstunden kaum zu einer Auslastung kommt. Die Website von Domino’s Pizza kann zu jeder Tageszeit ausgelastet sein, da sie mehr als 16.000 Filialen in fast 100 Ländern/Regionen betreibt. Es ist jedoch vorhersehbar, dass die Auslastung zu bestimmten Zeiten im Jahr höher ist als normal.
Beide Szenarios eignen sich für die zeitbasierte automatische Skalierung. Abbildung 7 zeigt, wie die geplante automatische Skalierung in Azure umgesetzt wird. In diesem Beispiel konfiguriert ein Cloudadministrator eine Azure App Service-Instanz, die die Website der Organisation hostet, um standardmäßig zwei Instanzen ausführen, aber vier Instanzen zwischen 06:00 Uhr und 18:00 Uhr an sechs Tagen der Woche (ohne Sonntag) hochskalieren zu können. Wenn der Administrator stattdessen die Option „Start-/Enddatum angeben“ auswählt, könnte er App Service so konfigurieren, dass am Sonntag vom Super Bowl auf zehn Instanzen horizontal hochskaliert wird. Zudem könnte er mehrere Skalierungsbedingungen definieren, sodass auch an anderen Daten horizontal hochskaliert wird.
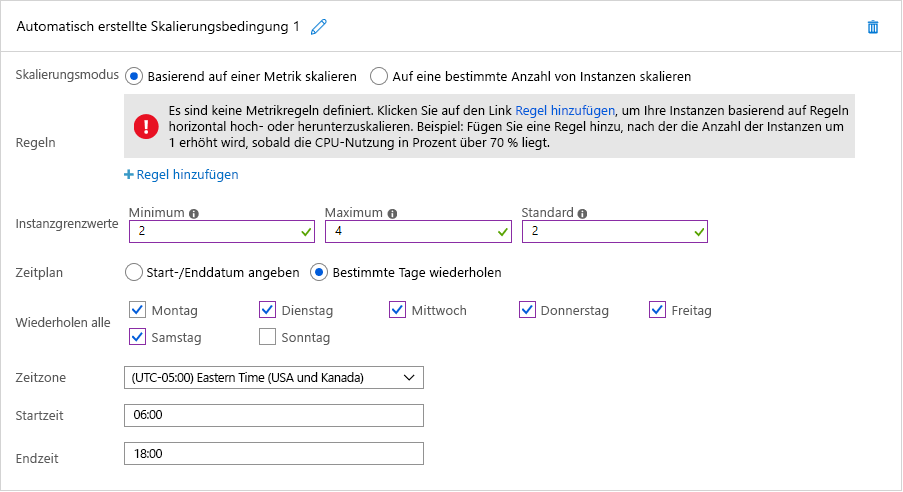
Abbildung 7: Geplante automatische Skalierung in Azure
Automatische metrikenbasierte Skalierung
Für den Fall, dass sich die Auslastung schlecht vorhersagen lässt, empfiehlt es sich, eine auf Metriken wie CPU-Auslastung und durchschnittlicher Wartezeit pro Anforderung basierende Skalierung zu verwenden. Eine solche Skalierung kann jedoch nur funktionieren, wenn das Tool für die automatische Skalierung weiß, wann sie nötig ist. Deshalb spielt Überwachung hier eine große Rolle. Durch Analyse von Datenverkehrsmustern oder Ressourcenverwendung wird entschieden, wann und wie stark bei den Ressourcen skaliert werden muss, um die optimale Kombination aus bestmöglicher Dienstqualität und geringstmöglichen Kosten zu erreichen.
Bei Ressourcen gibt es mehrere Aspekte, die überwacht werden, weil sie eine Skalierung erforderlich machen könnten. Die häufigste Metrik ist die Ressourcenverwendung. Ein Überwachungsdienst kann z. B. die CPU-Auslastung der einzelnen Ressourcenknoten nachverfolgen und die Ressourcen skalieren, wenn die Auslastung zu hoch oder zu niedrig ist. Wenn z. B. bei jeder Ressource eine Auslastung von mehr als 90 % vorliegt, sollten zusätzliche Ressourcen hinzugefügt werden, da das System stark ausgelastet ist. Normalerweise legen die Dienstanbieter fest, wann eine Skalierung ausgelöst werden soll. Dazu bestimmen sie den Punkt, an dem ein Ressourcenknoten wegen Überlastung nicht mehr korrekt arbeitet, und geben zusätzlich Aktionen für verschiedene Auslastungsstufen an. Obwohl aus Kostengründen jede Ressource maximal ausgelastet sein sollte, empfiehlt es sich, noch Kapazitäten für entstehenden Betriebssystemmehraufwand freizuhalten. Umgekehrt gilt bei einer niedrigen Auslastung von z. B. 30 %, dass nicht alle Ressourcenknoten benötigt werden, und ihre Bereitstellung teilweise aufgehoben werden kann.
In der Praxis überwachen Dienstanbieter normalerweise eine Kombination verschiedener Metriken eines Ressourcenknotens, um zu bewerten, wann eine Ressourcenskalierung nötig ist. Dazu zählen z. B. CPU-Auslastung, Arbeitsspeichernutzung, Durchsatz und Latenz. AWS verwendet CloudWatch, um EC2-Ressourcen zu überwachen und Metriken für die Skalierung bereitzustellen (Abbildung 8). CloudWatch überwacht die Metriken aller EC2-Instanzen in einer Skalierungsgruppe und löst einen Alarm aus, wenn eine bestimmte Metrik, z. B. die CPU-Auslastung, einen Schwellenwert überschreitet, z. B. 70%. AWS erhöht bzw. verringert dann die Zahl der EC2-Instanzen gemäß den von einem Administrator konfigurierten Skalierungsrichtlinien.
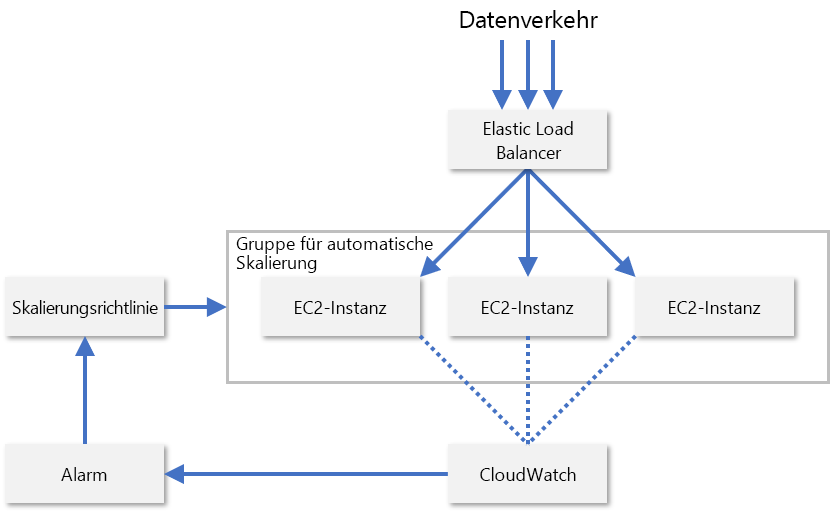
Abbildung 8: Automatische Skalierung von EC2-Instanzen in AWS
AWS unterstützt auch die vorausdenkende Skalierung, eine Funktion, bei der mithilfe von maschinellem Lernen versucht wird, Datenverkehrsmuster vorauszusagen und die Instanzenzahl entsprechend anzupassen. Ziel ist es, Cloudressourcen intelligent skalieren zu können, ohne dass vorher ein Cloudadministrator Regeln für die automatische Skalierung erstellen muss. Wichtige Cloud-Dienstanbieter entwickeln ständig neue Möglichkeiten, ihre Plattformen mit maschinellem Lernen zu verbessern. Microsoft zum Beispiel verwendet maschinelles Lernen, um die Resilienz von Azure Virtual Machines zu verbessern, indem VM-Fehler proaktiv vorhergesagt und entschärft werden1.
References
- Microsoft (2018). Verbessern der Resilienz von Azure-VMs durch Vorhersagen basierend auf maschinellem Lernen und durch Livemigration. https://azure.microsoft.com/blog/improving-azure-virtual-machine-resiliency-with-predictive-ml-and-live-migration/.