Lastenausgleich
Bei zunehmendem Datenverkehr stellt die horizontale Skalierung eine effektive Maßnahme zur Deckung des Bedarfs dar, indem neue virtuelle Computer online geschaltet werden. Für diese Flexibilität ist entscheidend, dass virtuelle Computer schnell bereitgestellt werden können. Zusätzliche Server sind jedoch nur dann von Nutzen, wenn der Datenverkehr auch auf diese Server verteilt wird. Dadurch kann das System die erhöhte Last bewältigen. Aus diesem Grund ist der Lastenausgleich für die Flexibilität genauso wichtig wie die dynamische Anpassung der Ressourcen für eine Aufgabe.
Zwei grundlegende Anforderungen machen den Lastenausgleich erforderlich. Erstens wird der Durchsatz durch eine parallele Verarbeitung erhöht. Schafft es ein einzelner Server, 5.000 Anforderungen pro Zeiteinheit zu verarbeiten, können zehn Server mit optimalem Lastenausgleich 50.000 Anforderungen pro Zeiteinheit verarbeiten. Zweitens erzielen Ressourcen mit Lastenausgleich eine höhere Verfügbarkeit. Anstatt eine Anforderung an einen Server weiterzuleiten, der bereits nahe der Auslastungsgrenze arbeitet, kann ein Load Balancer die Anforderung an einen Server mit geringerer Auslastung weiterleiten. Wenn ein Server offline geht und der Lastenausgleich dies erkennt, kann er außerdem Anforderungen an andere Server weiterleiten.
Was ist ein Lastenausgleich?
Eine bekannte Art des Lastenausgleichs stellt Roundrobin-DNS dar, das von vielen großen Webdiensten zum Verteilen von Anforderungen auf mehrere Servern verwendet wird. Mehrere Front-End-Server mit jeweils einer eindeutigen IP-Adresse verwenden einen gemeinsamen DNS-Namen. Große Unternehmen wie Google verwalten und erstellen für jeden DNS-Eintrag einen Pool mit IP-Adressen, um die Anzahl der Anforderungen gleichmäßig auf die einzelnen Webserver zu verteilen. Wenn ein Client eine Anforderung sendet (z. B. an www.google.com), wählt das DNS von Google eine der verfügbaren Adressen im Pool aus und sendet sie an den Client. Die einfachste Möglichkeit zur Verteilung von IP-Adressen ist die Verwendung einer Roundrobin-Warteschlange, bei der nach jeder DNS-Antwort die Liste der Adressen umgestellt wird.
Vor dem Aufkommen der Cloud stellte der DNS-Lastenausgleich eine einfache Möglichkeit zur Verringerung der Wartezeit bei Fernverbindungen dar. Der Verteiler auf dem DNS-Server wurde so programmiert, dass er mit der IP-Adresse des Servers antwortete, der dem Client geografisch am nächsten war. Dies wurde dadurch erreicht, dass die IP-Adresse im Pool, die der IP-Adresse des Clients numerisch am ähnlichsten war, für die Antwort verwendet wurde. Da IP-Adressen jedoch nicht global hierarchisch verteilt werden, war diese Methode unzuverlässig. Die aktuelle Vorgehensweise ist komplexer: Sie beruht auf einer Softwarezuordnung zwischen IP-Adressen und Standorten, die auf physischen Karten von Internetdienstanbietern basiert. Diese Methode führt zu besseren Ergebnissen, ist in der Berechnung jedoch teuer, da die Zuordnung als kostenaufwändige Softwaresuche implementiert ist. Die Kosten für eine langsame Suche amortisieren sich jedoch, da eine DNS-Suche nur dann ausgeführt wird, wenn die erste Verbindung zu einem Server vom Client hergestellt wird. Die nachfolgende Kommunikation erfolgt dann direkt zwischen dem Client und dem Server, der die verteilte IP-Adresse besitzt. Abbildung 9 zeigt das Beispielschema eines DNS-Lastenausgleichs.
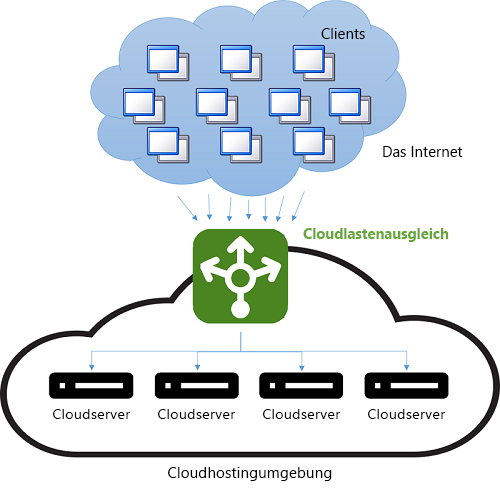
Abbildung 9: Lastenausgleich in einer Cloudumgebung
Der Nachteil dieser Methode zeigt sich bei einem Serverfehler, da der Wechsel zu einer anderen IP-Adresse von der konfigurierten Gültigkeitsdauer des DNS-Caches abhängt. DNS-Einträge besitzen eine lange Gültigkeitsdauer, und die Weitergabe von Updates dauert bekanntermaßen länger als eine Woche. Dies bedeutet, dass Serverfehler nur schwer vom Client verborgen werden können. Das Verkürzen der Gültigkeitsdauer einer IP-Adresse im Cache kann hier zwar Abhilfe schaffen, führt jedoch zu Leistungseinbußen und einer höheren Anzahl von Suchvorgängen.
Moderne Formen des Lastenausgleichs verwenden häufig eine dedizierte Instanz (oder ein Instanzenpaar), um eingehende Anforderungen an Back-End-Server zu verteilen. Bei jeder an einem angegebenen Port eingehenden Anforderung leitet der Load Balancer den Datenverkehr gemäß einer Verteilungsstrategie an einen der Back-End-Server um. Dabei verwaltet der Load Balancer die Metadaten der Anforderung, wie etwa Anwendungsprotokollheader (z. B. HTTP-Header). Da jede Anforderung den Load Balancer durchläuft, spielen veraltete Informationen hier keine Rolle.
Während alle Arten von Load Balancers für Netzwerke Anforderungen an die Back-End-Server zusammen mit jeglichem Kontext weiterleiten, stehen ihnen beim Zurücksenden der Antwort an den Client zwei grundlegende Strategien zur Verfügung1:
Proxyfunktion: Bei dieser Vorgehensweise empfängt der Load Balancer die Antwort vom Back-End-Server und leitet sie an den Client weiter. Der Load Balancer verhält sich wie ein Standardwebproxy und ist an beiden Teilen der Netzwerktransaktion beteiligt, d. h. an der Weiterleitung der Anforderung an den Client und am Zurücksenden der Antwort.
TCP-Übergabe: Hier wird die TCP-Verbindung mit dem Client an den Back-End-Server weitergegeben, der die Antwort direkt an den Client sendet, ohne Durchlaufen des Load Balancers.
Die zweite Strategie wird in Abbildung 10 dargestellt.
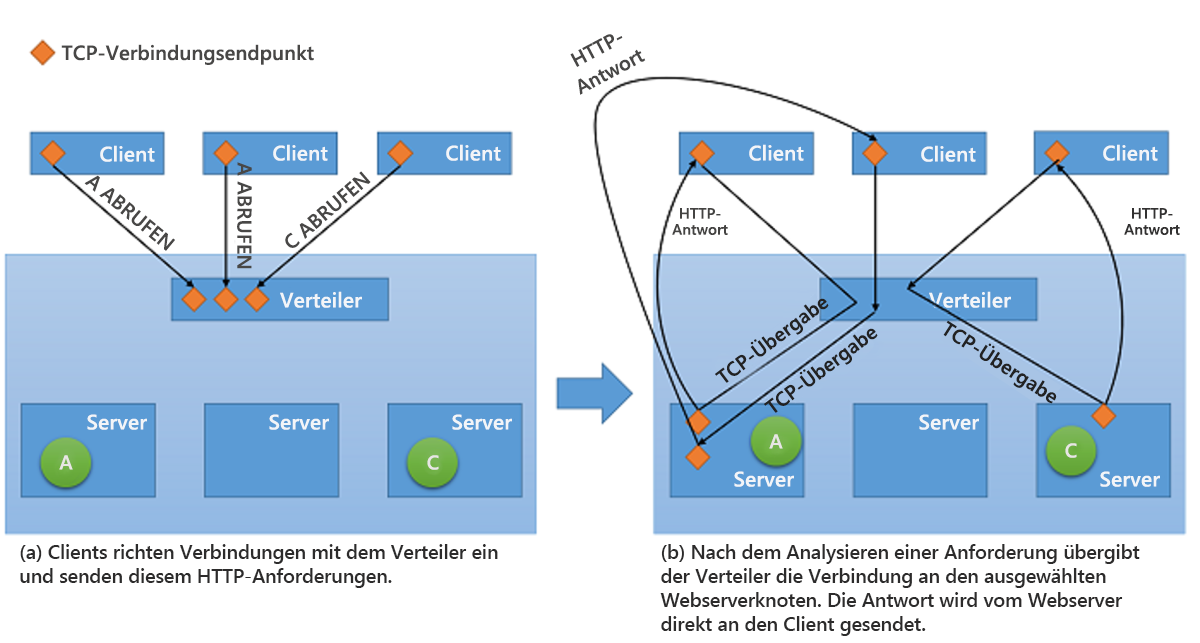
Abbildung 10: Schema der TCP-Übergabe vom Verteiler zum Back-End-Server
Vorteile des Lastenausgleichs
Einer der Vorteile des Lastenausgleichs besteht im „Verschleiern“ von Fehlern im System. Solange der Client für einen einzelnen Endpunkt, der mehrere Ressourcen darstellt, verfügbar gemacht wird, bemerkt der Client Fehler in einzelnen Ressourcen nicht, da Anforderungen mithilfe von anderen Ressourcen verarbeitet werden. Dadurch kann der Load Balancer jedoch selbst zur Fehlerquelle werden. Bei einem beliebigen Fehler im Load Balancer werden keine Clientanforderungen mehr verarbeitet, und dies bei voller Funktionsfähigkeit der Back-End-Server. Daher werden Load Balancer im Sinne der Hochverfügbarkeit häufig als Paar implementiert.
Ein noch größerer Vorteil des Lastenausgleichs ist die verbesserte Reaktionsfähigkeit, da Workloads auf mehrere Computeressourcen in der Cloud verteilt werden. Eine einzelne Compute-Instanz in der Cloud weist mehrere Einschränkungen auf. In früheren Modulen wurden die physischen Leistungseinschränkungen erläutert, da für größere Workloads mehr Ressourcen erforderlich sind. Durch Verwendung des Lastenausgleichs werden größere Workloads auf mehrere Ressourcen verteilt, sodass jede Ressource ihre Anforderungen zeitgleich und unabhängig ausführen kann, wodurch der Durchsatz der Anwendung erhöht wird. Mit Lastenausgleich werden auch die durchschnittlichen Reaktionszeiten verkürzt, da die Workload von einer größeren Anzahl von Servern verarbeitet wird.
Bei der Implementierung erfolgreicher Strategien zum Lastenausgleich spielen Integritätsprüfungen eine wesentliche Rolle. Ein Load Balancer muss darüber Bescheid wissen, wenn eine Ressource nicht mehr verfügbar ist, damit der Datenverkehr nicht mehr an diese Ressource weitergeleitet wird. Eine der beliebtesten Methoden zur Überprüfung der Integrität bestimmter Ressourcen ist die Ping-Echoüberwachung, bei der der Load Balancer mit ICMP-Anforderungen (Internet Control Message Protocol) einen Ping-Befehl an einen Server sendet. Bei der Weiterleitung von Datenverkehr an eine Ressource berücksichtigen einige Lastenausgleichsstrategien neben der Integrität auch andere Metriken wie Durchsatz, Latenz und CPU-Auslastung.
Load Balancer müssen häufig Hochverfügbarkeit garantieren. Die einfachste Möglichkeit hierfür besteht im Erstellen mehrerer Lastenausgleichsinstanzen (jeweils mit einer eindeutigen IP-Adresse), die mit einer einzigen DNS-Adresse verknüpft werden. Tritt bei einem Load Balancer ein Fehler auf, wird er durch einen neuen ersetzt, und der gesamte Datenverkehr wird mit nur minimalen Leistungseinbußen an die Failoverinstanz übergeben. Gleichzeitig kann eine neue Load Balancer-Instanz als Ersatz für die fehlerhafte Instanz konfiguriert werden, und die DNS-Einträge müssen sofort aktualisiert werden.
Neben der Verteilung von Anforderungen auf Back-End-Server verwenden Load Balancer häufig Mechanismen zur Verringerung der Serverlast und zur Erhöhung des Gesamtdurchsatzes. Dazu zählen:
SSL-Auslagerung: HTTPS-Verbindungen führen zu zusätzlichen Leistungseinbußen, da der Datenverkehr über eine solche Verbindung verschlüsselt ist. Anstatt alle Anforderungen über Secure Sockets Layer (SSL) auszuführen, wird SSL nur noch für die Verbindung zwischen Client und Load Balancer verwendet, während Umleitungsanforderungen an die Server unverschlüsselt über eine HTTP-Verbindung gesendet werden. Dadurch kann die Serverlast deutlich verringert werden. Die Sicherheit bleibt zudem erhalten, solange Umleitungsanforderungen nicht über ein offenes Netzwerk ausgeführt werden.
TCP-Pufferung: Clients mit einer langsamen Verbindung werden in den Load Balancer ausgelagert, um die Server zu entlasten, die Antworten an diese Clients senden.
Zwischenspeicherung: In bestimmten Szenarios kann der Load Balancer einen Cache für die häufigsten Anforderungen beibehalten (oder für Anforderungen, die ohne Kommunikation mit den Servern verarbeitet werden können, wie statische Inhalte), um die Serverlast zu verringern.
Strukturierung des Datenverkehrs: Mit dieser Vorgehensweise kann der Load Balancer den Fluss der Pakete verzögern oder deren Prioritäten ändern, um den Datenverkehr für die Serverkonfiguration zu optimieren. Dies wirkt sich zwar auf die Servicequalität einiger Anforderungen aus, stellt jedoch sicher, dass die eingehende Last verarbeitet werden kann.
Beachten Sie, dass Lastenausgleich nur funktioniert, wenn der Load Balancer selbst nicht überlastet ist. Sonst kann der Load Balancer zum Engpass werden. Doch meist verarbeiten Load Balancer selbst nur wenige der Anforderungen, die sie empfangen. Sie überlassen den Vorgang des Umwandelns von Anforderungen in Antworten vielmehr den Back-End-Servern.
Gleichmäßige Verteilung
In der Cloud stehen mehrere Möglichkeiten des Lastenausgleichs zur Verfügung. Eine der gängigsten stellt die gleichmäßige Verteilung dar, bei der mithilfe eines einfachen Roundrobin-Algorithmus der Datenverkehr gleichmäßig auf alle Knoten verteilt wird. Dabei wird weder die Verwendung einzelner Ressourcen im System noch die Ausführungszeit der Anforderungen berücksichtigt. Alle Knoten im System sollen ausgelastet sein. Diese Vorgehensweise lässt sich mit am einfachsten implementieren.
AWS verwendet diese Methode für den Dienst Elastic Load Balancer (ELB). ELB stellt Load Balancer bereit, die den Datenverkehr über angefügte EC2-Instanzen ausgleichen. Load Balancer stellen im Wesentlichen selbst EC2-Instanzen dar, die den speziellen Dienst enthalten, Datenverkehr weiterzuleiten. Werden die Ressourcen hinter dem Load Balancer horizontal skaliert, werden die IP-Adressen der neuen Ressourcen im DNS-Eintrag des Load Balancers aktualisiert. Dieser Vorgang dauert einige Minuten, da hierfür sowohl Überwachungs- als auch Bereitstellungszeit erforderlich ist. Diese Skalierungszeit, also die Wartezeit, bis der Load Balancer zur Verarbeitung der höheren Last bereit ist, wird als „Aufwärmphase“ des Load Balancers bezeichnet.
Load Balancer von AWS überwachen außerdem die Ressourcen, die ihnen für die Verteilung der Workload angefügt wurden, um eine Integritätsprüfung beizubehalten. Mithilfe eines Ping-Echomechanismus wird sichergestellt, dass alle Ressourcen fehlerfrei funktionieren. ELB-Benutzer können die Parameter der Integritätsprüfung durch Angabe der Verzögerungen und der Anzahl der Wiederholungen konfigurieren.
Hashbasierte Verteilung
Bei dieser Methode soll sichergestellt werden, dass die Anforderungen eines Clients für die Dauer einer Sitzung immer an denselben Server weitergeleitet werden. Dafür werden die Metadaten, die die einzelnen Anforderungen definieren, mit einem Hash versehen, der wiederum als Grundlage für die Auswahl des Servers verwendet wird. Wird der Hashvorgang ordnungsgemäß ausgeführt, werden die Anforderungen relativ gleichmäßig auf die Server verteilt. Dadurch ist diese Methode bestens für sitzungsfähige Anwendungen geeignet, die Sitzungsdaten im Arbeitsspeicher speichern können, anstatt sie in einen freigegebenen Datenspeicher zu schreiben, wie z. B. eine Datenbank oder ein Redis Cache. Ein Nachteil besteht darin, dass jeder Anforderung ein Hash hinzugefügt werden muss, was zu einer kurzen Wartezeit führt.
Azure Load Balancer verwendet einen hashbasierten Mechanismus zur Verteilung der Last. Dabei wird für jede Anforderung ein Hash erstellt basierend auf Quell-IP, Quellport, Ziel-IP, Zielport und Protokolltyp. So wird sichergestellt, dass unter normalen Umständen jedes Paket aus derselben Sitzung an denselben Back-End-Server weitergeleitet wird. Durch die Hashfunktion erfolgt die Verteilung der Verbindungen auf die Server zufällig.
Weitere Lastenausgleichsmethoden
Wenn sich ein bestimmter Server bei der Verarbeitung einer Anforderung (oder mehreren Anforderungen) aufhängt, werden Anforderungen von Lastenausgleichsmodulen, die Roundrobin- oder hashbasierte Verteilungsalgorithmen verwenden, trotzdem an ihn weitergeleitet. Es gibt noch weitere, anspruchsvollere Strategien für den Lastenausgleich über mehrere Ressourcen hinweg, die die Kapazität berücksichtigen. Zwei der am häufigsten verwendeten Metriken zum Messen der Kapazität sind folgende:
Anforderungsausführungszeit: Strategien, die auf dieser Metrik basieren, verwenden einen Prioritätsplanungsalgorithmus, wobei Anforderungsausführungszeiten verwendet werden, um das Ziel für einzelne Anforderungen auszuwählen. Die größte Herausforderung bei der Verwendung dieses Ansatzes ist die genaue Messung der Ausführungszeiten. Ein Lastenausgleich kann Ausführungszeiten schätzen, indem er eine speicherinterne Tabelle verwendet (die ständig aktualisiert wird), in der die Unterschiede zwischen dem Zeitpunkt, an dem eine Anforderung an die einzelnen Server weitergeleitet wird, und dem Zeitpunkt der Rückgabe gespeichert werden.
Ressourcennutzung: Strategien, die auf dieser Metrik basieren, verwenden die CPU-Auslastung, um die Auslastung knotenübergreifend auszugleichen. Der Lastenausgleich verwaltet eine geordnete Liste von Ressourcen basierend auf deren Auslastung und leitet jede empfangene Anforderung an die Ressource mit der geringsten Auslastung weiter.
Der Lastenausgleich ist entscheidend für die Implementierung skalierbarer Clouddienste. Ohne eine effektive Möglichkeit, den Datenverkehr auf die Back-End-Ressourcen zu verteilen, ist die Elastizität stark eingeschränkt, die durch das Schaffen von Ressourcen, wenn sie benötigt werden, und durch das Aufheben ihrer Bereitstellung, wenn sie nicht benötigt werden, erreicht wird.
Literatur
- Aron, Mohit and Sanders, Darren and Druschel, Peter and Zwaenepoel, Willy (2000). „Scalable content-aware request distribution in cluster-based network servers“ (Skalierbare inhaltsabhängige Anforderungsverteilung auf clusterbasierten Netzwerkservern). „Proceedings of the 2000 Annual USENIX technical Conference“