Übung: Importieren von Python-Bibliotheken und Raketenstartdaten
Sie haben nun ein Ziel: Ist es wahrscheinlich, dass ein Start bei bestimmten Wetterbedingungen erfolgt? Sie verfügen über ein Dataset, das Wetterdaten aus folgenden Quellen enthält:
- Mehrere erfolgreiche Raketenstarts
- Ein verschobener Starttermin
- Die Tage vor und nach jedem Start
Jetzt können Sie damit beginnen, Code zu schreiben.
Maschinelles Lernen in Code
Sie können verschiedene Tools und Dienste nutzen, um Machine Learning-Probleme zu lösen. In diesem Lernpfaden zum Thema Raumfahrt werden Visual Studio Code, Python, scikit-learn und Azure verwendet.
Sehen Sie sich dieses Video von Microsoft an, um zu erfahren, wie Sie eine vergleichbare Umgebung herunterladen und entsprechend Ihren Anforderungen konfigurieren.
Beim Einrichten Ihrer lokalen Programmierumgebung wird empfohlen, dass Sie eine Anaconda-Umgebung erstellen, um sicherzustellen, dass Sie über genau das verfügen, was Sie für das Projekt benötigen. Sie können Ihre bevorzugte Methode und Ihre bevorzugten Werkzeuge verwenden. Die meisten dieser Module erfordern Visual Studio Code oder Azure nicht explizit.
Einrichten der lokalen Umgebung
Stellen Sie sicher, dass Sie über Folgendes verfügen, bevor Sie fortfahren:
- Installation von Visual Studio Code, Anaconda und Python. (Die Anaconda-Umgebung wird in den folgenden Schritten erstellt.)
- Ein lokaler Ordner, den Sie zum Speichern des gesamten Codes und der Daten erstellt haben.
- Die Excel-Datei mit den Daten, die heruntergeladen und in Ihrem lokalen Ordner gespeichert werden.
- Eine leere Jupyter Notebook-Instanz, die im Ordner gespeichert wird (Erstellen Sie in Ihrem lokalen Ordner eine Dummydatei namens IhrDateiname.ipynb).
So richten Sie Ihre lokale Umgebung ein:
Öffnen Sie die Anaconda-Eingabeaufforderung.
Erstellen Sie in der Anaconda-Eingabeaufforderung eine neue Anaconda-Umgebung mit Pandas, NumPy, scikit-learn, PyDotPlus und Jupyter:
conda create -n myenv python=3.8 pandas numpy jupyter seaborn scikit-learn pydotplusAktivieren Sie die neue Umgebung in der Anaconda-Eingabeaufforderung:
conda activate myenvInstallieren Sie „AzureML-SDK“ über die Anaconda-Eingabeaufforderung:
pip install --upgrade azureml-sdkIn einigen Fällen kann die Installation einige Minuten dauern. Warten Sie, bis der Vorgang abgeschlossen ist.
Installieren Sie in der Anaconda-Eingabeaufforderung einen Excel-Reader (beachten Sie, dass xlrd möglicherweise nicht mit der heruntergeladenen Excel-Datendatei funktioniert):
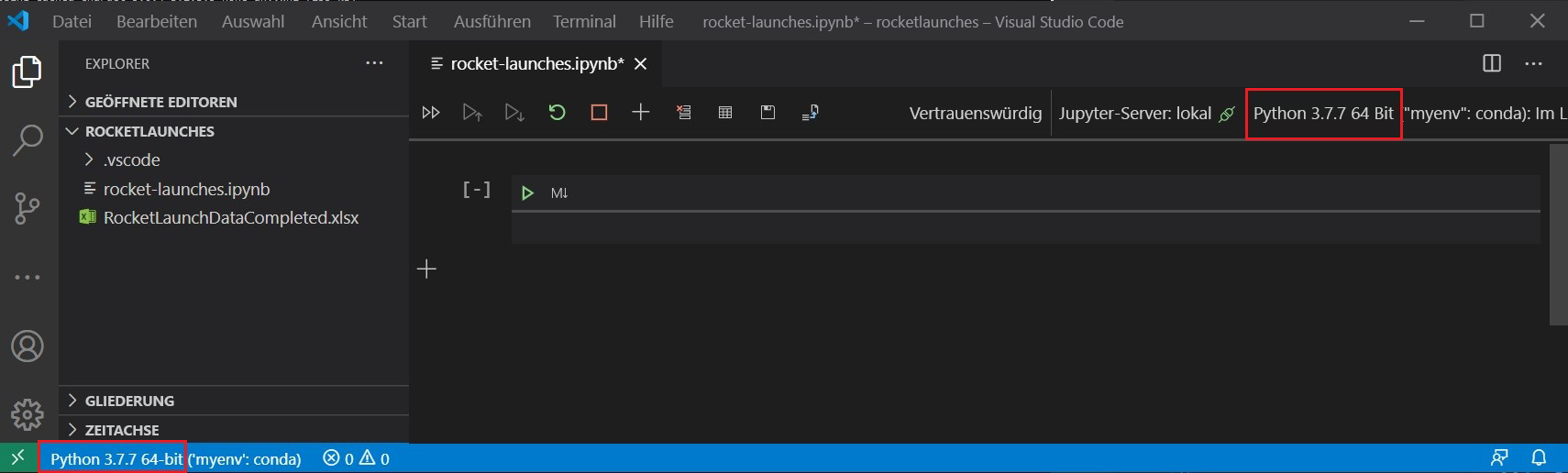
pip install openpyxlÖffnen Sie in Visual Studio Code den lokalen Ordner, den Sie zum Speichern des gesamten Codes und der Daten erstellt haben. Wählen Sie sowohl die Python-Version des Jupyter-Kernels oben rechts als auch den Python-Interpreter unten links aus, und konfigurieren Sie beide zur Verwendung der Anaconda-Umgebung:
Importbibliotheken
Nachdem Sie Ihre lokale Visual Studio Code-Umgebung erstellt haben, können Sie nun die Bibliotheken importieren. Diese unterstützen Sie beim Importieren und Bereinigen der Wetterdaten und beim Erstellen und Testen des Machine Learning-Modells.
Kopieren Sie den folgenden Code in eine Zelle, und führen Sie ihn aus, um die Bibliotheken zu importieren.
# Pandas library is used for handling tabular data
import pandas as pd
# NumPy is used for handling numerical series operations (addition, multiplication, and ...)
import numpy as np
# Sklearn library contains all the machine learning packages we need to digest and extract patterns from the data
from sklearn import linear_model, model_selection, metrics
from sklearn.model_selection import train_test_split
# Machine learning libraries used to build a decision tree
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
# Sklearn's preprocessing library is used for processing and cleaning the data
from sklearn import preprocessing
# for visualizing the tree
import pydotplus
from IPython.display import Image
Lesen von Daten in eine Variable
Da Sie nun alle Bibliotheken importiert haben, können Sie die Pandas-Bibliothek nutzen, um die Daten zu importieren. Verwenden Sie den Befehl pd.read_excel, um die Daten zu lesen und in einer Variable zu speichern. Verwenden Sie dann die .head()-Funktion, um die ersten fünf Zeilen der Daten zu drucken und sicherzustellen, dass alles richtig gelesen wurde.
launch_data = pd.read_excel('RocketLaunchDataCompleted.xlsx')
launch_data.head()
Beginnen mit der Untersuchung der Daten
Abschließend können Sie den Funktionsaufruf .columns verwenden, um alle Spalten in den Daten anzuzeigen. Dadurch werden die Attribute der Daten angezeigt. Ihnen werden einige allgemeine Attribute wie die Namen von Raketen, deren Start in der Vergangenheit geplant wurde, die geplanten Termine, ob sie tatsächlich gestartet wurden und viele mehr angezeigt. Sehen Sie sich diese Spalten an, und versuchen Sie zu schlussfolgern, welche Attribute die größten Auswirkungen darauf haben, ob ein Raketenstart stattfinden kann.
launch_data.columns