Datenmodellierung für Dataverse
Wenn Sie Daten mit Ihrer App speichern oder anzeigen, ist die Datenstruktur ein wichtiger Bestandteil des Designs. Sie sollten sich im Voraus überlegen, wie die Daten in einer bestimmten App oder einem bestimmten Bildschirm verwendet werden und wie andere die Daten verwenden. Wenn Sie auf Ihre Personas, Aufgaben, Geschäftsprozesse und Ziele zurückgreifen, können Sie definieren, welche Daten gespeichert und wie sie strukturiert werden sollen.
Tabellentypen
Dataverse hat drei Tabellentypen:
- Standard – Tabellen, in denen Sie Daten speichern und in modellgesteuerten Apps zur Navigation hinzufügen können. Die meisten von Ihnen erstellten Tabellen sind Standardtabellen. Es werden verschiedene Standardtabellen aus dem Common Data Model-Schema in einer Dataverse-Umgebung erstellt.
- Aktivität – Diese Tabellen werden zum Speichern von Interaktionen wie Telefonanrufen, Aufgaben und Terminen verwendet. Es gibt eine Reihe von Aktivitätstabellen in einer Dataverse-Datenbank.
- Virtuell – Mit diesen Tabellen können Sie Tabellen und Spalten in Dataverse erstellen, verwenden Sie dann aber eine externe Datenquelle zum Speichern der Daten. Für den Benutzer werden die Daten in seinen Apps wie alle anderen Daten angezeigt.
Wenn Sie eine benutzerdefinierte Standardtabelle erstellen, müssen Sie deren Besitz angeben:
- Benutzer/Team – Standardoption
- Organisation – Wird als Referenzdaten verwendet

Benutzerdefinierte Aktivitätstabellen
Aktivitätstabellen werden zum Speichern von Interaktionen verwendet. Sie haben eine Beziehung zu allen Tabellen, bei denen Für Aktivitäten aktivieren in ihren Tabellenmetadaten festgelegt ist. Aktivitätstabellen verwenden denselben Spaltensatz und dieselben Sicherheitsberechtigungen. Zeilen in Aktivitätstabellen werden in der Zeitleiste in modellgesteuerten App-Formularen angezeigt. In diesem Beispiel wurde eine benutzerdefinierte Aktivitätstabelle mit dem Namen „Spende“ erstellt.
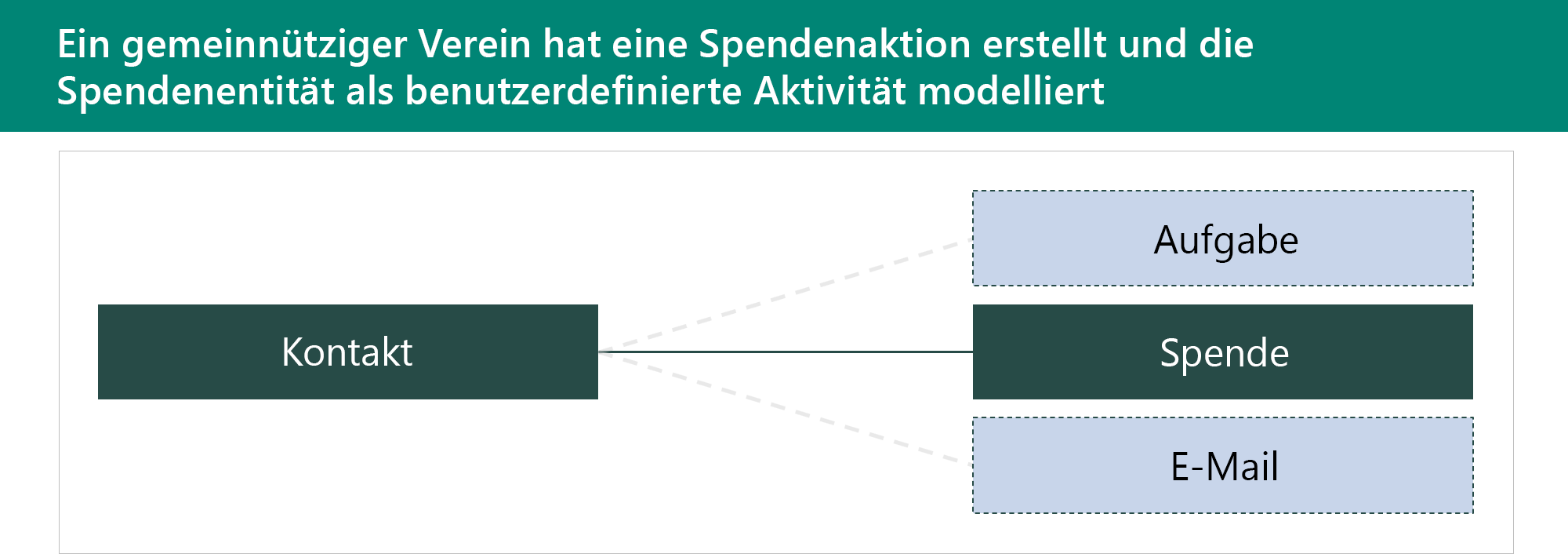
Die Verwendung benutzerdefinierter Aktivitätstabellen bietet einige Vorteile:
- Wird in einer Liste mit anderen Aktivitäten angezeigt
- Kann mit anderen Aktivitäten zusammengefasst werden
- Kann eine Spende in jeder Tabelle erstellen, die Aktivitäten unterstützt
Die Verwendung benutzerdefinierter Aktivitätstabellen hat auch einige Nachteile:
- Sicherheitskonfiguration anders als bei allen anderen Aktivitäten
- Steuern, welche Tabellen mit einer Spende zusammenhängen
Spaltendatentypen
Sie müssen den Datentyp für Spalten mit Bedacht auswählen. Dies gilt insbesondere für numerische Datentypen, da Sie numerische Spalten nicht mit verschiedenen Typen vergleichen können und die Datentypen für berechnete und Rollup-Spalten eingeschränkt sind. Nachdem ein Typ ausgewählt wurde, kann er nicht mehr geändert werden.
| Datentyp | Bemerkungen |
|---|---|
| Ja/Nein | Sicherstellen, dass Sie nie mehr Auswahlmöglichkeiten benötigen |
| Datei und Bild | Ermöglicht das Inline-Speichern von Dateien und Bildern in Dataverse |
| Debitor | Kann ein Kontakt oder ein Konto sein |
| Suche/Auswahl | Sicherstellen, dass Sie die beste Auswahl treffen |
| Datum/Uhrzeit | Sicherstellen, dass Sie das geeignete Verhalten auswählen |
| Numerisch | Viele zur Auswahl, wählen Sie mit Bedacht aus |
Auswahltabelle vs. Suchtabelle
Es hängt von den Umständen ab, ob Sie sich zwischen einer Suchtabelle oder einer Auswahltabelle entscheiden sollten.
Verwenden Sie eine Auswahltabelle, wenn Sie eine Tabelle mit folgenden Funktionen benötigen:
- Speichert nur Bezeichnung und Wert als Schlüssel-Wert-Paar
- Hat integrierte Lokalisierung.
- Wird als Lösungskomponente betrachtet
- Keine integrierte Möglichkeit, um Werte zurückzuziehen
- UX arbeitet mit ungefähr 200 Elementen
- Kann mit JavaScript gefiltert werden
- Wird als ganze Zahl in der Zeile gespeichert
Verwenden Sie eine Suchtabelle, wenn Sie eine Tabelle mit folgenden Funktionen benötigen:
- Kann andere Daten in Spalten in der Zeile speichern
- Erfordert die Erstellung einer Lokalisierung
- Wird als Referenzdaten behandelt
- Unterstützt einen inaktiven Status
- Hat UX, die auf viele Elemente skaliert
- Kann nach Ansichten und Sicherheit filtern
- Wird als Entitätsreferenz gespeichert
Das Speichern anderer Daten in der Suchtabelle ermöglicht den Zugriff beim Ausführen von Workflows oder anderen Anpassungen, die auf die Daten verweisen. Beispielsweise kann eine verwandte Eigenschaft in einer Prüfbedingung verwendet werden.
Als Lösungskomponente behandelt können Auswahltabellen die Zusammenführungsauflösung bewältigen, indem dem Wert das Herausgeberpräfix vorangestellt wird.
Das Hinzufügen von Werten zu einer Auswahltabelle erfordert Zugriff auf Administrator-/Anpasser-Ebene, während Suchwerte von einem Benutzer geändert werden können, wenn die Berechtigung über Sicherheitsrollen erteilt wird.
Die Benutzererfahrung (UX) für Optionen ist ideal für kleine Mengen, funktioniert jedoch nicht gut für große Mengen. Suchvorgänge bieten Funktionen für Suchtypen, die bei Auswahlen nicht verfügbar sind.
Wenn Sie Multiple-Choice-Spalten haben, die voneinander abhängig sind, kann diese Aufgabe nur mit formularbasiertem Skript erreicht werden, während Suchen mithilfe der Konfiguration nach anderen Suchen gefiltert werden können.
Datei‑ und Bilddaten speichern
Sie haben mehrere Möglichkeiten, Dateien und Bilder zu speichern:
- Dataverse – Speichern Sie Dateien und Bilder mithilfe von File‑ und Image-Datentypen.
- SharePoint – Dies dient der Zusammenarbeit, aber es gibt ein Problem mit der Sicherheit. Die Sicherheit für die Dateien folgt den SharePoint-Berechtigungen und ist nicht Dataverse-Zeilenberechtigungen synchronisiert.
- Azure Storage – Verwenden Sie dies für die Archivierung und den externen Zugriff. Diese Auswahl verfügt über eigenständige Sicherheit, kann jedoch für kurze Zeiträume basierend auf dem für den Verbrauch generierten Link (Valet-Muster) gewährt werden. Azure Storage kann auch große Dateien verarbeiten.
Merkmale von Datei‑ und Bilddatentypen:
- Sie eignen sich gut zum Hochladen und Nachschlagen.
- Die Sicherheit folgt den Datensatzberechtigungen.
- Sie sind durch die Größe begrenzt.
Berechnete Spalten (Fx-Formelspalten)
Mit berechneten Spalten können einfache Berechnungen für Daten in einer Zeile durchgeführt werden, und sie verfügen über folgende Eigenschaften:
- Werden beim Abrufen eines Datensatzes berechnet
- Haben einen schreibgeschützt Wert
- Können Spalten aus derselben Zeile und Spalten in n:1-Beziehungen enthalten
- Können Rollupspalten in die Berechnung einbeziehen
- Können kein Ereignis für Workflow, Plug-In oder Power Automate auslösen.
- Sie werden mit der Fx-Formelsprache erstellt.
Rollupspalten
Rollupspalten ermöglichen Aggregationen für verwandte Zeilen in 1:n-Beziehungen, und sie verfügen über folgende Eigenschaften:
- Werden planmäßig berechnet (mindestens 1 Stunde) und können von einem Benutzer bei Bedarf aktualisiert werden
- Haben einen schreibgeschützt Wert
- Können berechnete Spalten zusammenfassen
- Können die Hierarchie verwandter Datensätze verwenden
- Können über verwandte Tabellen hinweg filtern
- Können kein Ereignis für Workflow, Plug-In oder Power Automate auslösen
Sie können „einfache“ berechnete Spalten zusammenfassen, d. h. berechnete Spalten, die nicht deterministische Funktionen enthalten, können nicht zusammengefasst werden.
Verbindungen
Beziehungen definieren, wie Zeilen miteinander in Dataverse in Beziehung stehen. Jede Tabelle in Dataverse hat einen Primärschlüssel, um einen eindeutigen Verweis auf die Zeilen in der Tabelle bereitzustellen. In Dataverse ist der Primärschlüssel ein Global Unique Identifier (GUID), der automatisch von Dataverse generiert wird, wenn eine Zeile erstellt wird. Beziehungen werden durch Hinzufügen eines Verweises auf den Primärschlüssel erstellt, der auch Fremdschlüssel genannt wird. In Dataverse werden Beziehungen mithilfe einer Spalte in einer Tabelle erstellt, in der der Fremdschlüsselwert gespeichert ist. Dieser Fremdschlüssel ist ein Zeiger auf den Primärschlüssel in der anderen Tabelle.
Zwei Arten von Beziehungen werden in Dataverse unterstützt:
- Eins-zu-viele (1:n)
- Viele-zu-viele (n:n)
Eins-zu-viele-Beziehung
Die folgende Spesenabrechnung zeigt ein Beispiel für eine Eins-zu-viele-Beziehung (1:n).
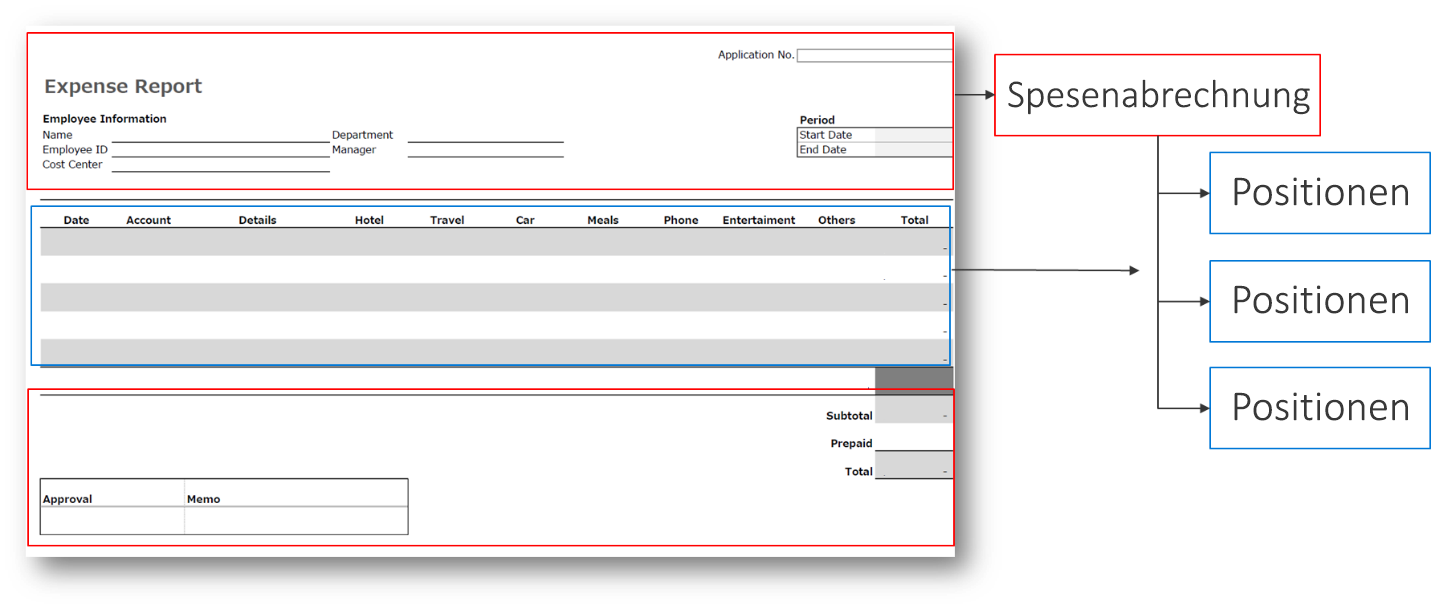
Der vorangehende Screenshot zeigt den Hauptteil der Spesenabrechnung, die den Namen des Mitarbeiters und die Abteilungsdetails enthält. Unterhalb des Hauptteils sehen Sie mehrere Beschreibungszeilen für jeden gekauften Artikel. In diesem Beispiel werden diese Beschreibungen Positionsartikel genannt. Die Positionen haben eine andere Struktur als der Hauptteil der Spesenabrechnung. Daher enthält jede Spesenabrechnung mehrere Positionen.
Die Beziehung zwischen der Spesenabrechnung und der Position ist ein Beispiel für eine Eins-zu-viele-Beziehung (1:n). Der Hauptteil der Spesenabrechnung ist mit mehreren Positionen verknüpft. Sie können die Beziehung auch aus der Perspektive der Positionen anzeigen: jede Position kann nur mit einer Spesenabrechnung verknüpft werden, wobei es sich um eine Eins-zu-viele-Beziehung (1:n) handelt.
Viele-zu-viele-Beziehung
Eine Viele-zu-viele-Datenstruktur ist ein spezieller Typ und wird in Fällen verwendet, in denen mehrere Datensätze mehreren Sätzen anderer Datensätze zugeordnet werden können. Ein gutes Beispiel für eine Viele-zu-viele-Datenstruktur ist Ihr Netzwerk von Geschäftspartnern. Sie haben mehrere Geschäftspartner (Kunden und Lieferanten), mit denen Sie zusammenarbeiten, und diese Geschäftspartner arbeiten auch mit mehreren Ihrer Kollegen zusammen.
Die folgenden Abschnitte enthalten Beispiele für verschiedene Arten von Viele-zu-viele-Datenstrukturen.
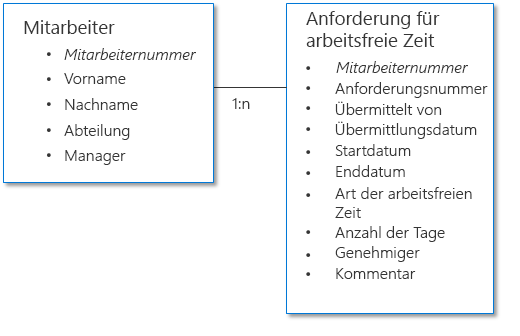
Beispiel 1: Antrag auf Freistellungsgenehmigung
Das folgende Beispiel zeigt zwei Datensätze: einen, der den Mitarbeiter darstellt, und einen, der die Freistellungsanforderung darstellt. Da jeder Mitarbeiter mehrere Anfragen sendet, ist die Beziehung in diesem Szenario eins-zu-viele, wobei „eins“ der Mitarbeiter und „viele“ die Anfragen sind. Die Mitarbeiterdaten und die Daten zur Freistellungsanforderung sind miteinander verknüpft, indem die Mitarbeiternummer als gemeinsame Spalte (auch als Schlüssel bezeichnet) verwendet wird.
Beispiel 2: Genehmigung einer Bestellung
In diesem Beispiel sieht die Datenstruktur komplex aus, ähnelt jedoch dem am Anfang dieses Artikels beschriebenen Beispiel für eine Spesenabrechnung. Jeder Anbieter oder Lieferant ist mehreren Bestellungen zugeordnet. Jeder Mitarbeiter ist für mehrere Bestellungen verantwortlich. Daher haben diese beiden Datensätze eine Eins-zu-viele-Datenstruktur.
Da Mitarbeiter möglicherweise nicht immer denselben Anbieter oder Lieferanten verwenden, werden Lieferanten von mehreren Mitarbeitern verwendet, und jeder Mitarbeiter arbeitet mit mehreren Lieferanten zusammen. Daher ist die Beziehung zwischen Mitarbeitern und Lieferanten Viele-zu-viele.

Beispiel 3: Spesenabrechnung
Das folgende Beispiel zeigt ein Entitätsbeziehungsdiagramm (ERD, Entity Relationship Diagram), das mehrere Tabellen für eine Spesenabrechnungslösung enthält.

Beispiel 4: Nachverfolgen, welche zwei Vorteile der VIP ausgewählt hat
In diesem Beispiel haben wir zwei VIPs, John und Mary. John hat das WLAN und die Wäscherei als Vorteile ausgewählt, und Mary hat das WLAN und die Mini-Bar als Vorteile gewählt. Sie können dieses Szenario auf unterschiedliche Weise gestalten. Die erste Möglichkeit besteht darin, das Szenario als 1:n-Beziehung umzusetzen.
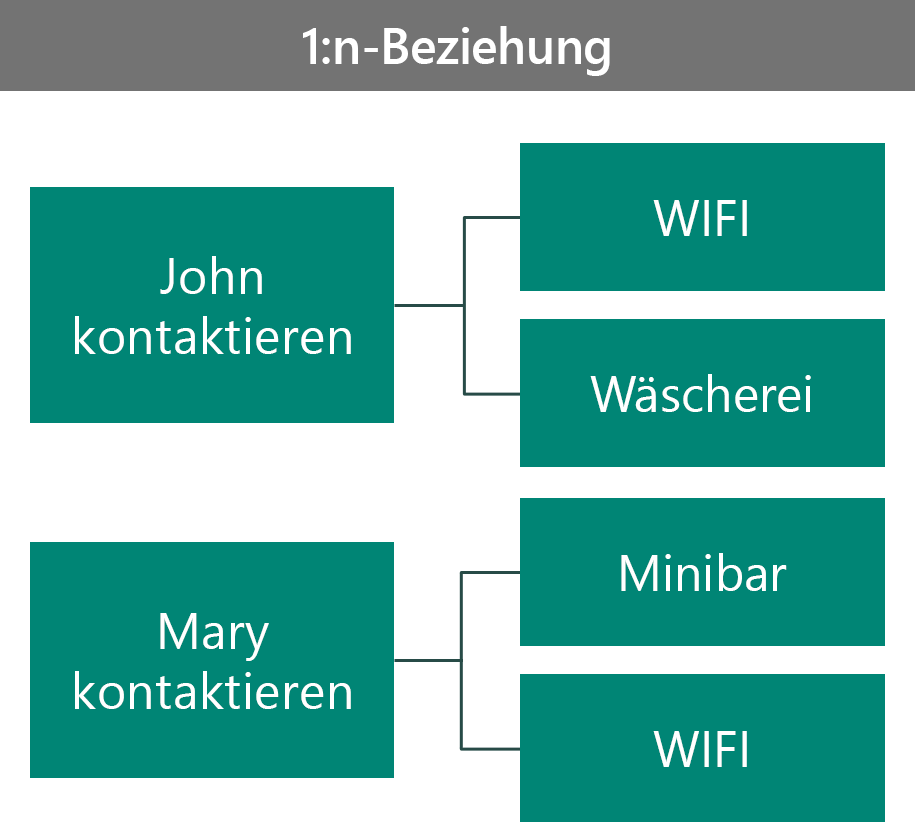
In dieser Konfiguration:
- Der Vorteil-Datensatz ist für den Kontakt einzigartig.
- Es gibt keine Möglichkeit, alle Kontakte anzuzeigen, die einen bestimmten Vorteil auswählen.
- Sie können die Sicherheit des Vorteilsdatensatzes basierend auf dem Besitzer des Kontakts ermöglichen.
- Sie können mehr Daten im Vorteilsdatensatz speichern, die kontaktspezifisch sind.
- Die Beziehung verhält sich übergeordnet zum Vorteil, andernfalls wäre der Vorteil-Datensatz verwaist.
Die zweite Möglichkeit besteht darin, das Szenario als n:n-Beziehung umzusetzen.
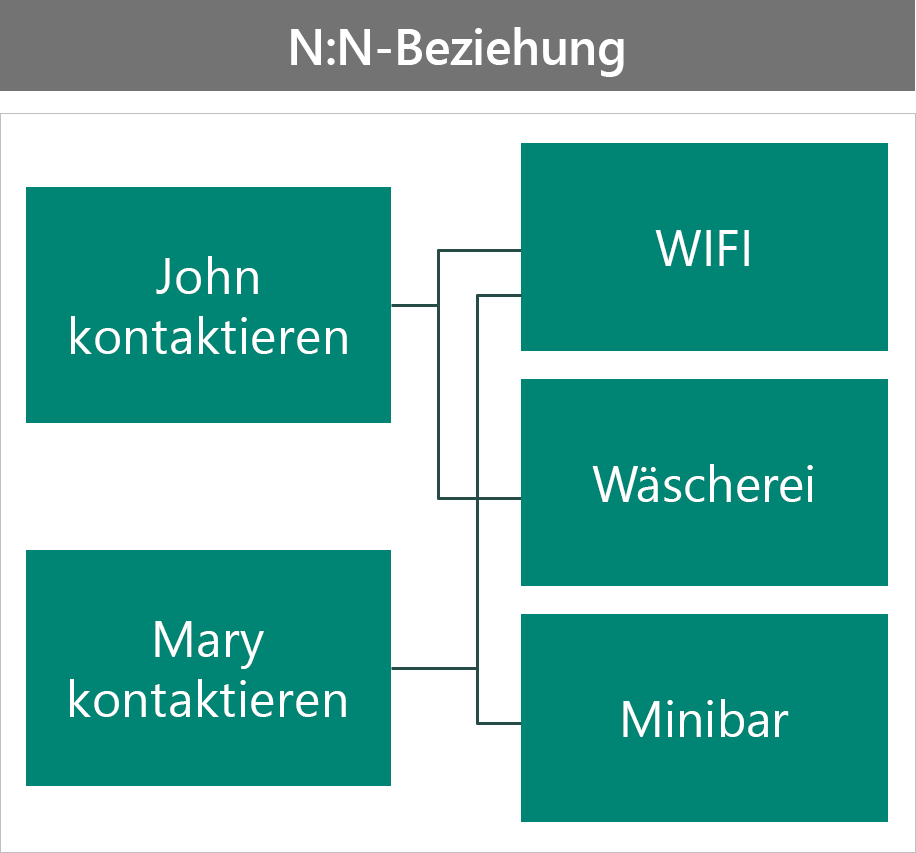
In dieser Konfiguration:
- Wenn Sie sich die zugehörigen Datensätze aus dem Vorteil ansehen, werden alle Kontakte angezeigt, die diesen Vorteil ausgewählt haben.
- Die Sicherheit des Vorteils wird für alle Kontakte geteilt, sodass diese nicht auf jeden Kontakt zugeschnitten werden können.
- Alle Attribute des Vorteils werden für alle Kontakte freigegeben, sodass Sie keine kontaktspezifischen Daten haben.
- Sie müssen eine Referenzbeziehung verwenden, da Sie sonst den Vorteil anderer Kontakte entfernen würden.
Keine der Konfigurationen ist ideal.
Das nächste Beispiel zeigt die Erstellung einer benutzerdefinierten (Interset-)Tabelle, in der die Vorteile des VIP enthalten sind.
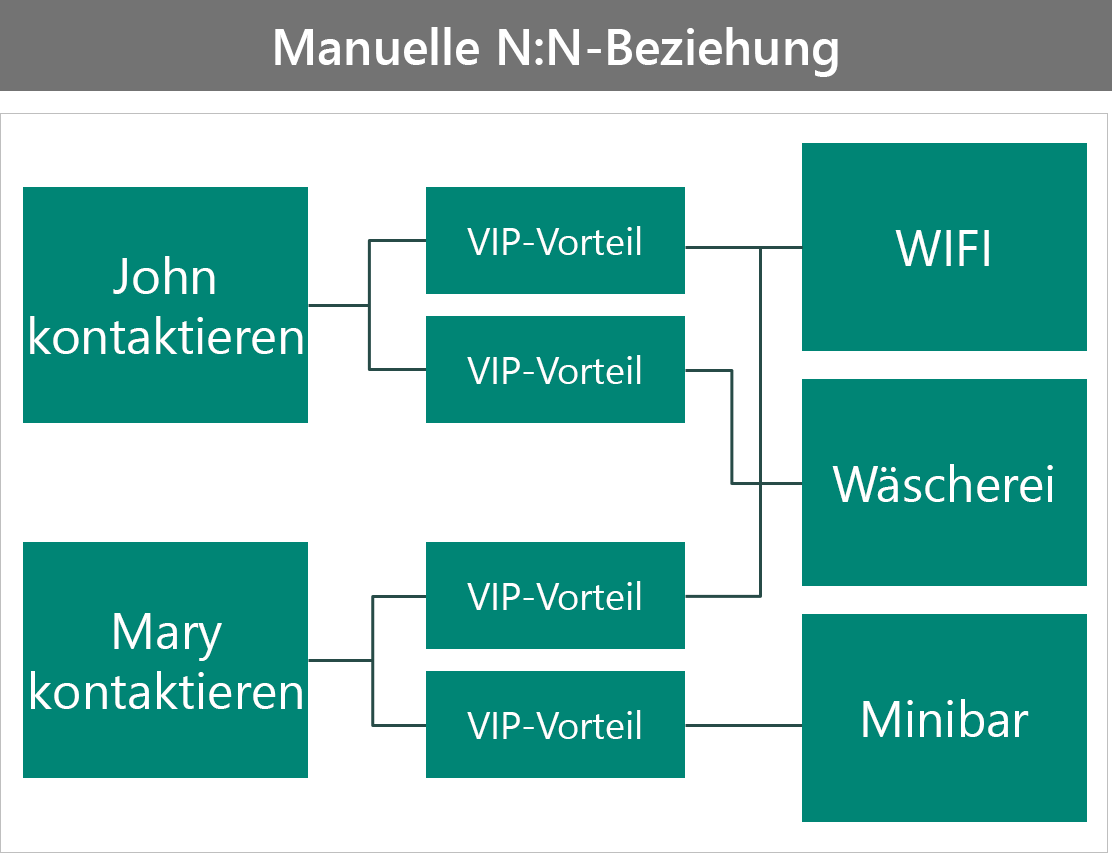
Diese Konfiguration:
- Fügt die Möglichkeit hinzu, mehr Daten in der für diesen Kontakt spezifischen Vorteilstabelle zu speichern.
- Erfordert mehr Arbeit für den Benutzer, um die Datensätze zu verbinden. Jetzt muss er die Schnittzeile manuell erstellen.
- Sichert Vorteile einzeln.
- Macht Abfragen schwieriger, da Sie nicht direkt auf Attribute in der Vorteilstabelle zugreifen können.
Das folgende Beispiel zeigt die Verwendung von Spalten in der Kontakttabelle.
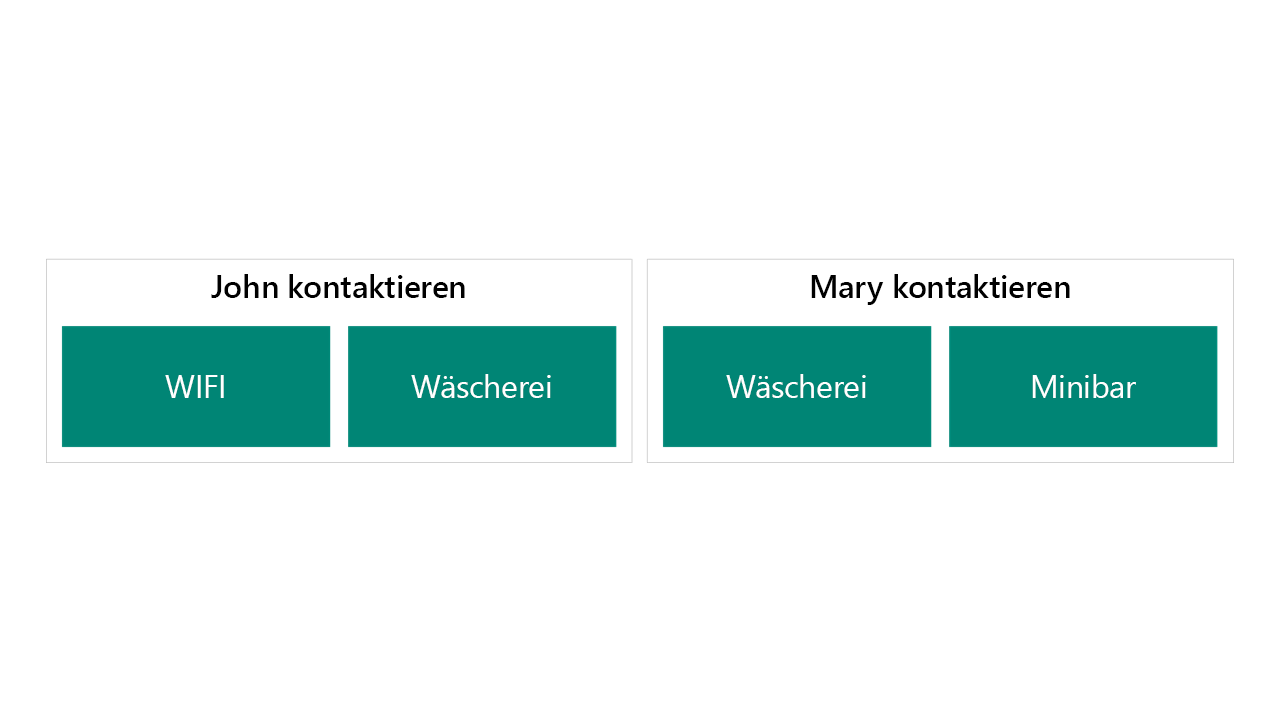
Diese Konfiguration:
- Funktioniert gut für primäre und sekundäre Vorteile, lässt sich jedoch nicht auf die Verfolgung vieler Vorteile skalieren.
- Vereinfacht Abfragen und Self-Service-Power BI für Benutzer.
- Verfolgt die gleiche Sicherheit wie der Kontaktdatensatz.
- Das Abfragen aller Benutzer, die einen primären Vorteil auswählen, würde eine Abfrage erfordern, die sowohl die primären als auch die sekundären Vorteile scannt.
Diese Konfiguration ist ein gutes Beispiel, wenn der Nutzen aus Compliance-/statistischen Gründen erfasst werden muss, jedoch keine Auswirkungen auf das Geschäft oder die Verarbeitung hat.
Beziehungsverhalten
Das Beziehungsverhalten steuert, wie bestimmte Aktionen über die 1:n-Beziehung zu Zeilen kaskadieren, die sich auf die primäre Tabellenzeile beziehen. Verhaltensweisen behalten die referentielle Integrität bei und können verhindern, dass verwaiste Datensätze zurückgelassen werden.

Wichtig
Das Definieren des Beziehungsverhaltens ist wichtig, da das Kaskadieren der zugewiesenen Datensätze dazu führen kann, dass zugehörige Datensätze zugewiesen werden. Stellen Sie im Zweifelsfall das Verhalten auf „Referentiell“ und „Einschränken“ ein.
Alternativschlüssel
In Integrationen werden Alternativschlüssel verwendet, um die Notwendigkeit zu verringern, eine Abfrage zum Suchen eines Datensatzes durchzuführen. Mit einem Alternativschlüssel können Sie eine Zeile aktualisieren, ohne die GUID zu kennen.
Alternativschlüssel:
- Sind ideal für Abrufe und Updates geeignet.
- Können Dezimal-, Ganzzahl-, Textfelder, Datums‑ und Suchfelder enthalten.
- Können bis zu fünf Alternativschlüssel pro Tabelle haben.
- Erstellen Sie im Hintergrund einen nullbaren eindeutigen Index, um die Eindeutigkeit des Schlüssels zu erzwingen.
Wenn ein Schlüssel erstellt wird, überprüft das System, ob dieser Schlüssel von der Plattform unterstützt werden kann.
Diagramm zu bewährten Methoden
Beim Erstellen von ERDs für Dataverse sollten Sie Folgendes beachten:
- Vermeiden Sie Datenduplizierung. Jedes Datenelement sollte nur einmal auftauchen. Anstatt dieselben Daten zwischen mehreren Tabellen zu duplizieren, sollten Funktionen wie Schnellansichtsformulare und die Anzeige zugehöriger Tabellendaten in Ansichten verwendet werden.
- Verwenden Sie die ERD-Beziehungen, um potenzielle Kaskadierungsverhalten zu überprüfen und zu identifizieren, die sich auf die Geschäftslogik auswirken können. Bei übergeordneten Beziehungen werden Berechtigungen wie Zuweisen, Freigeben, Aufheben der Freigabe, erneutes Überordnen, Löschen und Zusammenführen beispielsweise automatisch für verwandte Datensätze verwendet, wenn ein übergeordneter Datensatz aktualisiert wird.