Entwerfen einer Datenintegrationslösung mit Azure Data Lake
Bei einem Data Lake handelt es sich um ein Repository mit Daten, die in ihrem natürlichen Format in der Regel als Blobs oder Dateien gespeichert sind. Bei Azure Data Lake Storage handelt es sich um eine in Azure integrierte, umfangreiche, skalierbare und kosteneffiziente Data Lake-Lösung für Big Data-Analysen. Azure Data Lake Storage kombiniert ein Dateisystem mit einer Speicherplattform, damit Sie schneller Erkenntnisse aus Ihren Daten gewinnen können. Die Lösung baut auf Azure Blob Storage-Funktionen auf, um Optimierungen für Analyseworkloads bereitzustellen. Diese Integration bietet Azure Storage-Funktionen für Analyseleistung, Hochverfügbarkeit, Sicherheit und Dauerhaftigkeit.
Hinweis
Die aktuelle Implementierung des Diensts ist Azure Data Lake Storage Gen2.
Wissenswertes über Azure Data Lake Storage
Um Azure Data Lake Storage besser zu verstehen, sehen wir uns die folgenden Merkmale an.
- Azure Data Lake Storage kann jede Art von Daten mithilfe des nativen Formats der Daten speichern. Durch die Unterstützung beliebiger Datenformate und großer Datenmengen kann Azure Data Lake Storage mit strukturierten, halbstrukturierten und unstrukturierten Daten arbeiten.
- Die Lösung ist in erster Linie für die Arbeit mit Hadoop und allen Frameworks konzipiert, die Apache Hadoop Distributed File System (HDFS) als Datenzugriffsebene verwenden. Datenanalyseframeworks, die HDFS als Datenzugriffsebene verwenden, können direkt darauf zugreifen.
- Azure Data Lake Storage unterstützt hohen Durchsatz für eingabe- und ausgabeintensive Analysen und Datenverschiebungen.
- Das Zugriffssteuerungsmodell von Azure Data Lake Storage unterstützt sowohl rollenbasierte Zugriffssteuerung von Azure (RBAC) als auch POSIX-Zugriffssteuerungslisten (Portable Operating System Interface for Unix).
- Azure Data Lake Storage Azure Blob-Replikationsmodelle. Diese Modelle bieten Datenredundanz in einem einzelnen Rechenzentrum mit lokal redundantem Speicher (LRS).
- Azure Data Lake Storage bietet umfangreichen Speicherplatz und akzeptiert zahlreiche Datentypen für Analysen.
- Die Preise für Azure Data Lake Storage entsprechen denen von Azure Blob Storage.
Funktionsweise von Azure Data Lake Storage
Es gibt drei wichtige Schritte zur Verwendung von Azure Data Lake Storage:
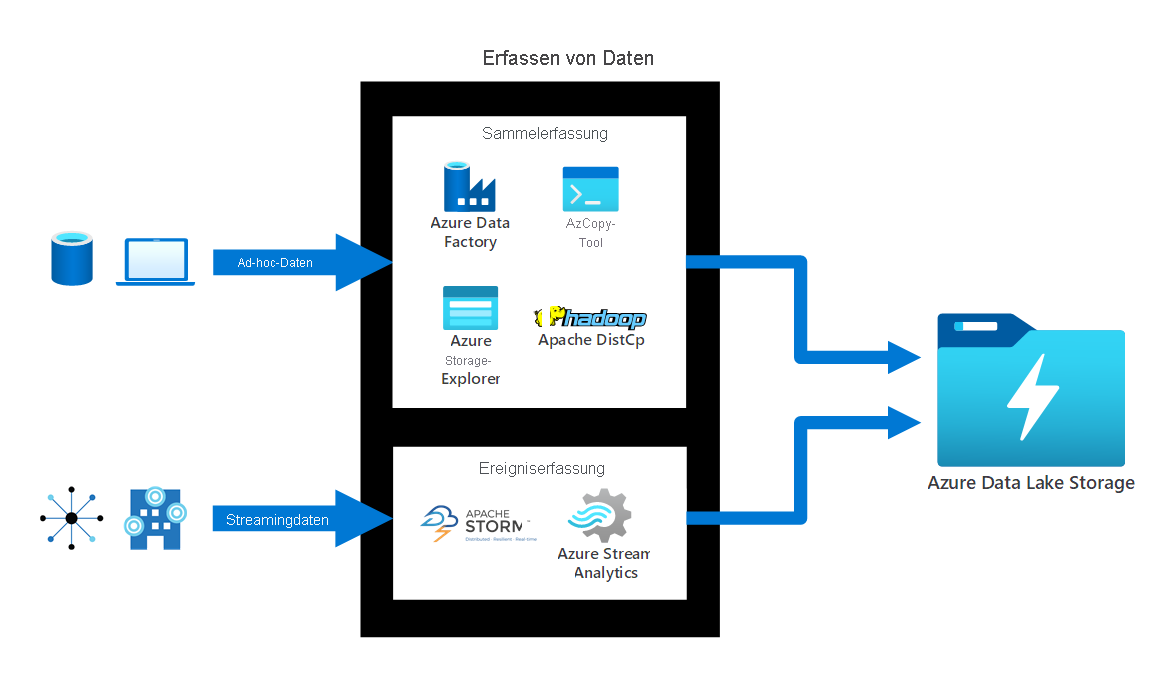
Erfassen von Daten. Azure Data Lake Storage bietet viele verschiedene Datenerfassungsmethoden:
- Für ungeplante Daten können Sie Tools wie AzCopy, die Azure CLI, PowerShell und Azure Storage-Explorer verwenden.
- Für relationale Daten kann der Azure Data Factory-Dienst verwendet werden. Sie können Daten aus jeder beliebigen Quelle übertragen, z. B. Azure Cosmos DB, SQL-Datenbank, Azure SQL Managed Instances und mehr.
- Für Streamingdaten können Sie Tools wie Apache Storm in Azure HDInsight oder Azure Stream Analytics usw. verwenden.
Das folgende Diagramm zeigt, wie ungeplante Daten und Streamingdaten in Azure Data Lake Storage massenhaft erfasst oder ungeplant erfasst werden.
Zugreifen auf gespeicherte Daten. Die einfachste Möglichkeit für den Zugriff auf Ihre Daten ist die Verwendung von Azure Storage-Explorer. Storage-Explorer ist eine eigenständige Anwendung mit grafischer Benutzeroberfläche (GUI) für den Zugriff auf Ihre Azure Data Lake Storage-Daten. Sie können auch PowerShell, die Azure CLI, die HDFS CLI oder andere Programmiersprachen-SDKs für den Zugriff auf die Daten verwenden.
Konfigurieren der Zugriffssteuerung. Kontrollieren Sie, wer auf die in Azure Data Lake Storage gespeicherten Daten zugreifen kann, indem Sie einen Autorisierungsmechanismus implementieren. Sie können Azure RBAC oder ACL auswählen.
Geschäftsszenario
Tailwind Traders hat mehrere Datenquellen, einschließlich Websites, Point-of-Sale-Systeme (POS), Social Media-Kanäle und IoT-Geräte (Internet of Things, Internet der Dinge). Das Unternehmen möchte Azure für die Analyse aller Geschäftsdaten verwenden. Sie sind damit beauftragt, Anleitungen bereitzustellen, wie Azure die vorhandenen BI-Systeme verbessern kann. Sie müssen das Team dazu beraten, wie Azure-Speicherfunktionen der BI-Lösung des Unternehmens einen Mehrwert bieten können. Um die Datenanforderungen zu erfüllen, planen Sie die Empfehlung von Azure Data Lake Storage. Über Data Lake Storage wird ein Repository bereitgestellt, das für das Hochladen und Speichern großer Mengen an unstrukturierten Daten geeignet ist, damit leistungsstarke Big Data-Analysen durchgeführt werden können.
Sehen wir uns an, wie Azure Data Lake Storage die richtige Wahl für die Big Data-Anforderungen der Organisation sein kann.
| Szenario | Lösung |
|---|---|
| Bereitstellen eines Data Warehouse in der Cloud für die Verwaltung großer Datenmengen. | Azure Data Lake Storage wird auf virtueller Hardware auf der Azure-Plattform ausgeführt. Speicher ist skalierbar, schnell und zuverlässig, ohne dass hohe Gebühren anfallen. Speicherkosten werden von Computekosten getrennt. Wenn Ihr Datenvolumen wächst, ändern sich nur Ihre Speicheranforderungen. |
| Unterstützen einer vielfältigen Sammlung von Datentypen, z. B. JSON-Dateien, CSV-Dateien, Protokolldateien oder andere Formate. | Azure Data Lake Storage ermöglicht die Demokratisierung von Daten für Ihre Organisation, indem alle Datenformate (einschließlich Rohdaten) an einem einzigen Ort gespeichert werden. Durch die Beseitigung von Datensilos können Ihre Benutzer Tools wie Azure Data Explorer verwenden, um auf jedes Datenelement in ihrem Speicherkonto zuzugreifen und mit diesen zu arbeiten. |
| Ermöglichen der Datenerfassung und -speicherung in Echtzeit. | Azure Data Lake Storage kann Echtzeitdaten direkt aus einer Instanz von Apache Storm für Azure HDInsight, Azure IoT Hub, Azure Event Hubs oder Azure Stream Analytics erfassen. Der Dienst funktioniert auch mit teilweise strukturierten Daten und ermöglicht Ihnen die Erfassung all Ihrer Echtzeitdaten in Ihrem Speicherkonto. |
Zu berücksichtigende Punkte bei der Auswahl von Azure Blob Storage oder Azure Data Lake
In der folgenden Tabelle werden die Kriterien von Speicherlösungen für die Verwendung von Azure Blob Storage gegenüber Azure Data Lake verglichen. Überprüfen Sie die Kriterien, und überlegen Sie, welche Lösung für Tailwind Traders optimal ist.
| Vergleichen | Azure Data Lake | Azure Blob Storage |
|---|---|---|
| Datentypen | Gut geeignet zum Speichern großer Mengen von Textdaten | Gut geeignet zum Speichern unstrukturierter, nicht textbasierter Daten wie Fotos, Videos und Sicherungen |
| Geografische Redundanz | Datenreplikation muss manuell konfiguriert werden | Stellt standardmäßige georedundanten Speicher bereit |
| Namespaces | Unterstützung hierarchischer Namespaces | Unterstützung flacher Namespaces |
| Hadoop-Kompatibilität | Verwendung der in Azure Data Lake gespeicherten Daten durch Hadoop-Dienste möglich | Mithilfe des ABFS-Treibers (Azure Blob File System) können Anwendungen und Frameworks auf Daten in Azure Blob Storage zugreifen. |
| Security | Unterstützt präzisen Zugriff | Keine Unterstützung für präzisen Zugriff |