Entwerfen einer Lösung zur Datenintegration und -analyse mit Azure Synapse Analytics
Azure Synapse Analytics kombiniert Funktionen der Big Data-Analyse, Unternehmensdatenspeicherung und Datenintegration. Mit dem Dienst können Sie Abfragen an serverlose Daten oder Daten im großen Stil ausführen. Azure Synapse unterstützt die Erfassung, Untersuchung, Transformation und Verwaltung von Daten sowie Analysen für alle Ihre BI- und Machine Learning-Anforderungen.
Wissenswertes über Azure Synapse Analytics
Azure Synapse Analytics implementiert eine MPP-Architektur (Massively Parallel Processing, hochparallele Verarbeitung) und weist die folgenden Merkmale auf.
Die Azure Synapse Analytics-Architektur beinhaltet einen Steuerknoten und einen Pool von Computeknoten.
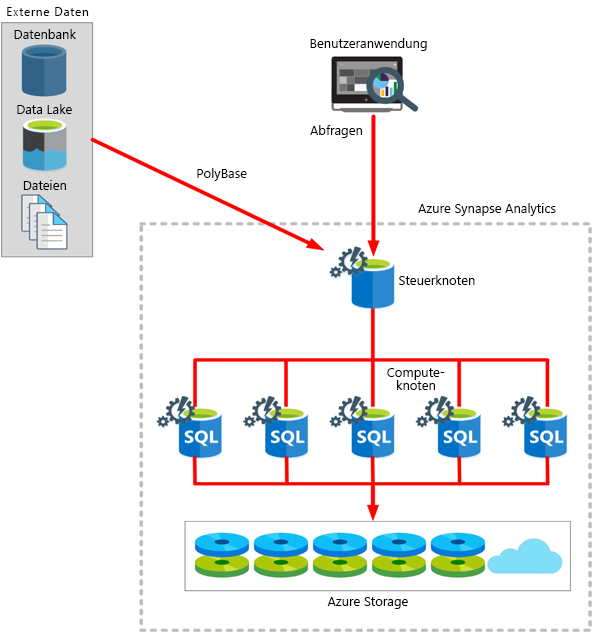
Der Steuerknoten ist der zentrale Bestandteil (das „Gehirn“) der Architektur. Er ist das Front-End, das mit allen Anwendungen interagiert. Die Computeknoten liefern die Rechnerleistung. Die zu verarbeitenden Daten sind gleichmäßig auf den Knoten verteilt.
Sie übermitteln Abfragen in Form von Transact-SQL-Anweisungen, und Azure Synapse Analytics führt sie aus.
Azure Synapse verwendet eine Technologie namens PolyBase, mit der Sie Daten aus relationalen und nicht relationalen Quellen abrufen und abfragen können. Sie können die Daten, die als SQL-Tabellen gelesen wurden, im Azure Synapse-Dienst speichern.

Komponenten von Azure Synapse Analytics
Azure Synapse Analytics besteht aus fünf Elementen:
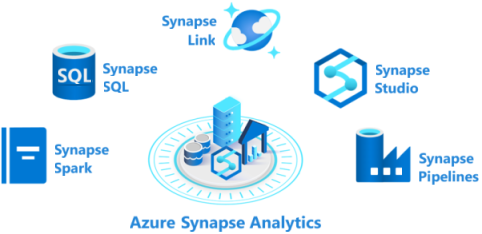
- Azure Synapse SQL-Pool: Synapse SQL bietet sowohl serverlose als auch dedizierte Ressourcenmodelle für die Arbeit mit einer knotenbasierten Architektur. Sie können dedizierte SQL-Pools erstellen, um von planbarer Leistung und planbaren Kosten zu profitieren. Für unregelmäßige oder ungeplante Workloads können Sie den stets verfügbaren, serverlosen SQL-Endpunkt verwenden.
- Azure Synapse Spark-Pool: Dieser Pool ist ein Cluster aus Servern, auf denen Apache Spark zum Verarbeiten von Daten ausgeführt wird. Datenverarbeitungslogiken werden mit einer der vier folgenden unterstützten Sprachen geschrieben: Python, Scala, SQL und C# (über .NET für Apache Spark). In Apache Spark für Azure Synapse ist Apache Spark integriert (die Open-Source-Engine für Big Data, die für Datenaufbereitung, Datentechnik, ETL und maschinelles Lernen verwendet wird).
- Azure Synapse Pipelines: Azure Synapse Pipelines nutzt die Funktionen von Azure Data Factory. Pipelines sind der cloudbasierte ETL- und Datenintegrationsdienst, mit dem Sie datengesteuerte Workflows erstellen können, um Datenverschiebungen und -transformationen bedarfsgesteuert zu orchestrieren. Sie können Aktivitäten einbinden, mit denen die Daten bei der Übertragung transformiert werden. Oder Sie können Daten aus unterschiedlichen Quellen miteinander vereinen.
- Azure Synapse Link: Mit dieser Komponente können Sie eine Verbindung mit Azure Cosmos DB herstellen. Diese Komponente kann verwendet werden, um in einer Azure Cosmos DB-Datenbank gespeicherte operative Daten in Quasi-Echtzeit zu analysieren.
- Azure Synapse Studio: Dieses Element ist eine webbasierte IDE, die zentral für die Arbeit mit allen Funktionen von Azure Synapse Analytics verwendet werden kann. Mit Azure Synapse Studio können SQL- und Spark-Pools erstellt, Pipelines definiert und ausgeführt und Links zu externen Datenquellen konfiguriert werden.
Analyseoptionen
Azure Synapse Analytics unterstützt eine Reihe analytischer Szenarien. Berücksichtigen Sie beim Überprüfen der Tabelle, wie die Szenarien für die Tailwind Traders-Organisation zutreffen.
| Analyse | Szenario | BESCHREIBUNG |
|---|---|---|
| Beschreibend | Was passiert? | Azure Synapse nutzt die Funktion für dedizierte SQL-Pools, mit der Sie ein dauerhaftes Data Warehouse zur Analyse von Was nun?-Fragen erstellen können. Sie können den serverlosen SQL-Pool verwenden, um Daten aus Dateien vorzubereiten, die in einem Data Lake gespeichert sind, um ein Data Warehouse interaktiv zu erstellen. |
| Diagnostic | Warum geschieht das? | Sie können die serverlose SQL-Poolfunktion innerhalb von Azure Synapse verwenden, um Daten in einem Data Lake interaktiv zu untersuchen. Mithilfe serverloser SQL-Pools können Benutzer schnell nach anderen Daten suchen, die ihnen beim Verständnis von Warum-Fragen helfen können. |
| Vorhersagend | Was wird wahrscheinlich passieren? | Azure Synapse Analytics verwendet seine integrierte Apache Spark-Engine und Azure Synapse Spark-Pools für Predictive Analytics. Es kombiniert diese Aktion mit anderen Diensten, z. B. Azure Machine Learning Services und Azure Databricks, um Ihnen bei der Beantwortung von Welche Zukunft?-Fragen zu helfen. |
| Vorschreibend | Was muss unternommen werden? | Sie können Prescriptive Analytics (präskriptive Analysen) in Echtzeit oder in Quasi-Echtzeit verwenden, um Lösungen für Ihre Welche Aktion?-Fragen zu identifizieren. Azure Synapse Analytics stellt diese Funktion sowohl über Apache Spark und Azure Synapse Link bereit als auch durch die Integration von Streamingtechnologien wie Azure Stream Analytics. |
Geschäftsszenario
Sehen wir uns ein Szenario an, in dem das Unternehmen Kunden mit Börseninformationen versorgt. Sie müssen eine Kombination aus Batch- und Streamverarbeitung bereitstellen, um die Tailwind Traders-Infrastruktur zu unterstützen. Die auf die Sekunde aktuellen Daten können zur Echtzeitüberwachung verwendet werden, um im Bruchteil einer Sekunde fundierte Kauf- oder Verkaufsentscheidungen zu treffen. Historische Daten sind ebenso wichtig, um Leistungstrends anzuzeigen. Welche Art von Data Warehouse- und Datenintegrationslösung würden Sie empfehlen, um Zugriff auf die Rohdatenströme und die von diesen Daten abgeleiteten vorbereiteten Geschäftsinformationen bereitzustellen? Mit Azure Synapse Analytics können Sie Daten aus externen Quellen erfassen und diese Daten dann in ein für die Analyseverarbeitung geeignetes Format transformieren und aggregieren.
Zu berücksichtigende Aspekte bei der Auswahl von Azure Data Factory oder Azure Synapse Analytics
In der folgenden Tabelle werden die Kriterien für Speicherlösungen für die Verwendung von Azure Data Factory gegenüber Azure Synapse Analytics verglichen. Überprüfen Sie die Kriterien, und überlegen Sie, welche Lösung für Tailwind Traders optimal ist.
| Vergleichen | Azure Data Factory | Azure Synapse Analytics |
|---|---|---|
| Datenfreigabe | Daten können von verschiedenen Data Factorys gemeinsam genutzt werden. | Nicht unterstützt |
| Lösungsvorlagen | Lösungsvorlagen werden im Azure Data Factory-Vorlagenkatalog bereitgestellt. | Lösungsvorlagen werden im Knowledge Center für Synapse-Arbeitsbereiche bereitgestellt. |
| Regionsübergreifende Integration Runtime-Flows | Regionsübergreifende Datenflüsse werden unterstützt. | Nicht unterstützt |
| Überwachen von Daten | Die Datenüberwachung ist in Azure Monitor integriert. | Diagnoseprotokolle sind in Azure Monitor verfügbar. |
| Überwachen von Spark-Aufträgen hinsichtlich des Datenflusses | Nicht unterstützt | Spark-Aufträge können mithilfe von Synapse Spark-Pools hinsichtlich des Datenflusses überwacht werden. |
Azure Synapse Analytics ist eine ideale Lösung für viele andere Szenarien. Ziehen Sie folgende Möglichkeiten in Betracht:
- Berücksichtigen der Vielzahl von Datenquellen. Wenn Sie über verschiedene Datenquellen verfügen, die Azure Synapse Analytics für codelose ETL- und Datenflussaktivitäten verwenden.
- Berücksichtigen von Machine Learning. Wenn Sie Machine Learning-Lösungen mittels Apache Spark implementieren müssen, können Sie Azure Synapse Analytics für integrierte Unterstützung von AzureML verwenden.
- Berücksichtigen der Data Lake-Integration. Wenn Sie vorhandene Daten in einem Data Lake gespeichert haben und Integration in Azure Data Lake und andere Eingabequellen benötigen, bietet Azure Synapse Analytics eine nahtlose Integration zwischen beiden Komponenten.
- Berücksichtigen von Echtzeitanalysen. Wenn Sie Echtzeitanalysen benötigt, können Sie Features wie Azure Synapse Link verwenden, um Daten in Echtzeit zu analysieren und Erkenntnisse bereitzustellen.