Erkunden von fortlaufenden Vorgängen
Fortlaufende Vorgänge sind eine der acht Funktionen in der DevOps-Taxonomie.
Entdecken Sie, warum kontinuierliche Vorgänge erforderlich sind.
Bei komplexen Systemen können Fehler auftreten, die kostspielige Ausfälle und Unterbrechungen verursachen. Sehen wir uns einige Beispiele an.
| Unternehmen | Ereignis |
|---|---|
|
Delta Air Lines |
Im August 2016 wurde Delta gezwungen, 2.300 Flüge abzubrechen, als ein einzelnes Stück fehlfunktionierender Ausrüstung einen Stromausfall in seinem Betriebszentrum in Atlanta verursachte. Gemeldete Kosten für das Unternehmen betrug 150 Millionen US-Dollar. |
|
betreffenFedEx und UK National Health Service |
Im Mai 2017 verursachte WannaCry Ransomware Betriebsunterbrechungen an FedEx. Eine FedEx-Tochter meldete 300 Millionen US-Dollar an Verlusten. Der nationale Gesundheitsdienst des Vereinigten Königreichs war ein weiteres Opfer der Ransomware, die den Zugriff auf seine Computer blockierte, wichtige medizinische Ausrüstung gesperrt und einige Krankenhäuser gezwungen, Krankenwagen an andere Standorte umzuleiten. |
|
Amazon S3 |
Im Februar 2017 verursachte der Betreiberfehler eine vierstündige Unterbrechung der Kernspeicherdienste von Amazon, die mehrere Auswirkungen auf wichtige Webeigenschaften wie Alexa, IFTTT, Quora und Trello hatten. |
|
|
Bei LinkedIn ist ein Problem aufgetreten, das verhinderte, dass DEV-Arbeit zwei Monate lang durchgeführt wurde. |
|
betreffenEquifax |
Equifax erlebte 2017 einen Verstoß, der dazu führte, dass die persönlichen Informationen von über 160 Millionen Verbrauchern offengelegt wurden. Wir haben es ausführlicher in Continuous Security besprochen. |
Die Geschäftlichen Auswirkungen und Kosten einer Verletzung
Die Kosten einer Sicherheitsverletzung gehen häufig weit über die verlorenen Umsätze und das verlorene Vertrauen in ein Unternehmen hinaus. Diese Kosten können folgendes umfassen:
- Antwort-&-Benachrichtigung
- Es gibt Betriebs- und Servicekosten, um betroffene Parteien gemäß den gesetzlichen Vorschriften zu benachrichtigen. Diese Kosten umfassen häufig auch zusätzliche Kosten für Callcenter, PR-Support und Kreditüberwachungsdienste.
- Verlorene Mitarbeiterproduktivität und Umsatz
- Der Generalberater von Yahoo trat zurück, und der CEO wurde 2016 nicht mit einem jährlichen Bonus ausgezeichnet.
- Rechtsstreitigkeiten und Siedlungen
- Ziel zahlte 18,5 Millionen US-Dollar an 47 US-Staaten.
- Behördliche Geldbußen und Antworten
- Mit den seit 2018 wirksamen neuen Datenschutzpolitiken in der Europäischen Union beträgt die Geldbuße 4% jährlicher Einnahmen oder 20 Millionen Euro, je nachdem, welcher Wert größer ist.
- Kosten für Markenwiederherstellung
- Das Bergbautechnologieunternehmen Codan verzeichnete einen Umsatzrückgang von 45 Millionen US-Dollar auf 9,2 Millionen US-Dollar innerhalb eines Jahres.
- Sonstige Verbindlichkeiten
- Verizon zahlte nach zwei massiven Hacks 350 Millionen DOLLAR weniger für Yahoo.
Es können auch zusätzliche Sicherheits- und Überwachungsanforderungen erforderlich sein.
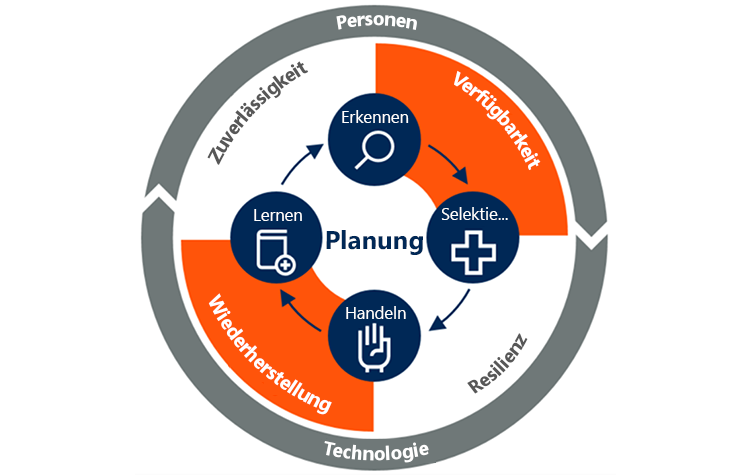
Verfügbarkeit und Wiederherstellung in fortlaufenden Vorgängen
Laut einer Umfrage von Gartner erwarten Unternehmens- und IT-Führungskräfte, dass bis 2020 rund 47% Produktionsanwendungen an öffentlichen Cloudstandorten ausgeführt werden.
Wenn ganze Rechenzentren mit einer Codezeile zerstört werden können,&ich den Fokus von O-Führungskräften auf die Verfügbarkeit und Wiederherstellung von Produktionsumgebungen ändern muss. Neue Bereitstellungsmuster ändern sich, wie wir die Verfügbarkeit und Wiederherstellungsfunktionen von Anwendungen und Infrastruktur sicherstellen.
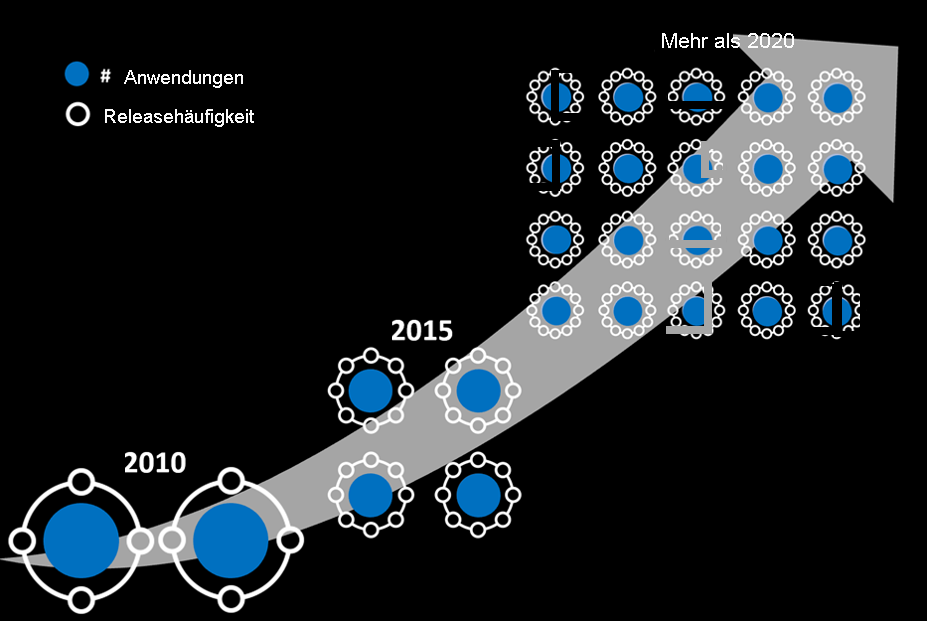
Steigende Anzahl von Apps und Versionen in der Produktion
Die wichtigsten Leistungsindikatoren für die Leistung der Softwarebereitstellung sind:
- Vorlaufzeit für Änderungen
- Bereitstellungshäufigkeit
- Mittlere Zeit für die Wiederherstellung
- Änderungsfehlerrate
Teams, die daran arbeiten, die Geschwindigkeit zu erhöhen, aber nicht ausreichend in die Integration von Qualität in den Prozess investieren, werden größere Misserfolge erleben und mehr Zeit benötigen, um den Dienst wiederherzustellen. Teams, die Qualität in den Prozess integrieren, erzielen sowohl Geschwindigkeit als auch Stabilität.
Die Anzahl der Web- und mobilen Anwendungen und die Häufigkeit der Anwendungsversionen sind erheblich gestiegen. Code ist auch immer komplexer geworden.
Hinweis
Ein großer Teil des Werts von DevOps im Allgemeinen besteht darin, das richtige Gleichgewicht zwischen Innovation (Geschwindigkeit) und Geschäftskontinuität (Kontrolle) zu finden.
Was ist fortlaufender Betrieb?
Wichtig
Der kontinuierliche Betrieb reduziert oder beseitigt die Notwendigkeit geplanter Ausfallzeiten oder Unterbrechungen, z. B. geplante Wartungen. Die kontinuierliche Überwachung von Infrastruktur, Anwendungen und Diensten sollte nach Möglichkeit an die automatisierte Wartung gebunden werden. Ein Benutzer sollte nie wissen, wann ein Update oder eine inkrementelle Version auftritt.
Das Diagramm zeigt, wie AIOps und Digital Experience Monitoring, Application Release Orchestration und uptime-basierte Überwachung Customer Experience Insights, schnelle Anwendungsbereitstellung, dynamische Skalierbarkeit und Cloud-first-Strategien unterstützen.
Vergleich herkömmlicher und fortlaufender Vorgänge
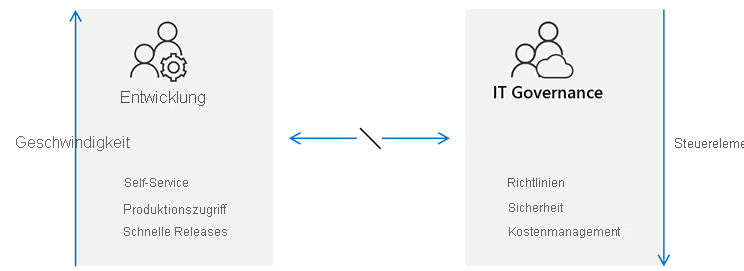
In einem herkömmlichen Enterprise-Modell erzwingt die IT das, was freigegeben wird, und steuert jeden mit starren Prozessen und Verfahren.
Dieser Ansatz führt zu einer Fehlausrichtung zwischen Entwicklungsteams und IT-Governance. Entwicklungsteams sind hauptsächlich agil, konzentriert sich auf Geschwindigkeit und erwarten, dass sie so oft wie gewünscht veröffentlicht werden. Für sie scheint IT Governance ein Engpass zu sein, der nicht mit den erwarteten Time to Market-Zielen der heutigen Geschäftsanforderungen übereinstimmt.
Wichtig
Nach der ordnungsgemäßen Implementierung kann DevOps sowohl Innovation (Geschwindigkeit) als auch Geschäftskontinuität (Kontrolle) bereitstellen.
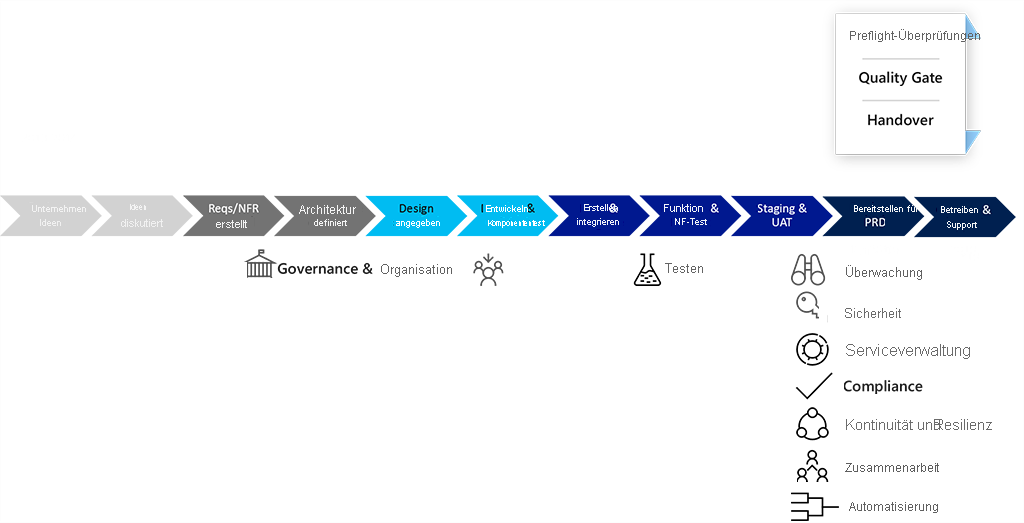
In einem herkömmlichen Entwicklungslebenszyklus:
- Tests werden direkt vor dem Go-Live durchgeführt.
- Die Überwachung wird oft übergeben.
- Sicherheit wird häufig in den Testphasen konsultiert.
- Während der Übergabe müssen Sicherheitsüberprüfungen des Codes und alle Dienstverwaltungssteuerelemente durchgeführt werden.
- Compliance ist oft nicht Teil der Übergabe, sondern etwas, das während des Betriebszustands eines Diensts "eingeblennt" wird.
- Resilienz/Kontinuitätsplanung erfolgt im Rahmen der Entwurfsphase, aber tatsächliche Tests verwandter Szenarien werden häufig nur während der Betriebs- oder Testphase durchgeführt, was zu Konfigurationsänderungen, Überarbeitungen und verschwendetem Aufwand führen kann.
- Die Zusammenarbeit zwischen Vorgängen, Sicherheit & Compliance und Entwicklern erfolgt häufig reaktiv durch Vorfallverwaltungs- und Problemverwaltungsprozesse.
- Die Automatisierung bis zu den letzten Phasen verlassen oft nur wenige Ressourcen, um dies zu erledigen.
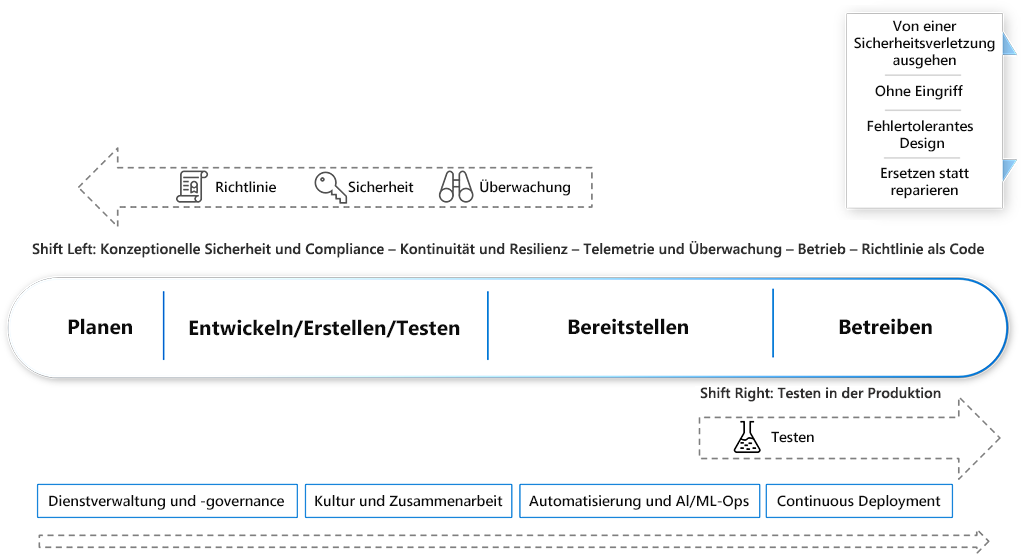
Neue Methoden, Technologien und Arbeitsweisen rufen einen neuen Ansatz für kontinuierliche Vorgänge auf. Die folgenden acht wichtigsten Kontinuierlichen Betriebspraktiken sind entstanden und entwickeln sich weiter:
- Sicherheit und Compliance bereits im Design erkennt an, dass bestimmte Standards, Rechtsvorschriften, aber auch geschäftliche Anforderungen wie Rückverfolgbarkeit und Überprüfbarkeit beim Entwurf für hochautomatisierte Cloudumgebungen berücksichtigt werden müssen.
- Die Kontinuität und Resilienz erfordert eine enge Zusammenarbeit mit der Organisation, um sicherzustellen, dass die Geschäftsanforderungen im Design und in der Implementierung widerzuspiegeln sind.
- Telemetrie und Überwachung können verwendet werden, um Kundennutzungsmuster, potenzielle neue Anforderungen und detaillierte Informationen darüber zu ermitteln, wo Benutzer Auf Fehler stoßen. Diese Tools können auch dazu beitragen, dass der Wert bereitgestellt wird.
-
Service Management ist eine andere Diskussion in einer DevOps-Kultur.
- Die Umstellung bedeutet, dass Sie es besitzen. Sie erstellen es, führen Sie sie aus, und wenn sie unterbrochen wird, beheben Sie sie.
- Konzentrieren Sie sich auf das, was erforderlich ist.
- Befähigen Sie Governance.
- Transparenz erleichtern.
- Kultur und Zusammenarbeit sind für den kontinuierlichen Betrieb unerlässlich. Organisationen müssen häufig die Art und Weise ändern, wie sie arbeiten, um die Transformation in DevOps-Teams zu erleichtern. Die Zusammenarbeit ist auch beim Entwerfen für Sicherheit und Resilienz von wesentlicher Bedeutung.
- Automatisierungs- und AI/ML-Ops sind wichtige Aspekte, die DevOps (und Cloud) gegenüber herkömmlichen Betriebsteams unterscheiden. Der Fokus muss auf das gesamte System liegen, das automatisiert (systemische Automatisierung) und nicht nur ein Bereich ist.
- Die kontinuierliche Bereitstellung verwendet moderne Releasepipelines, um Entwicklungsteams die schnelle und sichere Bereitstellung neuer Features zu ermöglichen, sodass ein kontinuierlicher Kundenwert und die Zeit zur Behebung von Problemen verkürzt wird.
- Bei Shift-Right-Tests werden Verfahren wie Dark-Launching, Featureflags, Überwachung und A/B-Tests verwendet. Teams können dann weiterhin Tests durchführen, um sicherzustellen, dass eine Anwendung verhalten, leistung und Verfügbarkeitserwartungen während der Liveverwendung erfüllt.
Für den Übergang zu einem DevOps-Ansatz ist ein erheblicher Paradigmenwechsel in der Kultur erforderlich, um mit einem modernen IT-Ansatz für einen geschäftlichen Mehrwert zu sorgen.
| Traditionelle IT | Moderne IT | |
|---|---|---|
| DNA | Vermittlung | Entfernung der Vermittlung |
| Servicebereitstellung | Wellenbasiert | Fortlaufende Iteration |
| Dienststabilität | Entwurf für Erfolg (HA/Redundant) | Entwurf für Fehler (ausfallsicher) |
| Delegierungsebenen | IT-Silos | End-to-End-Dienste |
| Abläufe | In Dokumenten, optimiert, neu gestaltet | Self Service, Wissen, geringe Reibung, automatisiert |
| Automatisierung | Isoliert, manuell initiiert | Systemisch, ausgelöst, automatisch |
| Überwachung | Element, fehlerorientiert | Service, End-to-End-Funktion fokussiert |
| Unterstützen | Service Desk / Contact Center | Kundendienst / Self-Service |
| Lebenszyklus | N-1 oder älter | N, N+1 |
| Konfigurations-/Bestandsverwaltung | Ermittelte/manuelle Konfiguration | Vorgeschrieben, deklarativ, automatisiert |
Diese Änderungen führen zu vereinfachten und automatisierten Prozessen, abgestimmten Ergebnisanreizen, reduzierten Risiken und einem kundenorientierten Ansatz.