Übung: Untersuchen der Verteilung von Tabellen durch Citus
In dieser Übung erstellen Sie eine Azure Cosmos DB for PostgreSQL-Datenbank mit mehreren Knoten. Anschließend erstellen Sie mehrere Tabellen, bevor Sie einige Abfragen für Ihre Datenbank durchführen, um weitere Informationen zur von der Citus-Erweiterung für PostgreSQL bereitgestellten verteilten Architektur zu erhalten.
Erstellen einer Datenbank in Azure Cosmos DB for PostgreSQL
Um diese Übung abzuschließen, müssen Sie einen Azure Cosmos DB for PostgreSQL-Cluster erstellen. Ihr Cluster verfügt über Folgendes:
- Einen Koordinatorknoten mit vier virtuellen Kernen, 16 GiB RAM und 512 GiB Speicher
- Zwei Workerknoten mit jeweils vier virtuellen Kernen, 32 GiB RAM und 512 GiB Speicher
Navigieren Sie in einem Webbrowser zum Azure-Portal.
Wählen Sie im Azure-Portal nacheinander Ressource erstellen, Datenbanken und Azure Cosmos DB aus. Sie können auch die Suchfunktion verwenden, um die Ressource zu finden.
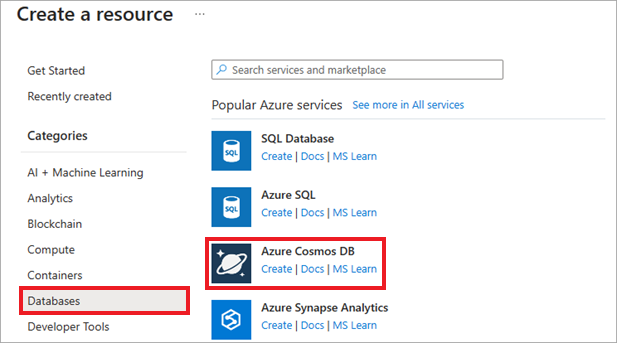
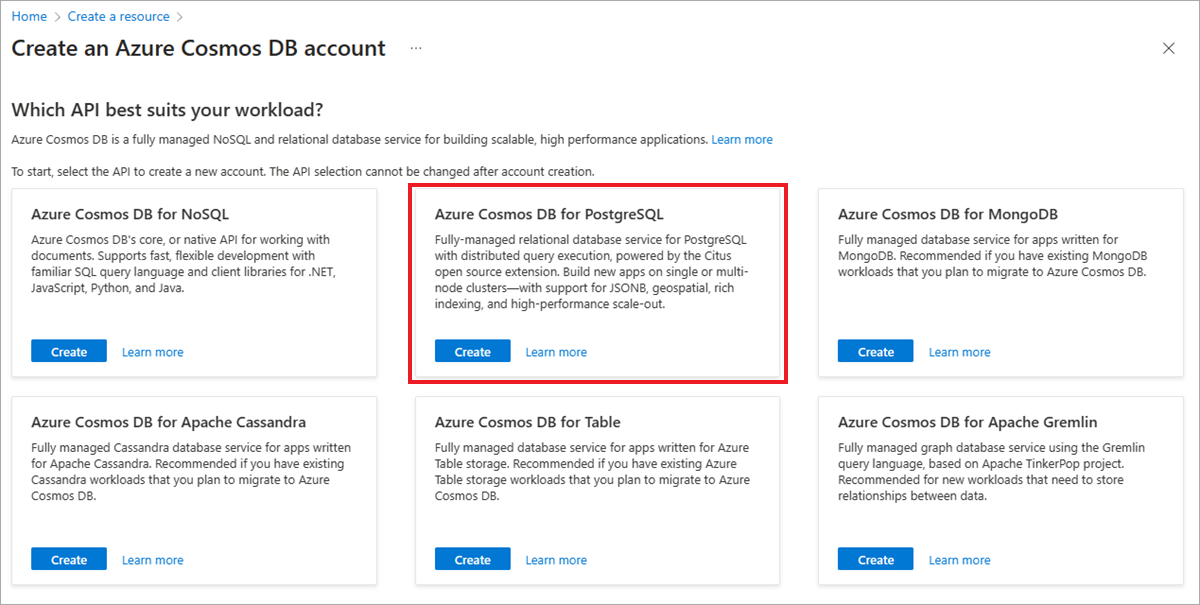
Wählen Sie auf dem Bildschirm API-Option auswählen auf der Kachel Azure Cosmos DB for PostgreSQL die Option Erstellen aus.
Hinweis
Nachdem Sie Erstellen ausgewählt haben, wird im Portal ein Datenbankkonfigurationsbildschirm angezeigt.
Geben Sie auf der Registerkarte Grundlegende Einstellungen folgende Informationen ein:
Parameter Wert Projektdetails Subscription Wählen Sie Ihr Azure-Abonnement aus. Resource group Wählen Sie Neu erstellen aus, und geben Sie der Ressourcengruppe den Namen learn-cosmosdb-postgresql.Clusterdetails Clustername Geben Sie einen global eindeutigen Namen ein, wie z. B. learn-cosmosdb-postgresql.Standort Übernehmen Sie die Standardeinstellung, oder verwenden Sie eine Region in Ihrer Nähe. Skalieren Weitere Informationen finden Sie in den Konfigurationseinstellungen im nächsten Schritt. PostgreSQL-Version Behalten Sie die Standardversion (15) bei. Administratorkonto Administratorbenutzername Der Benutzername lautet citusund kann nicht bearbeitet werden.Kennwort Geben Sie ein sicheres Kennwort ein, und bestätigen Sie es. 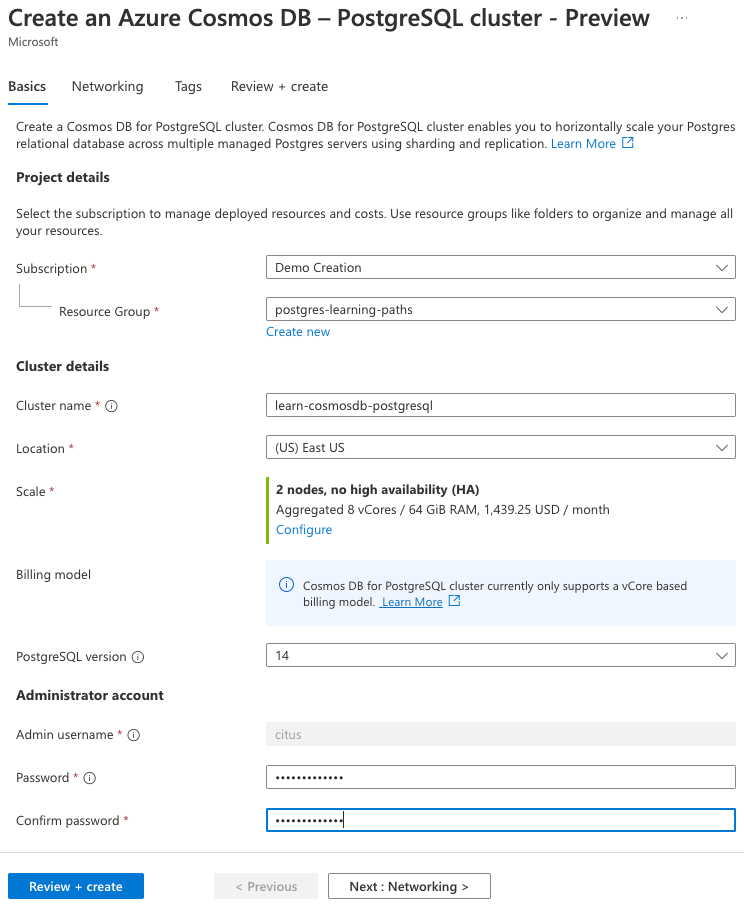
Notieren Sie sich das Kennwort zur späteren Verwendung.
Wählen Sie für die Einstellung Skalierung die Option Konfigurieren aus. Legen Sie auf der Seite für die Knotenkonfiguration folgende Einstellungen fest:
Parameter Wert Nodes Anzahl der Knoten Wählen Sie zwei Knoten aus. Compute pro Knoten Wählen Sie die Option 4 vCores, 32 GiB RAM (4 virtuelle Kerne, 32 GiB RAM) aus. Speicher pro Knoten Wählen Sie die Option 512 GiB aus. Koordinator (Möglicherweise müssen Sie diesen Abschnitt aufklappen) Koordinator-Compute Wählen Sie die Option 4 vCores, 16 GiB RAM (4 virtuelle Kerne, 16 GiB RAM) aus. Koordinatorspeicher Wählen Sie die Option 512 GiB aus. Die Funktionen für Hochverfügbarkeit und automatisches Failover werden in dieser Übung nicht genutzt. Lassen Sie das Kontrollkästchen Hochverfügbarkeit daher deaktiviert.
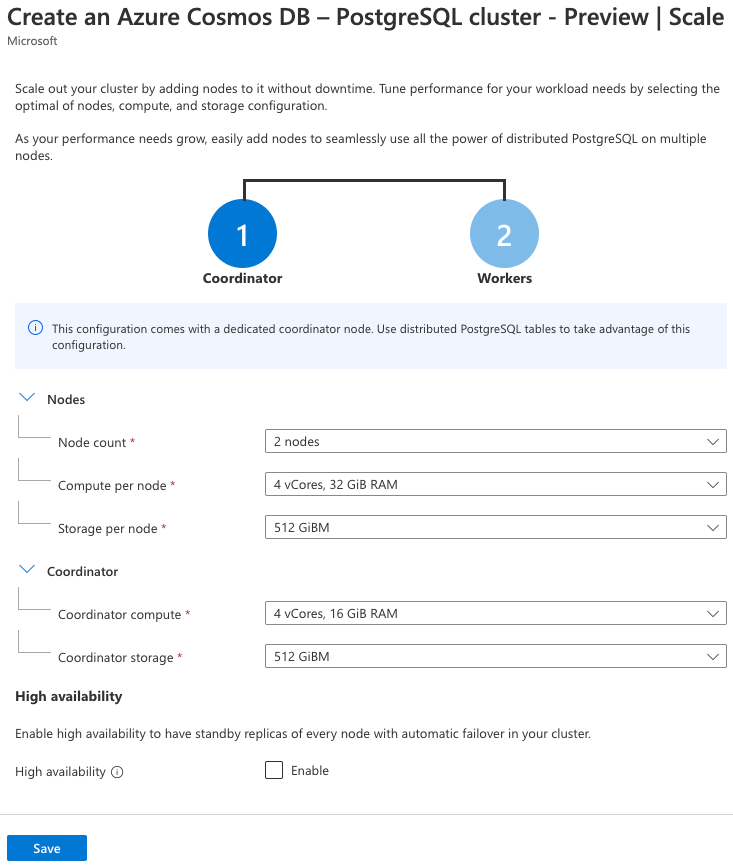
Klicken Sie auf der Skalierungsseite auf Speichern, um zur Clusterkonfiguration zurückzukehren.
Wählen Sie die Schaltfläche Weiter: Netzwerk > aus, um im Konfigurationsdialogfeld zur Registerkarte Netzwerk zu wechseln.
Legen Sie auf der Registerkarte Netzwerk die Option Konnektivitätsmethode auf Public access (allowed IP addresses) (Öffentlicher Zugriff [zugelassene IP-Adressen]) fest. Aktivieren Sie das Kontrollkästchen Allow public access from Azure services and resources within Azure to this cluster (Von Azure-Diensten und -Ressourcen in Azure aus öffentlichen Zugriff auf diesen Cluster gestatten).
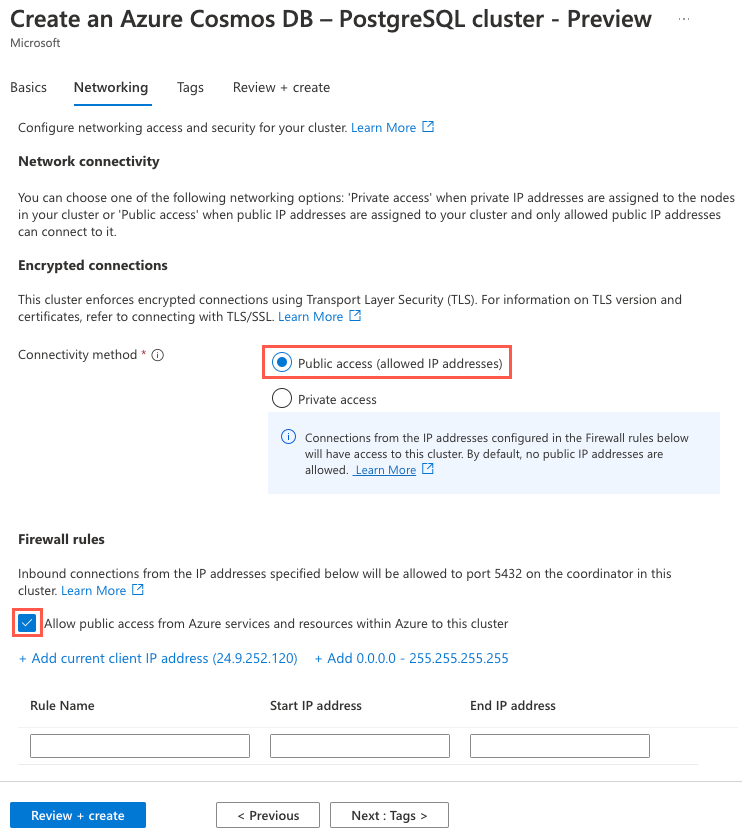
Wählen Sie die Schaltfläche Überprüfen und erstellen aus und wählen Sie dann auf dem Überprüfungsbildschirm die Option Erstellen aus, um Ihr Cluster zu erstellen.
Herstellen einer Verbindung mit der Datenbank mithilfe von psql in Azure Cloud Shell
Nachdem die Bereitstellung Ihres Azure Cosmos DB for PostgreSQL-Clusters abgeschlossen wurde, navigieren Sie zur Ressource im Azure-Portal.
Wählen Sie im Navigationsmenü auf der linken Seite unter Einstellungen die Option Verbindungszeichenfolgen aus, und kopieren Sie die Verbindungszeichenfolge mit der Bezeichnung psql.
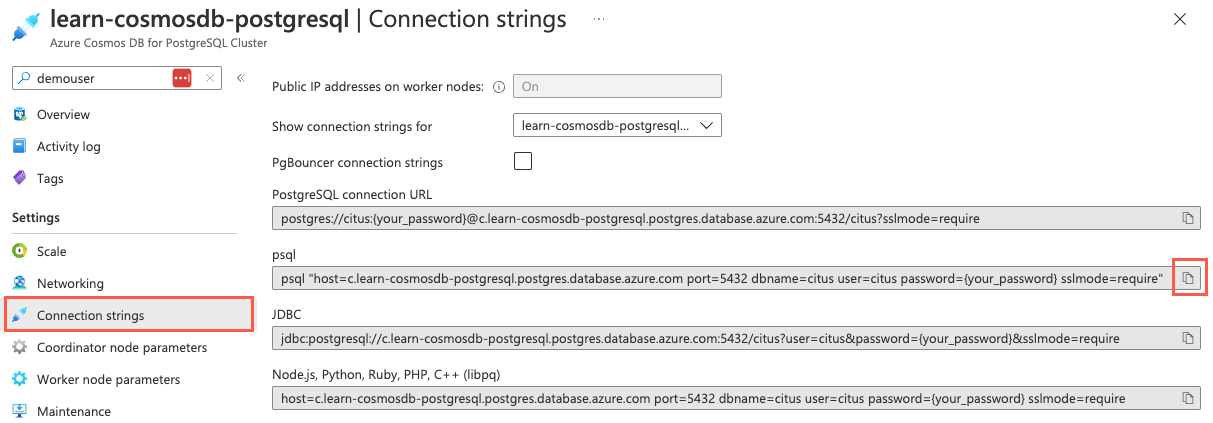
Auf der Seite „Verbindungszeichenfolgen“ wird die Schaltfläche „In Zwischenablage kopieren“ rechts neben der psql-Verbindungszeichenfolge hervorgehoben.
Fügen Sie die Verbindungszeichenfolge in einen Text-Editor ein, wie z. B. Notepad, und ersetzen Sie das Token
{your_password}durch das Kennwort, das Sie dem Benutzercitusbei der Clustererstellung zugewiesen haben. Kopieren Sie die aktualisierte Verbindungszeichenfolge für die nachfolgende Verwendung.Öffnen Sie den Azure Cloud Shell-Dienst in einem Webbrowser.
Wählen Sie Bash als Umgebung aus.
Wenn Sie dazu aufgefordert werden, wählen Sie das Abonnement aus, das Sie für Ihr Azure Cosmos DB for PostgreSQL-Konto verwendet haben. Klicken Sie anschließend auf Speicher erstellen.
Verwenden Sie nun das Befehlszeilenhilfsprogramm „psql“, um eine Verbindung mit Ihrer Datenbank herzustellen. Fügen Sie Ihre aktualisierte Verbindungszeichenfolge (die mit dem richtigen Kennwort) an der Eingabeaufforderung im Cloud Shell-Dienst ein, und führen Sie dann den Befehl aus, der dem folgenden Befehl ähneln sollte:
psql "host=c.learn-cosmosdb-postgresql.postgres.database.azure.com port=5432 dbname=citus user=citus password=P@ssword.123! sslmode=require"
Ermitteln von Informationen zu den Knoten in Ihrem Cluster
Die Koordinatormetadatentabellen enthalten Informationen zu Workerknoten in Ihrem Cluster.
Führen Sie die folgende Abfrage für die Workerknotentabelle (
pg_dist_node) aus, um Informationen zu den Knoten in Ihrem Cluster anzuzeigen:-- Turn on expanded display to pivot the results \x-- Retrieve node details SELECT * FROM pg_dist_node;Überprüfen Sie die Abfrageausgabe auf Details, einschließlich der ID, des Namens und des Ports der einzelnen Knoten. Dort sehen Sie u. a. auch, ob der Knoten aktiv ist und Shards enthalten sollte.
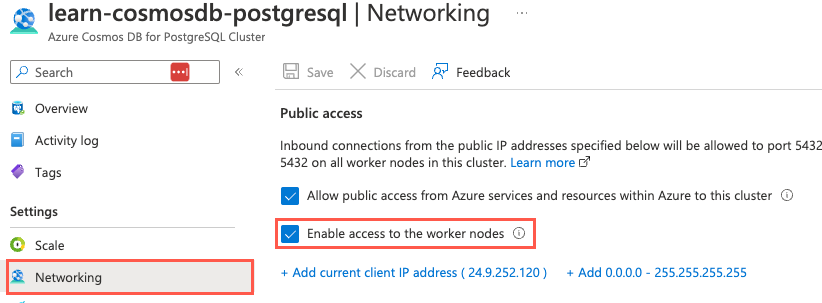
-[ RECORD 1 ]----+----------------------------------------------------------------- nodeid | 2 groupid | 2 nodename | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com nodeport | 5432 noderack | default hasmetadata | t isactive | t noderole | primary nodecluster | default metadatasynced | t shouldhaveshards | t -[ RECORD 2 ]----+----------------------------------------------------------------- nodeid | 3 groupid | 3 nodename | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com nodeport | 5432 noderack | default hasmetadata | t isactive | t noderole | primary nodecluster | default metadatasynced | t shouldhaveshards | t -[ RECORD 3 ]----+----------------------------------------------------------------- nodeid | 4 groupid | 0 nodename | private-c.learn-cosmosdb-postgresql.postgres.database.azure.com nodeport | 5432 noderack | default hasmetadata | t isactive | t noderole | primary nodecluster | default metadatasynced | t shouldhaveshards | fMithilfe der in der Ausgabe bereitgestellten Knotennamen und Portnummern können Sie eine direkte Verbindung mit Workerknoten herstellen, was eine gängige Methode zur Optimierung der Abfrageleistung darstellt. Wenn Sie eine direkte Verbindung mit Workerknoten herstellen möchten, muss das Kontrollkästchen Enable access to the worker nodes (Zugriff auf die Workerknoten ermöglichen) auf der Seite Netzwerk Ihrer Azure Cosmos DB for PostgreSQL-Ressource im Azure-Portal aktiviert sein.
Erstellen verteilter Tabellen
Nachdem Sie nun eine Verbindung mit Ihrer Datenbank hergestellt haben, können Sie mit dem Auffüllen der Datenbank beginnen. Sie verwenden psql für Folgendes:
- Erstellen von Benutzern und „payment“-Tabellen
- Weisen Sie Citus an, beide Tabellen zu verteilen, indem Sie sie horizontal auf die Workerknoten partitionieren.
Verteilte Tabellen werden horizontal auf verschiedenen Workerknoten partitioniert. Bei dieser Verteilung werden die Zeilen der Tabelle auf verschiedenen Knoten in Fragmenttabellen (sogenannten Shards) gespeichert.
Führen Sie in Cloud Shell die folgende Abfrage aus, um die Tabellen
payment_usersundpayment_eventszu erstellen:CREATE TABLE payment_users ( user_id bigint PRIMARY KEY, url text, login text, avatar_url text ); CREATE TABLE payment_events ( event_id bigint, event_type text, user_id bigint, merchant_id bigint, event_details jsonb, created_at timestamp, -- Create a compound primary key so that user_id can be set as the distribution column PRIMARY KEY (event_id, user_id) );Die
PRIMARY KEY-Zuweisung für die Tabellepayment_eventsist ein zusammengesetzter Schlüssel, wodurch das Felduser_idals Verteilungsspalte zugewiesen werden kann.Wenn die
CREATE TABLE-Befehle ausgeführt werden, werden lokale Tabellen auf dem Koordinatorknoten erstellt. Um die Tabellen auf die Workerknoten zu verteilen, müssen Sie diecreate_distributed_table-Funktion für jede Tabelle ausführen und dabei angeben, welche Verteilungsspalte beim Sharding verwendet werden soll. Führen Sie im Cloud Shell-Dienst die folgende Abfrage aus, um die Tabellenpayment_eventsundpayment_usersauf die Workerknoten zu verteilen:SELECT create_distributed_table('payment_users', 'user_id'); SELECT create_distributed_table('payment_events', 'user_id');Die Tabellen
payment_eventsundpayment_userswurden derselben Verteilungsspalte zugewiesen, wodurch verwandte Daten für beide Tabellen demselben Knoten zugeordnet werden. In diesem Lernmodul erhalten Sie keine Informationen zum Auswählen der richtigen Verteilungsspalte. Im Artikel Auswählen von Verteilungsspalten in Azure Cosmos DB for PostgreSQL in der Microsoft-Dokumentation können Sie jedoch mehr darüber erfahren.
Erstellen einer Verweistabelle
Als Nächstes verwenden Sie psql für Folgendes:
- Erstellen der Tabelle „merchants“
- Weisen Sie Citus an, die gesamte Tabelle als Verweistabelle auf jeden Workerknoten zu verteilen.
Eine Verweistabelle ist eine verteilte Tabelle, deren gesamter Inhalt in einem einzigen Shard konzentriert ist, der auf jeden Worker repliziert wird. Abfragen für jeden Worker können lokal auf die Verweisinformationen zugreifen, und zwar ohne den Netzwerkmehraufwand für das Anfordern von Zeilen von einem anderen Knoten. Bei Verweistabellen muss keine Verteilungsspalte angegeben werden, da nicht zwischen verschiedenen Shards pro Zeile unterschieden werden muss. Verweistabellen sind in der Regel klein. Sie werden zum Speichern von Daten verwendet, die für Abfragen relevant sind, die auf allen Workerknoten ausgeführt werden.
Führen Sie im Cloud Shell-Dienst die folgende Abfrage aus, um die Tabelle
payment_merchantszu erstellen:CREATE TABLE payment_merchants ( merchant_id bigint PRIMARY KEY, name text, url text );Verwenden Sie als Nächstes die
create_reference_table()-Funktion, um die Tabelle auf jeden Workerknoten zu verteilen.SELECT create_reference_table('payment_merchants');
Laden von Daten in die Ereignistabelle
Woodgrove Bank hat Ihnen seine historischen Ereignisdaten als CSV-Datei zur Verfügung gestellt, damit Sie beim Installieren und Testen der gewünschten Erweiterungen mit diesen Daten arbeiten können. Sie stellen Benutzerdaten über ein sicheres Azure Blob Storage-Konto für Sie bereit, damit Sie die payment_users-Tabelle in der nächsten Übung auffüllen können. Die Datei events.csv ist über eine öffentlich zugängliche URL verfügbar.
Sie können den Befehl COPY nutzen, um ein einmaliges Massenladen dieser Daten in die Tabelle payment_events durchzuführen.
Führen Sie den folgenden Befehl aus, um die CSV-Dateien mit den Benutzer- und Zahlungsinformationen herunterzuladen. Führen Sie anschließend den Befehl
COPYaus, um die Daten aus den heruntergeladenen CSV-Dateien in die verteilten Tabellenpayment_usersundpayment_eventszu laden:SET CLIENT_ENCODING TO 'utf8'; \COPY payment_events FROM PROGRAM 'curl https://raw.githubusercontent.com/MicrosoftDocs/mslearn-create-connect-postgresHyperscale/main/events.csv' WITH CSVIm ausgegebenen Befehl
COPYwird der Koordinator mithilfe derFROM PROGRAM-Klausel informiert, dass die Datendateien aus einer auf dem Koordinatorknoten ausgeführten Anwendung (in diesem Fallcurl) abgerufen werden sollen. Die OptionWITH CSVenthält Formatinformationen zur erfassten Datei.Führen Sie die folgenden Befehle aus, um zu überprüfen, ob die Daten mithilfe des Befehls
COPYin die Tabellepayment_eventsgeladen wurden.SELECT COUNT(*) FROM payment_events;
Anzeigen von Details zu Ihren verteilten Tabellen
Nachdem Sie nun einige verteilte Tabellen erstellt haben, verwenden wir die Ansicht citus_tables, um diese Tabellen zu untersuchen.
Führen Sie die folgende Abfrage aus, um die Details Ihrer verteilten Tabellen anzuzeigen:
SELECT table_name, citus_table_type, distribution_column, table_size, shard_count FROM citus_tables;Sehen Sie sich die Ausgabe der Abfrage und die darin enthaltenen Details an.
table_name | citus_table_type | distribution_column | table_size | shard_count ------------------+------------------+---------------------+------------+------------- payment_events | distributed | user_id | 26 MB | 32 payment_merchants | reference | <none> | 48 kB | 1 payment_users | distributed | user_id | 512 kB | 32Hinweis
Beachten Sie den
shard_countund wie viele Shards für verteilte Tabellen bzw. für Verweistabellen verwendet werden. Diese Unterscheidung gibt Aufschluss darüber, wie Citus die Verteilung von Daten intern handhabt. Die Ansichtcitus_tableenthält außerdem Informationen zur Größe Ihrer Tabellen.
Untersuchen des Shardings von Tabellen
Sehen Sie sich als Nächstes die Shards an, die von Citus erstellt wurden, um die Daten der einzelnen Tabellen zu verteilen:
Die Metadatentabelle
pg_dist_shardenthält die Details der Shards in Ihrem Cluster. Führen Sie die folgende Abfrage durch, um die für jede Ihrer Tabellen erstellten Shards anzuzeigen:SELECT * from pg_dist_shard;Überprüfen Sie die Ausgabe der obigen Abfrage. Denken Sie daran, dass die Tabelle
payment_merchantssich in einem einzelnen Shard befindet. Vergleichen Sie dies mit den Tabellenpayment_eventsundpayment_users, die jeweils 32 Shards enthalten.Wenn Sie nachvollziehen möchten, wie Citus das Sharding von Verweistabellen verarbeitet, können Sie die Ansicht
citus_shardsverwenden, um den Speicherort der Shards auf Workerknoten anzuzeigen. Führen Sie die folgenden Abfrage aus:SELECT table_name, shardid, citus_table_type, nodename FROM citus_shards WHERE table_name = 'payment_merchants'::regclass;In der Ausgabe wird der einzelne Shard der Tabelle
payment_merchantsauf jeden Knoten im Cluster verteilt.table_name | shardid | citus_table_type | nodename ------------------+---------+------------------+----------------------------------------------------------------- payment_merchants | 102072 | reference | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_merchants | 102072 | reference | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_merchants | 102072 | reference | private-c.learn-cosmosdb-postgresql.postgres.database.azure.comFühren Sie zum Vergleich die folgende Abfrage aus, um die Verteilung von Shards für die Tabelle
payment_eventsanzuzeigen:SELECT table_name, shardid, citus_table_type, nodename FROM citus_shards WHERE table_name = 'payment_events'::regclass;Für
distributed-Tabellen wird jedershardidnur einmal in den Ergebnissen angezeigt, und jeder Shard ist nur auf einem einzelnen Knoten vorhanden.table_name | shardid | citus_table_type | nodename ---------------+---------+------------------+----------------------------------------------------------------- payment_events | 102040 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102041 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102042 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102043 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102044 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102045 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102046 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102047 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102048 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102049 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102050 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102051 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102052 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102053 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102054 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102055 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102056 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102057 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102058 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102059 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102060 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102061 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102062 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102063 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102064 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102065 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102066 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102067 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102068 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102069 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102070 | distributed | private-w0.learn-cosmosdb-postgresql.postgres.database.azure.com payment_events | 102071 | distributed | private-w1.learn-cosmosdb-postgresql.postgres.database.azure.comHerzlichen Glückwunsch! Sie haben mithilfe von Azure Cosmos DB for PostgreSQL erfolgreich eine verteilte Datenbank mit mehreren Knoten erstellt. Mithilfe von Metadatentabellen und Ansichten haben Sie untersucht, wie die Citus-Erweiterung Daten verteilt und zusätzliche Funktionen zu PostgreSQL bereitstellt.
Führen Sie den folgenden Befehl in Cloud Shell aus, um die Verbindung mit der Datenbank zu trennen:
\qSie können Cloud Shell geöffnet lassen und mit der nächsten Lerneinheit fortfahren.