Übung – Arbeiten mit Datendateien in Azure Blob Storage direkt aus Azure Cosmos DB for PostgreSQL
In dieser Übung verwenden Sie die pg_azure_storage-Erweiterung, um Daten aus Dateien zu erfassen, die sicher in einem privaten Container in Azure Blob Storage gespeichert sind.
Wichtig
Diese Übung basiert auf der Datenbank Azure Cosmos DB for PostgreSQL und verteilten Tabellen, die Sie in Lerneinheit 3 erstellt haben.
Erstellen eines Azure Blob Storage-Kontos
Für diese Übung müssen Sie ein Azure Storage-Konto erstellen, seinen Zugriffsschlüssel abrufen, einen Container erstellen und die historischen Datendateien der Woodgrove Bank in den Container kopieren. In dieser Aufgabe erstellen Sie das Speicherkonto.
Öffnen Sie einen Webbrowser, und navigieren Sie zum Azure-Portal.
Wählen Sie Ressource erstellen, Speicher und Speicherkonto aus. Sie können auch die Suchfunktion verwenden, um die Ressource zu finden.
Geben Sie auf der Registerkarte Grundlegende Einstellungen folgende Informationen ein:
Parameter Wert Projektdetails Subscription Wählen Sie Ihr Azure-Abonnement aus. Resource group Wählen Sie die learn-cosmosdb-postgresql-Ressourcengruppe aus, die Sie in der vorherigen Übung erstellt haben.Instanzendetails Speicherkontoname Geben Sie einen global eindeutigen Namen ein, wie z. B. stlearnpostgresql.Region Wählen Sie die gleiche Region aus, die Sie für Ihren Azure Cosmos DB for PostgreSQL-Datenbankcluster ausgewählt haben. Leistung Wählen Sie Standard aus. Redundanz Wählen Sie Lokal redundanter Speicher (LRS) aus. 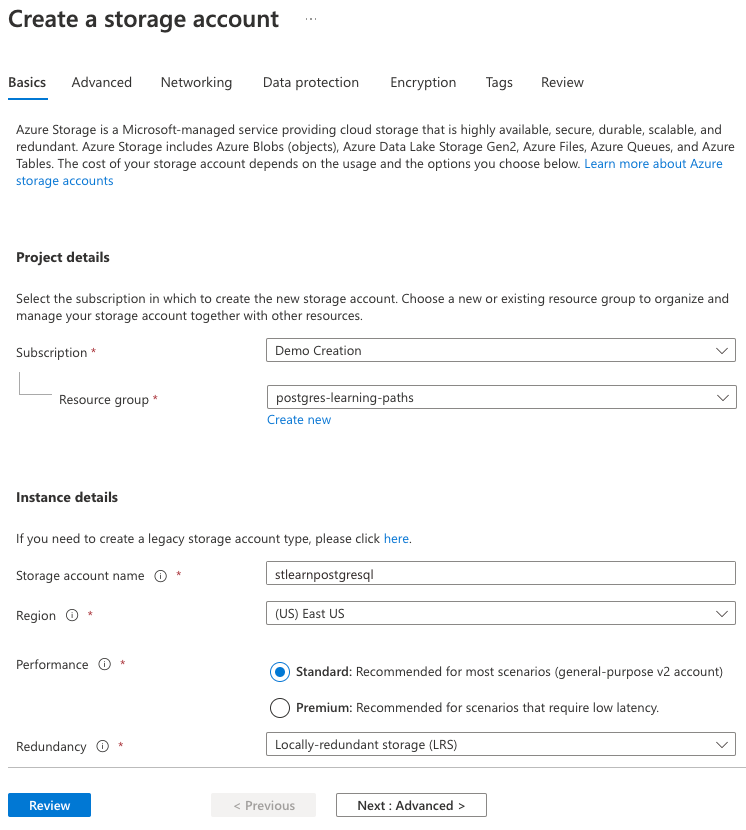
Sie verwenden für die verbleibenden Registerkarten der Konfiguration des Speicherkontos die Standardeinstellungen. Wählen Sie daher die Schaltfläche Überprüfen aus.
Wählen Sie auf der Registerkarte Überprüfen die Schaltfläche Erstellen aus, um das Speicherkonto zu erstellen.
Erstellen eines Blobspeichercontainers und Hochladen von Datendateien
Die Woodgrove Bank hat Ihnen ihre historischen Datendateien im CSV-Format bereitgestellt. Erstellen Sie einen Container namens historical-data im neuen Speicherkonto, und laden Sie diese Dateien dann mithilfe der Azure CLI in ihn hoch.
Navigieren Sie im Azure-Portal zu Ihrem neuen Speicherkonto.
Wählen Sie im linken Navigationsmenü Container unter Datenspeicher aus, und wählen Sie dann auf der Symbolleiste + Container aus.
Geben Sie im Dialogfeld Neuer Container den Namen
historical-dataim Feld Name ein, und lassen Sie Privat (kein anonymer Zugriff) für die Einstellung Öffentliche Zugriffsebene ausgewählt. Wählen Sie dann Erstellen aus.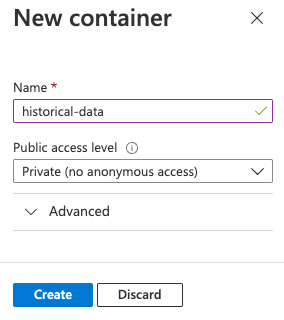
Durch Festlegen der Zugriffsebene des Containers auf Privat (kein anonymer Zugriff) verhindern Sie den öffentlichen Zugriff auf den Container und dessen Inhalte. Unten stellen Sie für die
pg_azure_storage-Erweiterung den Kontonamen und den Zugriffsschlüssel bereit, sodass sie sicher auf die Dateien zugreifen kann.Sie benötigen den Namen und den Schlüssel, der Ihrem Speicherkonto zugeordnet ist, um die Datendateien mithilfe der Azure CLI hochzuladen. Wählen Sie im linken Navigationsmenü Zugriffsschlüssel unter Sicherheit und Netzwerk aus.
Wenn die Seite Zugriffsschlüssel geöffnet ist, wählen Sie das Cloud Shell-Symbol in der Azure-Portal-Symbolleiste aus, um einen neuen Cloud Shell-Bereich unten im Browserfenster zu öffnen.
Führen Sie an der Eingabeaufforderung von Azure Cloud Shell die folgenden
curl-Befehle aus, um die von der Woodgrove Bank bereitgestellten Dateien herunterzuladen.curl -O https://raw.githubusercontent.com/MicrosoftDocs/mslearn-create-connect-postgresHyperscale/main/users.csv curl -O https://raw.githubusercontent.com/MicrosoftDocs/mslearn-create-connect-postgresHyperscale/main/events.csvDie Dateien werden dem Cloud Shell-Speicherkonto hinzugefügt.
Als Nächstes verwenden Sie die Azure CLI, um die Dateien in den
historical-data-Container hochzuladen, den Sie in Ihrem Speicherkonto erstellt haben. Erstellen Sie zunächst Variablen, um Ihren Speicherkontonamen und wichtige Werte zu speichern und die Arbeit so zu vereinfachen.Kopieren Sie den Namen Ihres Speicherkontos, indem Sie die Schaltfläche In Zwischenablage kopieren neben dem Namen des Speicherkontos auf der Seite „Zugriffsschlüssel“ oberhalb Ihrer Cloud Shell auswählen:
Führen Sie nun den folgenden Befehl aus, um eine Variable für den Namen Ihres Speicherkontos zu erstellen, indem Sie das Token
{your_storage_account_name}durch den Namen des Speicherkontos ersetzen:ACCOUNT_NAME={your_storage_account_name}Wählen Sie als Nächstes die Schaltfläche Anzeigen neben dem Schlüssel für key1 aus, und wählen Sie dann die Schaltfläche In Zwischenablage kopieren neben dem Wert des Schlüssels aus.
Führen Sie dann den folgenden Befehl aus, wobei Sie das Token
{your_storage_account_key}durch den von Ihnen kopierten Schlüsselwert ersetzen:ACCOUNT_KEY={your_storage_account_key}Zum Hochladen der Dateien verwenden Sie den Befehl
az storage blob uploadaus der Azure CLI. Führen Sie die folgenden Befehle aus, um die Dateien in den Containerhistorical-dataIhres Speicherkontos hochzuladen:az storage blob upload --account-name $ACCOUNT_NAME --account-key $ACCOUNT_KEY --container-name historical-data --file users.csv --name users.csv --overwrite az storage blob upload --account-name $ACCOUNT_NAME --account-key $ACCOUNT_KEY --container-name historical-data --file events.csv --name events.csv --overwriteIn dieser Übung arbeiten Sie mit ein paar Dateien. In realen Szenarios arbeiten Sie wahrscheinlich mit sehr viel mehr Dateien. Unter diesen Umständen können Sie verschiedene Methoden zum Migrieren von Dateien zu einem Azure Storage-Konto überprüfen und die Methode auswählen, die für Ihre Situation am besten geeignet ist.
Zur Überprüfung, ob die Dateien hochgeladen wurden, können Sie zur Seite Container Ihres Speicherkontos navigieren, indem Sie Container im linken Navigationsmenü auswählen. Wählen Sie den Container
historical-dataaus der Liste der Container aus, und beachten Sie, dass der Container jetzt Dateien namensevents.csvundusers.csventhält.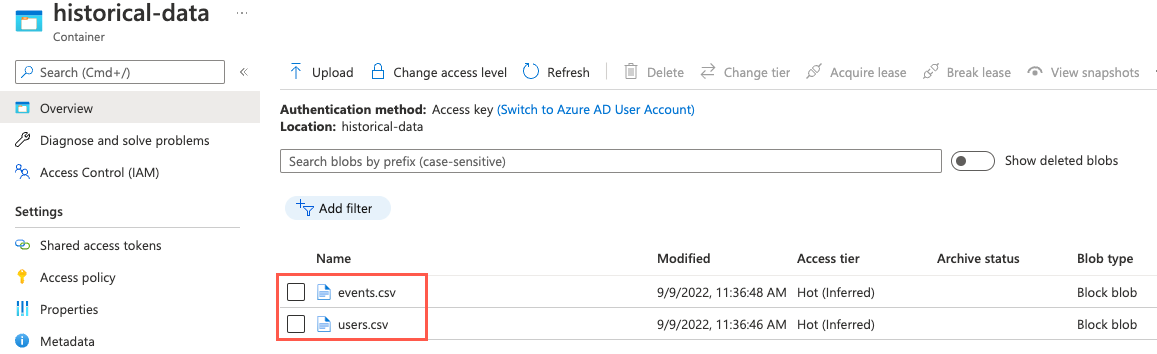
Herstellen einer Verbindung mit der Datenbank mithilfe von psql in Azure Cloud Shell
Nachdem die Dateien nun sicher im Blobspeicher gespeichert sind, ist es an der Zeit, die Erweiterung pg_azure_storage in Ihrer Datenbank einzurichten. Sie verwenden das Befehlszeilenprogramm psql von Azure Cloud Shell, um diese Aufgabe auszuführen.
Navigieren Sie von der Browserregisterkarte, auf der die Cloud Shell geöffnet ist, zu Ihrer Azure Cosmos DB for PostgreSQL-Ressource im Azure-Portal.
Wählen Sie im linken Navigationsmenü der Datenbank unter Einstellungen die Option Verbindungszeichenfolgen aus, und kopieren Sie die Verbindungszeichenfolge mit der Bezeichnung psql.
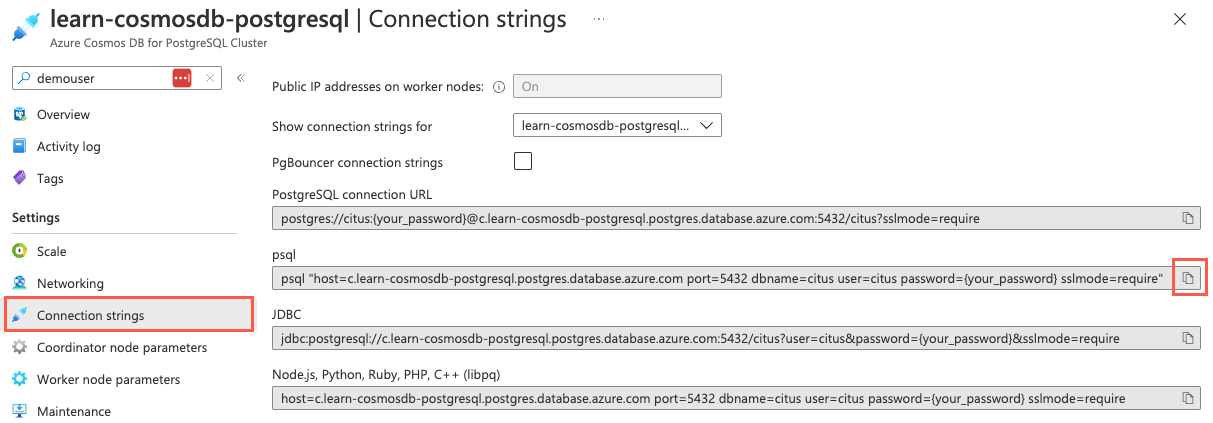
Fügen Sie die Verbindungszeichenfolge in einen Text-Editor ein, wie z. B. Notepad, und ersetzen Sie das Token
{your_password}durch das Kennwort, das Sie dem Benutzer bzw. der Benutzerincitusbei der Clustererstellung zugewiesen haben. Kopieren Sie die aktualisierte Verbindungszeichenfolge für die nachfolgende Verwendung.Stellen Sie in Ihrem geöffneten Cloud Shell-Bereich sicher, dass Bash für die Umgebung ausgewählt ist, und verwenden Sie dann das Befehlszeilenprogramm psql, um eine Verbindung mit Ihrer Datenbank herzustellen. Fügen Sie Ihre aktualisierte Verbindungszeichenfolge (die mit dem richtigen Kennwort) an der Eingabeaufforderung im Cloud Shell-Dienst ein, und führen Sie dann den Befehl aus, der dem folgenden Befehl ähneln sollte:
psql "host=c.learn-cosmosdb-postgresql.postgres.database.azure.com port=5432 dbname=citus user=citus password=P@ssword.123! sslmode=require"
Installieren der Erweiterung „pg_azure_storage“
Nachdem Sie nun mit Ihrer Datenbank verbunden sind, können Sie die Erweiterung pg_azure_storage installieren.
Führen Sie von der Cloud Shell Citus-Eingabeaufforderung aus den folgenden SQL-Befehl aus, um die Erweiterung in Ihre Datenbank zu laden:
SELECT create_extension('azure_storage');Der Name der Erweiterung wird beim Erstellen und Arbeiten mit der Erweiterung in Ihrer Datenbank auf
azure_storageverkürzt.
Gewähren des Zugriffs auf ein Blob Storage-Konto
Der nächste Schritt besteht darin, Ihrem Speicherkonto nach der Installation der Erweiterung pg_azure_storage Zugriff zu gewähren. Erinnern Sie sich daran, dass der Container historical-data mit der Zugriffsebene Privat (kein anonymer Zugriff) erstellt wurde, sodass Sie den Namen und den Schlüssel angeben müssen, der Ihrem Speicherkonto zugeordnet ist, um der Erweiterung den Zugriff auf Dateien im Container zu gewähren.
Navigieren Sie von der Browserregisterkarte, auf der die Cloud Shell geöffnet ist, zu Ihrer Speicherkontoressource im Azure-Portal.
Wählen Sie im linken Navigationsmenü Zugriffsschlüssel unter Sicherheit und Netzwerk aus.
Führen Sie die nachstehende Abfrage aus, um der Erweiterung
pg_azure_storageZugriff auf Ihr Speicherkonto zu gewähren. Ersetzen Sie dafür die Token{storage_account_name}und{storage_account_key}durch Ihre Werte, die Sie von der Seite Zugriffsschlüssel Ihres Speicherkontos kopieren können.SELECT azure_storage.account_add('{storage_account_name}', '{storage_account_key}');Wenn Sie die Liste der Konten anzeigen möchten, die Ihrer Datenbank hinzugefügt wurden, können Sie die
account_list()-Funktion wie folgt verwenden:SELECT azure_storage.account_list();Diese Abfrage stellt die folgende Ausgabe bereit:
account_list ------------------------ (stlearnpostgresql,{})Beachten Sie, dass Sie mithilfe der
account_remove('ACCOUNT_NAME')-Funktion Konten aus der Datenbank entfernen können. Führen Sie diesen Schritt aber hier nicht aus, da Sie das Konto für den Rest der Übung benötigen.
Auflisten von Dateien in einem Blob Storage-Container
Nachdem Sie nun sicher mit dem Speicherkonto verbunden sind, können Sie die blob_list()-Funktion verwenden, um eine Liste der Blobs in einem benannten Container zu erstellen.
Führen Sie die folgende Abfrage aus, um die Dateien im Container
historical-dataanzuzeigen:SELECT path, content_type, pg_size_pretty(bytes) FROM azure_storage.blob_list('stlearnpostgresql', 'historical-data');Die Funktion
blob_list()gibt alle Blobs innerhalb des angegebenen Containers aus:path | content_type | pg_size_pretty ------------+--------------+---------------- events.csv | text/csv | 17 MB users.csv | text/csv | 29 MB
Überprüfen der users.csv-Datei
Bevor Sie versuchen, Daten aus einer beliebigen Datei zu erfassen, müssen Sie die Struktur der Daten innerhalb der Datei verstehen. Die einfachste Möglichkeit, die Struktur zu verstehen, besteht darin, eine Vorschau der Datei im Azure-Portal anzuzeigen, aber dieses Feature ist auf Dateien beschränkt, die kleiner als 2,1 MB sind. Die Ausgabe der blob_list()-Funktion zeigt an, dass die Größe der beiden Dateien, die die Woodgrove Bank bereitgestellt hat, den Grenzwert überschreitet. Sie müssen die Dateien herunterladen und lokal öffnen, um sie zu überprüfen.
Navigieren Sie im Azure-Portal zu Ihrer Speicherkontoressource, wählen Sie im linken Navigationsmenü den Speicherbrowser aus, und wählen Sie dann auf der Seite „Speicherbrowser“ die Option Blobcontainer aus.
Wählen Sie in der Liste der Container historical-data aus.
Wählen Sie die Auslassungspunkte (...) rechts neben der Datei
users.csvaus, und wählen Sie Herunterladen aus dem Kontextmenü aus.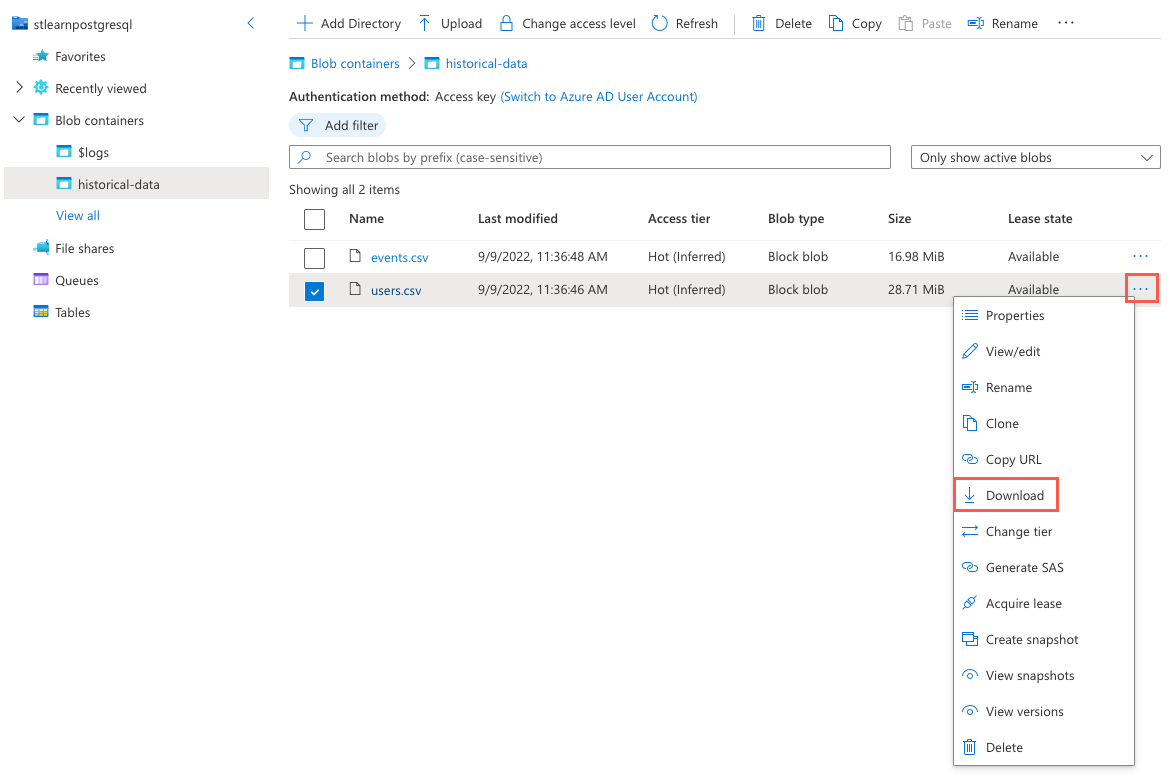
Öffnen Sie nach Abschluss des Downloads die Datei mithilfe von Microsoft Excel oder einem anderen Text-Editor, der CSV-Dateien öffnen kann, und sehen Sie sich die Struktur der Daten in der Datei an, die dem folgenden Beispiel der ersten 10 Zeilen der Datei
users.csvähnelt.user_idurlloginavatar_url21https://api.woodgrove.com/users/technoweenietechnoweeniehttps://avatars.woodgroveusercontent.com/u/21?22https://api.woodgrove.com/users/macournoyermacournoyerhttps://avatars.woodgroveusercontent.com/u/22?38https://api.woodgrove.com/users/atmosatmoshttps://avatars.woodgroveusercontent.com/u/38?45https://api.woodgrove.com/users/mojodnamojodnahttps://avatars.woodgroveusercontent.com/u/45?69https://api.woodgrove.com/users/rsanheimrsanheimhttps://avatars.woodgroveusercontent.com/u/69?78https://api.woodgrove.com/users/indirectindirecthttps://avatars.woodgroveusercontent.com/u/78?81https://api.woodgrove.com/users/engineyardengineyardhttps://avatars.woodgroveusercontent.com/u/81?82https://api.woodgrove.com/users/jsierlesjsierleshttps://avatars.woodgroveusercontent.com/u/82?85https://api.woodgrove.com/users/brixenbrixenhttps://avatars.woodgroveusercontent.com/u/85?87https://api.woodgrove.com/users/tmorninitmorninihttps://avatars.woodgroveusercontent.com/u/87?Beachten Sie, dass die Datei vier Spalten enthält. Die erste Spalte enthält ganzzahlige Werte, und die verbleibenden Spalten enthalten Text. Es ist auch wichtig zu beachten, dass die Datei keine Kopfzeile enthält. Diese Informationen ändern, wie Sie den
COPY-Befehl einrichten, um die Daten der Datei in Ihrer Datenbank zu erfassen.Sie haben die Tabelle
payment_usersin Lektion 3 erstellt. Hier noch einmal die Struktur der Tabelle zur Erinnerung:/* -- Table structure and distribution details provided for reference CREATE TABLE payment_users ( user_id bigint PRIMARY KEY, url text, login text, avatar_url text ); SELECT created_distributed_table('payment_users', 'user_id'); */Basierend auf der beobachteten Struktur der Datei
users.csvscheinen die Daten den Erwartungen zu entsprechen, und Sie sollten die Tabellepayment_usersohne Probleme laden können.
Extrahieren von Daten aus Dateien im Blobspeicher
Nachdem Sie nun die in der Datei enthaltenen Daten verstehen, können Sie die Anforderung der Woodgrove Bank erfüllen, ihre historischen Daten aus Dateien per Massenladen in einem Azure Blob Storage-Konto zu erfassen. Die Erweiterung pg_azure_storage bietet Massenladefunktionen, indem der native PostgreSQL-Befehl COPY so erweitert wird, dass er Azure Blob Storage-Ressourcen-URLs verarbeiten kann. Dieses Feature ist standardmäßig aktiviert und kann mithilfe der Einstellung azure_storage.enable_copy_command verwaltet werden.
Führen Sie mit dem erweiterten
COPY-Befehl den folgenden Befehl aus, um Daten aus der Tabelleusers.csvin der Tabellepayment_userszu erfassen. Achten Sie darauf, das Token{STORAGE_ACCOUNT_NAME}durch den eindeutigen Namen des oben erstellten Speicherkontos zu ersetzen.-- Bulk load data from the user.csv file in Blob Storage into the payment_users table copy payment_users FROM 'https://{STORAGE_ACCOUNT_NAME}.blob.core.windows.net/historical-data/users.csv';Die Ausgabe des
COPY-Befehls gibt die Anzahl der Zeilen an, die in die Tabelle kopiert werden. Das Ergebnis für die Dateiusers.csvsollte angezeigt werden:COPY 264197.Angenommen, die Datei
users.csventhielt eine Kopfzeile. Zur Verarbeitung mit dem BefehlCOPYund der Erweiterungpg_azure_storagemüssen Sie die OptionWITH (header)nach der Ressourcen-URL angeben. Beispielsweisecopy payment_users FROM 'https://{STORAGE_ACCOUNT_NAME}.blob.core.windows.net/historical-data/users.csv' WITH (header);.Führen Sie als Nächstes eine
COUNT-Abfrage in der Tabellepayment_usersaus, um die Anzahl der Datensätze zu überprüfen, die in die Tabelle kopiert wurden:SELECT COUNT(*) FROM payment_users;Die folgenden Ergebnisse sollten angezeigt werden, die dem Ergebnis des Befehls
COPYentsprechen:count -------- 264197Herzlichen Glückwunsch! Sie haben Ihre Azure Cosmos DB for PostgreSQL-Datenbank erfolgreich erweitert und die Erweiterung
pg_azure_storagezur Erfassung von Dateidaten aus einem sicheren Container in Azure Blob Storage in einer verteilten Tabelle verwendet.Führen Sie den folgenden Befehl in Cloud Shell aus, um die Verbindung mit der Datenbank zu trennen:
\q
Bereinigen
Es ist wichtig, dass Sie alle ungenutzten Ressourcen bereinigen. Die Abrechnung basiert auf der konfigurierten Kapazität und nicht auf der Verwendung der Datenbank. Gehen Sie wie folgt vor, um Ihre Ressourcengruppe zusammen mit den Ressourcen zu löschen, die Sie für dieses Modul erstellt haben.
Öffnen Sie einen Webbrowser, und navigieren Sie zum Azure-Portal.
Wählen Sie im Navigationsmenü auf der linken Seite Ressourcengruppen und dann die Ressourcengruppe aus, die Sie im Rahmen der Übung in Lektion 4 erstellt haben.
Wählen Sie im Bereich Übersicht die Option Ressourcengruppe löschen aus.
Geben Sie zur Bestätigung den Namen der Ressourcengruppe ein, die Sie erstellt haben, und wählen Sie dann Löschen aus.
Wählen Sie erneut Löschen aus, um den Löschvorgang zu bestätigen.