Erkunden und Verarbeiten von Daten mit Microsoft Fabric
Daten sind der Eckpfeiler der Data Science, insbesondere bei der Ausbildung eines Machine Learning-Modells zur Erreichung der künstlichen Intelligenz. In der Regel weisen Modelle eine verbesserte Leistung auf, da die Größe des Schulungsdatensatzes zunimmt. Neben der Datenmenge ist die Qualität der Daten gleichermaßen wichtig.
Um sowohl die Qualität als auch die Quantität Ihrer Daten zu gewährleisten, lohnt sich die Verwendung der robusten Datenaufnahme- und Verarbeitungsmodule von Microsoft Fabric. Sie haben die Flexibilität, sich für einen Low-Code- oder Code-first-Ansatz zu entscheiden, wenn Sie die wesentlichen Datenaufnahme-, Explorations- und Transformationspipelines einrichten.
Importieren Sie Ihre Daten in Microsoft Fabric
Um mit Daten in Microsoft Fabric zu arbeiten, müssen Sie zuerst Daten aufnehmen. Sie können Daten aus mehreren Quellen sowohl aus lokalen als auch aus Clouddatenquellen aufnehmen. Sie können beispielsweise Daten aus einer CSV-Datei aufnehmen, die auf Ihrem lokalen Computer oder in einem Azure Data Lake Storage (Gen2) gespeichert ist.
Tipp
Erfahren Sie mehr darüber, wie Sie Daten aus verschiedenen Quellen mit Microsoft Fabric aufnehmen und koordinieren.
Nachdem Sie eine Verbindung mit einer Datenquelle hergestellt haben, können Sie die Daten in einem Microsoft Fabric Lakehouse speichern. Sie können das Seehaus als zentralen Ort verwenden, um strukturierte, halbstrukturierte und unstrukturierte Dateien zu speichern. Sie können sich dann problemlos mit dem Seehaus verbinden, wenn Sie auf Ihre Daten zugreifen möchten, um sie zu erkunden oder zu transformieren.
Erkunden und Transformieren Ihrer Daten
Als Data Scientist können Sie mit dem Schreiben und Ausführen von Code in Notizbüchern am vertrautsten sein. Microsoft Fabric bietet eine vertraute Notizbuchumgebung, die von Spark compute unterstützt wird.
Apache Spark ist ein Open Source Parallel Processing Framework für die umfangreiche Datenverarbeitung und -analyse.
Notizbücher werden automatisch an Spark compute angefügt. Wenn Sie eine Zelle in einem Notebook zum ersten Mal ausführen, wird eine neue Spark-Sitzung gestartet. Die Sitzung wird beibehalten, wenn Sie nachfolgende Zellen ausführen. Die Spark-Sitzung wird nach einiger Zeit der Inaktivität automatisch beendet, um Kosten zu sparen. Sie können die Sitzung auch manuell beenden.
Wenn Sie in einem Notizbuch arbeiten, können Sie die sprache auswählen, die Sie verwenden möchten. Für Data Science-Workloads arbeiten Sie wahrscheinlich mit PySpark (Python) oder SparkR (R).
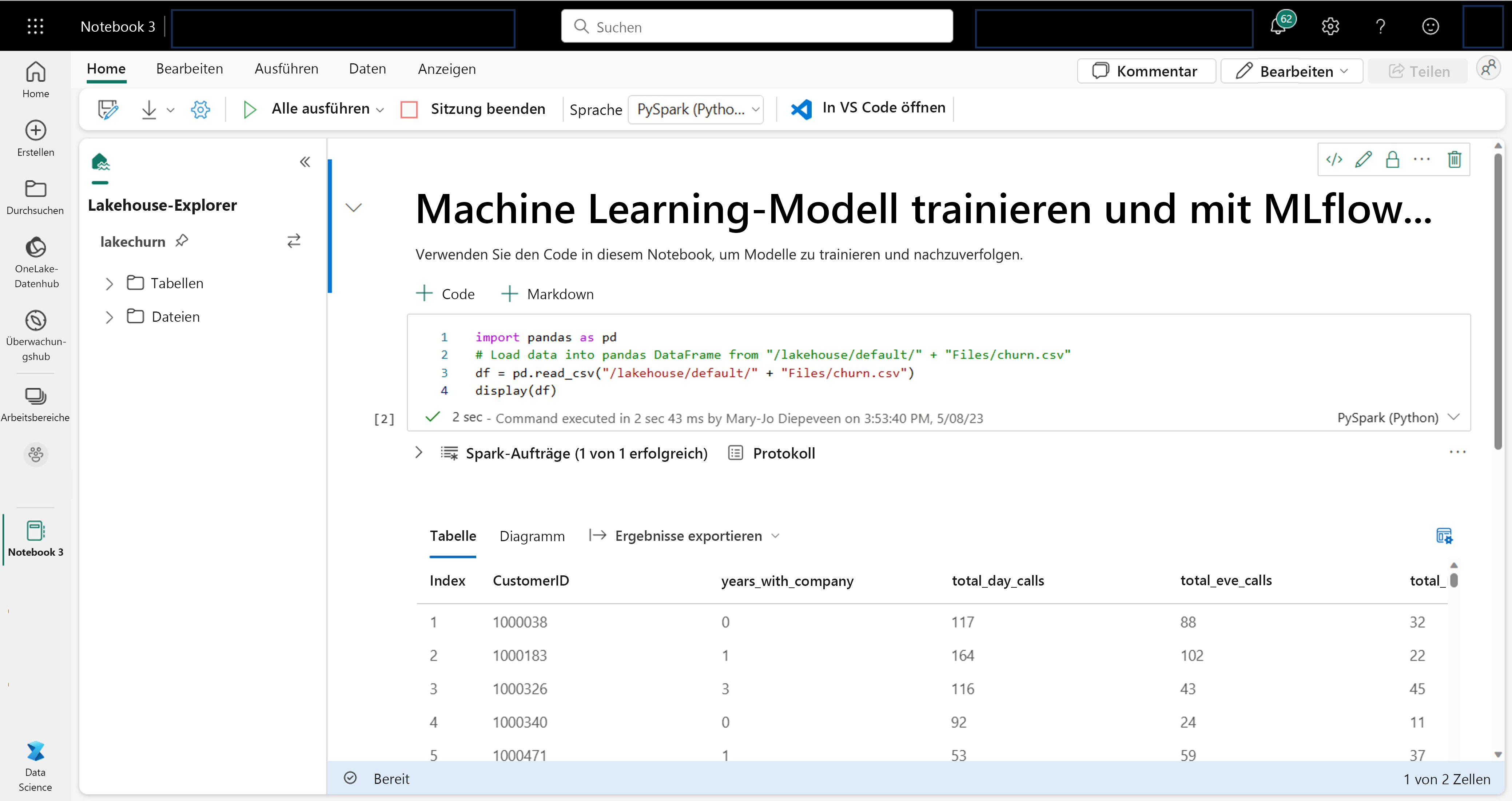
Innerhalb des Notizbuchs können Sie Ihre Daten mithilfe Ihrer bevorzugten Bibliothek oder mit einer der integrierten Visualisierungsoptionen erkunden. Bei Bedarf können Sie Ihre Daten transformieren und die verarbeiteten Daten speichern, indem Sie sie zurück in das Seehaus schreiben.
Vorbereiten Ihrer Daten mit dem Daten-Wrangler
Um Ihre Daten schneller zu untersuchen und zu transformieren, bietet Microsoft Fabric den einfach zu verwendenden Data Wrangler.
Nach dem Starten des Daten-Wranglers erhalten Sie einen beschreibenden Überblick über die Daten, mit der Sie arbeiten. Sie können die Zusammenfassungsstatistiken Ihrer Daten anzeigen, um Probleme wie fehlende Werte zu finden.
Um Ihre Daten zu bereinigen, können Sie einen der integrierten Datenreinigungsvorgänge auswählen. Wenn Sie einen Vorgang auswählen, wird automatisch eine Vorschau des Ergebnisses und der zugeordnete Code generiert. Wenn Sie alle erforderlichen Vorgänge ausgewählt haben, können Sie die Transformationen in Code exportieren und für Ihre Daten ausführen.