Erkunden von Hyperscale-Funktionen
Die Hyperscale-Dienstebene in der Azure SQL-Datenbank ist eine Dienstebene im vCore-basierten Einkaufsmodell , das ideal für Geschäftsworkloads geeignet ist. Es handelt sich um eine hochgradig skalierbare Speicher- und Computeleistungsstufe, die Azure verwendet, um die Speicher- und Computeressourcen für eine Azure SQL-Datenbank erheblich über die Für die Dienstebenen " Allgemeiner Zweck" und " Geschäftskritisch" verfügbaren Grenzwerte zu skalieren. Sie entkoppelt die Abfrageverarbeitungs-Engine von Komponenten für die langfristige Speicherung und ermöglicht eine nahtlose Skalierung von Compute- und Speicherressourcen.
Hyperscale vereinfacht die Infrastruktur und das Anwendungsdesign, sodass Entwickler sich auf geschäftliche Anforderungen konzentrieren können, anstatt Datenbankressourcen zu verwalten.
Azure SQL-Datenbank war bisher auf 4 TB Speicher pro Datenbank beschränkt. Die Hyperscale-Dienstebene ermöglicht es Datenbanken jedoch jetzt, 100 TB zu überschreiten. Hyperscale verwendet die horizontale Skalierung, um bei der Zunahme von daten Computeknoten hinzuzufügen. Die Kosten ähneln denen für die normale Azure SQL-Datenbank-Instanz, es fallen jedoch zusätzliche Speicherkosten pro Terabyte an.
Grundlegendes zu den Vorteilen
Die Dienstebene „Hyperscale“ beseitigt viele praktische Einschränkungen, die in der Regel für Clouddatenbanken gelten. Im Gegensatz zu den meisten anderen Datenbanken, die durch die Ressourcen eines einzelnen Knotens eingeschränkt sind, weisen Hyperscale-Datenbanken keine derartigen Einschränkungen auf. Mit der flexiblen Speicherarchitektur wird der Speicher nach Bedarf erweitert, und es gibt keine vordefinierte maximale Größe. Sie bezahlen nur für die Kapazität, die Sie verwenden. Bei leseintensiven Workloads bietet Hyperscale eine schnelle horizontale Skalierung, indem zusätzliche Replikate zum Auslagern von Lesevorgängen bereitgestellt werden.
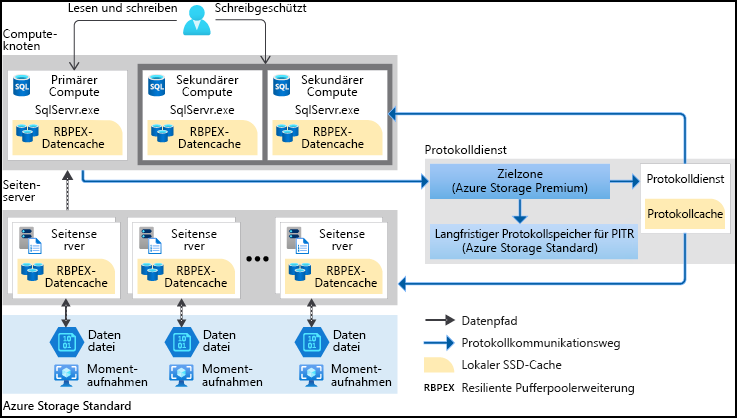
Darüber hinaus ist die Zeit, die zum Erstellen von Datenbanksicherungen oder zum Hoch- bzw. Herunterskalieren erforderlich ist, nicht mehr an die Menge der Daten in der Datenbank gebunden. Hyperscale-Datenbanken können sofort gesichert werden. Außerdem können Sie eine Datenbank in Minutenschnelle in der Größenordnung von zig Terabyte hoch- oder herunterskalieren. Durch diese Funktion müssen Sie nicht befürchten, durch Ihre Auswahl bei der Anfangskonfiguration eingeschränkt zu werden. Hyperscale bietet auch schnelle Datenbankwiederherstellungen, die in Minuten statt in Stunden oder Tagen abgeschlossen werden.
Hyperscale bietet schnelle Skalierbarkeit basierend auf Ihrem Workloadbedarf.
| Feature | Beschreibung | Vorteil | Anwendungsfall |
|---|---|---|---|
| Nach oben/unten skalieren | Sie können die primäre Computegröße im Hinblick auf Ressourcen wie CPU und Arbeitsspeicher in konstanter Zeit hochskalieren und anschließend herunterskalieren. Da der Speicher freigegeben ist, wird die Skalierung nach oben und unten nicht mit dem Datenvolumen in der Datenbank verknüpft. | Sorgt für Flexibilität und Effizienz bei der Ressourcenverwaltung. | Ideal für Anwendungen mit unterschiedlichen Workloads, die unterschiedliche Computeleistungsebenen erfordern. |
| Skalieren/Verkleineren | Sie können auch mehrere Computereplikate bereitstellen, um Ihre Leseanforderungen zu verarbeiten. Diese zusätzlichen Computereplikate fungieren als schreibgeschützte Replikate, um die Leseworkload vom primären Computeknoten auszulagern. Darüber hinaus dienen diese Replikate als unmittelbar betriebsbereite Standbyserver, die übernehmen können, wenn bei der primären Computeressource ein Fehler auftritt. | Verbessert die Leistung und Zuverlässigkeit, indem Leseworkloads ausgelagert und Failoverfunktionen bereitgestellt werden. | Geeignet für leseintensive Anwendungen, die Hochverfügbarkeit und schnelles Failover benötigen. |
Leistungsmaximierung
Die Hyperscale-Dienstebene wurde für Kunden mit großen lokalen SQL Server-Datenbanken entwickelt, die ihre Anwendungen modernisieren möchten, indem Sie in die Cloud wechseln. Sie ist auch ideal für Kunden, die bereits Azure SQL-Datenbank verwenden und Wachstumspotenzial ihrer Datenbanken erheblich erweitern möchten. Darüber hinaus ist Hyperscale perfekt für diejenigen geeignet, die hohe Leistung und hohe Skalierbarkeit suchen.
Zusätzlich zu Features zur schnellen Skalierung bietet Hyperscale die folgenden Leistungsfunktionen:
- Datenbanksicherungen erfolgen unabhängig von der Größe nahezu sofort und ohne Auswirkungen auf Computeressourcen.
- Datenbankwiederherstellungen sind in wenigen Minuten anstelle von Stunden oder Tagen abgeschlossen.
- Die Gesamtleistung wird aufgrund eines höheren Transaktionsprotokolldurchsatzes und kürzerer Transaktionscommitdauer unabhängig von Datenmengen gesteigert.
Hinweis
Informationen zum Bereitstellen einer Hyperscale-Datenbank in Azure SQL-Datenbank finden Sie hier:
Bereitstellen von Hyperscale in Azure SQL-Datenbank
So stellen Sie Azure SQL-Datenbank mit der Hyperscale-Ebene bereit
Melden Sie sich beim Azure-Portal an.
Navigieren Sie zur Azure SQL-Seite , und wählen Sie dann +Erstellen aus.
Wählen Sie SQL-Datenbank, einzelne Datenbank und die Schaltfläche " Erstellen " aus.
Wählen Sie auf der Registerkarte " Grundlagen " auf der Seite " SQL-Datenbank erstellen " das gewünschte Abonnement, die Ressourcengruppe und den Datenbanknamen aus.
Wählen Sie den Link " Neuen Server erstellen" aus, und füllen Sie die neuen Serverinformationen aus, z. B. Servername, Serveradministratoranmeldung und -kennwort sowie Standort.
Wählen Sie unter Compute + Storage den Link "Datenbank konfigurieren" aus.
Wählen Sie Hyperscale für die Dienstebene und bereitgestellt für die Computeebene aus.
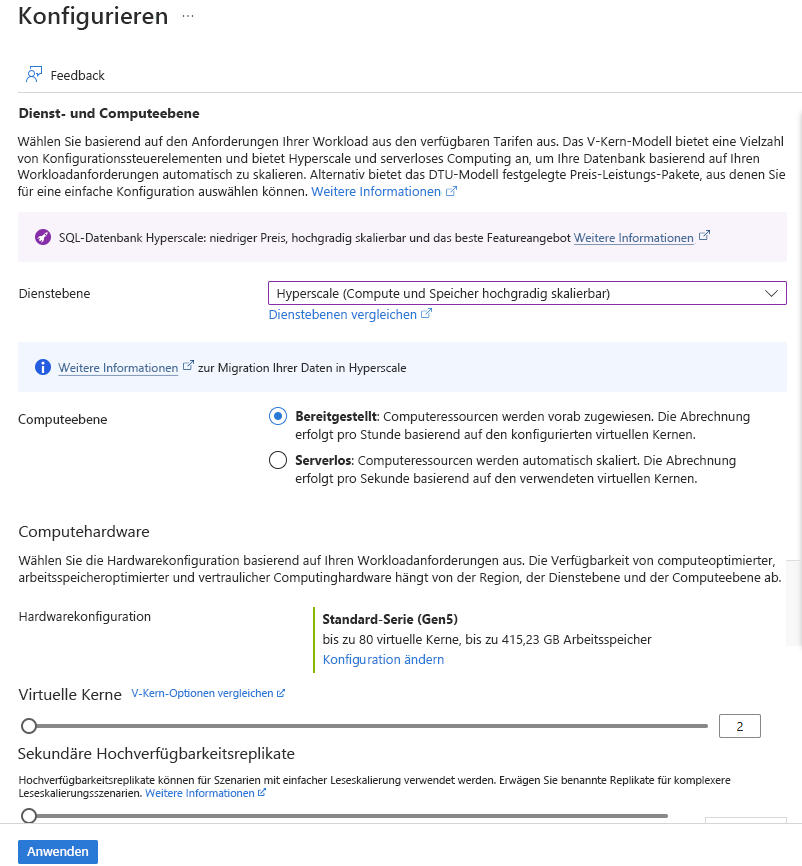
Wählen Sie unter "Hardwarekonfiguration" den Link "Konfigurationsänderung" aus. Überprüfen Sie die verfügbaren Hardwarekonfigurationen, und wählen Sie die am besten geeignete Konfiguration für Ihre Datenbank aus. In diesem Beispiel übernehmen wir die Standardoption Standard-Serie (Gen5).
Passen Sie optional den vCores-Schieberegler an, wenn Sie die Anzahl der vCores für Ihre Datenbank erhöhen möchten.
Passen Sie den Schieberegler fürHigh-Availability sekundäre Replikate an, um ein Replikat zu erstellen. Klicken Sie auf Übernehmen.
Wählen Sie "Weiter" aus: Netzwerk am unteren Rand der Seite.
Legen Sie auf der Registerkarte "Netzwerk " " Aktuelle Client-IP-Adresse hinzufügen " auf "Ja" fest.
Wählen Sie die Schaltfläche "Überprüfen+ Erstellen " und dann " Erstellen" aus.

Hinweis
Nach dem Konvertieren einer Datenbank in Hyperscale ist es nicht möglich, sie wieder auf eine normale Azure SQL-Datenbank-Instanz zurückzusetzen. Weitere Informationen zu Hyperscale-Einschränkungen finden Sie unter bekannten Einschränkungen für die Hyperscale-Dienstebene.
Herstellen einer Verbindung mit einem schreibgeschützten Replikat
Sie können eine Verbindung mit einem schreibgeschützten Replikat herstellen, indem Sie das Argument ApplicationIntent in Ihrer Verbindungszeichenfolge auf ReadOnly festlegen. Verbindungen mit der Anwendungsabsicht ReadOnly werden automatisch an eines der schreibgeschützten Computereplikate weitergeleitet.
Server=tcp:<your_server_name>.database.windows.net,1433;Database=<your_database_name>;User ID=<your_username>@<your_server_name>;Password=<your_password>;Encrypt=true;Connection Timeout=30;ApplicationIntent=ReadOnly;