Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() Azure SQL-Datenbank
Azure SQL-Datenbank
In diesem Artikel wird das einkaufsmodell vCore für Azure SQL-Datenbank überprüft.
Überblick
Ein virtueller Kern (V-Kern) repräsentiert eine logische CPU und bietet Ihnen die Möglichkeit, die physischen Hardwaremerkmale (z. B. Anzahl der Kerne, Arbeitsspeicher und Speichergröße) auszuwählen. Beim vCore-basierten Kaufmodell erhalten Sie Flexibilität, Kontrolle und Transparenz in Bezug auf den individuellen Ressourcenverbrauch. Außerdem können Sie die lokalen Workloadanforderungen leicht auf die Cloud übertragen. Mit diesem Modell wird der Preis optimiert, und Sie können Compute-, Arbeitsspeicher- und Speicherressourcen entsprechend Ihren jeweiligen Workloadanforderungen auswählen.
Im vCore-basierten Kaufmodell hängen Ihre Kosten von der Auswahl und Verwendung der folgenden Elemente ab:
- Dienstebene (Hyperscale, Business Critical oder General Purpose)
- Hardwarekonfiguration
- Computeressourcen (Anzahl von virtuellen Kernen und Arbeitsspeichermenge)
- Reservierter Datenbankspeicher
- Tatsächlicher Sicherungsspeicher
Wichtig
Rechenressourcen, E/A sowie Daten- und Protokollspeicher werden pro Datenbank oder elastischem Pool berechnet. Der Sicherungsspeicher wird pro Datenbank belastet. Details zu den Preisen finden Sie auf der Azure SQL-Datenbank Preisseite.
Vergleich der vCore- und DTU-Einkaufsmodelle
Das von Azure SQL-Datenbank verwendete vCore-Einkaufsmodell bietet mehrere Vorteile gegenüber dem DTU-basierten Einkaufsmodell:
- Höhere Rechen-, Speicher-, E/A- und Speichergrenzwerte.
- Wählen Sie die Hardwarekonfiguration aus, um die Rechen- und Arbeitsspeicheranforderungen der Workload besser abzugleichen.
- Preisrabatte mit dem Azure-Hybridvorteil (AHB).
- Größere Transparenz bei den Hardwaredetails, was die Planung von Migrationen von lokalen Deployments erleichtert.
- Reservierte Instanzenpreise sind nur für das vCore-Einkaufsmodell verfügbar.
- Höhere Skalierungsgranularität mit mehreren verfügbaren Rechengrößen.
Hilfe bei der Auswahl zwischen vCore- und DTU-Einkaufsmodellen finden Sie unter den Unterschieden zwischen den vCore- und DTU-basierten Einkaufsmodellen.
Berechnen
Das vCore-basierte Einkaufsmodell verfügt über eine bereitgestellte Computeebene und eine serverlose Computeebene. In der bereitgestellten Computeebene spiegeln die Rechenkosten die gesamte Computekapazität wider, die kontinuierlich für die Anwendung bereitgestellt wird, unabhängig von der Workloadaktivität. Wählen Sie die Ressourcenzuordnung aus, die ihren Geschäftlichen Anforderungen am besten entspricht, basierend auf vCore- und Speicheranforderungen, und skalieren Sie dann Ressourcen nach Bedarf nach Ihren Arbeitsauslastungen nach oben und unten. Auf der serverlosen Computeebene für Azure SQL-Datenbank werden Computeressourcen automatisch basierend auf der Workloadkapazität skaliert und für die genutzte Computeleistung pro Sekunde in Rechnung gestellt.
Serverlos wird nur auf Hardware der Standardserie (Gen5) unterstützt.
Zusammenfassung:
- Während die bereitgestellte Computeebene eine bestimmte Menge an Rechenressourcen kontinuierlich bereitstellt, die unabhängig von der Workloadaktivität sind, skaliert die serverlose Computeebene automatisch die Rechenressourcen basierend auf der Workloadaktivität.
- Während die bereitgestellte Compute-Ebene für die bereitgestellte Kapazität zu einem festen Preis pro Stunde abgerechnet wird, berechnet die serverlose Compute-Ebene die Kosten nach der Menge der genutzten Rechenleistung pro Sekunde.
Unabhängig von der Computeebene werden automatisch drei zusätzliche sekundäre Replikate für hohe Verfügbarkeit in der Business Critical-Dienstebene zugewiesen, um hohe Resilienz gegen Fehler zu bieten und schnelle Failovers zu ermöglichen. Aufgrund dieser zusätzlichen Replikate sind die Kosten ca. 2,7-mal höher als auf der universellen Dienstebene. Ebenso spiegelt die höheren Speicherkosten pro GB auf der Business Critical-Dienstebene die höheren E/A-Grenzwerte und die geringere Latenz des lokalen SSD-Speichers wider.
In Hyperscale steuern Kunden die Anzahl zusätzlicher Replikate mit hoher Verfügbarkeit von 0 bis 4, um die von ihren Anwendungen erforderliche Resilienzniveau zu erhalten und gleichzeitig Kosten zu steuern.
Weitere Informationen zur Berechnung in Azure SQL-Datenbank finden Sie unter Compute resources (CPU and memory).
Ressourcenbeschränkungen
Überprüfen Sie für vCore-Ressourcenbeschränkungen die verfügbaren Hardwarekonfigurationen, und überprüfen Sie dann die Ressourcengrenzwerte für:
Daten- und Protokollspeicher
Die folgenden Faktoren wirken sich darauf aus, wie viel Speicherplatz für Daten- und Protokolldateien verwendet wird. Dies gilt für die Dienstebenen „Universell“ und „Unternehmenskritisch“.
- Jede Computegröße unterstützt eine konfigurierbare maximale Datengröße mit einem Standardwert von 32 GB.
- Wenn Sie die maximale Datengröße konfigurieren, kommen automatisch 30 Prozent zusätzlicher kostenpflichtiger Speicher für die Protokolldatei hinzu.
- In der Service-Ebene „Generell“ wird für
tempdblokaler SSD-Speicher verwendet, und diese Speicherkosten sind im vCore-Preis enthalten. - In der Dienststufe „Unternehmenskritisch“ wird der lokale SSD-Speicher gemeinsam von Daten- und Protokolldateien genutzt, und die Speicherkosten für
tempdbsind im vCore-Preis enthalten. - In den Ebenen "Allgemeiner Zweck" und "Geschäftskritisch" werden Sie für die maximale Speichergröße belastet, die für eine Datenbank oder einen elastischen Pool konfiguriert ist.
- Für die SQL-Datenbank können Sie eine beliebige maximale Datengröße zwischen 1 GB und der unterstützten Speichergröße in 1-GB-Schritten auswählen.
Die folgenden Speicherüberlegungen gelten für Hyperscale:
- Die maximale Datenspeichergröße ist auf 128 TB festgelegt und kann nicht konfiguriert werden.
- Sie werden nur für den zugewiesenen Datenspeicher belastet, nicht für maximale Datenspeicherung mit mindestens 10 GB.
- Sie werden nicht für den Protokollspeicher belastet.
-
tempdbverwendet lokalen SSD-Speicher, und seine Kosten sind im vCore-Preis enthalten. Wenn Sie die aktuell zugeordnete und verwendete Datenspeichergröße in SQL-Datenbank überwachen möchten, können Sie in Azure Monitor die Metrikallocated_data_storage bzw. storage verwenden.
Um die aktuelle zugewiesene und verwendete Speichergröße einzelner Daten und Protokolldateien in einer Datenbank mithilfe von T-SQL zu überwachen, verwenden Sie die sys.database_files Ansicht und die FILEPROPERTY(... , 'SpaceUsed')- Funktion.
Tipp
Unter bestimmten Umständen müssen Sie ggf. eine Datenbank verkleinern, um ungenutzten Speicherplatz freizugeben. Weitere Informationen finden Sie unter Manage file space in Azure SQL-Datenbank.
Sicherungsspeicher
Speicher für Datenbanksicherungen wird zugewiesen, um die Funktionen für die Point-in-Time-Wiederherstellung (PITR) und die langfristige Aufbewahrung (LONG-Term Retention, LTR) der SQL-Datenbank zu unterstützen. Dieser Speicher ist vom Daten- und Protokolldateispeicher getrennt und wird separat abgerechnet.
- PITR: Bei den Ebenen „Universell“ und „Unternehmenskritisch“ werden einzelne Datenbanksicherungen automatisch in Azure-Speicher kopiert. Die Speichergröße wird dynamisch erhöht, wenn neue Sicherungen erstellt werden. Der Speicher wird für vollständige, differenzielle und Transaktionsprotokollsicherungen verwendet. Der Speicherverbrauch richtet sich nach der Änderungsrate der Datenbank und nach dem für Sicherungen konfigurierten Aufbewahrungszeitraum. Sie können einen separaten Aufbewahrungszeitraum für jede Datenbank zwischen 1 und 35 Tagen für die SQL-Datenbank konfigurieren. Eine Sicherungsspeichermenge, die der konfigurierten maximalen Datengröße entspricht, wird ohne Zusatzkosten bereitgestellt.
- LTR: Sie können auch eine langfristige Aufbewahrung vollständiger Sicherungen für bis zu 10 Jahre konfigurieren. Wenn Sie eine LTR-Richtlinie einrichten, werden diese Sicherungen automatisch in Azure BLOB-Speicher gespeichert, aber Sie können steuern, wie oft die Sicherungen kopiert werden. Zur Einhaltung unterschiedlicher Konformitätsanforderungen können Sie verschiedene Aufbewahrungszeiträume für wöchentliche, monatliche und/oder jährliche Sicherungen auswählen. Die Menge an Speicher, die für LTR-Sicherungen verwendet wird, richtet sich nach der ausgewählten Konfiguration. Weitere Informationen finden Sie unter Langfristiges Aufbewahren von Sicherungen.
Informationen zum Sicherungsspeicher in Hyperscale finden Sie unter Automatisierte Sicherungen für Hyperscale-Datenbanken.
Dienstebenen
Zu den Dienstebenenoptionen im vCore-Einkaufsmodell gehören "General Purpose", "Business Critical" und "Hyperscale". Die Dienstebene bestimmt in der Regel Speichertyp und Leistung, Optionen für hohe Verfügbarkeit und Notfallwiederherstellung sowie die Verfügbarkeit bestimmter Features wie In-Memory OLTP.
| ㅤ | Allgemeiner Zweck | Unternehmenskritisch | Hyperscale- |
|---|---|---|---|
| Am besten geeignet für | Budgetorientierte ausgewogene Berechnungs- und Speicheroptionen. | OLTP-Anwendungen mit hoher Transaktionsrate und geringen Latenzen bei E/A-Vorgängen. Hohe Resilienz gegenüber Fehlern und schnellen Failovers mithilfe mehrerer Hot-Standby-Replikate. | Die empfohlene und standardmäßige Dienstebene für alle neuen und modernisierenden OLTP- und HTAP-Workloads. Am besten geeignet für die größte Vielfalt von Workloads, einschließlich dieser Workloads mit hoch skalierbaren Speicher- und Leseanforderungen. Bietet eine höhere Resilienz gegenüber Fehlern, indem die Konfiguration von mehr als einem sekundären Replikat mit hoher Verfügbarkeit ermöglicht wird. |
| Berechnungsgröße | 2 bis 128 virtuelle Kerne | 2 bis 128 virtuelle Kerne | 2 bis 192 vCores3 |
| Speichertyp | Premium-Fernspeicher (pro Instanz) | Äußerst schneller lokaler SSD-Speicher (pro Instanz) | Entkoppelter Speicher mit lokalem SSD-Cache (pro Computereplikat) |
| Speichergröße | 1 GB - 4 TB | 1 GB - 4 TB | 10 GB – 128 TB |
| Max. IOPS | 320 IOPS pro virtuellem Kern mit maximal 16.000 IOPS | 4.000 IOPS pro virtuellem Kern mit maximal 327.680 IOPS | 5.500 IOPS pro vCore mit maximal 544.000 lokalen SSD-IOPS. Hyperscale ist eine mehrstufige Architektur mit Caching auf mehreren Ebenen. Effektive IOPS sind von der Arbeitsauslastung abhängig. |
| Arbeitsspeicher/vCPU | 5,1 GB | 5,1 GB | 5,1 GB oder 10,2 GB |
| Sicherungen | Auswahl zwischen lokal redundantem Speicher (LRS), zonenredundantem Speicher (ZRS) oder georedundantem Speicher (GRS) Aufbewahrung von 1 bis 35 Tagen (standardmäßig 7 Tage) mit bis zu 10 Jahren langfristiger Aufbewahrung |
Auswahl zwischen lokal redundantem Speicher (LRS), zonenredundantem Speicher (ZRS) oder georedundantem Speicher (GRS) Aufbewahrung von 1 bis 35 Tagen (standardmäßig 7 Tage) mit bis zu 10 Jahren langfristiger Aufbewahrung |
Auswahl zwischen lokal redundantem Speicher (LRS), zonenredundantem Speicher (ZRS) oder georedundantem Speicher (GRS) Aufbewahrung von 1 bis 35 Tagen (standardmäßig 7 Tage) mit bis zu 10 Jahren langfristiger Aufbewahrung |
| Verfügbarkeit | Ein Replikat, keine Leseskalierungsreplikate. Zonenredundante Hochverfügbarkeit | Drei Replikate, ein Leseskalierungsreplikat. Zonenredundante Hochverfügbarkeit | Mehrere Replikate, bis zu 4 Leseskalierungsreplikate. Zonenredundante Hochverfügbarkeit |
| Preise/Abrechnung |
Virtueller Kern, reservierter Speicher und Sicherungsspeicher werden in Rechnung gestellt. IOPS werden nicht in Rechnung gestellt. |
Virtueller Kern, reservierter Speicher und Sicherungsspeicher werden in Rechnung gestellt. IOPS werden nicht in Rechnung gestellt. |
Virtueller Kern für jedes Replikat, belegter Speicher und Sicherungsspeicher werden in Rechnung gestellt. IOPS werden nicht in Rechnung gestellt. |
| Rabattmodelle1 |
Azure-Reservierungen Azure-Hybridvorteil2 Enterprise- und Dev/Test Pay-As-You-Go-Abonnements |
Azure-Reservierungen Azure-Hybridvorteil2 Enterprise- und Dev/Test Pay-As-You-Go-Abonnements |
Da Hyperscale keine SQL-Softwarelizenzgebühr1 hat, ist Azure-Hybridvorteil für neue Hyperscale-Datenbanken2 nicht verfügbar. |
| In-Memory-Tabellen | Nein | Ja | Nein |
1 Vereinfachte Preise für SQL-Datenbank Hyperscale ab Dezember 2023. Ausführlichere Informationen dazu finden Sie im Hyperscale-Preisblog.
2 Ab Dezember 2023 ist Azure-Hybridvorteil nicht für neue Hyperscale-Datenbanken oder in Entwicklungs-/Testabonnements verfügbar. Bestehende Hyperscale Single-Datenbanken mit bereitgestellter Berechnung können Azure-Hybridvorteil weiterhin nutzen, um bis Dezember 2026 Berechungskosten zu sparen. Weitere Informationen finden Sie im Blog zu den Hyperscale Preisen.
3 Derzeit sind die 160- und 192 vCore-Optionen ein Vorschaufeature.
- Weitere Informationen erhalten Sie, wenn Sie Ressourcenbeschränkungen für logische Server, einzelne Datenbanken und poolierte Datenbanken überprüfen.
- Weitere Informationen zum Service Level Agreement (SLA) finden Sie unter SLA für Azure SQL-Datenbank.
Allgemeiner Zweck
Das Architekturmodell für die Dienstebene „Universell“ basiert auf der Trennung von Compute- und Speicherebene. Dieses Architekturmodell basiert auf der hohen Verfügbarkeit und Zuverlässigkeit von Azure Blob-Speicher, die Datenbankdateien transparent repliziert und garantiert keinen Datenverlust, wenn zugrunde liegende Infrastrukturfehler auftreten.
In der folgenden Abbildung sind vier Knoten im Architekturmodell des Typs „Standard“ mit getrennter Compute- und Speicherebene dargestellt.
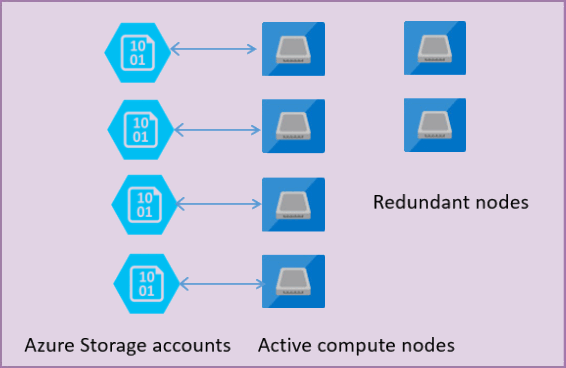
Das Architekturmodell für die Dienstebene „Universell“ umfasst zwei Ebenen:
- Eine zustandslose Computeebene, auf der der Prozess
sqlservr.exeausgeführt wird und die nur temporäre und zwischengespeicherte Daten (z. B. Plancache, Pufferpool, Spaltenspeicherpool) enthält. Dieser zustandslose Knoten wird von Azure Service Fabric betrieben, das den Prozess initialisiert, den Status des Knotens steuert und bei Bedarf einen Failover zu einem anderen Ort durchführt. - Eine zustandsbehaftete Datenebene mit Datenbankdateien (.mdf/.ldf), die in Azure Blob-Speicher gespeichert sind. Azure Blob-Speicher garantiert, dass keine Datensätze verloren gehen, die in einer Datenbankdatei abgelegt werden. Azure Storage verfügt über integrierte Datenverfügbarkeit/Redundanz, die sicherstellt, dass jeder Datensatz in der Protokolldatei oder Seite in der Datendatei beibehalten wird, auch wenn der Prozess abstürzt.
Wenn das Datenbankmodul oder Betriebssystem aktualisiert wird, schlägt ein Teil der zugrunde liegenden Infrastruktur fehl, oder wenn ein kritisches Problem im prozess sqlservr.exe erkannt wird, verschiebt Azure Service Fabric den zustandslosen Prozess auf einen anderen zustandslosen Computeknoten. Es gibt eine Reihe von Ersatzknoten, die auf die Ausführung eines neuen Computediensts warten, wenn ein Failover des primären Knotens erfolgt, um die Failoverzeit zu minimieren. Daten in Azure Speicherebene sind nicht betroffen, und Daten-/Protokolldateien werden an einen neu initialisierten Prozess angefügt. Dieser Prozess stellt standardmäßig eine SLA-Verfügbarkeit der Unternehmensklasse sicher, die bei der Implementierung von Zonenredundanz zunimmt. Aufgrund der Übergangszeit und der Tatsache, dass der neue Knoten mit einem kalten Cache startet, kann es zu Leistungseinbußen bei großen Workloads kommen, die aktuell ausgeführt werden.
Wann man die Dienstebene für allgemeine Zwecke wählen sollte
Die Allzweck-Dienstebene ist die Standarddienstebene in Azure SQL-Datenbank, die für die meisten allgemeinen Arbeitslasten entwickelt wurde. Wenn Sie ein vollständig verwaltetes Datenbankmodul mit einer standardmäßigen SLA- und Speicherlatenz zwischen 5 ms und 10 ms benötigen, ist die Stufe "Allgemein" die Option für Sie.
Geschäftskritisch
Das Dienstebenenmodell des Typs „Unternehmenskritisch“ basiert auf einem Cluster von Datenbank-Engine-Prozessen. Dieses Architekturmodell basiert auf einem Quorum von Datenbankmodulknoten, um die Leistungsauswirkungen auf Ihre Arbeitsauslastung zu minimieren, auch während Wartungsaktivitäten. Upgrades und Patches des zugrunde liegenden Betriebssystems, der Treiber und des Datenbankmoduls erfolgen transparent, mit minimaler Down-Time für Endbenutzer.
Im unternehmenskritischen Modell sind die Berechnung und der Speicher für jeden Knoten integriert. Hochverfügbarkeit wird durch Replikation von Daten zwischen Datenbankmodulprozessen auf jedem Knoten eines Vier-Knoten-Clusters erreicht, wobei jeder Knoten lokal angefügte SSD-Datenträger als Datenspeicher verwendet. Das folgende Diagramm zeigt, wie die Business Critical-Dienstebene einen Cluster von Datenbankmodulknoten in Verfügbarkeitsgruppenreplikaten organisiert.

Sowohl der Datenbankmodulprozess als auch die zugrunde liegenden .mdf/.ldf-Dateien werden auf demselben Knoten mit lokal angefügtem SSD-Speicher platziert und bieten eine geringe Latenz für Ihre Workload. Hohe Verfügbarkeit wird mithilfe von Technologien implementiert, die SQL Server Always On availability groups ähneln. Jede Datenbank ist ein Cluster von Datenbankknoten mit einem primären Replikat, auf das für Kundenarbeitslasten zugegriffen werden kann, und drei sekundäre Replikate, die Kopien von Daten enthalten. Das primäre Replikat überträgt ständig Änderungen an die sekundären Replikate, um sicherzustellen, dass die Daten dort verfügbar sind, falls das primäre Replikat aus irgendeinem Grund ausfällt. Failover wird von Service Fabric und dem Datenbankmodul behandelt – ein sekundäres Replikat wird zum primären Replikat, und es wird ein neues sekundäres Replikat erstellt, um sicherzustellen, dass genügend Knoten im Cluster vorhanden sind. Die Workload wird automatisch an das neue primäre Replikat umgeleitet.
Darüber hinaus umfasst der Cluster des Typs „Unternehmenskritisch“ eine integrierte Funktion Horizontale Leseskalierung, die ein gebührenfreies, integriertes und schreibgeschütztes Replikat bereitstellt, das zum Ausführen von schreibgeschützten Abfragen (z. B. Berichten) verwendet werden kann, die die Leistung des primären Replikats nicht beeinträchtigen.
Wann sollte die Dienstebene "Geschäftskritischer Dienst" ausgewählt werden
Die Business Critical-Dienstebene wurde für Anwendungen entwickelt, die eine geringe Latenz bei den Antwortzeiten vom zugrunde liegenden SSD-Speicher (durchschnittlich 1-2 ms) erfordern, schneller wiederhergestellt werden müssen, wenn die zugrunde liegende Infrastruktur ausfällt, oder Berichte, Analysen und schreibgeschützte Abfragen an das kostenlos lesbare sekundäre Replikat der primären Datenbank auslagern möchten.
Die wichtigsten Gründe dafür, dass Sie die Dienstebene „Unternehmenskritisch“ anstelle der Ebene „Universell“ wählen sollten, sind folgende:
- Geringe I/O-Latenzanforderungen – Workloads, die eine konstant schnelle Reaktion von der Speicherschicht benötigen (durchschnittlich 1–2 Millisekunden), sollten die Business Critical-Schicht verwenden.
- Workloads mit Berichterstellungs- und Analyseabfragen eignen sich, wenn ein kostenloses sekundäres schreibgeschütztes Replikat ausreicht.
- Höhere Resilienz und schnellere Wiederherstellung nach Fehlern. Falls ein Systemfehler auftritt, wird die Datenbank auf der primären Instanz deaktiviert, und eines der sekundären Replikate wird sofort zur neuen primären Lese-/Schreibdatenbank, die für die Verarbeitung von Abfragen bereit ist.
- Höhere Verfügbarkeit: Die Dienstebene „Unternehmenskritisch“ bietet in der Konfiguration mit mehreren Verfügbarkeitszonen Resilienz gegenüber Zonenausfällen und eine SLA mit höherer Verfügbarkeit.
- Schnelle Geowiederherstellung – Wenn die aktive Georeplikation konfiguriert ist, verfügt die Business Critical-Stufe über ein garantiertes Wiederherstellungspunktziel (RPO) von 5 Sekunden und RTO (Recovery Time Objective) von 30 Sekunden für 100% der bereitgestellten Stunden.
Hyperskalierung
Die Dienstebene „Hyperscale“ ist für alle Workloadtypen geeignet. Die cloud-native Architektur bietet unabhängig skalierbare Rechen- und Speicherressourcen, um die unterschiedlichsten traditionellen und modernen Anwendungen zu unterstützen. Auf der Dienstebene „Hyperscale“ sind mehr Compute- und Speicherressourcen als auf den Dienstebenen „Universell“ oder „Unternehmenskritisch“ verfügbar.
Weitere Informationen finden Sie unter Hyperscale-Dienstebene für Azure SQL-Datenbank.
Wann die Hyperscale-Dienstebene ausgewählt werden soll
Die Dienstebene „Hyperscale“ beseitigt viele praktische Einschränkungen, die normalerweise für Clouddatenbanken gelten. Während die meisten anderen Datenbanken durch die auf einem einzelnen Knoten verfügbaren Ressourcen eingeschränkt werden, gelten in der Dienstebene „Hyperscale“ keine solchen Limits. Mit seiner flexiblen Speicherarchitektur wächst eine Hyperscale-Datenbank nach Bedarf – und Sie werden nur für die verwendete Speicherkapazität in Rechnung gestellt.
Neben den erweiterten Skalierungsfunktionen ist Hyperscale eine großartige Option für jede Arbeitsauslastung, nicht nur für große Datenbanken. Mit Hyperscale können Sie:
- Erzielen Sie hohe Resilienz und schnelle Fehlerwiederherstellung bei der Kostenkontrolle, indem Sie die Anzahl der Replikate mit hoher Verfügbarkeit von 0 bis 4 auswählen.
- Verbessern Sie die hohe Verfügbarkeit , indem Sie Zonenredundanz für Compute und Speicher aktivieren.
- Erzielen Sie eine niedrige E/A-Latenz (1-2 Millisekunden im Durchschnitt) für den häufig aufgerufenen Teil Ihrer Datenbank. Bei kleineren Datenbanken kann dies für die gesamte Datenbank gelten.
- Implementieren Sie mit benannten Replikaten eine Vielzahl von Szenarien für die horizontale Leseskalierung.
- Nutzen Sie die schnelle Skalierung, ohne darauf zu warten, dass Daten auf den lokalen Speicher auf neuen Knoten kopiert werden.
- Genießen Sie eine kontinuierliche Datenbanksicherung ohne Beeinträchtigung und schnelle Wiederherstellung.
- Unterstützen Sie Geschäftskontinuitätsanforderungen mithilfe von Failovergruppen und Georeplikation.
Hardwarekonfiguration
Zu den gängigen Hardwarekonfigurationen im vCore-Modell gehören Standardserien (Gen5), Premium-Serie, optimierter Speicher der Premium-Serie und DC-Serie. Hyperscale bietet auch eine Option für (arbeitsspeicheroptimierte) Hardware der Premium-Serie. Die Hardwarekonfiguration definiert Compute- und Speicherbeschränkungen und andere Merkmale, die sich auf die Workloadleistung auswirken.
Bestimmte Hardwarekonfigurationen wie Standardreihen (Gen5) können mehr als einen Prozessortyp (CPU) verwenden, wie in Computeressourcen (CPU und Arbeitsspeicher) beschrieben. Während eine bestimmte Datenbank oder ein bestimmter elastischer Pool für längere Zeit auf der Hardware mit demselben CPU-Typ (häufig für mehrere Monate) verbleibt, gibt es bestimmte Ereignisse, die dazu führen können, dass eine Datenbank oder ein Pool auf die Hardware verschoben wird, die einen anderen CPU-Typ verwendet.
Eine Datenbank oder ein Pool kann für eine Vielzahl von Szenarien verschoben werden, einschließlich, aber nicht beschränkt auf folgendes:
- Das Dienstziel wird geändert.
- Die aktuelle Infrastruktur in einem Rechenzentrum nähert sich kapazitätsgrenzen
- Die aktuell verwendete Hardware wird aufgrund des Endes der Lebensdauer außer Betrieb genommen.
- Die zonenredundante Konfiguration ist aktiviert und wechselt aufgrund der verfügbaren Kapazität zu einer anderen Hardware.
Bei einigen Workloads kann ein Wechsel zu einem anderen CPU-Typ die Leistung ändern. DIE SQL-Datenbank konfiguriert Hardware mit dem Ziel, eine vorhersehbare Workloadleistung bereitzustellen, auch wenn sich der CPU-Typ ändert, um Leistungsänderungen innerhalb eines schmalen Bandes beizubehalten. Im breiten Spektrum der Kundenarbeitsauslastungen in der SQL-Datenbank und wenn neue CPUs-Typen verfügbar sind, ist es gelegentlich möglich, spürbarere Leistungsänderungen zu sehen, wenn eine Datenbank oder ein Pool zu einem anderen CPU-Typ wechselt.
Unabhängig vom verwendeten CPU-Typ bleiben Ressourcenlimits für eine Datenbank oder einen elastischen Pool (z. B. die Anzahl der Kerne, Arbeitsspeicher, max. Daten-IOPS, max. Protokollrate und max. gleichzeitige Mitarbeiter) gleich, solange die Datenbank auf demselben Dienstziel bleibt.
Rechenressourcen (CPU und Arbeitsspeicher)
In der folgenden Tabelle werden Computeressourcen in verschiedenen Hardwarekonfigurationen und Computeebenen für Azure SQL-Datenbank verglichen. Informationen zu Hyperscale finden Sie unter Hyperscale-Dienstebene.
| Hardwarekonfiguration | Zentrale Verarbeitungseinheit (CPU) | Gedächtnis |
|---|---|---|
| Standard-Serie (Gen5) |
Provisioniertes Rechnen - Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)*, AMD EPYC™ 7763v (Milan)*, AMD EPYC 9004 (Genoa)*, Intel® Xeon® Platinum 8573C (Emerald Rapids)* Prozessoren – Bereitstellung von bis zu 128 virtuellen Kernen (mit Hyperthreading) Serverloses Computing - Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 GHz*, Intel® Xeon® Platinum 8370C (Ice Lake)*, AMD EPYC™ 7763v (Milan)*, AMD EPYC 9004 (Genoa)*, Intel® Xeon® Platinum 8573C (Emerald Rapids)* Prozessoren – Autoskalierung auf bis zu 80 virtuelle Kerne (mit Hyperthreading) – Das Verhältnis von Arbeitsspeicher zu virtuellen Kernen passt sich je nach Workloadbedarf dynamisch an die Arbeitsspeicher- und CPU-Auslastung an und kann bis zu 24 GB pro virtuellem Kern betragen. Beispielsweise kann eine Workload zu einem bestimmten Zeitpunkt 240 GB Arbeitsspeicher und nur 10 vCores verwenden und dafür in Rechnung gestellt werden. |
Provisioniertes Rechnen - 5,1 GB pro virtuellem Kern – Bereitstellung von bis zu 625 GB Serverloses Computing - Autoskalierung auf bis zu 24 GB pro virtuellem Kern - Autoskalierung auf bis zu 240 GB |
| DC-Serie | - Intel® Xeon® E-2288G Prozessoren - Verfügt über Intel Software Guard Extension (Intel SGX) – Bereitstellung von bis zu 8 vCores (physisch) |
4,5 GB pro vCore |
| Fsv2-Serie** | - Intel® 8168 (Skylake) Prozessoren - Mit einer anhaltenden Kern-Turbo-Taktgeschwindigkeit von 3,4 GHz und einer maximalen Einzelkern-Turbotaktgeschwindigkeit von 3,7 GHz. – Bereitstellung von bis zu 72 vCores (mit Hyperthreading) |
- 1,9 GB pro vCore - Bereitstellung von bis zu 136 GB |
* Bei einer bestimmten Berechnungsgröße und Hardwarekonfiguration sind Ressourcengrenzwerte unabhängig vom CPU-Typ (Intel® Broadwell, Skylake, Ice Lake, Cascade Lake, Smaragd Rapid oder AMD Mailand, Genoa) identisch. In der dynamischen sys.dm_user_db_resource_governance-Verwaltungsansicht verwendet die Hardwaregenerierung für Datenbanken Folgendes:
- Intel® SP-8160 (Skylake) Prozessoren erscheinen als Gen6
- Intel® 8272CL (Cascade Lake) erscheint als Gen7
- Intel® Xeon® Platinum 8370C (Ice Lake) oder AMD EPYC™ 7763v (Milan) erscheinen als Gen8
- AMD EPYC™ 9004 (Genoa) werden als Gen9 dargestellt oder Intel® Xeon® Platinum 8573C (Emerald Rapids) als Gen10.
Die Fsv2-Serie-Hardware kann nicht mehr erstellt werden und wird am 1. Oktober 2026 eingestellt.
Weitere Informationen zu Ressourcengrenzwerten für einzelne Datenbanken und elastische Pools finden Sie hier.
Standard-Serie (Gen5)
Die Hardware der Standardreihe (Gen5) bietet ausgewogene Rechen- und Speicherressourcen und eignet sich für die meisten Datenbankworkloads.
Standard-Serie (Gen5)-Hardware ist in allen öffentlichen Regionen weltweit verfügbar.
Hyperscale Premium-Serie
Hardwareoptionen der Premium-Serie verwenden die neueste CPU- und Speichertechnologie von Intel und AMD. Premium-Serie bietet eine Steigerung der Rechenleistung im Vergleich zur Standard-Serie-Hardware.
- Die Option Premium-Serie bietet eine schnellere CPU-Leistung im Vergleich zu Standardserien und einer höheren Anzahl von maximalen vCores.
- Die speicherkapazität-optimierte Option der Premium-Serie bietet im Vergleich zur Standardserie doppelt so viel Arbeitsspeicher.
Standardserien-, Premium-Serien- und Premium-Serie optimierter Speicher sind für Hyperscale-elastische Pools verfügbar.
Weitere Informationen finden Sie in der Blogankündigung der Hyperscale Premium-Serie.
Verfügbare Regionen finden Sie unter Verfügbarkeit der Hyperscale Premium-Serie.
DC-Serie
- DC-Serie Hardware verwendet Intel-Prozessoren mit Software Guard Extensions (Intel SGX)-Technologie.
- DC-Serie ist für Always Encrypted mit sicheren Enklaven-Workloads erforderlich, die einen stärkeren Sicherheitsschutz für Hardwareenklaven im Vergleich zu Virtualisierungsbasierten Sicherheitsenklaven (VBS) erfordern.
- DC-Serie wurde für Workloads entwickelt, die vertrauliche Daten verarbeiten und vertrauliche Abfrageverarbeitungsfunktionen erfordern, die von Always Encrypted mit sicheren Enklaven bereitgestellt werden.
- Dc-Series-Hardware bietet ausgewogene Compute- und Speicherressourcen.
Die DC-Serie wird nur für bereitgestellte Computeressourcen (und nicht für „serverlos“) unterstützt. Außerdem unterstützt sie keine Zonenredundanz. Regionen, in denen DC-Serie verfügbar ist, finden Sie unter Verfügbarkeit der DC-Serie.
Azure-Angebotstypen, die von der DC-Serie unterstützt werden
Zum Erstellen von Datenbanken oder Pools für elastische Datenbanken auf Hardware der DC-Serie muss das Abonnement ein kostenpflichtiger Angebotstyp sein, einschließlich nutzungsbasierter Zahlung oder Enterprise Agreement (EA). Eine vollständige Liste der Azure Angebotstypen, die von DC-Serie unterstützt werden, finden Sie unter aktuelle Angebote ohne Ausgabenbeschränkungen.
Hardwarekonfiguration auswählen
Sie können die Hardwarekonfiguration für eine Datenbank oder einen elastischen Pool in der SQL-Datenbank zum Zeitpunkt der Erstellung auswählen. Sie können auch die Hardwarekonfiguration einer vorhandenen Datenbank oder eines elastischen Pools ändern.
So wählen Sie beim Erstellen einer SQL-Datenbank oder eines SQL-Pools eine Hardwarekonfiguration aus
Ausführliche Informationen finden Sie unter Erstellen einer SQL-Datenbank.
Wählen Sie auf der Registerkarte " Grundlagen " den Link " Datenbank konfigurieren" im Abschnitt " Compute + Storage " aus, und wählen Sie dann den Link "Konfigurationsänderung" aus:

Wählen Sie die gewünschte Hardwarekonfiguration aus:

So ändern Sie die Hardwarekonfiguration einer vorhandenen SQL-Datenbank oder eines vorhandenen Pools
Wählen Sie für eine Datenbank auf der Seite "Übersicht" den Link " Preisebene " aus:

Wählen Sie für einen Pool auf der Seite "Übersicht " die Option "Konfigurieren" aus.
Führen Sie die Schritte aus, um die Konfiguration zu ändern, und wählen Sie die Hardwarekonfiguration aus, wie in den vorherigen Schritten beschrieben.
Hardwareverfügbarkeit
Informationen zur Hardwareverfügbarkeit der aktuellen Generation finden Sie unter Feature-Verfügbarkeit nach Region für Azure SQL-Datenbank.
Hardware der vorherigen Generation
Fsv2-Serie
Die Fsv2-Serie-Hardware steht nicht mehr zur Erstellung zur Verfügung und wird am 1. Oktober 2026 eingestellt.
Um Dienstunterbrechungen zu minimieren und die Preisleistung aufrechtzuerhalten, wechseln Sie zu Hyperscale Premium-Serie oder Standard-Serie (Gen5)-Hardware. Weitere Informationen finden Sie unter Einstellungsankündigung: Azure SQL-Datenbank FSV2-Serie. Für die meisten Datenbanken und Workloads bieten Hyperscale Premium-Serie oder Standard-Serie (Gen5)-Hardware ähnliche oder bessere Preisleistung als Fsv2. Um sicherzustellen, überprüfen Sie dies bitte mit Ihrer spezifischen Datenbank und Ihren Workloads.
- Fsv2 bietet weniger Arbeitsspeicher und
tempdbpro vCore als andere Hardware, sodass Workloads, die auf diese Grenzwerte reagieren, bei Standardreihen (Gen5) möglicherweise besser funktionieren. - Fsv2-series wird nur in der Dienstebene „Universell“ unterstützt.
Gen4
Gen4-Hardware wurde eingestellt und steht für Bereitstellung sowie Hoch- oder Herunterskalierung nicht zur Verfügung. Migrieren Sie Ihre Datenbank zu einer unterstützten Hardwaregeneration, um eine größere Bandbreite bei der Skalierbarkeit von virtuellen Kernen und Arbeitsspeicher, beschleunigten Netzwerkbetrieb, optimale E/A-Leistung und minimale Latenz zu erzielen. Überprüfen Sie Hardwareoptionen für einzelne Datenbanken und Hardwareoptionen für elastische Pools. Weitere Informationen finden Sie unter Support wurde für gen 4-Hardware auf Azure SQL-Datenbank beendet.