Auswählen eines Partitionsschlüssels
Denken Sie daran, dass Daten in JSON-Dokumenten in Azure Cosmos DB-Datenbanken innerhalb von Containern gespeichert werden, die wiederum über physische Partitionen verteilt sind und in denen die Daten basierend auf dem Wert eines Partitionsschlüssels an die entsprechende physische Partition weitergeleitet werden.
Der Partitionsschlüssel ist eine erforderliche Dokumenteigenschaft, die sicherstellt, dass Dokumente mit demselben Partitionsschlüsselwert zu einer bestimmten physischen Partition weitergeleitet und dort gespeichert werden. Eine physische Partition unterstützt eine feste maximale Speicher- und Durchsatzmenge (RU/s). Azure Cosmos DB verteilt die logischen Partitionen automatisch auf die verfügbaren physischen Partitionen, wiederum mithilfe des Partitionsschlüsselwerts, sodass eine vorhersehbare Verteilung erfolgt.
In dieser Lerneinheit erfahren Sie mehr über logische Partitionen und darüber, wie Sie heiße Partitionen vermeiden. Diese Informationen helfen bei der Auswahl des geeigneten Partitionsschlüssels für die Kundendaten im vorliegenden Szenario.
In Azure Cosmos DB werden Speicher und Durchsatz erhöht, indem weitere physische Partitionen für den Zugriff auf Daten und das Speichern von Daten hinzugefügt werden. Die maximale Speichergröße einer physischen Partition beträgt 50 GB, und der maximale Durchsatz beträgt 10.000 RU/s.
Logische Partitionen in Azure Cosmos DB
Der Partitionsschlüssel stellt sicher, dass Dokumente mit demselben Partitionsschlüsselwert als zur gleichen logischen Partition gehörend betrachtet und an eine bestimmte physische Partition weitergeleitet und in dieser gespeichert werden. Das Konzept der logischen Partition ermöglicht die Gruppierung von Dokumenten mit demselben Partitionsschlüsselwert. Mehrere logische Partitionen können in einer einzelnen physischen Partition gespeichert werden, und der Container kann eine unbegrenzte Anzahl von logischen Partitionen enthalten. Einzelne logische Partitionen werden als Einheit in neue physische Partitionen verschoben, wenn der Container wächst. Durch das Verschieben logischer Partitionen als Einheit wird sichergestellt, dass sich alle darin enthaltenen Dokumente auf derselben physischen Partition befinden. Die maximale Größe einer logischen Partition beträgt 20 GB. Indem Sie einen Partitionsschlüssel mit hoher Kardinalität verwenden, können Sie diese 20-GB-Grenze umgehen, indem Sie Ihre Daten auf eine größere Anzahl logischer Partitionen verteilen.
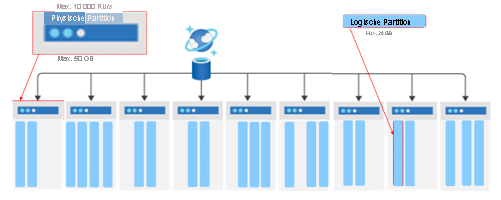
Ein Partitionsschlüssel bietet eine Möglichkeit, Daten für eine logische Partition weiterzuleiten. Der Partitionsschlüssel ist eine Eigenschaft, die in jedem Dokument in dem Container vorhanden ist, über den Daten weitergeleitet werden. Ein Container stellt eine weitere Abstraktion dar und beinhaltet alle Daten, die mit demselben Partitionsschlüssel gespeichert werden. Der Partitionsschlüssel wird definiert, wenn Sie einen Container erstellen.
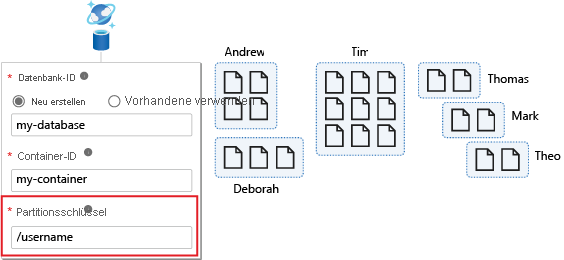
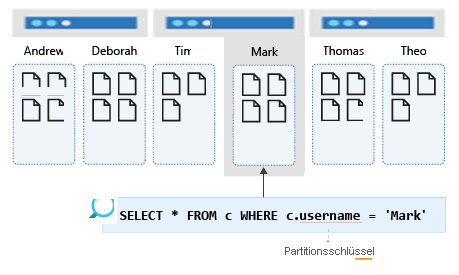
Im folgenden Beispiel verfügt der Container über den Partitionsschlüssel /username .
Vermeiden von heißen Partitionen
Beim Modellieren von Daten für Azure Cosmos DB ist es von entscheidender Bedeutung, dass der von Ihnen ausgewählte Partitionsschlüssel zu einer gleichmäßigen Verteilung der Daten und Anforderungen auf den physischen Partitionen im betreffenden Container führt. Dies gilt insbesondere dann, wenn die Container größer werden und eine zunehmende Anzahl von physischen Partitionen aufweisen.
Wenn Sie den Entwurf Ihrer Datenbank während der Entwicklung nicht unter Last testen, fällt ein schlecht gewählter Partitionsschlüssel möglicherweise erst auf, wenn die Anwendung in der Produktionsumgebung ausgeführt wird und wichtige Daten bereits geschrieben wurden.
Wenn Daten nicht ordnungsgemäß partitioniert werden, können heiße Partitionen auftreten. Heiße Partitionen verhindern, dass Ihre Anwendungsworkload skaliert wird, und sie können sowohl beim Speicher als auch beim Durchsatz auftreten.
Heiße Partitionen im Speicher
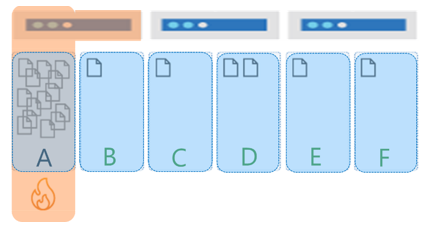
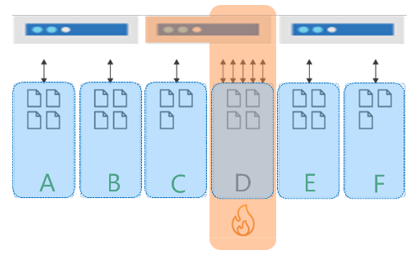
Eine heiße Partition im Speicher tritt auf, wenn Sie über einen Partitionsschlüssel verfügen, der zu hochgradig asymmetrischen Speichermustern führt. Stellen Sie sich beispielsweise eine Anwendung für mehrere Mandanten vor, bei der TenantId als Partitionsschlüssel für sechs Mandanten verwendet wird: A bis F. Die Mandanten B, C, E und F sind sehr klein, Mandant D hat etwas mehr Daten. Mandant A ist jedoch sehr groß und erreicht schnell den Grenzwert von 20 GB für seine Partition. In diesem Szenario müssen wird einen anderen Partitionsschlüssel auswählen, mit dem der Speicher auf mehr logische Partitionen verteilt wird.
Heiße Partitionen beim Durchsatz
Der Durchsatz kann durch heiße Partitionen beeinträchtigt werden, wenn die meisten oder alle Anforderungen an dieselbe logische Partition gehen.
Es ist wichtig, die Zugriffsmuster für die betreffende Anwendung zu verstehen, damit sichergestellt ist, dass Anforderungen so gleichmäßig wie möglich auf Partitionsschlüsselwerte verteilt werden. Beim Bereitstellen des Durchsatzes für einen Container in Azure Cosmos DB wird dieser gleichmäßig allen physischen Partitionen innerhalb eines Containers zugeordnet.
Wenn Sie beispielsweise über einen Container mit 30.000 RU/s verfügen, würde die Workload auf die drei physischen Partitionen für die sechs oben genannten Mandanten verteilt. Jede physische Partition erhält also 10.000 RU/s. Wenn Mandant D alle 10.000 RU/s verbraucht hat, wird die Rate begrenzt, da der den anderen Partitionen zugeordnete Durchsatz nicht verbraucht werden kann. Dies führt zu einer schlechten Leistung für Mandant C und D und zu ungenutzter Computekapazität für die anderen physischen Partitionen und die verbleibenden Mandaten. Letztlich führt dieser Partitionsschlüssel zu einem Datenbankentwurf, bei dem die Workload der Anwendung nicht skaliert werden kann.
Durch die gleichmäßige Verteilung von Daten und Anforderungen wird sichergestellt, dass die Datenbank so wachsen kann, dass sowohl der Speicher als auch der Durchsatz optimal genutzt werden. Dies führt zur bestmöglichen Leistung und zur höchsten Effizienz. Kurz gesagt: Der Datenbankentwurf ist skalierbar.
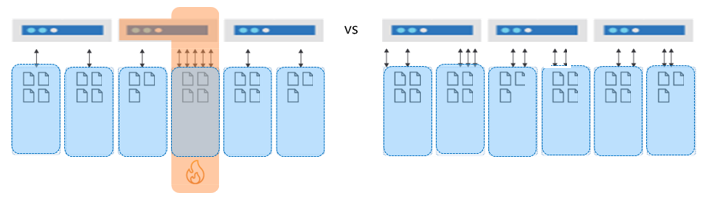
Lese- im Vergleich zu Schreibvorgängen
Wenn Sie einen Partitionsschlüssel auswählen, müssen Sie auch berücksichtigen, ob die Daten eher viele Lese- oder viele Schreibvorgänge erfordern. Bei Anforderungen, die viele Schreibvorgänge erfordern, sollten Sie versuchen, die Daten mit einem Partitionsschlüssel mit hoher Kardinalität zu verteilen.
Bei Workloads mit vielen Lesevorgängen sollten Sie sicherstellen, dass Abfragen von einer oder einer begrenzten Anzahl physischer Partitionen verarbeitet werden, indem Sie eine WHERE-Klausel mit einem Gleichheitsfilter für den Partitionsschlüssel oder einen IN-Operator für eine Teilmenge von Partitionsschlüsselwerten in Ihre Abfragen aufnehmen.
Auch für Szenarios, in denen die Anwendungsworkload sowohl viele Schreib- als auch viele Lesevorgänge erfordert, gibt es eine Lösung. Damit werden wir uns im nächsten Modul beschäftigen.
Die folgende Abbildung zeigt einen Container, der nach Benutzername partitioniert ist. Diese Abfrage wird nur für eine einzige logische Partition ausgeführt, sodass die Leistung immer optimal ist.
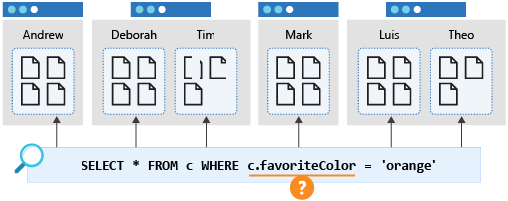
Eine nach einer anderen Eigenschaft wie favoriteColor gefilterte Abfrage würde jedoch auf alle Partitionen im Container ausgedehnt. Dies wird auch als partitionsübergreifende Abfrage bezeichnet. Eine solche Abfrage funktioniert wie erwartet, wenn der Container klein ist und nur eine einzelne Partition belegt. Wenn der Container jedoch wächst und es immer mehr physische Partitionen gibt, wird diese Abfrage langsamer und teurer, da sie jede Partition überprüfen muss, um die Ergebnisse zu erhalten, unabhängig davon, ob die physische Partition Daten enthält, die mit der Abfrage zusammenhängen.
Auswählen des Partitionsschlüssels für Kunden
Jetzt verstehen Sie die Partitionierung in Azure Cosmos DB, und Sie können einen Partitionsschlüssel für die Kundendaten festlegen. Wie bereits erwähnt, werden hier drei Vorgänge für Kunden ausgeführt: Erstellen eines Kunden, Aktualisieren eines Kunden und Abrufen eines Kunden. In diesem Fall wird der Kunde anhand seiner ID abgerufen. Da dieser Vorgang am meisten aufgerufen wird, ist es sinnvoll, die ID des Kunden als Partitionsschlüssel für den Container festzulegen.
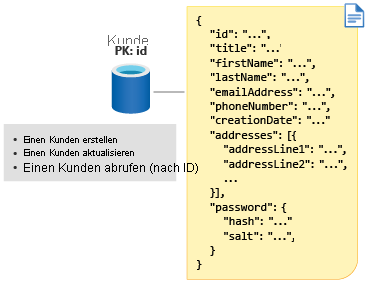
An dieser Stelle könnten Sie befürchten, dass durch die Festlegung der ID als Partitionsschlüssel die Anzahl der entstehenden logischen Partitionen so groß sein wird wie die Anzahl der Kunden und dass dabei jede logische Partition nur ein einziges Dokument enthält. Millionen von Kunden würden zu Millionen von logischen Partitionen führen.
Aber das ist völlig in Ordnung! Logische Partitionen sind ein virtuelles Konzept, und es gibt keine Grenze für die Anzahl der logischen Partitionen, die Sie festlegen können. In Azure Cosmos DB werden mehrere logische Partitionen auf derselben physischen Partition angeordnet. Mit zunehmender Größe oder Anzahl der logischen Partitionen werden diese in Cosmos DB bei Bedarf in neue physische Partitionen verschoben.