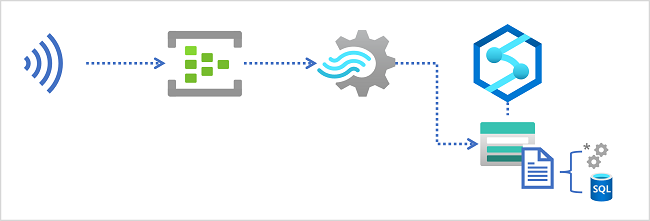
Szenarios für die Datenstromerfassung
Azure Synapse Analytics bietet mehrere Möglichkeiten für die Analyse großer Datenmengen. Dies sind zwei der gängigsten Ansätze für umfangreiche Datenanalysen:
- Data Warehouses: Dies sind relationale Datenbanken, die für verteilten Speicher und die Abfrageverarbeitung optimiert sind. Daten werden in Tabellen gespeichert und mithilfe von SQL abgefragt.
- Data Lakes: Hierbei handelt es sich um verteilten Dateispeicher, in dem Daten als Dateien gespeichert werden, die mit mehreren Runtimes (einschließlich Apache Spark und SQL) verarbeitet und abgefragt werden können.
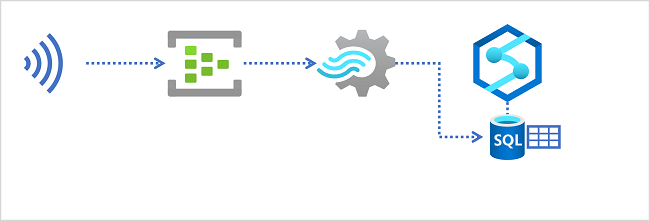
Data Warehouses in Azure Synapse Analytics
Azure Synapse Analytics bietet dedizierte SQL-Pools, mit denen Sie relationale Data Warehouses auf Unternehmensebene implementieren können. Dedizierte SQL-Pools basieren auf einer MPP-Instanz (Massively Parallel Processing) der relationalen Datenbank-Engine von Microsoft SQL Server, in der Daten in Tabellen gespeichert und abgefragt werden.
Um Echtzeitdaten in einem relationalen Data Warehouse zu erfassen, muss Ihre Azure Stream Analytics-Abfrage die Ergebnisse in eine Ausgabe schreiben, die auf die Tabelle verweist, in die Sie die Daten laden möchten.
Data Lakes in Azure Synapse Analytics
Ein Azure Synapse Analytics-Arbeitsbereich enthält in der Regel mindestens einen Speicherdienst, der als Data Lake verwendet wird. Am häufigsten wird der Data Lake in einem Azure Storage-Konto mit einem Container gehostet, der für die Unterstützung von Azure Data Lake Storage Gen2 konfiguriert ist. Dateien im Data Lake sind hierarchisch in Verzeichnissen (Ordnern) organisiert und können in mehreren Dateiformaten gespeichert werden, einschließlich durch Trennzeichen getrenntem Text (z. B. durch Kommas getrennte Werte oder CSV), Parquet und JSON.
Beim Erfassen von Echtzeitdaten in einem Data Lake muss Ihre Azure Stream Analytics-Abfrage die Ergebnisse in eine Ausgabe schreiben, die auf den Speicherort im Azure Data Lake Gen2-Speichercontainer verweist, in dem Sie die Datendateien speichern möchten. Data Analysts, technische Fachkräfte für Daten und wissenschaftliche Fachkräfte für Daten können dann die Dateien im Data Lake verarbeiten und abfragen, indem sie Code in einem Apache Spark-Pool ausführen oder SQL-Abfragen mithilfe eines serverlosen SQL-Pools ausführen.