Entscheidungsstrukturen und Modellarchitektur
Wenn von Architektur die Rede ist, denken wir oft an Gebäude. Die Architektur bestimmt den Aufbau eines Gebäudes: die Höhe, die Tiefe, die Anzahl der Stockwerke und die Art, wie die Elemente im Inneren miteinander verbunden sind. Diese Architektur hat darüber hinaus auch Einfluss auf die Nutzung eines Gebäudes: wo wir es betreten und wie wir davon profitieren.
Beim maschinellen Lernen wird mit der Architektur ein ähnliches Konzept beschrieben. Wie viele Parameter gibt es, und wie werden sie für eine Berechnung miteinander verknüpft? Wird viel parallel berechnet (Breite), oder werden serielle Vorgänge verwendet, die sich auf eine vorherige Berechnung stützen (Tiefe)? Wie können Eingaben für dieses Modell bereitgestellt werden, und wie erhalten wir Ausgaben? Architektonische Entscheidungen wie diese kommen in der Regel nur in komplexeren Modellen vor, wobei die Bandbreite der architektonischen Entscheidungen von einfach bis komplex reichen kann. Entscheidungen wie diese werden in der Regel getroffen, bevor das Modell trainiert wird, obwohl es unter bestimmten Umständen möglich ist, auch nach dem Training noch Änderungen vorzunehmen.
Im Folgenden werden wir dies am Beispiel von Entscheidungsbäumen konkreter untersuchen.
Was ist eine Entscheidungsstruktur?
Eine Entscheidungsstruktur ist im Prinzip ein Flussdiagramm. Entscheidungsstrukturen sind Kategorisierungsmodelle, mit dem Entscheidungen in mehrere Schritte gegliedert werden.
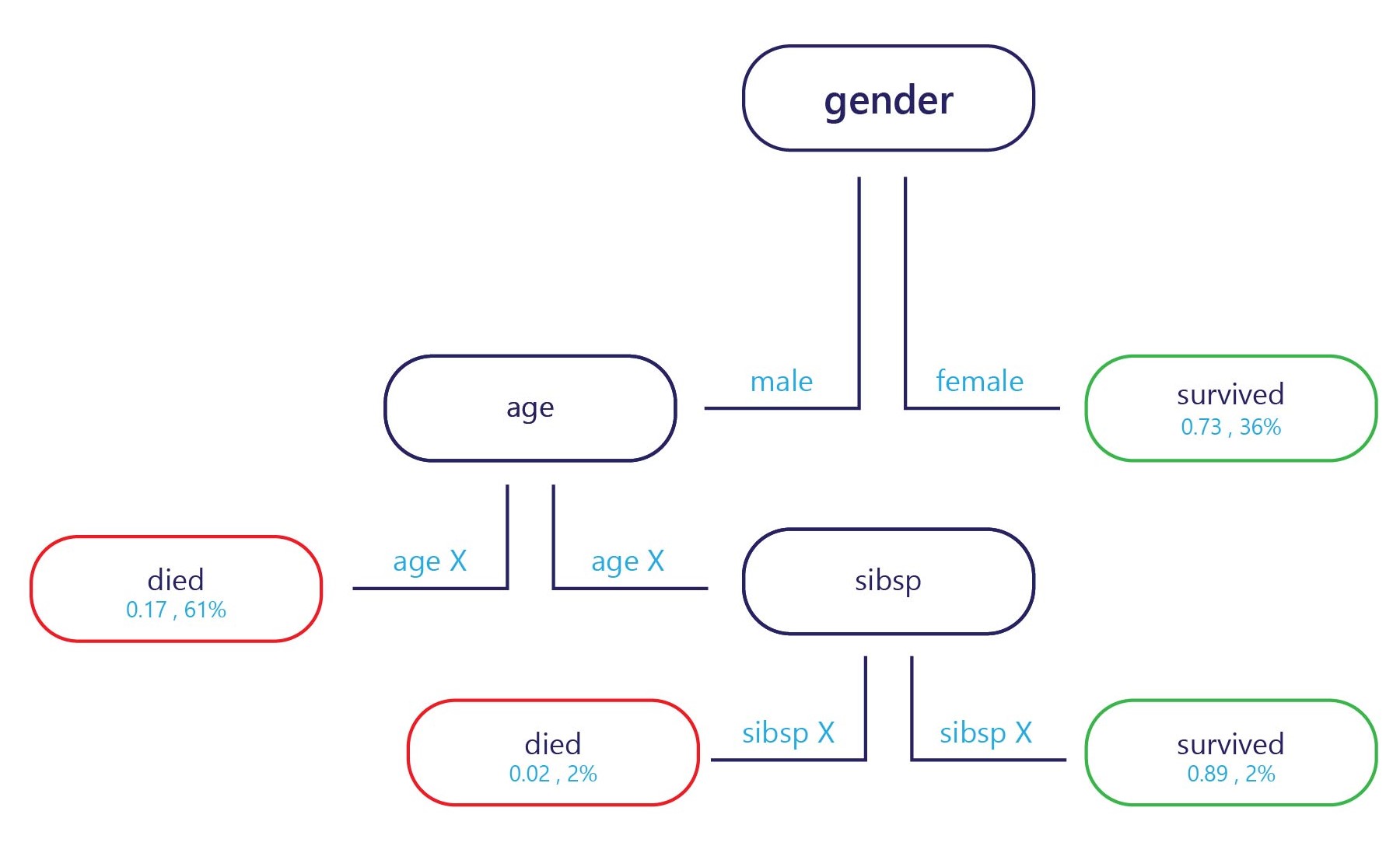
Die Stichprobe, wenn sie am Einstiegspunkt (oben im obigen Diagramm) bereitgestellt wird, und jeder Ausgangspunkt (unten im Diagramm) eine Bezeichnung aufweist. An jedem Knoten wird mit einer einfachen "if"-Anweisung entschieden, über welchen Branch die Stichprobe zum nächsten weitergeleitet wird. Sobald die Verzweigung das Ende der Struktur (Blätter) erreicht hat, wird sie einer Bezeichnung zugewiesen.
Wie werden Entscheidungsstrukturen trainiert?
Entscheidungsstrukturen werden jeweils für einen Knoten oder Entscheidungspunkt trainiert. Am ersten Knoten wird der gesamte Trainingsdatensatz bewertet. Anschließend wird ein Merkmal ausgewählt, mit dem sich die Gruppe in zwei Teilmengen mit homogeneren Bezeichnungen aufteilen lässt. Angenommen, der Trainingsdatensatz lautet wie folgt:
| Gewicht (Merkmal) | Alter (Merkmal) | Medaille gewonnen (Bezeichnung) |
|---|---|---|
| 90 | 18 | Nein |
| 80 | 20 | Nein |
| 70 | 19 | Nein |
| 70 | 25 | Nein |
| 60 | 18 | Ja |
| 80 | 28 | Ja |
| 85 | 26 | Ja |
| 90 | 25 | Ja |
Mit einer einfachen Regel zum Aufteilen dieser Daten können wir etwa bei 24 Jahren nach Alter trennen, weil die meisten Medaillengewinner*innen über 24 Jahre alt waren. Bei dieser Aufteilung würden sich zwei Datenteilmengen ergeben.
Teilmenge 1
| Gewicht (Merkmal) | Alter (Merkmal) | Medaille gewonnen (Bezeichnung) |
|---|---|---|
| 90 | 18 | Nein |
| 80 | 20 | Nein |
| 70 | 19 | Nein |
| 60 | 18 | Ja |
Teilmenge 2
| Gewicht (Merkmal) | Alter (Merkmal) | Medaille gewonnen (Bezeichnung) |
|---|---|---|
| 70 | 25 | Nein |
| 80 | 28 | Ja |
| 85 | 26 | Ja |
| 90 | 25 | Ja |
Wenn wir hier aufhören, besitzen wir ein einfaches Modell mit einem Knoten und zwei Blättern. Blatt 1 enthält die Personen, die keine Medaillen gewonnen haben, und trifft in unserem Trainingsdatensatz auf 75 % zu. Blatt 2 enthält Personen, die eine Medaille gewonnen haben, und trifft in unserem Trainingsdatensatz ebenfalls auf 75 % zu.
Wir müssen hier jedoch nicht aufhören. Wir können diesen Prozess fortsetzen, indem wir die Blätter weiter aufteilen.
In Teilmenge 1 könnte der erste neue Knoten nach Gewicht aufgeteilt werden, da der einzige Medaillengewinner ein geringeres Gewicht hatte als die Personen, die keine Medaille gewonnen haben. Als Regel könnte "Gewicht < 65" festgelegt werden. Personen mit Gewicht < 65 wird vorhergesagt, dass sie eine Medaille gewonnen haben, während Personen mit Gewicht ≥ 65 dieses Kriterium nicht erfüllen und vorhergesagt werden könnte, dass sie keine Medaille gewinnen.
In Teilmenge 2 könnte der neue Knoten ebenfalls nach Gewicht aufgeteilt werden. Dieses Mal wird jedoch vorhergesagt, dass alle Personen mit einem Gewicht über 70 eine Medaille gewinnen würden und Personen mit einem niedrigeren Gewicht dagegen nicht.
Dadurch erhalten wir eine Struktur, mit der für den Trainingsdatensatz eine Genauigkeit von 100 % erzielt werden könnte.
Stärken und Schwächen von Entscheidungsstrukturen
Entscheidungsstrukturen gelten als wenig verzerrend. Das bedeutet, dass sich damit in der Regel Merkmale gut erkennen lassen, die für eine ordnungsgemäße Bezeichnung wichtig sind.
Die größte Schwäche von Entscheidungsstrukturen ist die Überanpassung. Anhand des vorherigen Beispiels ist zu sehen, dass das Modell eine exakte Methode zum Berechnen der Medaillenchancen bereitstellt, mit der sich 100 % des Trainingsdatensatzes richtig vorhersagen lassen. Dieses Maß an Genauigkeit ist ungewöhnlich für Machine Learning-Modelle, durch die normalerweise zahlreiche Fehler im Trainingsdataset verursacht werden. Eine gute Trainingsleistung ist an sich nichts Schlechtes. Die Struktur ist jedoch derart auf den Trainingsdatensatz spezialisiert, dass sie beim Testdatensatz wahrscheinlich nicht gut abschneidet. Das liegt daran, dass von der Struktur Beziehungen im Trainingsdatensatz gelernt wurden, die wahrscheinlich nicht real sind, wie etwa die Aussage, dass eine Person mit einem Gewicht von 60 kg sicher eine Medaille gewinnt, wenn sie unter 25 Jahre alt ist.
Die Modellarchitektur wirkt sich auf die Überanpassung aus
Damit die Schwächen nicht zum Tragen kommen, gilt es, die Entscheidungsstruktur entsprechend aufzubauen. Je tiefer die Struktur, umso größer ist die Wahrscheinlichkeit einer Überanpassung des Trainingssatzes. Wenn wir beispielsweise die oben dargestellte einfache Struktur auf den ersten Knoten beschränken würden, würden im Trainingsdatensatz zwar Fehler auftreten, die Struktur wäre aber wahrscheinlich für den Testdatensatz besser geeignet. Das liegt daran, dass anstelle der sehr spezifischen Regeln, die sich möglicherweise nur auf den Trainingssatz anwenden lassen, allgemeinere Regeln dafür gelten würden, wer eine Medaille gewinnt, z. B. "Sportler über 24".
Obwohl der Fokus hier auf Strukturen liegt, besitzen andere komplexe Modelle häufig ähnliche Schwächen, die durch die Entscheidung darüber, wie die Modelle strukturiert sind oder inwiefern sie durch das Training beeinflusst werden können, verringert werden können.