Übung: Visualisieren des Machine Learning-Modells
Einer der Vorteile bei der Verwendung eines Entscheidungsstrukturklassifizierers ist die Visualisierung, mit deren Hilfe Sie besser verstehen können, wie das Modell Entscheidungen trifft. Mit graphviz und pydotplus können Sie schnell erkennen, wie eine Entscheidung getroffen wird. Bei zukünftigen Iterationen können Sie sehen, wie Entscheidungen geändert werden.
Erstellen der visuellen Struktur
Um eine visuelle Darstellung des Modells zu erstellen, erstellen Sie eine Funktion, die folgende Parameter verwendet:
- Daten:
tree- Das Machine Learning-Modell - Spalten:
feature_names- Eine Liste der Spalten in den Eingabedaten - Ausgabe:
class_names- Eine Liste der Optionen für die Klassifizierung (in diesem Fall „yes“ oder „no“) - Dateiname:
png_file_to_save- Der Name der Datei, in der die Visualisierung gespeichert werden soll
Sie rufen die Funktion export_graphviz() von scikit-learn auf und geben dann eine Bilddarstellung des von scikit-learn bereitgestellten Diagramms zurück.
# Let's import a library for visualizing our decision tree.
from sklearn.tree import export_graphviz
def tree_graph_to_png(tree, feature_names,class_names, png_file_to_save):
tree_str = export_graphviz(tree, feature_names=feature_names, class_names=class_names,
filled=True, out_file=None)
graph = pydotplus.graph_from_dot_data(tree_str)
return Image(graph.create_png())
Das Aufrufen dieser Funktion ist einfach:
- Daten:
tree_model- Das Modell, das Sie zuvor trainiert und getestet haben - Spalten:
X.columns.values- Die Liste der Spalten in der Eingabe - Ausgabe: [
yes,no] - Die beiden möglichen Ergebnisse - Dateiname:
decision_tree.png- Der Name der Datei, in der das Bild gespeichert werden soll
# This function takes a machine learning model and visualizes it.
tree_graph_to_png(tree=tree_model, feature_names=X.columns.values,class_names=['No Launch','Launch'], png_file_to_save='decision-tree.png')
Diese Funktion erstellt das folgende Bild.
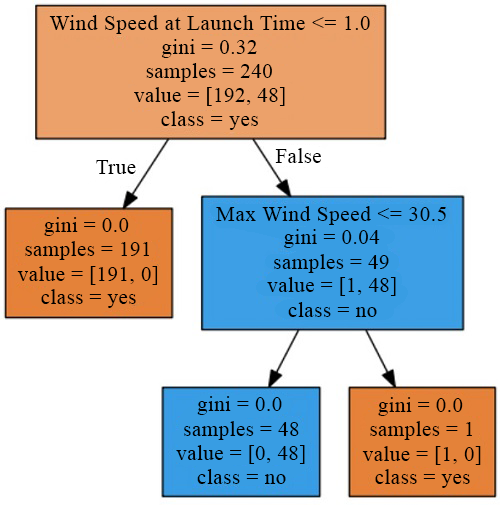
Wenn wir das Dataset anschauen, sehen wir 240 Stichprobenwerte:
- 192 sind Nicht-Starts.
- 48 sind Starts.
Dieses Ergebnis ist auf unsere Datenbereinigungsstrategie zurückzuführen, bei der davon ausgegangen wurde, dass alle nicht gekennzeichneten Tage Nicht-Start-Tage sind.
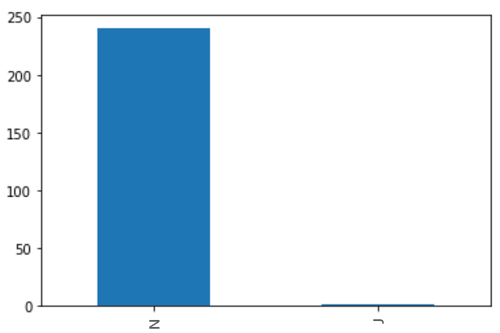
Mit den neuen Bezeichnungen können wir sagen: „Wenn die Windgeschwindigkeit weniger als 1,0 betrug, wurde für 191 der 240 Proben geschätzt, dass an diesem Tag kein Start möglich war.“ Dieses Ergebnis mag merkwürdig erscheinen, ist basierend auf den Daten aber korrekt. Hier ist der Beweis: Wir haben die Verteilung von Starts vs. Nicht-Starts für Tage aufgezeichnet, an denen die Windgeschwindigkeit zur Startzeit <= 1 war, bevor wir zu einem früheren Zeitpunkt diese Spalte in diesem Notebook verworfen haben. Wir sehen, dass es zu fast allen Zeiten zu einem Nicht-Start kam:
Verstehen der Visualisierung
Diese einfache Struktur zeigt, dass die wichtigste Funktion der Daten Wind Speed at Launch Time (d. h. die Windgeschwindigkeit zur Startzeit) war. Wenn die Windgeschwindigkeit kleiner als 1,0 war, wurde für 191 der 240 Stichproben korrekt geschätzt, dass es sich um einen Nicht-Start handelte. Wir sehen, dass bei 191 dieser Stichproben nur der Wert Wind Speed at Launch Time kleiner als 1,0 sein musste, um das Ergebnis richtig zu erraten, während bei Werten über 1,0 weitere Informationen nötig waren.
Diese Erkenntnis ist nicht gut. Wir haben zuvor alle Werte, die leer waren, auf 0 festgelegt. Wir wissen auch, dass viele der Werte, die mit der Startzeit verknüpft waren, 0 betrugen, weil sich 60 % unserer Daten nicht auf einen tatsächlichen oder versuchten Start bezogen.
Wenn Sie sich die Struktur weiter anschauen, sehen Sie, dass Max Wind Speed (d. h. die maximale Windgeschwindigkeit) die zweitwichtigste Funktion der Daten ist. Hier können Sie sehen, dass von den verbleibenden 49 Tagen, an denen die maximale Windgeschwindigkeit weniger als 30,5 betrug, 48 Tage ein korrektes Ergebnis „Start“ ergaben und einer das Ergebnis „Nicht-Start“ aufwies.
Diese Daten sind in einem realen Kontext wohl interessanter. Es gab nur einen Tag, an dem ein Start geplant war und an dem der Wert Max Wind Speed größer war als 30,5: den 27. Mai 2020. Der Start des Space X Dragon wurde in der Folge auf den 30. Mai 2020 verschoben. Dies ist der Beweis:
launch_data[(launch_data['Wind Speed at Launch Time'] > 1) & (launch_data['Max Wind Speed'] > 30.5)]

Verbessern der Ergebnisse
Mithilfe dieser Visualisierung können Sie erkennen, dass einige Merkmale an Bedeutung gewonnen haben. Diese Betonung beruhte jedoch auf falschen Informationen.
Eine mögliche Verbesserung besteht darin, die Beziehung zwischen Max Wind Speed und Wind Speed at Launch Time für die Zeilen zu bestimmen, die diese Information enthalten. Anstatt Wind Speed at Launch Time für Nicht-Start Tage auf 0 festzulegen, hätte es auf den Schätzwert einer gängigen Startzeit festgelegt werden können. Durch diese Änderung wären die Daten möglicherweise besser dargestellt worden.
Haben Sie weitere Ideen, wie sich die Daten verbessern lassen?