Übung: Bereinigen und Vorbereiten der Daten
Bevor Sie ein Dataset vorbereiten können, müssen Sie dessen Inhalt und Struktur verstehen. Im vorherigen Lab haben Sie ein Dataset importiert, das Informationen zu pünktlichen Ankünften einer großen US-amerikanischen Fluggesellschaft enthält. Diese Daten umfassen 26 Spalten und Tausende Zeilen. Dabei steht jede Zeile für einen Flug und enthält Angaben wie den Abflugflughafen, den Zielflughafen und die geplante Abflugzeit. Zudem haben Sie die Daten in ein Jupyter-Notebook geladen und ein einfaches Python-Skript verwendet, um daraus eine Pandas-Datenmatrix zu erstellen.
Eine Datenmatrix ist eine zweidimensionale Datenstruktur mit Bezeichnungen. Die Spalten in einer Datenmatrix können unterschiedliche Typen haben, genauso wie Spalten in einer Tabellenkalkulation oder einer Datentabelle. Eine Datenmatrix ist das am häufigsten verwendete Objekt in Pandas. In dieser Übung sehen Sie sich die Datenmatrix und die darin enthaltenen Daten genauer an.
Wechseln Sie zurück zum Azure-Notebook, das Sie im vorherigen Abschnitt erstellt haben. Wenn Sie das Notebook geschlossen haben, können Sie sich erneut beim Microsoft Azure Notebooks-Portal anmelden, Ihr Notebook öffnen und mit Cell>Run all (Zelle > Alle ausführen) alle Zellen im Notebook nach dem Öffnen erneut ausführen.
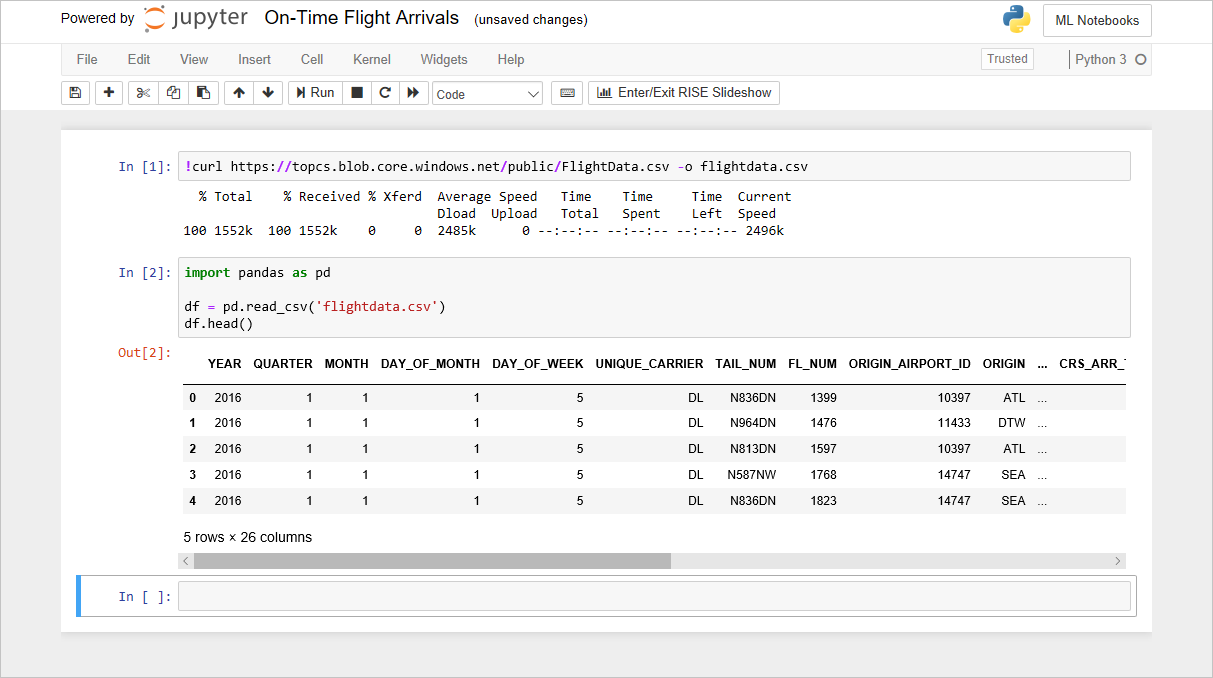
Das FlightData-Notebook
Der Code, den Sie im vorherigen Lab im Notebook eingefügt haben, erstellt eine Datenmatrix aus flightdata.csv und ruft darin DataFrame.head auf, um die ersten fünf Zeilen anzuzeigen. Am Anfang ist es zunächst für Sie interessant, wie viele Zeilen ein Dataset enthält. Geben Sie die folgende Anweisung in eine leere Zeile am Ende des Notebooks ein, und führen Sie diese aus, um die Zeilenanzahl abzurufen:
df.shapeDann sollten Sie sehen, dass die Datenmatrix 11.231 Zeilen und 26 Spalten enthält:

Abrufen der Zeilen- und Spaltenanzahl
Sehen Sie sich dann die 26 Spalten im Dataset an. Sie enthalten wichtige Informationen wie das Datum des Flugs (YEAR, MONTH und DAY_OF_MONTH), den Abflug- und Zielflughafen (ORIGIN und DEST), die geplante Abflug- und Ankunftszeit (CRS_DEP_TIME und CRS_ARR_TIME), die Abweichung zwischen geplanter und tatsächlicher Ankunftszeit in Minuten (ARR_DELAY) und ob der Flug 15 Minuten oder mehr verspätet war (ARR_DEL15).
Unten stehend sehen Sie die vollständige Liste der Spalten im Dataset. Uhrzeiten sind im 24-Stunden-Schema angegeben. Beispielsweise entspricht 1130 11:30 Uhr und 1500 gleich 15:00 Uhr.
Kolumne Beschreibung YEAR Das Jahr des Fluges QUARTER Das Quartal des Fluges (1–4) MONTH Der Monat des Fluges (1–12) DAY_OF_MONTH Der Tag des Monats des Fluges (1–31) DAY_OF_WEEK Der Wochentag des Fluges (1 = Montag, 2 = Dienstag usw.) UNIQUE_CARRIER Code des Betreibers der Fluggesellschaft (z.B. DL) TAIL_NUM Luftfahrzeugkennzeichen FL_NUM Flugnummer Ursprung_Flughafen_ID ID des Abflugflughafens URSPRUNG Code des Abflugflughafens (ATL, DFW, SEA usw.) DEST_AIRPORT_ID ID des Zielflughafens DEST Code des Zielflughafens CRS_DEP_TIME Geplante Abflugzeit DEP_TIME Tatsächliche Abflugzeit DEP_DELAY Verspätung des Abflugs in Minuten DEP_DEL15 0 = Abflug um weniger als 15 Minuten verspätet, 1 = Abflug 15 Minuten oder mehr verspätet CRS_ARR_TIME Geplante Ankunftszeit ARR_TIME Tatsächliche Ankunftszeit ARR_DELAY Verspätung der Ankunft in Minuten ARR_DEL15 0 = Ankunft um weniger als 15 Minuten verspätet, 1 = Ankunft 15 Minuten oder mehr verspätet ABGEBROCHEN 0 = Flug wurde nicht annulliert, 1 = Flug wurde annulliert DIVERTED 0 = Flug wurde nicht umgeleitet, 1 = Flug wurde umgeleitet CRS_ELAPSED_TIME Geplante Flugzeit in Minuten tatsächliche verstrichene Zeit Tatsächliche Flugzeit in Minuten ABSTAND Zurückgelegte Strecke in Meilen
Das Dataset enthält eine ungefähr gleichmäßige Verteilung der Daten im Laufe des Jahres. Dies ist sehr wichtig, da z.B. ein Flug aus Minneapolis im Juli weniger wahrscheinlich aufgrund von Schneestürmen verspätet ist als im Januar. Dieses Dataset ist jedoch noch lange nicht „sauber“ und einsatzbereit. Schreiben wir also nun Pandas-Code, um es zu bereinigen.
Einer der wichtigsten Schritte bei der Vorbereitung eines Datasets für Machine Learning ist das Auswählen von wichtigen Spalten, die für das Ergebnis relevant sind, das Sie vorhersagen möchten. Dabei werden Spalten ausgeblendet, die für das Ergebnis nicht relevant sind, dieses verzerren oder zu Multikollinearität führen könnten. Ein weiterer wichtiger Schritt ist das Vermeiden fehlender Werte, indem Sie entweder die Spalten oder Zeilen löschen, in denen Werte fehlen, oder die fehlenden Werte durch relevante Werte ersetzen. In dieser Übung entfernen Sie irrelevante Spalten und ersetzen fehlende Werte in den restlichen Spalten.
Data Scientists suchen normalerweise als Erstes nach fehlenden Werten. In Pandas können Sie ganz einfach nach fehlenden Werten suchen. Führen Sie dazu den folgenden Code in einer Zelle am Ende des Notebooks aus:
df.isnull().values.any()Achten Sie darauf, dass die Ausgabe „True“ ist. Dies gibt an, dass es mindestens einen fehlenden Wert im Dataset gibt.

Prüfen auf fehlende Werte
Als Nächstes müssen Sie herausfinden, wo sich die fehlenden Werte befinden. Führen Sie dazu den folgenden Code aus:
df.isnull().sum()Dann sollten Sie die folgende Ausgabe mit der Anzahl der fehlenden Werte in jeder Spalte sehen:
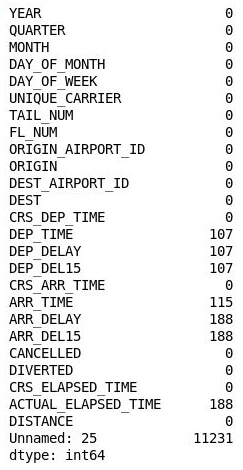
Die Anzahl der fehlenden Werte in jeder Spalte
Überraschenderweise fehlen in Spalte 26 („Unnamed: 25“) 11.231 Werte, was der Anzahl der Zeilen im Dataset entspricht. Diese Spalte wurde versehentlich erstellt, weil die von Ihnen importierte CSV-Datei ein Komma am Ende jeder Zeile enthält. Fügen Sie den folgenden Code im Notebook ein, und führen Sie diesen aus, um die Spalte zu entfernen:
df = df.drop('Unnamed: 25', axis=1) df.isnull().sum()Sehen Sie sich die Ausgabe erneut an, und vergewissern Sie sich, dass Spalte 26 nicht mehr in der Datenmatrix enthalten ist:
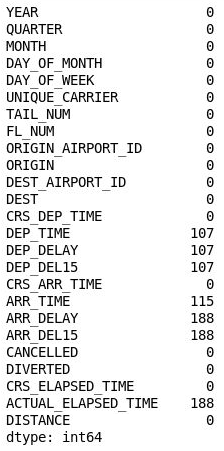
Die Datenmatrix ohne Spalte 26
Es fehlen immer noch viele Werte in der Datenmatrix. Einige sind jedoch nicht wichtig, da die Spalten, in denen sie enthalten sind, für das Modell, das Sie erstellen, nicht relevant sind. Mit dem Modell möchten Sie vorhersagen, ob es wahrscheinlich ist, dass ein Flug, den Sie buchen möchten, pünktlich ist. Wenn Sie herausfinden, dass es sehr wahrscheinlich ist, dass der Flug verspätet ist, können Sie sich für einen anderen Flug entscheiden.
Filtern Sie deshalb als Nächstes das Dataset, um die für das prädiktive Modell irrelevanten Spalten auszublenden. Das Luftfahrzeugkennzeichen ist z.B. für die pünktliche Ankunft eines Fluges unerheblich. Ebenso wissen Sie zum Zeitpunkt der Buchung noch nicht, ob ein Flug annulliert oder umgeleitet werden wird oder verspätet ist. Andererseits ist die geplante Abflugzeit sehr relevant für eine pünktliche Ankunft. Aufgrund der von Fluggesellschaften eingesetzten Speichenarchitektur sind Flüge am Morgen häufiger pünktlich als Flüge am Nachmittag oder Abend. An den großen Flughäfen sammelt sich der Flugverkehr im Laufe des Tages an, sodass es wahrscheinlicher ist, das spätere Flüge verspätet sind.
Mit Pandas können Sie ganz einfach irrelevante Spalten ausblenden. Führen Sie dazu den folgenden Code in einer neuen Zelle am Ende des Notebooks aus:
df = df[["MONTH", "DAY_OF_MONTH", "DAY_OF_WEEK", "ORIGIN", "DEST", "CRS_DEP_TIME", "ARR_DEL15"]] df.isnull().sum()In der Ausgabe sehen Sie, dass die Datenmatrix jetzt nur doch die Spalten enthält, die für das Modell relevant sind, und das die Anzahl der fehlenden Werten deutlich geringer ist.
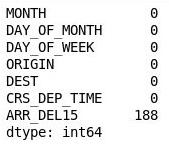
Die gefilterte Datenmatrix
Die einzige Spalte, die noch fehlende Werte enthält, ist die Spalte ARR_DEL15, in der Nullen (0) Flüge angeben, die pünktlich waren, und Einsen (1) Flüge, die verspätet waren. Mit dem folgenden Code können Sie die ersten fünf Zeilen mit fehlenden Werten anzeigen:
df[df.isnull().values.any(axis=1)].head()Pandas gibt fehlende Werte mit
NaNan. Dies steht für Not a Number (Keine Zahl). In der Ausgabe können Sie sehen, dass in diesen Zeilen tatsächlich Werte in der Spalte ARR_DEL15 fehlen: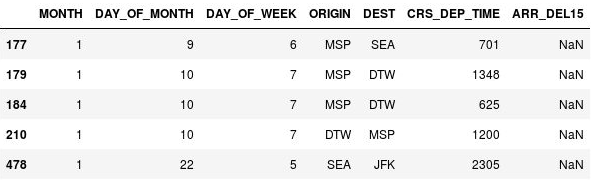
Zeilen mit fehlenden Werten
In diesen Zeilen fehlen Werte für ARR_DEL15, da es sich dabei um Flüge handelt, die annulliert oder umgeleitet wurden. Sie können in der Datenmatrix dropna aufrufen, um diese Zeilen zu entfernen. Da Flüge, die annulliert oder an einen anderen Flughafen umgeleitet wurden, auch als verspätet angesehen werden können, verwenden wir fillna, um die fehlenden Werte durch Einsen (1) zu ersetzen.
Mit dem folgenden Code können Sie fehlende Werte in der Spalte ARR_DEL15 durch Einsen (1) ersetzen und die Zeilen 177 bis 184 anzeigen:
df = df.fillna({'ARR_DEL15': 1}) df.iloc[177:185]Vergewissern Sie sich, dass die
NaNs in den Zeilen 177, 179 und 184 durch Einsen (1) ersetzt wurden, was angibt, dass die Flüge verspätet waren: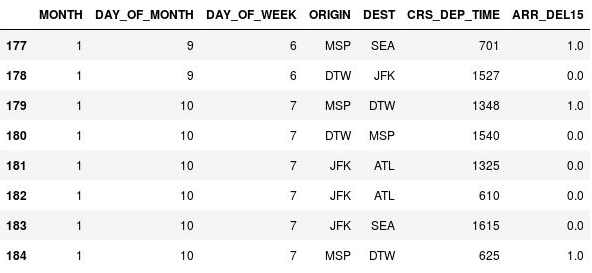
NaNs durch Einsen ersetzt
Jetzt ist das Dataset dahingehend „sauber“, dass es keine fehlenden Werte mehr enthält und die Spalten auf diejenigen eingegrenzt wurden, die für das Modell relevant sind. Das ist jedoch noch nicht alles. Es sind weitere Schritte erforderlich, um das Dataset für Machine Learning verwenden zu können.
Die Spalte CRS_DEP_TIME des Datasets steht für die geplante Abflugzeit. Die Genauigkeit der Zahlen in den Spalten – es gibt mehr als 500 einzigartige Werte – kann sich möglicherweise negativ auf die Treffergenauigkeit (accuracy) eines Machine Learning-Modells auswirken. Dies können Sie durch das sogenannte Binning oder die Quantisierung beheben. Was, wenn Sie jede Zahl in dieser Spalte durch 100 teilen und dann das Ergebnis auf die nächste ganze Zahl abrunden würden? Dann würde aus 1030 10 werden, aus 1925 19 usw., und Sie hätten nur noch maximal 24 unterschiedliche Werte in dieser Spalte. Intuitiv ist das sinnvoll, da es wahrscheinlich nicht wichtig ist, ob ein Flug um 10:30 Uhr oder um 10:40 Uhr startet. Es spielt aber eine große Rolle, ob er um 10:30 Uhr oder um 17:30 Uhr abhebt.
Zusätzlich enthalten die Spalten ORIGIN und DEST Flughafencodes, die für Machine Learning-Kategoriewerte stehen. Diese Spalten müssen in eindeutige Spalten mit Indikatorvariablen konvertiert werden, die auch als „Dummyvariablen“ bezeichnet werden. Anders gesagt: Die Spalte ORIGIN, die fünf Flughafencodes enthält, muss in fünf separate Spalten konvertiert werden, eine für jeden Flughafen. Jede Spalte enthält dann Einsen (1) und Nullen (0), die angeben, ob ein Flug von dem Flughafen gestartet ist, für den die Spalte steht. Für die Spalte DEST können Sie ähnlich vorgehen.
In dieser Übung quantifiziere Sie die Abflugzeiten in der Spalte CRS_DEP_TIME und verwenden die Pandas-Methode get_dummies, um aus den Spalten ORIGIN und DEST Indikatorspalten zu erstellen.
Mit dem folgenden Befehl können Sie die ersten fünf Zeilen in der Datenmatrix anzeigen:
df.head()Sie sehen, dass die Spalte CRS_DEP_TIME Werte von 0 bis 2359 enthält, die für das 24-Stunden-Schema stehen.
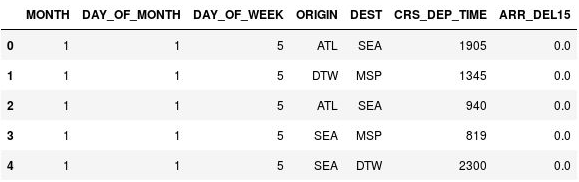
Die Datenmatrix mit nicht quantifizierten Abflugzeiten
Mit den folgenden Anweisungen können Sie die Abflugzeiten quantifizieren:
import math for index, row in df.iterrows(): df.loc[index, 'CRS_DEP_TIME'] = math.floor(row['CRS_DEP_TIME'] / 100) df.head()Vergewissern Sie sich, dass die Zahlen in der Spalte CRS_DEP_TIME jetzt zwischen 0 und 23 liegen:
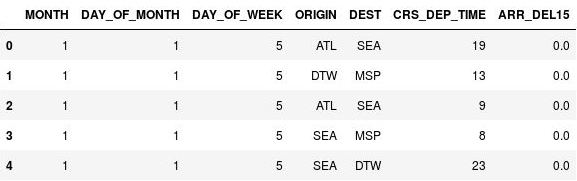
Die Datenmatrix mit quantifizierten Abflugzeiten
Jetzt können Sie mit den folgenden Anweisungen aus den Spalten ORIGIN und DEST Indikatorspalten generieren und die Spalten ORIGIN und DEST entfernen:
df = pd.get_dummies(df, columns=['ORIGIN', 'DEST']) df.head()Sehen Sie sich die daraus entstehende Datenmatrix an. Die Spalten ORIGIN und DEST wurden durch Spalten ersetzt, die den jeweiligen Flughafencodes in den ursprünglichen Spalten entsprechen. Die neuen Spalten enthalten Einsen (1) und Nullen (0), die angeben, ob ein gegebener Flug von einem Flughafen abgeflogen ist bzw. einen Flughafen als Ziel hatte.
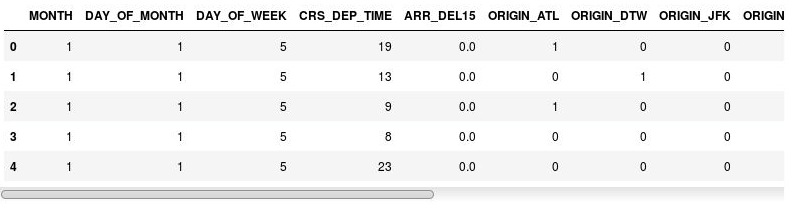
Die Datenmatrix mit Indikatorspalten
Verwenden Sie den Befehl File>Save and Checkpoint (Datei > Speichern und Prüfpunkt), um das Notebook zu speichern.
Das Dataset sieht nun ganz anders als am Anfang aus. Es ist jetzt für Machine Learning optimiert.