Übung: Erstellen des Machine Learning-Modells
Sie benötigen zwei Dataset, um ein Machine Learning-Modell zu erstellen: ein Trainingsdataset und ein Testdataset. In der Realität verfügen Sie oft nur über ein Dataset, das Sie dann in zwei Datasets aufteilen. In dieser Übung teilen Sie die Datenmatrix, die Sie im vorherigen Lab vorbereitet haben, 80 zu 20 auf, um damit ein Machine Learning-Modell zu trainieren. Außerdem teilen Sie die Datenmatrix in verwendete und vorherzusagende Spalten ein. Erstere enthalten die Eingabe für das Modell (z.B. der Abflug- und Zielflughafen des Fluges und die geplante Abflugzeit), und Letztere enthalten die Spalte, die das Modell vorhersagen soll – in unserem Fall die Spalte ARR_DEL15, die angibt, ob ein Flug pünktlich sein wird.
Wechseln Sie zurück zum Azure-Notebook, das Sie im vorherigen Abschnitt erstellt haben. Wenn Sie das Notebook geschlossen haben, können Sie sich erneut beim Microsoft Azure Notebooks-Portal anmelden, Ihr Notebook öffnen und mit Cell>Run all (Zelle > Alle ausführen) alle Zellen im Notebook nach dem Öffnen erneut ausführen.
Führen Sie dazu den folgenden Code in einer neuen Zelle am Ende des Notebooks aus:
from sklearn.model_selection import train_test_split train_x, test_x, train_y, test_y = train_test_split(df.drop('ARR_DEL15', axis=1), df['ARR_DEL15'], test_size=0.2, random_state=42)Durch die erste Anweisung wird die Hilfsfunktion train_test_split von Scikit-learn importiert. In der zweiten Zeile wird die Funktion verwendet, um die Datenmatrix in ein Trainingsdataset mit 80 % der ursprünglichen Daten und ein Testdataset mit den restlichen 20 % der Daten aufzuteilen. Der Parameter
random_statefügt durch Seeding einen Generator für zufällige Zahlen ein, der zum Aufteilen verwendet wird, und der erste und zweite Parameter sind Datenmatrizen, die die verwendeten Spalten und die zu bezeichnende Spalte enthalten.train_test_splitgibt vier Datenmatrizen zurück. Mit dem folgenden Befehl können Sie die Anzahl der Zeilen und Spalten in der Datenmatrix anzeigen, die die zum Trainieren verwendeten Spalten enthält:train_x.shapeVerwenden Sie den folgenden Befehl, um die Anzahl der Zeilen und Spalten in der Datenmatrix anzeigen, die die zum Testen verwendeten Spalten enthält:
test_x.shapeWie und warum unterscheiden sich die beiden Ausgaben?
Wissen Sie, was passiert, wenn Sie shape für die anderen beiden Datenmatrizen, train_y und test_y, aufrufen? Wenn Sie sich nicht sicher sind, können Sie es einfach ausprobieren und herausfinden.
Es gibt viele verschiedene Arten von Machine Learning-Modellen. Eines der häufigsten Modelle ist das Regressionsmodell, bei dem einer von mehreren Regressionsalgorithmen verwendet wird, um einen numerischen Wert zu erzeugen, z.B. das Alter einer Person oder die Wahrscheinlichkeit der betrügerischen Natur einer Kreditkartentransaktion. Sie werden ein Klassifizierungsmodells trainieren, das mehrere Eingaben in eine bekannte Ausgabe auflösen soll. Ein klassisches Beispiel für ein Klassifizierungsmodell ist ein Modell, das E-Mails untersucht und sie als „Spam“ oder „kein Spam“ klassifiziert. Ihr Modell ist ein binäres Klassifizierungsmodell, das vorhersagt, ob ein Flug pünktlich oder verspätet eintrifft („binär“, da es nur zwei mögliche Ausgaben gibt).
Einer der Vorteile von Scikit-learn ist die Tatsache, dass Sie diese Modelle nicht von Hand erstellen und die Algorithmen, die sie verwenden, nicht selbst implementieren müssen. Scikit-learn enthält unterschiedliche Klassen zum Implementieren gängiger Machine Learning-Modelle. Eine dieser Klassen ist RandomForestClassifier, die mehrere Entscheidungsstrukturen an die Daten anpasst und die Durchschnittsberechnung verwendet, um die Treffergenauigkeit zu erhöhen und die Überanpassung zu minimieren.
Führen Sie den folgenden Code in einer neuen Zelle aus, um ein
RandomForestClassifier-Objekt zu erstellen, und trainieren Sie dieses durch einen Aufruf der fit-Methode.from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(random_state=13) model.fit(train_x, train_y)In der Ausgabe sehen Sie die Parameter, die im Klassifizierer verwendet werde, u.a. auch
n_estimators, das die Anzahl der Strukturen in jedem Entscheidungswald angibt, undmax_depth, das die maximale Tiefe einer Entscheidungsstruktur angibt. Die angegebenen Werte sind die Standardwerte, aber Sie können diese überschreiben, wenn Sie dasRandomForestClassifier-Objekt erstellen.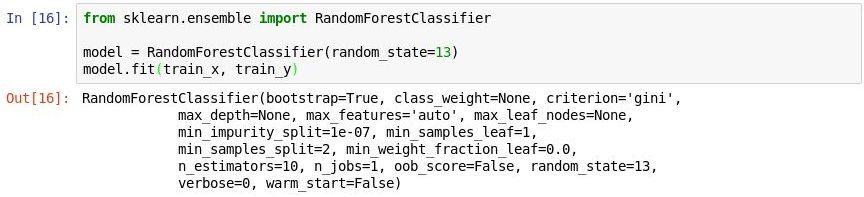
Trainieren des Modells
Rufen Sie die predict-Methode auf, um das Modell mit den Werten in
test_xzu testen. Rufen Sie danach die score-Methode auf, um die durchschnittliche Treffergenauigkeit des Modells zu bestimmen:predicted = model.predict(test_x) model.score(test_x, test_y)Dann sollten Sie die folgende Ausgabe sehen:

Testen des Modells
Die durchschnittliche Treffergenauigkeit beträgt 86 %, was auf den ersten Blick gut aussieht. Die durchschnittliche Treffergenauigkeit ist aber nicht immer ein zuverlässiger Indikator für die Genauigkeit eines Klassifizierungsmodells. Sehen wir uns das genauer an, um zu bestimmen, wie genau das Modell wirklich ist – wie gut es also vorhersagen kann, ob ein Flug pünktlich ankommt.
Es gibt mehrere Möglichkeiten, die Treffergenauigkeit eines Klassifizierungsmodells zu messen. Einer der besten Ansätze zum Messen der Genauigkeit eines Klassifizierungsmodells ist die „Area under Curve“der Receiver-Operating-Characteristic-Kurve, die Fläche unterhalb der Kurve (kurz auch ROC AUC), die einfach gesagt angibt, wie oft ein Modell eine korrekte Vorhersage machen wird, unabhängig vom Ergebnis. In dieser Lerneinheit berechnen Sie eine ROC-AUC-Bewertung für das Modell, das Sie erstellt haben, und erfahren, weshalb diese Bewertung geringer als die berechnete durchschnittliche Treffergenauigkeit der score-Methode ist. Außerdem lernen Sie andere Ansätze zum Messen der Treffergenauigkeit des Modells kennen.
Bevor Sie die ROC AUC berechnen, müssen Sie für das Testdataset Wahrscheinlichkeiten für die Vorhersage generieren. Diese Wahrscheinlichkeiten sind Schätzungen für jede Klasse oder Antwort, die das Modell vorhersagen kann.
[0.88199435, 0.11800565]bedeutet z.B., dass ein Flug mit 89-prozentiger Wahrscheinlichkeit pünktlich (ARR_DEL15 = 0) und mit 12-prozentiger Wahrscheinlichkeit verspätet ist (ARR_DEL15 = 1). Die Summe der Wahrscheinlichkeiten ergibt 100 %.Führen Sie den folgenden Code aus, um Wahrscheinlichkeiten der Vorhersage für das Testdataset zu generieren:
from sklearn.metrics import roc_auc_score probabilities = model.predict_proba(test_x)Führen Sie anschließend die folgende Anweisung aus, um mit der roc_auc_score-Methode von Scikit-learn eine ROC-AUC-Bewertung anhand der Wahrscheinlichkeiten zu berechnen:
roc_auc_score(test_y, probabilities[:, 1])Die Ausgabe sollte eine Bewertung von 67 % anzeigen:

Berechnen einer ROC-Bewertung
Warum ist die ROC-Bewertung geringer als die durchschnittliche Treffergenauigkeit, die wir in der vorherigen Übung berechnet haben?
Die Ausgabe der
score-Methode spiegelt wider, wie viele Elemente im Testdataset vom Modell korrekt vorhergesagt wurden. Die Bewertung ist verzerrt, da das Dataset, mit dem das Modell trainiert und getestet wurde, deutlich mehr Zeilen mit pünktlichen Ankünften als mit verspäteten Ankünften enthält. Durch dieses Missverhältnis in den Daten ist es wahrscheinlicher, dass die Vorhersage einer pünktlichen Ankunft korrekt ist.Die ROC AUC beachtet dies und bietet so eine genauere Einschätzung, wie wahrscheinlich eine Vorhersage bezüglich pünktlich oder verspätet korrekt sein wird.
Wenn Sie mehr über das Verhalten des Modells erfahren möchten, können Sie eine Konfusionsmatrix, auch als Wahrheitsmatrix bezeichnet, generieren. Eine Konfusionsmatrix quantifiziert die Anzahl der Fälle, in denen jede Antwort richtig oder falsch klassifiziert wurde. Genau gesagt quantifiziert sie die Anzahl falsch positiver, falsch negativer, richtig positiver und richtig negativer Ergebnisse. Dies ist sehr wichtig, da z.B. ein binäres Klassifizierungsmodell, das Katzen und Hunde erkennen soll und mit einem Dataset getestet wird, das zu 95 % aus Hunden besteht, eine Bewertung von 95 % erreichen könnte, wenn es einfach immer „Hund“ ausgibt. Wenn es jedoch keine Katzen erkennen könnte, wäre dieses Modell nutzlos.
Verwenden Sie den folgenden Code, um eine Konfusionsmatrix für Ihr Modell zu erstellen:
from sklearn.metrics import confusion_matrix confusion_matrix(test_y, predicted)Die erste Zeile in der Ausgabe stellt Flüge dar, die pünktlich angekommen sind. Die erste Spalte in dieser Zeile gibt an, wie viele der Flüge richtigerweise als „pünktlich“ vorhergesagt wurden. Die zweite Spalte gibt an, wie viele Flüge als „verspätet“ vorhergesagt wurden, in Wirklichkeit aber pünktlich waren. Es sieht so aus, als sei das Modell gut darin vorherzusagen, wann ein Flug pünktlich ist.

Erstellen einer Konfusionsmatrix
Wenn Sie sich jedoch die zweite Zeile ansehen, sehen Sie die Flüge, die verspätet waren. In der ersten Zeile wird gezeigt, wie viele verspätete Flüge fälschlicherweise als pünktlich vorhergesagt wurden. In der zweiten Zeile wird gezeigt, wie viele Flüge richtigerweise als verspätet vorhergesagt wurden. Offensichtlich ist das Modell besser darin, pünktliche Flüge vorherzusagen. Idealerweise sehen Sie in einer Konfusionsmatrix oben links und unten rechts hohe Zahlen und oben rechts und unten links niedrige Zahlen (vorzugsweise Nullen).
Die Treffergenauigkeit eines Klassifizierungsmodells kann auch mit dem kombinierten Gütemaß aus Genauigkeit (precision) und Trefferquote (recall) gemessen werden. Angenommen, das Modell erhält drei pünktliche und drei verspätete Flugankünfte, hat zwei der drei pünktlichen Ankünfte korrekt vorhergesagt, aber falsch vorhergesagt, dass zwei der drei verspäteten Flüge pünktlich ankommen. In diesem Fall beträgt die Genauigkeit 50 % (zwei der vier als pünktlich vorhergesagten Flüge waren tatsächlich pünktlich), und die Trefferquote liegt bei 67 % (es hat zwei der drei pünktlichen Flüge richtig vorhergesagt). Weitere Informationen zur Genauigkeit und Trefferquote finden Sie unter https://en.wikipedia.org/wiki/Precision_and_recall.
Scikit-learn enthält die praktische Methode precision_score zum Berechnen der Genauigkeit. Führen Sie die folgenden Anweisungen aus, um die Genauigkeit Ihres Modells zu quantifizieren:
from sklearn.metrics import precision_score train_predictions = model.predict(train_x) precision_score(train_y, train_predictions)Sehen Sie sich die Ausgabe an. Was ist die Genauigkeit Ihres Modells?

Messen der Genauigkeit
Scikit-learn enthält zudem die Methode recall_score zum Berechnen der Trefferquote. Führen Sie die folgenden Anweisungen aus, um die Trefferquote Ihres Modells zu berechnen:
from sklearn.metrics import recall_score recall_score(train_y, train_predictions)Was ist die Trefferquote Ihres Modells?

Messen der Trefferquote
Verwenden Sie den Befehl File>Save and Checkpoint (Datei > Speichern und Prüfpunkt), um das Notebook zu speichern.
In der Realität würden professionelle Data Scientists noch weiter an der Treffergenauigkeit des Modells arbeiten. Sie würden u.a. unterschiedliche Algorithmen ausprobieren und den ausgewählten Algorithmus weiter optimieren, um die optimale Kombination aus Parametern zu finden. Wahrscheinlich würden sie auch das Dataset von Tausenden auf Millionen von Zeilen ausweiten und versuchen, das Missverhältnis zwischen verspäteten und pünktlichen Flügen auszugleichen. Für unsere Zwecke ist das Modell jedoch so ausreichend.