Übung: Trainieren eines Machine Learning-Modells
Sie haben Sensordaten von intakten und ausgefallenen Produktionsgeräten gesammelt. Jetzt möchten Sie mit Model Builder ein Machine Learning-Modell trainieren, das vorhersagt, ob eine Maschine ausfallen wird oder nicht. Durch den Einsatz von maschinellem Lernen zur Automatisierung der Überwachung dieser Geräte können Sie für Ihr Unternehmen Kosten einsparen, indem Sie eine rechtzeitige und zuverlässige Wartung gewährleisten.
Hinzufügen eines neuen Machine Learning-Modellelements (ML.NET)
Um den Trainingsprozess zu starten, müssen Sie ein neues Machine Learning-Modellelement (ML.NET) zu einer neuen oder vorhandenen .NET-Anwendung hinzufügen.
Erstellen einer C#-Klassenbibliothek
Da Sie von Grund auf neu beginnen, erstellen Sie ein neues C#-Klassenbibliotheksprojekt, dem Sie ein Machine Learning-Modell hinzufügen können.
Starten Sie Visual Studio.
Wählen Sie im Startfenster die Option Neues Projekt erstellen aus.
Geben Sie im Dialogfeld Neues Projekt erstellen den Suchbegriff Klassenbibliothek in die Suchleiste ein.
Wählen Sie in der Liste der Optionen Klassenbibliothek aus. Stellen Sie sicher, dass die Sprache C# ist, und wählen Sie Weiter aus.
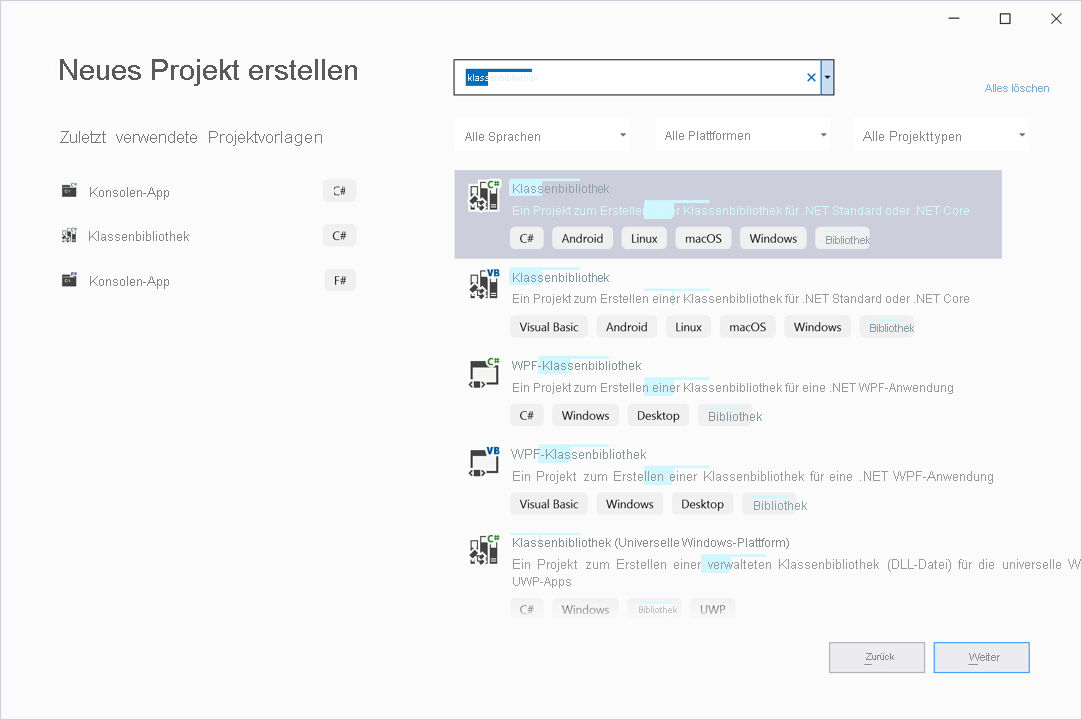
Geben Sie in das Textfeld Projektname den Namen PredictiveMaintenance ein. Behalten Sie für alle anderen Felder die Standardwerte bei, und klicken Sie auf Weiter.
Wählen Sie in der Dropdownliste Framework die Option .NET 6.0 (Vorschau) und dann Erstellen aus, um das Gerüst für Ihre C#-Klassenbibliothek zu erstellen.

Hinzufügen von Machine Learning zu Ihrem Projekt
Sobald Ihr Klassenbibliotheksprojekt in Visual Studio geöffnet wird, können Sie es mit maschinellem Lernen erweitern.
Klicken Sie im Projektmappen-Explorer von Visual Studio mit der rechten Maustaste auf Ihr Projekt.
Wählen Sie Hinzufügen>Machine Learning-Modell aus.
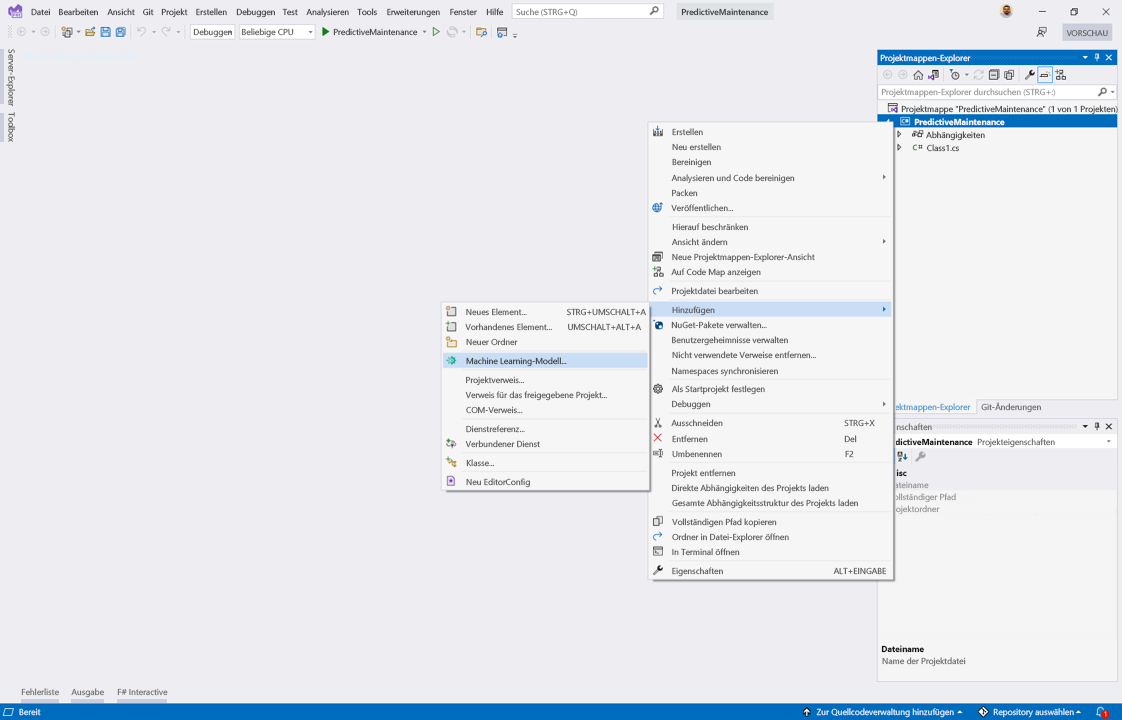
Wählen Sie in der Liste der neuen Elemente im Dialogfeld Neues Element hinzufügen die Option Machine Learning-Modell (ML.NET) aus.
Verwenden Sie im Textfeld Name den Namen PredictiveMaintenanceModel.mbconfig für Ihr Modell, und wählen Sie Hinzufügen aus.
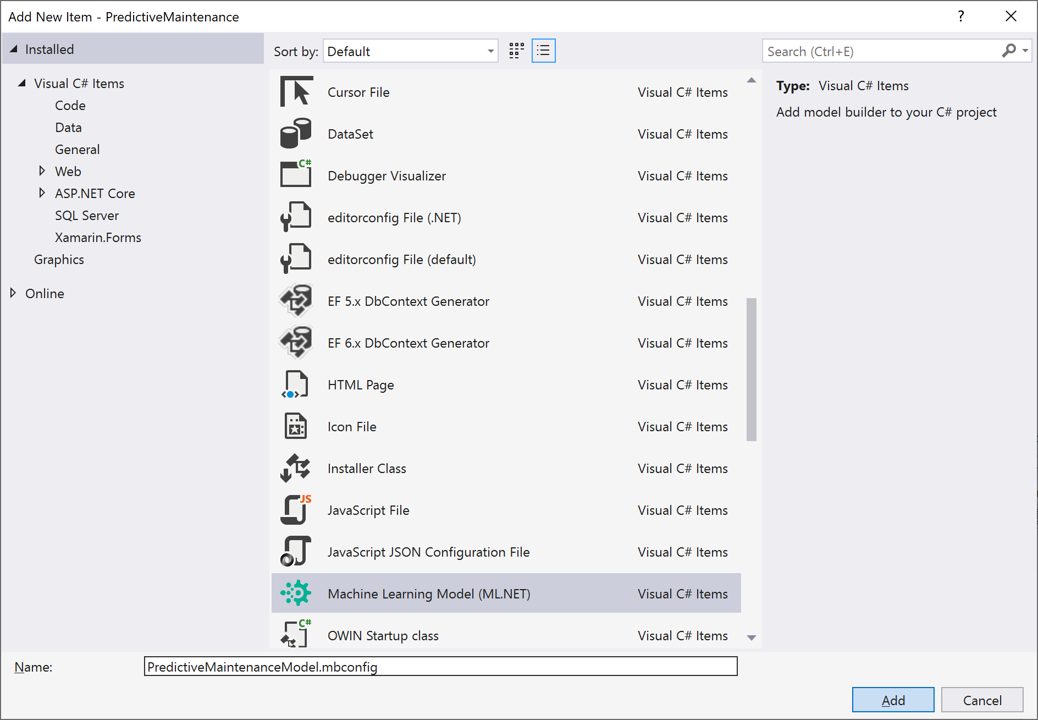


Nach einigen Sekunden wird dem Projekt eine Datei namens PredictiveMaintenanceModel.mbconfig hinzugefügt.
Auswählen Ihres Szenarios
Wenn Sie einem Projekt zum ersten Mal ein Machine Learning-Modell hinzufügen, wird der Model Builder-Bildschirm geöffnet. Jetzt ist es an der Zeit, Ihr Szenario auszuwählen.
In Ihrem Anwendungsfall versuchen Sie zu ermitteln, ob eine Maschine ausgefallen ist. Da es nur zwei Optionen gibt und Sie bestimmen möchten, in welchem Zustand sich eine Maschine befindet, ist das Datenklassifizierungsszenario am besten geeignet.
Wählen Sie im Schritt Szenario von Model Builder das Szenario Datenklassifizierung aus. Nachdem Sie dieses Szenario ausgewählt haben, wird sofort der Bildschirm Umgebung angezeigt.

Auswählen Ihrer Umgebung
Für Datenklassifizierungsszenarios werden nur lokale Umgebungen unterstützt, die Ihre CPU verwenden.
- Im Schritt Umgebung von Model Builder ist standardmäßig Lokal (CPU) ausgewählt. Lassen Sie die Standardumgebung ausgewählt.
- Wählen Sie Nächster Schritt aus.

Laden und Aufbereiten Ihrer Daten
Nachdem Sie Ihr Szenario und Ihre Trainingsumgebung ausgewählt haben, können Sie die gesammelten Daten mit Model Builder laden und aufbereiten.
Vorbereiten Ihrer Daten
Öffnen Sie die Datei im Text-Editor Ihrer Wahl.
Die ursprünglichen Spaltennamen enthalten Klammersonderzeichen. Entfernen Sie die Sonderzeichen aus den Spaltennamen, um Probleme beim Analysieren der Daten zu vermeiden.
Ursprünglicher Header:
UDI,Product ID,Type,Air temperature [K],Process temperature [K],Rotational speed [rpm],Torque [Nm],Tool wear [min],Machine failure,TWF,HDF,PWF,OSF,RNFAktualisierter Header:
UDI,Product ID,Type,Air temperature,Process temperature,Rotational speed,Torque,Tool wear,Machine failure,TWF,HDF,PWF,OSF,RNFSpeichern Sie die Datei ai4i2020.csv mit Ihren Änderungen.
Auswählen des Datenquellentyps
Das Predictive Maintenance-Dataset ist eine CSV-Datei.
Wählen Sie im Schritt Daten von Model Builder Datei (CSV, TSV, TXT) als Datenquellentyp aus.
Angeben des Speicherorts Ihrer Daten
Wählen Sie die Schaltfläche Durchsuchen aus, und verwenden Sie den Datei-Explorer, um den Speicherort Ihres Datasets ai4i2020.csv anzugeben.
Auswählen der Bezeichnungsspalte
Wählen Sie in der Dropdownliste Vorherzusagende Spalte (Bezeichnung) die Spalte Machine failure aus.

Auswählen erweiterter Datenoptionen
Standardmäßig werden alle Spalten, die nicht die Bezeichnung sind, als Features verwendet. Einige Spalten enthalten redundante Informationen, andere haben keinen Einfluss auf die Vorhersage. Verwenden Sie die erweiterten Datenoptionen, um diese Spalten zu ignorieren.
Wählen Sie Erweiterte Datenoptionen aus.
Wählen Sie im Dialogfeld Erweiterte Datenoptionen die Registerkarte Spalteneinstellungen aus.
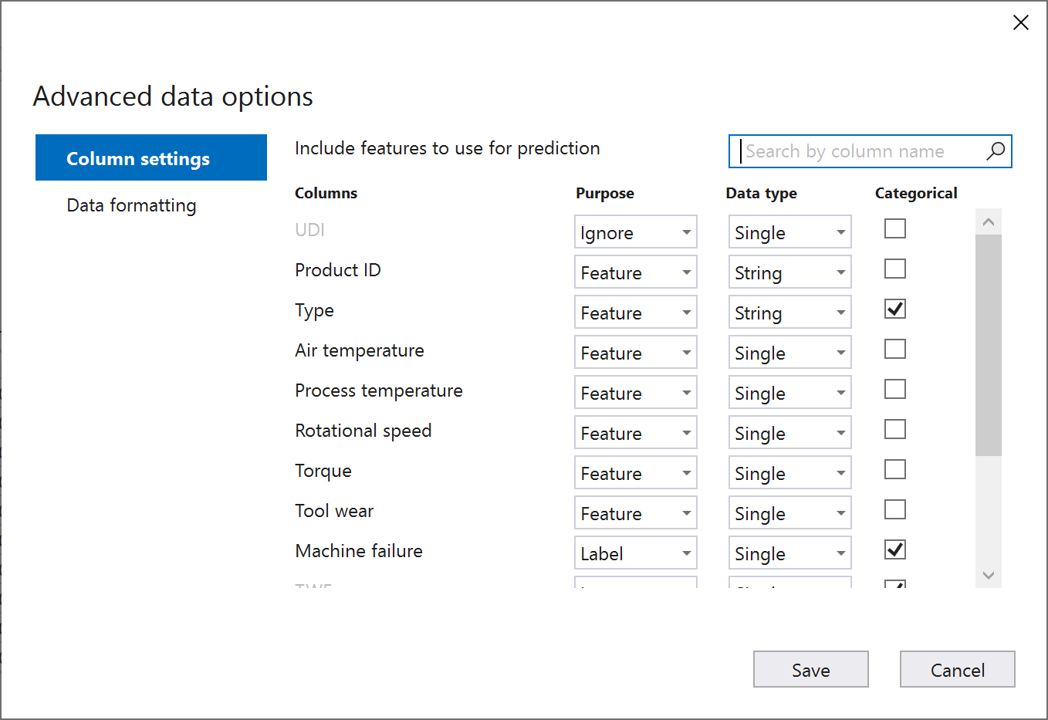
Konfigurieren Sie die Spalteneinstellungen wie folgt:
Spalten Zweck Datentyp Kategorisch UDI Ignorieren Single Product ID Komponente String type Funktion String X Air temperature Komponente Single Process temperature Komponente Single Rotational speed Komponente Single Torque Komponente Single Tool wear Komponente Single Machine failure Bezeichnung Single X TWF Ignorieren Single X HDF Ignorieren Single X PWF Ignorieren Single X OSF Ignorieren Single X RNF Ignorieren Single X Wählen Sie Speichern aus.
Wählen Sie im Schritt Daten von Model Builder Nächster Schritt aus.

Trainieren Ihres Modells
Verwenden Sie Model Builder und automatisiertes ML, um Ihr Modell zu trainieren.
Festlegen der Trainingszeit
Model Builder legt automatisch fest, wie lange Sie basierend auf der Größe Ihrer Datei trainieren sollten. Geben Sie in diesem Fall einen höheren Wert für die Trainingszeit an, damit Model Builder mehr Modelle untersuchen kann.
- Legen Sie im Schritt Trainieren von Model Builder die Trainingszeit (Sekunden) auf 30 fest.
- Wählen Sie Trainieren aus.
Nachverfolgen des Trainingsprozesses

Nachdem der Trainingsprozess gestartet wurde, untersucht Model Builder verschiedene Modelle. Ihr Trainingsprozess wird in den Trainingsergebnissen und im Ausgabefenster von Visual Studio nachverfolgt. Die Trainingsergebnisse geben Aufschluss über das beste Modell, das während des Trainingsprozesses gefunden wurde. Das Ausgabefenster enthält detaillierte Informationen, darunter den Namen des verwendeten Algorithmus, die Dauer des Trainings und die Leistungsmetriken für dieses Modell.
Möglicherweise wird der gleiche Algorithmusname mehrmals angezeigt. Dies liegt daran, dass Model Builder nicht nur verschiedene Algorithmen, sondern auch unterschiedliche Hyperparameterkonfigurationen für diese Algorithmen ausprobiert.
Auswerten des Modells
Verwenden Sie Auswertungsmetriken und -daten, um die Leistung Ihres Modells zu testen.
Untersuchen des Modells
Mit dem Schritt Auswerten von Model Builder können Sie den Algorithmus und die Auswertungsmetriken überprüfen, die für das beste Modell ausgewählt wurden. Denken Sie daran, dass es in Ordnung ist, wenn Ihre Ergebnisse von den in diesem Modul genannten abweichen, da der gewählte Algorithmus und die Hyperparameter unterschiedlich sein können.
Testen des Modells
Im Abschnitt Modell testen des Schritts Auswerten können Sie neue Daten bereitstellen und die Ergebnisse Ihrer Vorhersage auswerten.

Im Abschnitt Beispieldaten geben Sie Eingabedaten für Ihr Modell an, um Vorhersagen zu treffen. Jedes Feld entspricht den Spalten, die zum Trainieren Ihres Modells verwendet wurden. Dies ist eine praktische Möglichkeit, um zu überprüfen, ob sich das Modell wie erwartet verhält. Standardmäßig wird Model Builder vorab mit der ersten Zeile aus Ihrem Dataset aufgefüllt.
Testen Sie Ihr Modell, um festzustellen, ob es die erwarteten Ergebnisse liefert.
Geben Sie im Abschnitt Beispieldaten die folgenden Daten ein. Diese stammen aus der Zeile in Ihrem Dataset mit UID 161.
Spalte Wert Product ID L47340 type L Air temperature 298,4 Process temperature 308,2 Rotational speed 1282 Torque 60,7 Tool wear 216 Wählen Sie Predict aus.
Auswerten von Vorhersageergebnissen
Der Abschnitt Ergebnisse zeigt die von Ihrem Modell getroffene Vorhersage und den Grad der Zuverlässigkeit dieser Vorhersage an.
Wenn Sie sich die Spalte Machine failure mit UID 161 in Ihrem Dataset ansehen, werden Sie feststellen, dass der Wert 1 beträgt. Dies entspricht dem vorhergesagten Wert mit der höchsten Zuverlässigkeit im Abschnitt Ergebnisse.
Wenn Sie möchten, können Sie Ihr Modell mit unterschiedlichen Eingabewerten testen und die Vorhersagen auswerten.
Herzlichen Glückwunsch! Sie haben ein Modell trainiert, um Maschinenausfälle vorherzusagen. In der nächsten Lerneinheit erfahren Sie mehr über die Modellnutzung.