Repositorys und trunkbasierte Entwicklung
Viele Datenwissenschaftler bevorzugen die Arbeit mit Python oder R, um Workloads für maschinelles Lernen zu definieren. Sie können Jupyter-Notebooks oder Skripte verwenden, um Daten vorzubereiten oder ein Modell zu trainieren.
Die Arbeit an Coderessourcen wird einfacher, wenn Sie Quellcodeverwaltung verwenden. Die Quellcodeverwaltung ist die Vorgehensweise zum Verwalten von Code und zum Nachverfolgen von Änderungen , die Ihr Team am Code vorsetzt.
Wenn Sie mit DevOps-Tools wie Azure DevOps oder GitHub arbeiten, wird der Code in einem sogenannten Repository oder Repository gespeichert.
Verzeichnis
Beim Einrichten des MLOps-Frameworks erstellt wahrscheinlich ein Techniker für maschinelles Lernen das Repository. Unabhängig davon, ob Sie Azure Repos in Azure DevOps oder GitHub-Repositorys verwenden, verwenden beide Git-Repositorys , um Ihren Code zu speichern.
Im Allgemeinen gibt es zwei Möglichkeiten zum Festlegen des Bereichs des Repositorys:
- Monorepo: Behalten Sie alle Arbeitsauslastungen des maschinellen Lernens innerhalb desselben Repositorys bei.
- Mehrere Repositorys: Erstellen Sie für jedes neue Machine Learning-Projekt ein separates Repository.
Welche Vorgehensweise Ihr Team bevorzugt, hängt davon ab, wer Zugriff auf welche Ressourcen erhalten soll. Wenn Sie den schnellen Zugriff auf alle Coderessourcen sicherstellen möchten, können Monorepos den Anforderungen Ihres Teams besser entsprechen. Wenn Sie nur Personen Zugriff auf ein Projekt gewähren möchten, die aktiv daran arbeiten, kann Ihr Team mit mehreren Repositorys arbeiten. Beachten Sie, dass das Verwalten der Zugriffssteuerung zu mehr Aufwand führen kann.
Strukturieren Ihres Repositorys
Unabhängig vom gewählten Ansatz sollten Sie sich über die Standardordnerstruktur auf oberster Ebene für Ihre Projekte verständigen. Beispielsweise können Sie die folgenden Ordner in allen Repositorys haben:
-
.cloud: Enthält cloudspezifischen Code wie Vorlagen zum Erstellen eines Azure Machine Learning-Arbeitsbereichs. -
.ad/.github: Enthält Azure DevOps oder GitHub-Artefakte wie YAML-Pipelines, um Workflows zu automatisieren. -
src: Enthält einen Code (Python- oder R-Skripte), der für Workloads für maschinelles Lernen wie die Vorverarbeitung von Daten oder Modellschulungen verwendet wird. -
docs: Enthält alle Markdowndateien oder andere Dokumentationen, die zum Beschreiben des Projekts verwendet werden. -
pipelines: Enthält Azure Machine Learning-Pipelinedefinitionen. -
tests: Enthält Einheiten- und Integrationstests, die verwendet werden, um Fehler und Probleme in Ihrem Code zu erkennen. -
notebooks: Enthält Jupyter-Notebooks, die hauptsächlich für Experimente verwendet werden.
Hinweis
Schulungsdaten sollten nicht in Ihr Repository einbezogen werden. Die Daten sollten in einer Datenbank oder einem Data Lake gespeichert werden. Azure Machine Learning kann direkten Zugriff auf eine Datenbank oder einen Datensee haben, indem die Verbindungsinformationen als Datenspeicher gespeichert werden.
Durch eine in jedem Projekt verwendete Standardstruktur finden Datenwissenschaftler und andere Mitarbeiter einfacher den Code, an dem sie arbeiten müssen.
Tipp
Hier finden Sie weitere bewährte Methoden zum Strukturieren von Data Science-Projekten.
Um zu erfahren, wie Sie mit Repos als Data Scientist arbeiten, erfahren Sie mehr über die trunkbasierte Entwicklung.
Trunkbasierte Entwicklung
Die meisten Softwareentwicklungsprojekte verwenden Git als Quellcodeverwaltungssystem, das sowohl von Azure DevOps als auch GitHub verwendet wird.
Der Hauptvorteil der Verwendung von Git ist die einfache Zusammenarbeit im Code, während zudem sämtliche vorgenommenen Änderungen nachverfolgt werden. Darüber hinaus können Sie Genehmigungsprüfungen hinzufügen, um sicherzustellen, dass nur Änderungen am Produktionscode vorgenommen werden, die überprüft und akzeptiert wurden.
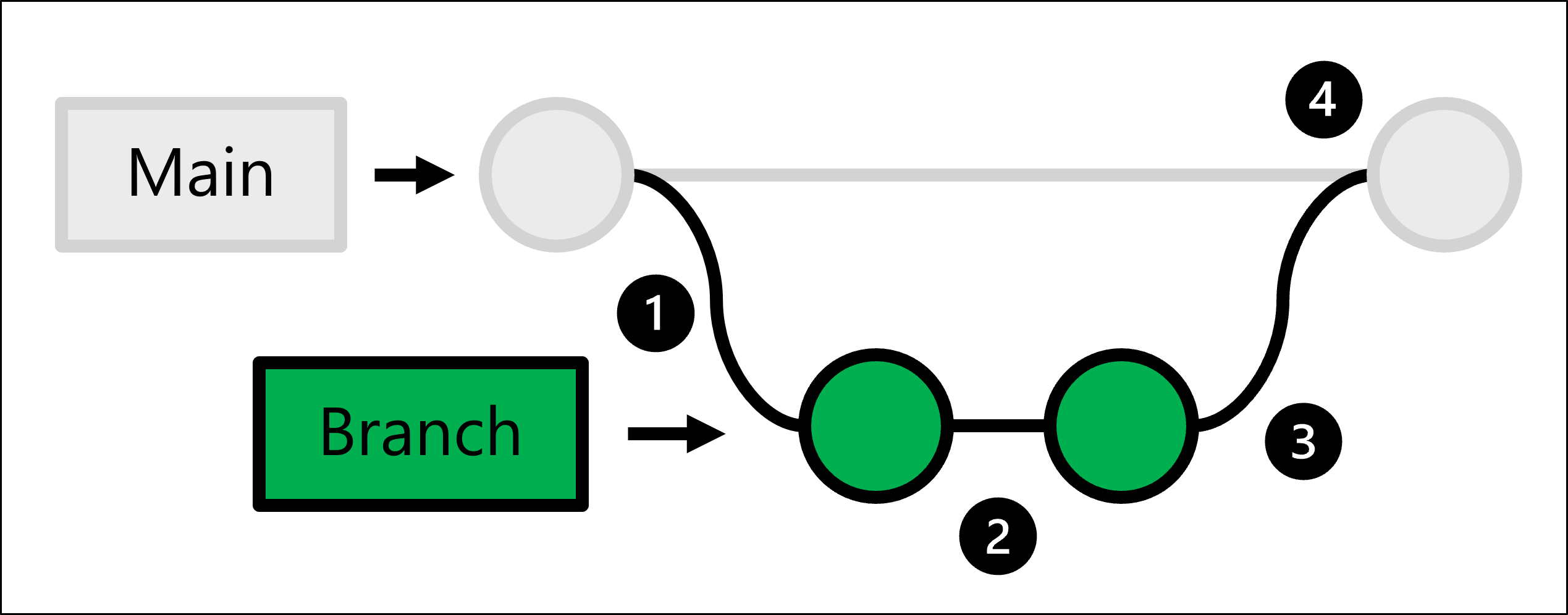
Um die oben genannten Schritte auszuführen, verwendet Git trunk-basierte Entwicklung, mit der Sie Verzweigungen erstellen können.
Der Produktionscode wird in der Hauptzweigung gehostet. Wenn jemand eine Änderung vornehmen möchte:
- Sie erstellen eine vollständige Kopie des Produktionscodes, indem Sie eine Verzweigung erstellen.
- In dem von Ihnen erstellten Branch nehmen Sie alle Änderungen vor und testen sie.
- Sobald die Änderungen in Ihrem Branch bereit sind, können Sie jemanden bitten, die Änderungen zu überprüfen.
- Wenn die Änderungen genehmigt werden, führen Sie den von Ihnen erstellten Zweig mit dem Haupt-Repository zusammen, und der Produktionscode wird aktualisiert, um Ihre Änderungen widerzuspiegeln.