Was ist Klassifizierung?
Binäre Klassifizierung ist eine Klassifizierung mit zwei Kategorien. Beispielsweise könnten Patienten als Nicht-Diabetiker oder Diabetiker bezeichnet werden.
Die Klassenvorhersage basiert auf der Wahrscheinlichkeit für jede Klasse, die durch einen Wert zwischen 0 (unmöglich) und 1 (sicher) angegeben wird. Die Gesamtwahrscheinlichkeit für alle Klassen beträgt immer 1, da der Patient definitiv entweder Diabetiker oder Nicht-Diabetiker ist. Wenn also die vorhergesagte Wahrscheinlichkeit, dass ein Patient Diabetiker ist, 0,3 beträgt, liegt die Wahrscheinlichkeit, dass der Patient Nicht-Diabetiker ist, entsprechend bei 0,7.
Ein Schwellenwert, häufig 0,5, wird verwendet, um die vorhergesagte Klasse zu bestimmen. Wenn die positive Klasse (in diesem Fall „Diabetiker“) eine vorhergesagte Wahrscheinlichkeit hat, die über dem Schwellenwert liegt, dann wird eine Klassifizierung in die Kategorie „Diabetiker“ vorhergesagt.
Trainieren und Bewerten eines Klassifizierungsmodells
Die Klassifizierung ist ein Beispiel einer überwachten Machine Learning-Methode, d. h., sie basiert auf Daten, die bekannte Merkmalwerte und bekannte Bezeichnungswerte enthalten. In diesem Beispiel sind die Merkmalwerte diagnostische Messungen für Patienten, und die Bezeichnungswerte sind eine Klassifizierung von Nicht-Diabetikern oder Diabetikern. Ein Klassifizierungsalgorithmus wird verwendet, um eine Teilmenge der Daten an eine Funktion anzupassen, die die Wahrscheinlichkeit für jede Klassenbezeichnung aus den Merkmalwerten berechnen kann. Die verbleibenden Daten werden verwendet, um das Modell zu bewerten, indem die basierend auf den Merkmalen generierten Vorhersagen mit den bekannten Klassenbezeichnungen verglichen werden.
Ein einfaches Beispiel
Sehen wir uns ein Beispiel an, in dem die wichtigsten Prinzipien erläutert werden. Angenommen, wir verfügen über die folgenden Patientendaten, die aus einem einzelnen Merkmal (Blutzuckerspiegel) und einer Klassenbezeichnung von 0 für Nicht-Diabetiker und 1 für Diabetiker bestehen.
| Blutzucker | Diabetisch |
|---|---|
| 82 | 0 |
| 92 | 0 |
| 112 | 1 |
| 102 | 0 |
| 115 | 1 |
| 107 | 1 |
| 87 | 0 |
| 120 | 1 |
| 83 | 0 |
| 119 | 1 |
| 104 | 1 |
| 105 | 0 |
| 86 | 0 |
| 109 | 1 |
Wir verwenden die ersten acht Beobachtungen zum Trainieren eines Klassifizierungsmodells. Zunächst führen wir ein Plotting für das Merkmal „Blutzucker“ (x) und die vorhergesagte Diabetikerbezeichnung (yy) durch.
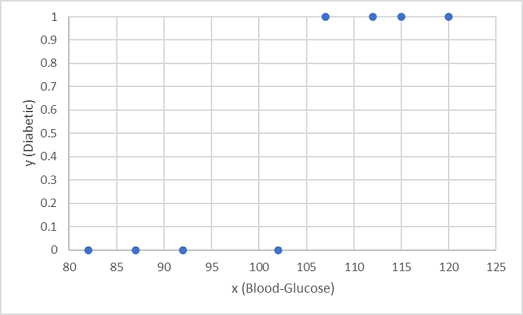
Wir benötigen eine Funktion, die einen Wahrscheinlichkeitswert für y berechnet, der auf x basiert (d. h., wir benötigen die Funktion f(x) = y). Sie können im Diagramm sehen, dass alle Patienten mit einem niedrigen Blutzuckerspiegel Nicht-Diabetiker sind, während Patienten mit einem höheren Blutzuckerspiegel Diabetiker sind. Es scheint, je höher der Blutzuckerspiegel ist, desto wahrscheinlicher ist es, dass ein Patient Diabetiker ist, wobei der entscheidende Punkt irgendwo zwischen 100 und 110 liegt. Wir müssen eine Funktion, die für y einen Wert zwischen 0 und 1 berechnet, an diese Werte anpassen.
Eine dieser Funktionen ist eine logistic-Funktion, die eine s-förmige Kurve (Sigmoidfunkion) bildet.
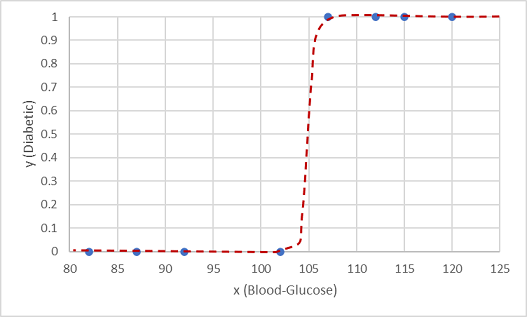
Nun können wir die Funktion verwenden, um einen Wahrscheinlichkeitswert für eine positive Diagnose (d. h., der Patient ist Diabetiker) von y zu berechnen. Diese Berechnung kann mit jedem Wert von x erfolgen, indem wir den Punkt auf der Funktionslinie für x finden. Wir können einen Schwellenwert von 0,5 als Grenzwert für die Klassenbezeichnungsvorhersage festlegen.
Lassen Sie uns das mit den zurückgehaltenen Datenwerten ausprobieren.
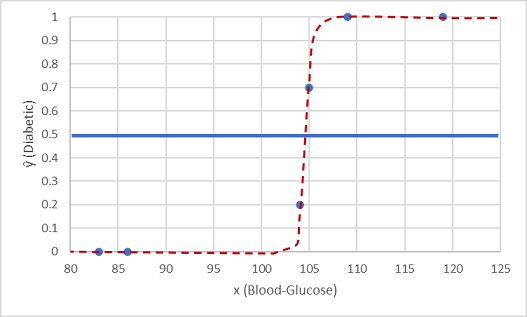
Punkte, die sich unterhalb der Linie für den Schwellenwert befinden, werden der vorhergesagten Klasse 0 zugeordnet (Nicht-Diabetiker). Analog dazu werden Punkte oberhalb der Schwellenwertlinie der vorhergesagten Klasse 1 zugeordnet (Diabetiker).
Nun können wir die Bezeichnungsvorhersagen (ŷ oder „y-Hut“) anhand der logistic-Funktion, die im Modell gekapselt ist, mit den tatsächlichen Klassenbezeichnungen (y) vergleichen.
| x | Y | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |