Bewerten von Klassifizierungsmodellen
Die Trainingsgenauigkeit eines Klassifizierungsmodells ist lange nicht so wichtig wie die Funktionsweise dieses Modells bei neuen, unbekannten Daten. Schließlich trainieren wir Modelle so, dass sie für neue Daten verwendet werden können, die wir in der realen Welt finden. Nachdem wir also ein Klassifizierungsmodell trainiert haben, werden wir nun seine Leistung für eine Reihe neuer, unbekannter Daten bewerten.
In den vorherigen Einheiten haben wir ein Modell erstellt, mit dem sich anhand des Blutzuckerspiegels eines Patienten vorhersagen lässt, ob dieser Diabetes hat oder nicht. Wenn wir dieses Modell nun auf Daten anwenden, die nicht Teil des Trainingssatzes waren, erhalten wir die folgenden Vorhersagen.
| x | y | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |
Denken Sie daran, dass sich x auf den Blutzuckerspiegel, y auf den tatsächlichen Gesundheitszustand des Patienten (Diabetiker oder nicht) und ŷ auf die Vorhersage des Modells (Diabetiker oder nicht) bezieht.
Einfach zu berechnen, wie viele Vorhersagen richtig waren, ist manchmal irreführend oder allzu einfach, als dass wir uns ein Bild davon machen könnten, welche Arten von Fehlern in der realen Welt auftreten. Um detailliertere Informationen zu erhalten, können wir die Ergebnisse in einer Struktur, die als Verwirrungsmatrix bezeichnet wird, wie folgt auffüllen:
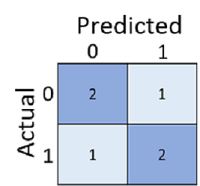
Die Konfusionsmatrix zeigt die Gesamtzahl der Fälle, in denen Folgendes gilt:
- Das Modell hat 0 vorhergesagt, und die tatsächliche Beschriftung ist 0 (true negative, oben links)
- Das Modell hat 1 vorhergesagt und die tatsächliche Beschriftung ist 1 (wahr positive Ergebnisse, unten rechts)
- Das Modell hat 0 vorhergesagt, und die tatsächliche Beschriftung ist 1 (falsch negativ, unten links)
- Das Modell hat 1 vorhergesagt und die tatsächliche Beschriftung ist 0 (falsch positive Ergebnisse, oben rechts)
Die Zellen in einer Konfusionsmatrix werden häufig farblich hinterlegt, damit höhere Werte einen stärkeren Farbton haben. Dadurch ist es einfacher, einen starken diagonalen Trend von oben links nach unten rechts zu erkennen. Dabei werden die Zellen hervorgehoben, bei denen vorhergesagter und tatsächlicher Wert übereinstimmen.
Aus diesen Kernwerten können Sie verschiedene andere Metriken berechnen, die Ihnen helfen können, die Leistung des Modells zu bewerten. Beispiel:
- Genauigkeit: (TP+TN)/(TP+TN+FP+FN) - aus allen Vorhersagen, wie viele waren richtig?
- Trefferquote: TP / (TP + FN) – wie viele der tatsächlich positiven Fälle hat das Modell ermittelt?
- Genauigkeit: TP/(TP+FP) - aller Fälle, die das Modell als positiv vorhergesagt hat, wie viele sind tatsächlich positiv?