Convolutional Neural Networks
Obwohl Sie Deep Learning-Modelle für jede Art von maschinellem Lernen verwenden können, sind sie besonders nützlich für den Umgang mit Daten, die aus großen Arrays numerischer Werte bestehen , z. B. Bilder. Machine Learning-Modelle, die mit Bildern arbeiten, sind die Grundlage für eine Region künstliche Intelligenz, die als Computervision bezeichnet wird, und Deep Learning-Techniken sind in den letzten Jahren dafür verantwortlich, erstaunliche Fortschritte in diesem Bereich voranzutreiben.
Im Mittelpunkt des Erfolgs von Deep Learning in diesem Bereich ist ein Modell, das als konvolutionales neurales Netzwerk oder CNN bezeichnet wird. Ein CNN funktioniert in der Regel, indem Features aus Bildern extrahiert und diese Features dann in ein vollständig verbundenes neurales Netzwerk eingespeist werden, um eine Vorhersage zu generieren. Die Featureextraktionsebenen im Netzwerk haben die Auswirkung, die Anzahl der Features aus dem potenziell riesigen Array einzelner Pixelwerte auf einen kleineren Featuresatz zu reduzieren, der die Beschriftungsvorhersage unterstützt.
Schichten in einem Convolutional Neural Network
CNNs bestehen aus mehreren Ebenen, die jeweils eine bestimmte Aufgabe zum Extrahieren von Features oder zur Vorhersage von Bezeichnungen ausführen.
Konvolutionsebenen
Einer der Hauptschichtentypen ist eine Konvolutionsschicht, die wichtige Merkmale in Bildern extrahiert. Eine konvolutionale Ebene funktioniert durch Anwenden eines Filters auf Bilder. Der Filter wird durch einen Kernel definiert, der aus einer Matrix von Gewichtungswerten besteht.
Beispielsweise kann ein 3x3-Filter wie folgt definiert werden:
1 -1 1
-1 0 -1
1 -1 1
Ein Bild ist auch nur eine Matrix von Pixelwerten. Um den Filter anzuwenden, überlagern Sie ihn auf ein Bild und berechnen eine gewichtete Summe der entsprechenden Bildpixelwerte unter dem Filterkern. Das Ergebnis wird dann der mittleren Zelle eines entsprechenden 3x3-Patches in einer neuen Matrix mit Werten zugewiesen, die dieselbe Größe wie das Bild aufweisen. Angenommen, ein Bild von 6 x 6 hat die folgenden Pixelwerte:
255 255 255 255 255 255
255 255 100 255 255 255
255 100 100 100 255 255
100 100 100 100 100 255
255 255 255 255 255 255
255 255 255 255 255 255
Das Anwenden des Filters auf den oberen linken 3x3-Patch des Bilds würde wie folgt funktionieren:
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 255 100 x -1 0 -1 = (255 x -1)+(255 x 0)+(100 x -1) + = 155
255 100 100 1 -1 1 (255 x1 )+(100 x -1)+(100 x 1)
Das Ergebnis wird dem entsprechenden Pixelwert in der neuen Matrix wie folgt zugewiesen:
? ? ? ? ? ?
? 155 ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Nun wird der Filter verschoben (gefaltet). Üblicherweise wird hierfür eine Schrittgröße von 1 verwendet (d. h. er wird um ein Pixel nach rechts verschoben), und der Wert für das nächste Pixel wird berechnet.
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 100 255 x -1 0 -1 = (255 x -1)+(100 x 0)+(255 x -1) + = -155
100 100 100 1 -1 1 (100 x1 )+(100 x -1)+(100 x 1)
Jetzt können wir also den nächsten Wert der neuen Matrix ausfüllen.
? ? ? ? ? ?
? 155 -155 ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Der Vorgang wird wiederholt, bis wir den Filter auf alle 3x3-Patches des Bilds angewendet haben, um eine neue Matrix mit Werten wie diesem zu erzeugen:
? ? ? ? ? ?
? 155 -155 155 -155 ?
? -155 310 -155 155 ?
? 310 155 310 0 ?
? -155 -155 -155 0 ?
? ? ? ? ? ?
Aufgrund der Größe des Filterkerns können wir keine Werte für die Pixel am Rand berechnen. Daher wenden wir in der Regel nur einen Abstandswert an (häufig 0):
0 0 0 0 0 0
0 155 -155 155 -155 0
0 -155 310 -155 155 0
0 310 155 310 0 0
0 -155 -155 -155 0 0
0 0 0 0 0 0
Die Ausgabe der Konvolution wird in der Regel an eine Aktivierungsfunktion übergeben, bei der es sich häufig um eine ReLU-Funktion ( Rectified Linear Unit ) handelt, die sicherstellt, dass negative Werte auf 0 festgelegt werden:
0 0 0 0 0 0
0 155 0 155 0 0
0 0 310 0 155 0
0 310 155 310 0 0
0 0 0 0 0 0
0 0 0 0 0 0
Die resultierende Matrix ist eine Featurezuordnung von Featurewerten, die zum Trainieren eines Machine Learning-Modells verwendet werden können.
Hinweis: Die Werte in der Featurezuordnung können größer als der Maximalwert für ein Pixel (255) sein. Wenn Sie also die Featurezuordnung als Bild visualisieren möchten, müssen Sie die Featurewerte zwischen 0 und 255 normalisieren .
Der Konvolutionsprozess wird in der nachstehenden Animation gezeigt.

- Ein Bild wird an die konvolutionale Ebene übergeben. In diesem Fall ist das Bild eine einfache geometrische Form.
- Das Bild besteht aus einem Array von Pixeln mit Werten zwischen 0 und 255 (für Farbbilder ist dies in der Regel ein 3-dimensionales Array mit Werten für rote, grüne und blaue Kanäle).
- Ein Filterkern wird in der Regel mit zufälligen Gewichtungen initialisiert (in diesem Beispiel haben wir Werte ausgewählt, um den Effekt hervorzuheben, den ein Filter auf Pixelwerte haben könnte. In einem echten CNN würden die Anfänglichgewichte in der Regel jedoch aus einer zufälligen Gaussischen Verteilung generiert). Dieser Filter wird verwendet, um eine Featurezuordnung aus den Bilddaten zu extrahieren.
- Der Filter wird über das Bild verteilt, wobei Funktionswerte berechnet werden, indem eine Summe der Gewichtungen angewendet wird, die mit ihren entsprechenden Pixelwerten an jeder Position multipliziert werden. Eine ReLU-Aktivierungsfunktion (Rectified Linear Unit) wird angewendet, um sicherzustellen, dass negative Werte auf 0 festgelegt sind.
- Nach der Konvolution enthält die Merkmalskarte die Merkmalswerte, die extrahiert wurden und häufig wichtige visuelle Attribute des Bilds betonen. In diesem Fall hebt die Featurekarte die Kanten und Ecken des Dreiecks im Bild hervor.
In der Regel wendet eine konvolutionale Ebene mehrere Filterkerne an. Jeder Filter erzeugt eine andere Featurezuordnung, und alle Featurezuordnungen werden auf die nächste Ebene des Netzwerks übergeben.
Poolingschichten
Nach dem Extrahieren von Feature- bzw. Merkmalswerten aus Bildern wird mit Poolingschichten (auch Komprimierungsschichten genannt) die Anzahl der Merkmalswerte verringert, wobei die wichtigsten extrahierten Unterscheidungsmerkmale erhalten bleiben.
Eine der am häufigsten verwendeten Arten von Pooling ist das max. Pooling , in dem ein Filter auf das Bild angewendet wird, und nur der maximale Pixelwert innerhalb des Filterbereichs wird beibehalten. Beispielsweise würde das Anwenden eines 2x2-Pooling-Kernels auf den folgenden Patch eines Images das Ergebnis 155 erzeugen.
0 0
0 155
Beachten Sie, dass der Effekt des 2x2-Poolingfilters darin besteht, die Anzahl der Werte von 4 auf 1 zu reduzieren.
Wie bei konvolutionalen Schichten arbeiten auch Pooling-Schichten, indem der Filter über die gesamte Merkmalskarte angewendet wird. Die folgende Animation zeigt ein Beispiel für Maxpooling für eine Zuordnung eines Bilds.

- Die Merkmalskarte, die von einem Filter in einer konvolutionalen Schicht extrahiert wird, enthält ein Array von Featurewerten.
- Ein Poolkern wird verwendet, um die Anzahl der Featurewerte zu reduzieren. In diesem Fall ist die Kernelgröße 2x2, sodass es ein Array mit vierteln der Anzahl der Featurewerte erzeugt.
- Der Poolingkern wird über die Merkmalszuordnung gefaltet, wobei bei jeder Position nur der höchste Pixelwert beibehalten wird.
Entfernungsschichten
Eine der größten Herausforderungen in einem CNN ist die Vermeidung von Überanpassung. Hierbei funktioniert das resultierende Modell gut mit den Trainingsdaten, kann aber nicht gut auf neue Daten generalisieren, mit denen es nicht trainiert wurde. Eine mögliche Methode zur Behebung von Überanpassung besteht darin, Schichten hinzuzufügen, in denen der Trainingsprozess zufällig Feature- bzw. Merkmalszuordnungen ausschließt (oder „entfernt“). Dies mag kontraintuitiv erscheinen, aber es ist eine effektive Möglichkeit, sicherzustellen, dass das Modell nicht zu stark von den Schulungsbildern abhängig wird.
Andere Techniken, die Sie verwenden können, um Überanpassung zu verringern, sind zufälliges Kippen, Spiegeln oder Verzerren der Trainingsbilder, um Daten zu generieren, die zwischen den Trainings-Epochen variieren.
Vereinfachungsschichten
Nach dem Extrahieren der wichtigsten Merkmale auf den Bildern mit Faltungs- und Poolingschichten handelt es sich bei den daraus resultierenden Merkmalszuordnungen um mehrdimensionale Arrays mit Pixelwerten. Mit einer Vereinfachungsschicht werden die Merkmalszuordnungen zu einem Vektor mit Werten vereinfacht, der als Eingabe für eine vollständig verbundene Schicht verwendet werden kann.
Vollständig verbundene Ebenen
In der Regel bildet ein vollständig verbundenes Netzwerk, in dem die Merkmalswerte an eine Eingabeschicht übergeben werden, eine oder mehrere verborgene Schichten durchlaufen und vorhergesagte Werte in einer Ausgabeschicht generiert werden, den Abschluss eines CNN.
Eine einfache CNN-Architektur sieht möglicherweise ähnlich wie folgt aus:
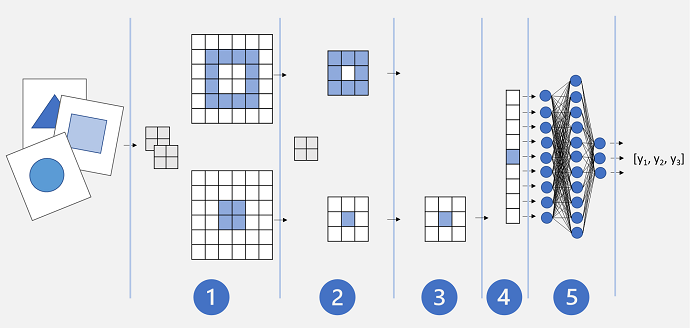
- Bilder werden in eine konvolutionale Ebene eingespeist. In diesem Fall gibt es zwei Filter, sodass jedes Bild zwei Merkmalskarten erzeugt.
- Die Merkmalszuordnungen werden an eine Poolingschicht weitergegeben, in der ein 2×2-Poolingkern ihre Größe reduziert.
- Eine Entfernungsschicht entfernt einige der Merkmalszuordnungen nach dem Zufallsprinzip. Dies hilft dabei, eine Überanpassung zu verhindern.
- In einer Vereinfachungsschicht werden die übrigen Merkmalszuordnungsarrays zu einem Vektor vereinfacht.
- Die Vektorelemente werden in ein vollständig verbundenes Netzwerk eingespeist, das die Vorhersagen generiert. In diesem Fall ist das Netzwerk ein Klassifizierungsmodell, das Wahrscheinlichkeiten für drei mögliche Bildklassen (Dreieck, Quadrat und Kreis) vorhersagt.
Schulung eines CNN-Modells
Wie bei jedem tiefen neuralen Netzwerk wird ein CNN trainiert, indem es Batches von Schulungsdaten über mehrere Epochen durchgibt, wobei die Gewichte und Voreingenommenheitswerte basierend auf dem für jede Epoche berechneten Verlust angepasst werden. Im Fall eines CNN umfasst die Backpropagation von angepassten Gewichtungen Filterkerngewichtungen, die in Faltungsschichten verwendet werden, sowie die in vollständig verbundenen Schichten verwendeten Gewichtungen.