Erkunden der Lösungsarchitektur
Sie sollten das Gesamtbild verstehen, bevor Sie die Implementierung durchführen, um sicherzustellen, dass alle Anforderungen erfüllt werden. Wir möchten außerdem gewährleisten, dass der Ansatz in Zukunft leicht angepasst werden kann. Der Schwerpunkt dieser Übung liegt darauf, GitHub Actions als Orchestrierungs- und Automatisierungstool für die in der Lösungsarchitektur definierte MLOps-Strategie (Machine Learning Operations) zu verwenden.
Hinweis
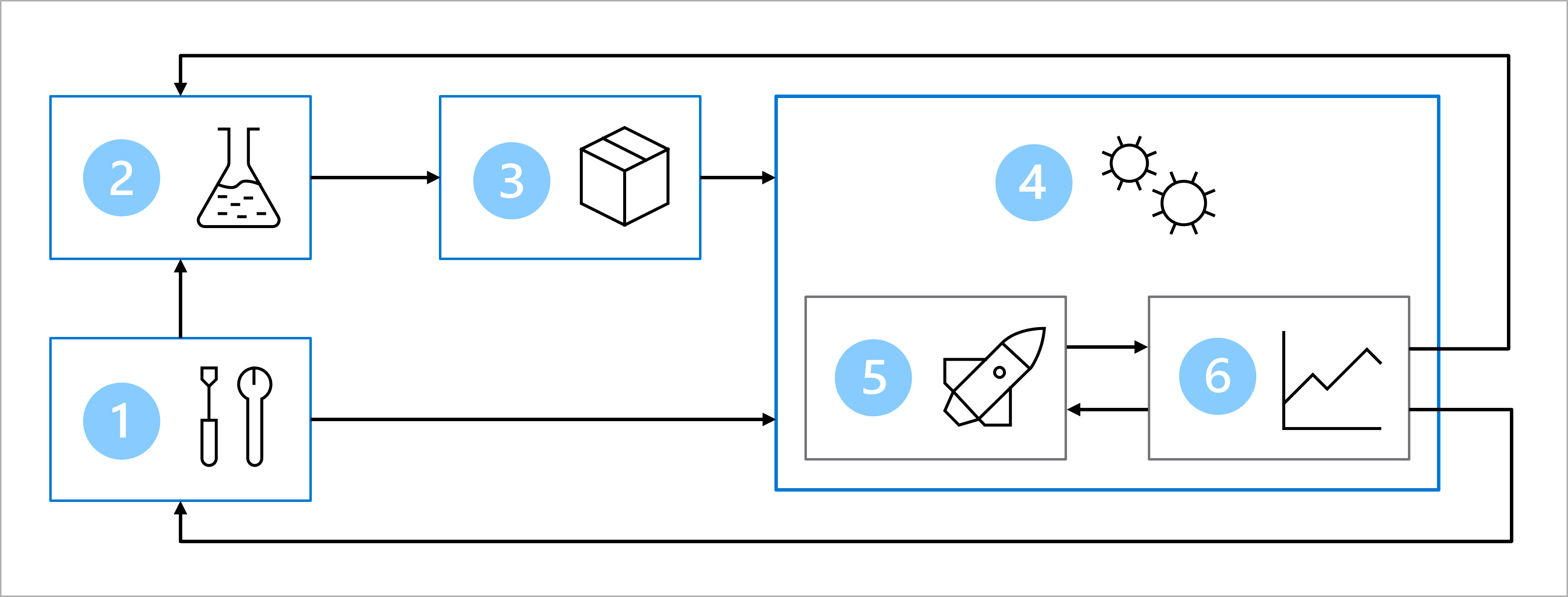
Das Diagramm zeigt eine vereinfachte Darstellung einer MLOps-Architektur. Eine detailliertere Beschreibung der Architektur finden Sie in den Anwendungsfällen im Solution Accelerator für MLOps (v2).
Die Architektur umfasst:
- Setup: Erstellen aller erforderlichen Azure-Ressourcen für die Lösung.
- Modellentwicklung (innere Schleife): Untersuchen und Verarbeiten der Daten zum Trainieren und Auswerten des Modells.
- Continuous Integration: Packen und Registrieren des Modells.
- Modellbereitstellung (äußere Schleife): Bereitstellen des Modells.
- Continuous Deployment: Testen des Modells und Höherstufen in die Produktionsumgebung.
- Überwachung: Überwachen der Modell- und Endpunktleistung.
Wir automatisieren insbesondere den Trainingsteil der Modellentwicklung bzw. die innere Schleife, wodurch wir letztendlich mehrere Modelle schnell für die Bereitstellung in Staging- und Produktionsumgebungen trainieren und registrieren können.
Der Azure Machine Learning-Arbeitsbereich, die Azure Machine Learning-Computeinstanz und das GitHub-Repository wurden vom Infrastrukturteam für Sie erstellt.
Darüber hinaus ist der Code zum Trainieren des Klassifizierungsmodells bereit für die Produktion, und die zum Trainieren des Modells benötigten Daten sind in einer Azure Blob Storage-Instanz verfügbar, die mit dem Azure Machine Learning-Arbeitsbereich verbunden ist.
Durch die Implementierung können Sie den Übergang von einer inneren zur äußeren Schleife automatisieren. Dieser Prozess wird immer dann durchgeführt, wenn ein*e Data Scientist neuen Modellcode an ein GitHub-Repository pusht. Dadurch wird die Continuous Delivery von Machine Learning-Modellen an nachgelagerte Consumer ermöglicht (z. B. an die Webanwendung, die das Diabetesklassifizierungsmodell verwendet).