Multiple lineare Regression und Bestimmtheitsmaß
In dieser Lerneinheit wird die multiple lineare Regression mit der einfachen linearen Regression verglichen. Wir sehen uns auch die Metrik „Bestimmtheitsmaß“ (R2, R-Squared) an, die häufig genutzt wird, um die Qualität eines Modells für die lineare Regression auszuwerten.
Multiple lineare Regression
Bei der multiplen linearen Regression wird die Beziehung zwischen mehreren Merkmalen und nur einer Variable modelliert. Mathematisch entspricht sie der einfachen linearen Regression, und normalerweise wird für die Anpassung auch die gleiche Kostenfunktion verwendet, aber mit mehr Merkmalen.
Anstatt einer einzelnen Beziehung werden bei diesem Verfahren mehrere Beziehungen gleichzeitig modelliert, die als unabhängig voneinander behandelt werden. Wenn wir beispielsweise anhand von age (Alter) und body_fat_percentage (Körperfettanteil) vorhersagen, wie schwer ein Hund erkrankt, werden zwei Beziehungen gefunden:
- Wie das Alter die Erkrankung ggf. verstärkt
- Wie der Körperfettanteil die Erkrankung ggf. verstärkt
Wenn wir nur mit zwei Features arbeiten, können wir unser Modell als 2D-Ebene visualisieren – genauso, wie wir auch die einfache lineare Regression als Linie modellieren können. Dies wird in der nächsten Übung beschrieben.
Annahmen bei der multiplen linearen Regression
Die Tatsache, dass vom Modell unabhängige Merkmale erwartet werden, wird als Modellannahme bezeichnet. Wenn Modellannahmen nicht zutreffen, trifft das Modell möglicherweise irreführende Vorhersagen.
Anhand des Alters kann beispielsweise wahrscheinlich vorhergesagt werden, wie krank Hunde werden, weil ältere Hunde schwerer erkranken. Dies gilt auch dafür, ob Hunde das Spielen mit einer Frisbeescheibe gelernt haben: Ältere Hunde wissen vermutlich ganz genau, wie Frisbee gespielt wird. Wenn wir age (Alter) und knows_frisbee (Frisbee-Erfahrung) als Features in unser Modell einbinden, informiert uns das Modell vermutlich darüber, dass sich anhand der Frisbee-Erfahrung eine Erkrankung vorhersagen lässt, und unterschätzt die Bedeutung des Alters. Das ist ein bisschen absurd, da die Wahrscheinlichkeit gering ist, dass durch Frisbee-Erfahrung eine Erkrankung verursacht wird. Im Gegensatz kann auch dog_breed (Hunderasse) ein guter Indikator für Erkrankungen sein, aber es gibt keinen Grund zu der Annahme, dass sich mit dem Alter die Hunderasse vorhersagen lässt. Daher können beide Features ohne Bedenken in ein Modell eingebunden werden.
Anpassungsgüte: R2
Wir wissen, dass anhand von Kostenfunktionen bewertet werden kann, wie gut ein Modell zu den Daten passt, mit denen es trainiert wurde. Modelle für die lineare Regression verfügen hierfür über die spezielle Kennzahl „R2“ (R-Quadrat, Bestimmtheitsmaß). R2 ist ein Wert zwischen 0 und 1, der angibt, wie gut ein Modell für die lineare Regression zu den Daten passt. Wenn von „starken Korrelationen“ gesprochen wird, ist damit häufig gemeint, dass der R2-Wert hoch ist.
Für R2 werden mathematische Verfahren genutzt, die über den Umfang dieses Kurses hinausgehen, aber wir können uns dies intuitiv vorstellen. In der vorherigen Übung haben wir uns die Beziehung zwischen age (Alter) und core_temperature (Körpertemperatur) angesehen. Der R2-Wert 1 bedeutet, dass anhand des Alters sicher vorhergesagt werden kann, wer eine hohe und wer eine niedrige Temperatur hatte. Im Gegensatz dazu würde der Wert 0 bedeuten, dass keinerlei Beziehung zwischen Alter und Temperatur besteht.
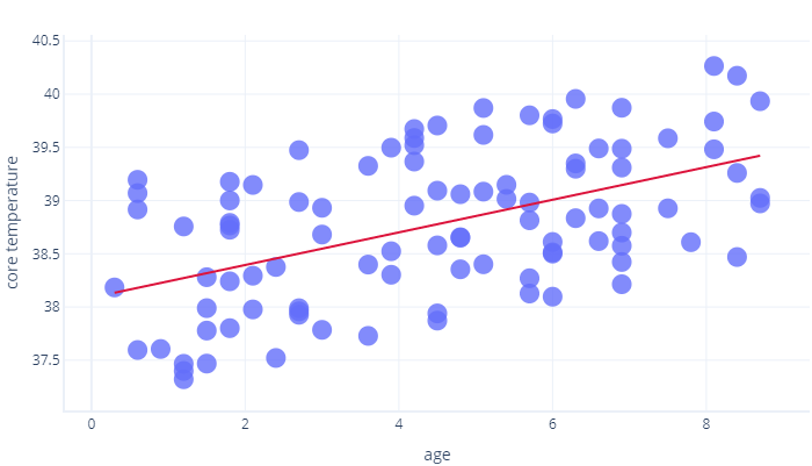
Die Wahrheit liegt irgendwo dazwischen. Unser Modell konnte die Temperatur bis zu einem gewissen Maß vorhersagen (also besser als R2 = 0), aber bei dieser Vorhersage haben sich leichte Punktabweichungen ergeben (Ergebnis unterhalb von R2 = 1).
R2 ist aber nur die halbe Wahrheit.
R2-Werte werden allgemein akzeptiert, aber sie sind keine perfekten Kennzahlen, die wir für die Isolation nutzen können. Hierfür gelten nämlich vier Einschränkungen:
- Aufgrund der Art und Weise, wie R2 berechnet wird, ist der R2-Wert umso höher, je größer die Anzahl von Stichprobenwerten ist. Dies kann zu der falschen Annahme führen, dass ein Modell besser als ein anderes (identisches) Modell ist, nur weil für die Berechnung der R2-Werte unterschiedliche Datenmengen genutzt wurden.
- Mit R2-Werten wird nicht angegeben, wie gut ein Modell in Bezug auf neue Daten funktioniert, die bisher noch nicht verwendet wurden. Statistikfachleute umgehen dies, indem sie eine zusätzliche Kennzahl (den p-Wert) berechnen, die hier aber nicht beschrieben werden kann. Beim maschinellen Lernen testen wir unser Modell häufig explizit basierend auf einem anderen Dataset.
- R2-Werte sagen nichts über die Richtung der Beziehung aus. Bei einem R2-Wert von 0,8 wissen wir beispielsweise nicht, ob die Linie nach oben oder nach unten zeigt. Wir wissen zudem nicht, wie groß die Steigung der Linie ist.
Denken Sie immer daran, dass es keine universellen Kriterien dafür gibt, wann ein R2-Wert „gut genug“ ist. In der Physik beispielsweise gelten Korrelationen, die nicht sehr nahe an 1 sind, in zumeist nicht als nützlich. Beim Modellieren komplexer Systeme dagegen können R2-Werte von 0,3 bereits als ausgezeichnet betrachtet werden.