Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Lernprogramm lernen Sie, Daten in einer Containeranwendung zu speichern. Wenn Sie sie ausführen oder aktualisieren, sind die Daten weiterhin verfügbar. Es gibt zwei Haupttypen von Volumes, die zum Speichern von Daten verwendet werden. Dieses Tutorial konzentriert sich auf benannte Volumes.
Außerdem erfahren Sie mehr über Bindungsbereitstellungen, die den genauen Bereitstellungspunkt auf dem Host steuern. Sie können Bindungsbereitstellungen verwenden, um Daten persistent zu speichern, aber es können auch weitere Daten in Containern hinzugefügt werden. Wenn Sie an einer Anwendung arbeiten, können Sie eine Bindungsbereitstellung verwenden, um Quellcode in Container einzubinden, damit Codeänderungen erkannt werden können und darauf reagiert werden kann und damit Ihnen die Änderungen sofort angezeigt werden.
In diesem Tutorial werden auch Image-Layering, die Zwischenspeicherung von Layern und mehrstufige Builds vorgestellt.
In diesem Lernprogramm erfahren Sie, wie Sie:
- Grundlegendes zu containerübergreifenden Daten
- Persistentes Speichern von Daten mithilfe benannter Volumes
- Verwenden von Bindungsbereitstellungen
- Bildebene anzeigen.
- Cacheabhängigkeiten.
- Mehrstufige Builds verstehen.
Voraussetzungen
In diesem Lernprogramm wird das vorherige Lernprogramm zum Erstellen und Freigeben einer Container-App mit Visual Studio Code fortgesetzt. Beginnen Sie mit diesem, was Voraussetzungen enthält.
Verstehen von Daten in Containern
In diesem Abschnitt beginnen Sie zwei Container und erstellen jeweils eine Datei. Die in einem Container erstellten Dateien sind in einem anderen Nicht verfügbar.
Starten Sie einen
ubuntuContainer mit diesem Befehl:docker run -d ubuntu bash -c "shuf -i 1-10000 -n 1 -o /data.txt && tail -f /dev/null"Dieser Befehl ruft mithilfe von
&&zwei Befehle auf. Der erste Teil wählt eine einzelne Zufallszahl aus und schreibt sie in/data.txt. Der zweite Befehl überwacht eine Datei, um den Container am Laufen zu halten.Klicken Sie im Container-Explorer im VS-Code mit der rechten Maustaste auf den Ubuntu-Container, und wählen Sie "Shell anfügen" aus.
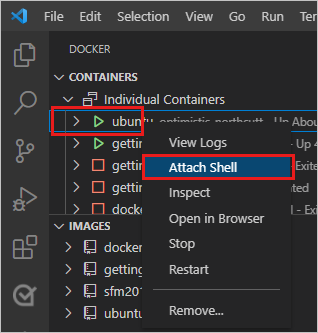
Ein Terminal wird geöffnet, das eine Shell im Ubuntu-Container ausführt.
Führen Sie den folgenden Befehl aus, um den Inhalt der
/data.txtDatei anzuzeigen.cat /data.txtDas Terminal zeigt eine Zahl zwischen 1 und 10000 an.
Wenn Sie die Befehlszeile verwenden möchten, um dieses Ergebnis anzuzeigen, rufen Sie die Container-ID mithilfe des Befehls
docker psab, und führen Sie den folgenden Befehl aus.docker exec <container-id> cat /data.txtStarten Sie einen weiteren
ubuntuContainer.docker run -d ubuntu bash -c "shuf -i 1-10000 -n 1 -o /data.txt && tail -f /dev/null"Verwenden Sie diesen Befehl, um den Ordnerinhalt anzuzeigen.
docker run -it ubuntu ls /Es sollte keine
data.txt-Datei vorhanden sein, da sie nur für den ersten Container in den Scratchspace geschrieben wurde.Wählen Sie diese beiden Ubuntu-Container aus. Klicken Sie mit der rechten Maustaste, und wählen Sie Entfernenaus. Über die Befehlszeile können Sie sie mithilfe des Befehls
docker rm -fentfernen.
Persistentes Speichern Ihrer To-do-Daten mit benannten Volumes
Standardmäßig speichert die Todo-App ihre Daten in einer SQLite-Datenbank bei /etc/todos/todo.db.
SQLite-Datenbank ist eine relationale Datenbank, die alle Daten in einer einzigen Datei speichert.
Dieser Ansatz funktioniert für kleine Projekte.
Sie können die einzelne Datei auf dem Host speichern. Wenn Sie sie für den nächsten Container verfügbar machen, kann die Anwendung an der Stelle weitermachen, an der sie unterbrochen wurde. Indem Sie ein Volume erstellen und an den Ordner anfügen oder einbinden, in dem die Daten gespeichert sind, können Sie die Daten persistent speichern. Der Container schreibt in die Datei todo.db, und diese Daten verbleiben auf dem Host im Volume.
Verwenden Sie für diesen Abschnitt ein benanntes Volume. Docker verwaltet den physischen Speicherort des Volumes auf dem Datenträger. Verweisen Sie auf den Namen des Datenvolumens, und Docker stellt die richtigen Daten bereit.
Erstellen Sie ein Volume mithilfe des Befehls
docker volume create.docker volume create todo-dbWählen Sie unter CONTAINERS die Option getting-started aus, und klicken Sie mit der rechten Maustaste darauf. Wählen Sie Stopp aus, um den App-Container anzuhalten.
Verwenden Sie den Befehl
docker stop, um den Container über die Befehlszeile zu beenden.Starten Sie den Getting-Started--Container mit dem folgenden Befehl.
docker run -dp 3000:3000 -v todo-db:/etc/todos getting-startedDer Volumenparameter gibt das Volume an, das eingehängt werden soll, und den Speicherort
/etc/todos.Aktualisieren Sie Ihren Browser, um die App neu zu laden. Wenn Sie das Browserfenster geschlossen haben, wechseln Sie zu
http://localhost:3000/. Fügen Sie Ihrer Aufgabenliste einige Elemente hinzu.
Entfernen Sie den Container getting-started für die To-do-App. Klicken Sie im Container-Explorer mit der rechten Maustaste auf den Container, und wählen Sie "Entfernen" aus, oder verwenden Sie die
docker stopBefehle.docker rmStarten Sie einen neuen Container mit demselben Befehl:
docker run -dp 3000:3000 -v todo-db:/etc/todos getting-startedMit diesem Befehl wird dasselbe Laufwerk wie zuvor bereitgestellt. Aktualisieren Sie Ihren Browser. Die hinzugefügten Elemente befinden sich weiterhin in Ihrer Liste.
Entfernen Sie den Container getting-started erneut.
Die unten erläuterten, benannten Volumes und Bindungsbereitstellungen sind die Haupttypen von Volumes, die von einer Standardinstallation der Docker-Engine unterstützt werden.
| Eigentum | Benannte Volumes | Bindungsbereitstellungen |
|---|---|---|
| Standort des Gastgebers | Auswahl durch Docker | Sie steuern |
Mount-Beispiel (mit -v) |
my-volume:/usr/local/data | /path/to/data:/usr/local/data |
| Auffüllen des neuen Volumes mit Containerinhalten | Ja | Nein |
| Unterstützung für Volumetreiber | Ja | Nein |
Es gibt viele Volumetreiber-Plug-Ins zur Unterstützung von NFS, SFTP, NetApp und mehr. Diese Plug-Ins sind besonders wichtig, Um Container auf mehreren Hosts in einer clusterierten Umgebung wie Schwarm oder Kubernetes auszuführen.
Wenn Sie sich fragen, wo Docker tatsächlich Ihre Daten speichert, führen Sie den folgenden Befehl aus.
docker volume inspect todo-db
Die Ausgabe sollte diesem Ergebnis ähneln.
[
{
"CreatedAt": "2019-09-26T02:18:36Z",
"Driver": "local",
"Labels": {},
"Mountpoint": "/var/lib/docker/volumes/todo-db/_data",
"Name": "todo-db",
"Options": {},
"Scope": "local"
}
]
Der Mountpoint ist der tatsächliche Speicherort, an dem die Daten gespeichert werden.
Auf den meisten Computern benötigen Sie Stammzugriff, um vom Host aus auf dieses Verzeichnis zuzugreifen.
Verwenden von Bindungsbereitstellungen
Mithilfe von Bindungsbereitstellungen können Sie den exakten Bereitstellungspunkt auf dem Host bestimmen. Dieser Ansatz speichert Daten, wird jedoch häufig verwendet, um mehr Daten in Containern bereitzustellen. Sie können ein Bind-Mount verwenden, um Quellcode in den Container einzubinden, damit dieser Codeänderungen erkennt und darauf reagiert, sodass Sie die Änderungen sofort sehen können.
Um Ihren Container zur Unterstützung eines Entwicklungsworkflows auszuführen, führen Sie die folgenden Schritte aus:
Entfernen Sie alle
getting-startedContainer.Führen Sie im Ordner
appden folgenden Befehl aus.docker run -dp 3000:3000 -w /app -v ${PWD}:/app node:lts-alpine sh -c "yarn install && yarn run dev"Dieser Befehl enthält die folgenden Parameter.
-
-dp 3000:3000Wie zuvor. Führen Sie den getrennten Modus aus, und erstellen Sie eine Portzuordnung. -
-w /appArbeitsverzeichnis innerhalb des Containers. -
-v ${PWD}:/app": Hier wird eine Bindungsbereitstellung für das aktuelle Verzeichnis vom Host im Container in das/app-Verzeichnis durchgeführt. -
node:lts-alpineDas zu verwendende Bild. Dieses Image ist das Basisimage für Ihre App aus dem Dockerfile . -
sh -c "yarn install && yarn run dev": Dies ist ein Befehl. Sie startet eine Shell mitshund führtyarn installaus, um alle Abhängigkeiten zu installieren. Anschließend wirdyarn run devausgeführt. Wenn Sie diepackage.json-Datei genauer ansehen, wirddevvom Skriptnodemongestartet.
-
Sie können die Protokolle mithilfe von
docker logsansehen.docker logs -f <container-id>$ nodemon src/index.js [nodemon] 2.0.20 [nodemon] to restart at any time, enter `rs` [nodemon] watching path(s): *.* [nodemon] watching extensions: js,mjs,json [nodemon] starting `node src/index.js` Using sqlite database at /etc/todos/todo.db Listening on port 3000Wenn der letzte Eintrag in dieser Liste angezeigt wird, wird die App ausgeführt.
Wenn Sie mit der Überwachung der Protokolle fertig sind, wählen Sie eine beliebige Taste im Terminalfenster aus, oder wählen Sie STRG+C- in einem externen Fenster aus.
Öffnen Sie in VS Code src/static/js/app.js. Ändern Sie den Text der Schaltfläche Element hinzufügen in Zeile 109.
- {submitting ? 'Adding...' : 'Add Item'} + {submitting ? 'Adding...' : 'Add'}Speichern Sie Ihre Änderung.
Aktualisieren Sie Ihren Browser. Du solltest die Änderung sehen.

Entfernen Sie den
node:lts-alpineContainer.Führen Sie im
appOrdner den folgenden Befehl aus, um dennode_modulesOrdner zu entfernen, der in den vorherigen Schritten erstellt wurde.rm -r node_modules
Bildebenen anzeigen
Sie können sich die Ebenen ansehen, aus denen ein Bild besteht.
Führen Sie den Befehl docker image history aus, um den Befehl anzuzeigen, der zum Erstellen der einzelnen Ebenen in einem Image verwendet wurde.
Verwenden Sie
docker image history, um die Ebenen im Getting-Started Bild anzuzeigen, das Sie zuvor im Tutorial erstellt haben.docker image history getting-startedIhr Ergebnis sollte diesem Ergebnis ähneln.
IMAGE CREATED CREATED BY SIZE COMMENT a78a40cbf866 18 seconds ago /bin/sh -c #(nop) CMD ["node" "/app/src/ind… 0B f1d1808565d6 19 seconds ago /bin/sh -c yarn install --production 85.4MB a2c054d14948 36 seconds ago /bin/sh -c #(nop) COPY dir:5dc710ad87c789593… 198kB 9577ae713121 37 seconds ago /bin/sh -c #(nop) WORKDIR /app 0B b95baba1cfdb 13 days ago /bin/sh -c #(nop) CMD ["node"] 0B <missing> 13 days ago /bin/sh -c #(nop) ENTRYPOINT ["docker-entry… 0B <missing> 13 days ago /bin/sh -c #(nop) COPY file:238737301d473041… 116B <missing> 13 days ago /bin/sh -c apk add --no-cache --virtual .bui… 5.35MB <missing> 13 days ago /bin/sh -c #(nop) ENV YARN_VERSION=1.21.1 0B <missing> 13 days ago /bin/sh -c addgroup -g 1000 node && addu… 74.3MB <missing> 13 days ago /bin/sh -c #(nop) ENV NODE_VERSION=12.14.1 0B <missing> 13 days ago /bin/sh -c #(nop) CMD ["/bin/sh"] 0B <missing> 13 days ago /bin/sh -c #(nop) ADD file:e69d441d729412d24… 5.59MBJede der Linien stellt eine Ebene im Bild dar. Die Ausgabe zeigt die Basis unten mit der neuesten Ebene oben an. Mithilfe dieser Informationen können Sie die Größe jeder Ebene sehen und dabei helfen, große Bilder zu diagnostizieren.
Mehrere der Zeilen werden abgeschnitten. Wenn Sie den parameter
--no-trunchinzufügen, erhalten Sie die vollständige Ausgabe.docker image history --no-trunc getting-started
Cacheabhängigkeiten
Sobald sich eine Ebene ändert, müssen auch alle nachgelagerten Schichten neu erstellt werden. Hier sehen Sie erneut das Dockerfile:
FROM node:lts-alpine
WORKDIR /app
COPY . .
RUN yarn install --production
CMD ["node", "/app/src/index.js"]
Jeder Befehl in der Dockerfile- wird zu einer neuen Ebene im Image.
Um die Anzahl der Ebenen zu minimieren, können Sie Ihre Dockerfile- umstrukturieren, um das Zwischenspeichern von Abhängigkeiten zu unterstützen.
Bei Knotenbasierten Anwendungen werden diese Abhängigkeiten in der Datei package.json definiert.
Der Ansatz besteht darin, zuerst nur diese Datei zu kopieren; die Abhängigkeiten zu installieren und dann alles andere zu kopieren.
In diesem Prozess werden die Yarn-Abhängigkeiten nur erneut erstellt, wenn eine Änderung an package.json vorgenommen wurde.
Aktualisieren Sie das Dockerfile, damit zuerst
package.jsonkopiert wird, installieren Sie anschließend die Abhängigkeiten, und kopieren Sie daraufhin den Rest. Hier ist die neue Datei:FROM node:lts-alpine WORKDIR /app COPY package.json yarn.lock ./ RUN yarn install --production COPY . . CMD ["node", "/app/src/index.js"]Erstellen Sie ein neues Image mit
docker build.docker build -t getting-started .Die Ausgabe sollte wie die folgenden Ergebnisse aussehen:
Sending build context to Docker daemon 219.1kB Step 1/6 : FROM node:lts-alpine ---> b0dc3a5e5e9e Step 2/6 : WORKDIR /app ---> Using cache ---> 9577ae713121 Step 3/6 : COPY package* yarn.lock ./ ---> bd5306f49fc8 Step 4/6 : RUN yarn install --production ---> Running in d53a06c9e4c2 yarn install v1.17.3 [1/4] Resolving packages... [2/4] Fetching packages... info fsevents@1.2.9: The platform "linux" is incompatible with this module. info "fsevents@1.2.9" is an optional dependency and failed compatibility check. Excluding it from installation. [3/4] Linking dependencies... [4/4] Building fresh packages... Done in 10.89s. Removing intermediate container d53a06c9e4c2 ---> 4e68fbc2d704 Step 5/6 : COPY . . ---> a239a11f68d8 Step 6/6 : CMD ["node", "/app/src/index.js"] ---> Running in 49999f68df8f Removing intermediate container 49999f68df8f ---> e709c03bc597 Successfully built e709c03bc597 Successfully tagged getting-started:latestAlle Ebenen wurden neu erstellt. Dieses Ergebnis wird erwartet, da Sie das Dockerfile geändert haben.
Nehmen Sie eine Änderung an src/static/index.html vor. Ändern Sie beispielsweise den Titel in "The Awesome Todo App".
Erstellen Sie das Docker-Image jetzt mit
docker builderneut. Diesmal sollte Ihre Ausgabe etwas anders aussehen.Sending build context to Docker daemon 219.1kB Step 1/6 : FROM node:lts-alpine ---> b0dc3a5e5e9e Step 2/6 : WORKDIR /app ---> Using cache ---> 9577ae713121 Step 3/6 : COPY package* yarn.lock ./ ---> Using cache ---> bd5306f49fc8 Step 4/6 : RUN yarn install --production ---> Using cache ---> 4e68fbc2d704 Step 5/6 : COPY . . ---> cccde25a3d9a Step 6/6 : CMD ["node", "/app/src/index.js"] ---> Running in 2be75662c150 Removing intermediate container 2be75662c150 ---> 458e5c6f080c Successfully built 458e5c6f080c Successfully tagged getting-started:latestDa Sie den Buildcache verwenden, sollte es viel schneller gehen.
Mehrstufige Builds
Mehrstufige Builds sind ein unglaublich leistungsfähiges Tool, mit dem Sie mehrere Phasen zum Erstellen eines Images verwenden können. Es gibt mehrere Vorteile für sie:
- Abgrenzen von Abhängigkeiten zur Buildzeit von Laufzeitabhängigkeiten
- Verringern der Gesamtbildgröße, indem Sie nur das versenden, was Ihre App ausführen muss
Dieser Abschnitt enthält kurze Beispiele.
Beispiel für Maven/Tomcat
Wenn Sie Java-basierte Anwendungen erstellen, wird ein JDK benötigt, um den Quellcode in Java-Bytecode zu kompilieren. Das JDK wird in der Produktion nicht benötigt. Möglicherweise verwenden Sie Tools wie Maven oder Gradle, um die App zu erstellen. Diese Tools werden auch in Ihrem endgültigen Image nicht benötigt.
FROM maven AS build
WORKDIR /app
COPY . .
RUN mvn package
FROM tomcat
COPY --from=build /app/target/file.war /usr/local/tomcat/webapps
In diesem Beispiel wird eine Phase buildverwendet, um den tatsächlichen Java-Build mit Maven auszuführen.
Die zweite Phase, beginnend mit "FROM tomcat", kopiert Dateien aus der build-Phase.
Das endgültige Bild ist nur die letzte Erstellungsphase, die mit dem parameter --target überschrieben werden kann.
React-Beispiel
Beim Erstellen von React-Anwendungen benötigen Sie eine Node-Umgebung, um den JavaScript-Code, Sass-Stylesheets und vieles mehr in statisches HTML, JavaScript und CSS zu kompilieren. Wenn Sie kein serverseitiges Rendering durchführen, benötigen Sie nicht einmal eine Node-Umgebung für den Produktionsbuild.
FROM node:lts-alpine AS build
WORKDIR /app
COPY package* yarn.lock ./
RUN yarn install
COPY public ./public
COPY src ./src
RUN yarn run build
FROM nginx:alpine
COPY --from=build /app/build /usr/share/nginx/html
In diesem Beispiel wird ein node:lts-alpine-Image verwendet, um den Build auszuführen, wodurch die Layerzwischenspeicherung maximiert wird, und anschließend wird die Ausgabe in einen nginx- container kopiert.
Bereinigen von Ressourcen
Bewahren Sie alles auf, was Sie bisher getan haben, um diese Reihe von Tutorials fortzusetzen.
Nächste Schritte
Sie haben die Optionen zum Speichern von Daten für Container-Apps kennengelernt.
Was möchten Sie als Nächstes tun?
Arbeiten mit mehreren Containern mithilfe von Docker Compose:
Erstellen von Multicontainer-Apps mit MySQL und Docker Compose
Bereitstellen in Azure Container Apps:
Bereitstellung auf Azure App Service