Indizierungsprozess in Windows Search
In diesem Thema werden die drei Phasen des Indizierungsprozesses und die jeweils beteiligten primären Komponenten beschrieben, der Zeitpunkt der Indizierungsaktivität erläutert und einige Hinweise für Entwickler von Drittanbietern bereitgestellt, die ihre Datenspeicher oder Dateiformate indizieren möchten.
Dieses Thema ist wie folgt organisiert:
- Übersicht
- Phase 1: Warteschlangen für URLs für die Indizierung
- Phase 2: Durchforsten von URLs
- Phase 3: Aktualisieren des Indexes
- Geplante Indizierung
- Hinweise für Ausführende
- Zugehörige Themen
Übersicht
Windows Search unterstützt die Indizierung von Eigenschaften und Inhalten aus Dateien verschiedener Dateiformate, z. B. .doc- oder JPEG-Formaten, und Datenspeichern wie dem Dateisystem oder Windows Outlook-Postfächern. Es gibt zwei Arten von Indizes: Wertindizes, die das Filtern und Sortieren nach dem gesamten Wert einer Eigenschaft ermöglichen, und invertierte Indizes, die Wörter innerhalb von Texteigenschaften oder Inhalten indizieren. Wenn Sie über ein benutzerdefiniertes Dateiformat oder einen benutzerdefinierten Datenspeicher verfügen, müssen Sie verstehen, wie Windows Search-Indizes verwendet werden, um Ihre Elemente ordnungsgemäß indiziert zu bekommen.
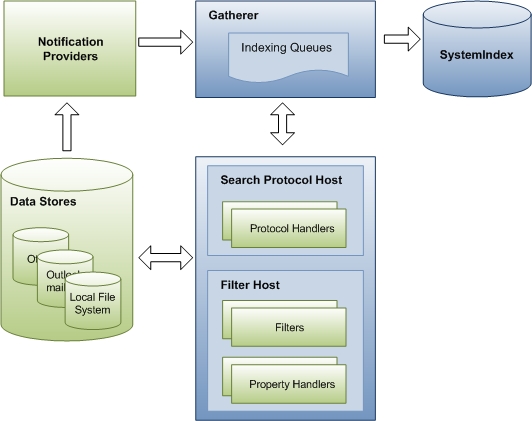
Der Indizierungsprozess erfolgt in drei Phasen, die von einer Windows Search-Komponente namens Gatherer gesteuert werden. In der ersten Phase fügt der Gatherer URLs zu Warteschlangen hinzu. Die URLs identifizieren elemente, die indiziert werden sollen, und die Warteschlangen sind nur priorisierte Listen von URLs. In der zweiten Phase koordiniert der Gatherer andere Windows Search- und Drittanbieterkomponenten, um auf die Elemente zuzugreifen und Daten darüber zu sammeln. Schließlich werden in der dritten Phase die gesammelten Daten dem Index hinzugefügt.
Das folgende Diagramm zeigt die Hauptkomponenten und den Datenfluss durch den Indizierungsprozess. Am Sammeln von Daten für den Index sind mehrere Komponenten beteiligt. Einige davon sind Teil von Windows Search, und einige stammen aus Anwendungen von Drittanbietern. Wenn Sie über einen benutzerdefinierten Datenspeicher oder ein benutzerdefiniertes Dateiformat verfügen, basiert Windows Search auf Ihrem Protokollhandler und filtert für den Zugriff auf URLs und das Ausgeben von Eigenschaften für die Indizierung. Windows Search-Komponenten werden blau und Komponenten von Drittanbietern grün angezeigt.
Phase 1: Warteschlangen für URLs für die Indizierung
In der ersten Phase der Indizierung sammelt der Gatherer Informationen zu Aktualisierungen an Datenspeichern, vergleicht diese Informationen mit dem bekannten Durchforstungsbereich und erstellt dann eine Warteschlange mit URLs zum Durchlaufen, um Daten für den Index zu sammeln. Für Quellen, die nicht auf Benachrichtigungen basieren, z. B. FAT-Laufwerke, initiiert der Gatherer in regelmäßigen Abständen eine vollständige Durchforstung des Durchforstungsbereichs, damit die Daten im Index aktuell bleiben. Für Quellen wie NTFS gibt es nur eine einzige Durchforstung, und alles andere wird von Benachrichtigungen aus dem USN Change Journal verarbeitet. Es gibt auch keine Durchforstung von Microsoft Outlook. Das folgende Diagramm zeigt eine allgemeine Ansicht des Warteschlangenprozesses für nicht durchforstete Indizierung.
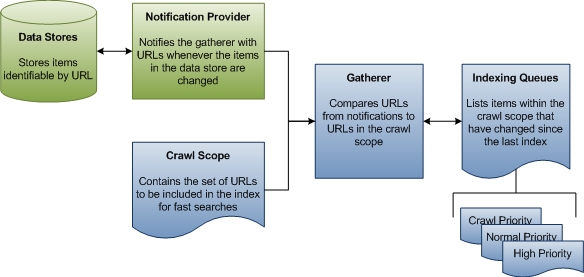
Im weiteren Verlauf dieses Abschnitts wird erläutert, wie Windows Search bestimmt, welche URLs durchforstet werden sollen, und definiert dabei einige wichtige Begriffe.
Durchforstungsbereich Der Durchforstungsbereich besteht aus einer Reihe von URLs, die Windows Search durchläuft, um Daten zu Elementen zu sammeln, die der Benutzer für schnellere Suchvorgänge indiziert haben möchte. Windows Search fügt dem Durchforstungsbereich standardmäßig einige URLs hinzu, z. B. Pfade zu den Ordnern Dokumente und Bilder von Benutzern. Andere URLs können von Drittanbieteranwendungen, Benutzern und Gruppenrichtlinie hinzugefügt werden. Schließlich können sowohl Benutzer als auch Gruppenrichtlinie URLs explizit ausschließen. Windows Search akzeptiert alle hinzugefügten URLs und entfernt die ausgeschlossenen URLs, um den Durchforstungsbereich zu bestimmen. Dies ist der Arbeitssatz von URLs, aus denen der Gatherer seine Arbeit beginnt.
Gatherer Der Gatherer ist eine Windows Search-Komponente, die Informationen zu URLs innerhalb des Durchforstungsbereichs sammelt und eine Warteschlange mit URLs erstellt, die der Indexer durchforstet. Wenn ein Element im Durchforstungsbereich hinzugefügt, gelöscht oder aktualisiert wird, wird der Gatherer vom Benachrichtigungsanbieter des Datenspeichers benachrichtigt. Es gibt eine erste Durchforstung, bei der der Gatherer am Stamm des Durchforstungsbereichs beginnt. Die URL wird an den Protokollhandler und dann an den entsprechenden IFilter übergeben. Der Filter ist in der Regel eine Verzeichnisaufzählung, die mehr URLs erzeugt. Benachrichtigungen sind der stabile Zustand. In der Regel verfügt jeder Datenspeicher über einen eigenen Protokollhandler, der diese Benachrichtigungen bereitstellt. Beispielsweise fungiert das USN Change Journal im lokalen Dateisystem als Benachrichtigungsanbieter für alle URLs unter dem file://-Protokoll. Ebenso fungiert Microsoft Outlook als Benachrichtigungsanbieter für alle URLs unter dem mapi://-Protokoll. Wenn ein Benutzer E-Mails empfängt, verschiebt oder löscht, benachrichtigt Outlook den Gatherer über die geänderte status der E-Mail. Anhand dieser Benachrichtigungen erstellt der Gatherer Indizierungswarteschlangen von URLs, die durchforstet werden sollen.
Indizieren von Warteschlangen Die Indizierungswarteschlangen sind Listen von URLs, die Elemente identifizieren, die indiziert oder neu indiziert werden müssen. Der Gatherer vergleicht die URLs, die er von Benachrichtigungsanbietern erhält, mit den URLs im Durchforstungsbereich. Jede URL von Benachrichtigungsanbietern, die in den Durchforstungsbereich fällt, wird einer Warteschlange hinzugefügt, die der Gatherer verwendet, um zu priorisieren, welche URLs als Nächstes verarbeitet werden sollen.
Es gibt drei Warteschlangen: Benachrichtigungen mit hoher Priorität, normale Benachrichtigungen und regelmäßige Durchforstungen. Die Warteschlange mit hoher Priorität ist für Benachrichtigungen vorgesehen, die sofort verarbeitet werden sollen. Wenn ein Benutzer beispielsweise die Title-Eigenschaft eines Elements in Windows Explorer ändert, muss die Ansicht windows Explorer unmittelbar nach der Änderung aktualisiert werden. Die normale Benachrichtigungswarteschlange gilt für alle verbleibenden Änderungsbenachrichtigungen. Die Benachrichtigungswarteschlangen werden vor der Durchforstungswarteschlange verarbeitet, da geänderte Elemente für einen Benutzer wahrscheinlicher von Interesse sind. Der Gatherer greift auf Daten für die URLs in jeder Warteschlange in fiFO-Reihenfolge (First In, First Out) zu.
Weitere Informationen zu Priorisierungs- und Ereignis-APIs, die in Windows 7 eingeführt wurden, finden Sie unter Indizierungspriorisierungs- und Rowsetereignisse in Windows 7. Weitere Informationen zur Verwaltung des Durchforstungsbereichs und zu Benachrichtigungen finden Sie unter Bereitstellen von Änderungsbenachrichtigungen und Verwenden des Durchforstungsbereichs-Managers.
Phase 2: Durchforsten von URLs
In der zweiten Indizierungsphase durchforstet der Gatherer die Warteschlangen, greift auf Datenspeicher und ruft Elementdatenströme ab. Zunächst sucht der Gatherer den entsprechenden Protokollhandler für jede URL. Anschließend übergibt der Gatherer die URL an den Protokollhandler. Der Protokollhandler greift auf das Element zu und übergibt Elementmetadaten zurück an den Gatherer. Der Gatherer verwendet die Metadaten, um den richtigen Filter zu identifizieren.
Das folgende Diagramm zeigt eine allgemeine Ansicht des URL-Durchforstungsprozesses. Diese Phase umfasst eine erhebliche Koordinierung und Kommunikation zwischen den Komponenten.
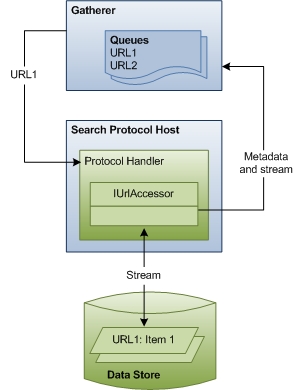
Im weiteren Verlauf dieses Abschnitts wird beschrieben, wie Windows Search auf Elemente für die Indizierung zugreift, und die Rollen der einzelnen beteiligten Komponenten werden erläutert.
Gatherer In Phase 2, der Durchforstungsphase, verarbeitet der Gatherer die URLs in den Warteschlangen, beginnend mit der Warteschlange mit hoher Priorität. Jede URL wird untersucht, um ihr Protokoll zu identifizieren. Der Gatherer sucht dann den für dieses Protokoll registrierten Protokollhandler und instanziiert ihn im Suchprotokollhostprozess.
Suchprotokollhost Der Suchprotokollhost ist lediglich ein geschachtelter Hostprozess für Protokollhandler. In der Regel erstellt Windows Search zwei solche Hostprozesse, einen, der im Systemsicherheitskontext ausgeführt wird, und einen, der im Benutzersicherheitskontext ausgeführt wird. Durch diese Trennung wird sichergestellt, dass benutzerspezifische Daten niemals im Systemkontext ausgeführt werden.
Windows Search verwendet auch den Hostprozess, um eine instance eines Protokollhandlers von anderen Prozessen oder Anwendungen zu isolieren. Auf diese Weise kann keine externe Anwendung auf diese spezifische instance des Protokollhandlers zugreifen, und wenn der Protokollhandler unerwartet fehlschlägt, ist nur der Indizierungsprozess betroffen. Da der Hostprozess Code von Drittanbietern (Protokollhandler) ausführt, verwendet Windows Search den Prozess in regelmäßigen Abständen, um die Zeit zu minimieren, die ein erfolgreicher Angriff für die Ausnutzung von Informationen im Prozess hat. Darüber hinaus wirkt sich der Suchprotokollhost nicht auf das Durchforsten von URLs oder die Indizierung von Elementen aus.
Protokollhandler Protokollhandler ermöglichen den Zugriff auf Elemente in einem Datenspeicher mithilfe des Protokolls des Datenspeichers. Der NTFS-Protokollhandler ermöglicht beispielsweise mithilfe des file://-Protokolls Zugriff auf Dateien auf einem lokalen Laufwerk. Der Protokollhandler weiß, wie er den Datenspeicher durchläuft, neue oder aktualisierte Elemente identifiziert und den Gatherer benachrichtigt. Wenn die Durchforstung beginnt, stellt der Protokollhandler dem Gatherer ein IUrlAccessor-Objekt bereit, um an den zugrunde liegenden Datenstrom des Elements zu binden und Elementmetadaten wie Sicherheitseinschränkungen und zeitpunkt der letzten Änderung zurückzugeben.
Hinweis
Protokollhandler sind keine Windows Search-Komponenten. Sie sind Komponenten des spezifischen Protokolls und Datenspeichers, auf das sie zugreifen sollen. Wenn Sie über einen benutzerdefinierten Datenspeicher verfügen, den Sie indizieren möchten, müssen Sie einen Protokollhandler implementieren. Weitere Informationen zu Protokollhandlern und deren Implementierung finden Sie unter Developing Protocol Handlers (Entwickeln von Protokollhandlern).
Metadaten und Stream Mithilfe von Metadaten, die vom IUrlAccessor-Objekt des Protokollhandlers zurückgegeben werden, identifiziert der Gatherer den richtigen Filter für die URL. Der Gatherer analysiert die Dateinamenerweiterung des Elements und sucht den filter, der für diese Erweiterung registriert ist. Wenn der Gatherer keinen Filter finden kann, verwendet Windows Search die Metadaten, um einen minimalen Satz von Systemeigenschafteninformationen (z. B. System.ItemName) abzuleiten und den Index zu aktualisieren. Wenn der Gatherer den Filter findet, beginnt andernfalls die dritte Indizierungsphase.
Phase 3: Aktualisieren des Indexes
In der dritten Indizierungsphase instanziiert der Gatherer den richtigen Filter für die URL und initialisiert den Filter mit dem Stream aus dem IUrlAccessor-Objekt . Der Filter greift dann auf das Element zu und gibt Inhalt für den Index zurück. Wenn Sie über ein benutzerdefiniertes Dateiformat verfügen, basiert Windows Search auf Ihrem Filter, um auf URLs zuzugreifen und Inhalte und Eigenschaften für die Indizierung auszugeben.
Das folgende Diagramm zeigt eine allgemeine Ansicht des Datenzugriffsprozesses. Diese Phase umfasst eine erhebliche Koordinierung und Kommunikation zwischen den Komponenten.
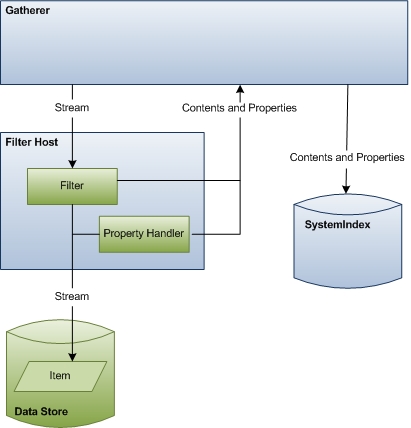
Im weiteren Verlauf dieses Abschnitts wird beschrieben, wie Windows Search auf Elementdaten für die Indizierung zugreift, und die Rollen der einzelnen beteiligten Komponenten werden erläutert.
Gatherer Zu Beginn dieser Phase besteht die Rolle des Gatherers darin, den richtigen Filter für das Element zu instanziieren und es an den Elementstream zu übergeben. Am Ende dieser Phase übernimmt der Gatherer den Inhalt und die Eigenschaften, die vom Filter und Eigenschaftenhandler ausgegeben werden, und aktualisiert den Index.
Filterhost Der Filterhost ist lediglich ein Hostprozess für Filter und Eigenschaftenhandler und dient einem Zweck, der dem Suchprotokollhost ähnelt. Der Hostprozess isoliert Filter und Eigenschaftshandler vom Rest des Systems aus denselben Sicherheits- und Stabilitätsgründen, aus denen Suchprotokollhostprozesse Protokollhandler isolieren. Der Hostprozess wird mit minimalen Rechten ausgeführt (er kann nicht einmal auf das Dateisystem zugreifen) und wird gelegentlich zum Schutz vor Sicherheitsangriffen wiederverwendet. Windows Search überwacht auch die Ressourcennutzung, sodass der Hostprozess wiederverwendet wird, wenn ein Filter zu viele Ressourcen verbraucht.
Filter Filter sind wichtige Komponenten im Indizierungsprozess, die Elementinformationen für den Gatherer ausgeben. Filter werden nach der Prinzipalschnittstelle benannt, die in ihrer Implementierung verwendet wird, der IFilter-Schnittstelle , und werden daher manchmal als IFilter bezeichnet. Es gibt zwei Arten von Filtern: einer, der mit einzelnen Elementen wie Dateien interagiert, und einer, der mit Containern wie Ordnern interagiert. Beide stellen Daten für den Index bereit.
Mithilfe von Metadaten, die vom IUrlAccessor-Objekt des Protokollhandlers zurückgegeben werden, identifiziert der Gatherer den richtigen Filter für eine bestimmte URL und übergibt ihn an den Stream. Der Gatherer identifiziert den richtigen Filter entweder über einen Protokollhandler oder über die Dateinamenerweiterung, den MIME-Typ oder den Klassenbezeichner (CLSID). Wenn die URL auf einen Container verweist, gibt der Filter Eigenschaften für den Container aus und listet die Elemente im Container auf (untergeordnete URLs). Wenn die URL auf ein Element zeigt, gibt der Filter den Textinhalt zurück, wenn eigenschaften gelesen werden und komplexer sind als Eigenschaftenhandler. Im Allgemeinen wird empfohlen, dass Filter Elementinhalte ausgeben, während Eigenschaftenhandler Elementeigenschaften ausgeben. Wenn Ihr Filter jedoch mit älteren Anwendungen arbeiten muss, die keine Eigenschaftenhandler erkennen, können Sie den Filter auch implementieren, um Eigenschaften ausgibt.
Hinweis
Filter sind keine Windows Search-Komponenten. Sie sind Komponenten, die sich auf das spezifische Dateiformat oder den spezifischen Container beziehen, auf das bzw. den sie zugreifen sollen. Weitere Informationen zu Filtern und zum Implementieren von Filtern für ein benutzerdefiniertes Dateiformat oder einen benutzerdefinierten Container finden Sie unter Bewährte Methoden zum Erstellen von Filterhandlern in der Windows-Suche.
In der folgenden Tabelle sind die Ergebnisse aufgeführt, die der Gatherer während des Indizierungsprozesses von einem Filter (IFilter) und einem Eigenschaftenhandler (IPropertyStore) empfängt.
| Ifilter | Ipropertystore | |
|---|---|---|
| Schreibvorgänge zulassen | Nein | Ja |
| Kombinieren von Inhalten und Eigenschaften | Ja | Nein |
| Mehrsprachige | Ja | Nein |
| Ausgeben von Links | Ja | Nein |
| MIME | Ja | Nein |
| Textgrenzen | Satz, Absatz, Kapitel | Keine |
| Client/Server | Beide | Client |
| Implementierung | Complex | Einfach |
Eigenschaftenhandler Eigenschaftenhandler sind Komponenten, die Eigenschaften für ein bestimmtes Dateiformat lesen und schreiben. Sie greifen auf Elemente zu und geben Eigenschaften für den Gatherer auf die gleiche Weise wie Filter für Inhalte aus. Eigenschaftenhandler sind einfacher zu implementieren als Filter. Wenn ein textbasiertes Dateiformat sehr einfach ist oder die Dateien sehr klein sein sollen, kann der Eigenschaftenhandler sowohl Eigenschaften als auch Inhalte ausgeben.
Hinweis
Eigenschaftenhandler sind keine Windows Search-Komponenten. Sie sind Komponenten, die sich auf das spezifische Dateiformat beziehen, auf das sie zugreifen sollen. Weitere Informationen zu Eigenschaftenhandlern und zum Implementieren eines für ein benutzerdefiniertes Dateiformat finden Sie unter Developing Property Handlers for Windows Search.
Eigenschaften Windows Search stellt ein Eigenschaftensystem bereit, das eine große Bibliothek von Eigenschaften enthält. Jede Eigenschaft kann in jedem Element angezeigt werden, wie vom Filter oder Eigenschaftenhandler definiert. Wenn Sie über ein benutzerdefiniertes Dateiformat verfügen, können Sie die Eigenschaften Ihres Dateiformats diesen Systemeigenschaften zuordnen und neue benutzerdefinierte Eigenschaften erstellen. Wenn der Filter oder Eigenschaftenhandler diese Eigenschaften ausgibt, aktualisiert der Gatherer den Index, damit Benutzer mithilfe Ihrer Eigenschaften suchen können. Weitere Informationen zum Erstellen und Registrieren benutzerdefinierter Eigenschaften für ein Dateiformat finden Sie unter Eigenschaftensystem.
SystemIndex Der Index namens SystemIndex speichert indizierte Daten und besteht aus einem Eigenschaftenspeicher und Indizes für die Eigenschaften und inhalte für Elementeigenschaften sowie einem invertierten Index für Textinhalte und Eigenschaften. Nachdem der Gatherer den Index aktualisiert hat, kann der Index von Windows Search und anderen Anwendungen abgefragt werden. Weitere Informationen zu Methoden zum Abfragen des Index finden Sie unter Programmgesteuertes Abfragen des Indexes.
Hinweis
Beachten Sie, dass Änderungen, die an Attributen zuvor definierter Eigenschaften vorgenommen wurden, beim erneuten Registrieren eines Schemas möglicherweise nicht vom Indexer berücksichtigt werden. Die Lösung besteht entweder darin, den Index neu zu erstellen oder neue Eigenschaften einzuführen, die die Änderungen widerspiegeln, anstatt alte zu aktualisieren (nicht empfohlen). Weitere Informationen finden Sie unter Hinweis zu Implementern in der Übersicht über das Eigenschaftensystem.
Geplante Indizierung
Wenn Windows Search zum ersten Mal installiert wird, führt sie eine vollständige Indizierung des Durchforstungsbereichs durch und wird in Zeiten hoher E/A- und Benutzeraktivität angehalten. Der Standarddurchforstungsbereich besteht aus den Standardspeicherorten der Bibliothek, z. B. Dokumente, Musik, Bilder und Videos. Benachrichtigungen werden verarbeitet, bevor die erste Durchforstung abgeschlossen ist. Gelegentlich durchforstet der Gatherer die URLs aus dem vollständigen Durchforstungsbereich. Diese vollständigen Durchforstungen stellen sicher, dass die Daten im Index aktuell sind. Wenn beispielsweise ein Benachrichtigungsanbieter keine Benachrichtigungen sendet oder die Windows-Suchdienst unerwartet beendet wird, hat der Gatherer keine Kenntnisse über neue oder geänderte Elemente und würde diese Elemente nicht indizieren. Es gibt zwei Arten von Quellen: nur Benachrichtigung und aktivierte Benachrichtigungen. In beiden Quellen durchforstet der Gatherer zunächst den Index. Nach der ersten Durchforstung führen die nur benachrichtigungsbasierten Quellen nie wieder eine vollständige Durchforstung durch, es sei denn, es tritt ein Fehler auf, z. B. das Rollover des USN Change Journals . Benachrichtigungsfähige Quellen führen beim Starten des Indexers eine inkrementelle Durchforstung durch, lauschen dann aber während der Ausführung auf Benachrichtigungen. NTFS und Microsoft Outlook sind nur Benachrichtigungen. Internet Explorer und FAT sind Benachrichtigungen aktiviert.
Hinweise für Ausführende
Die Qualität der Daten im Index und die Effizienz des Indizierungsprozesses hängen weitgehend von Ihrer Filter- und Eigenschaftenhandlerimplementierung ab. Da der Filter jedes Mal aufgerufen wird, wenn eine URL Ihr Dateiformat identifiziert, kann sich der Indizierungsprozess erheblich verlangsamen, wenn der Filter ineffizient ist. Wenn der Eigenschaftenhandler nicht alle Dateieigenschaften den Systemeigenschaften korrekt zuzuordnen oder diese Eigenschaften nicht ordnungsgemäß ausgibt, sind die Daten im Index falsch, und später werden bei der Suche nach diesen Eigenschaften falsche Ergebnisse zurückgegeben. Wenn der Filter- oder Eigenschaftenhandler fehlschlägt, kann der Indexer keine Daten indizieren.
Andere Anwendungen und Prozesse als Windows Search basieren auf Protokollhandlern, Filtern und Eigenschaftenhandlern. Ihre Implementierungen können sich auf diese Anwendungen auf eine Weise auswirken, die Sie möglicherweise nicht erwarten. Der Windows Search-Entwicklungsleitfaden enthält Empfehlungen zu Entwurfsentscheidungen und zum Testen jeder dieser Komponenten.
Zugehörige Themen
Indizieren, Abfragen und Benachrichtigungen in der Windows-Suche
Abfrageprozess in Windows Search
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für