Σημείωμα
Η πρόσβαση σε αυτήν τη σελίδα απαιτεί εξουσιοδότηση. Μπορείτε να δοκιμάσετε να εισέλθετε ή να αλλάξετε καταλόγους.
Η πρόσβαση σε αυτήν τη σελίδα απαιτεί εξουσιοδότηση. Μπορείτε να δοκιμάσετε να αλλάξετε καταλόγους.
Ο εγγενής μηχανισμός εκτέλεσης είναι μια πρωτοποριακή βελτίωση για εκτελέσεις εργασιών Apache Spark στο Microsoft Fabric. Αυτός ο διανυσματικός μηχανισμός βελτιστοποιεί την απόδοση και την αποδοτικότητα των ερωτημάτων Spark εκτελώντας τα απευθείας στην υποδομή lakehouse σας. Η απρόσκοπτη ενοποίηση της μηχανής σημαίνει ότι δεν απαιτεί τροποποιήσεις κώδικα και αποτρέπει το κλείδωμα προμηθευτή. Υποστηρίζει Apache Spark API και είναι συμβατό με Runtime 1.3 (Apache Spark 3.5) και Runtime 2.0 (Apache Spark 4.1) και λειτουργεί με μορφές Parquet, Delta και CSV. Ανεξάρτητα από τη θέση των δεδομένων σας στο OneLake ή εάν αποκτάτε πρόσβαση σε δεδομένα μέσω συντομεύσεων, ο εγγενής μηχανισμός εκτέλεσης μεγιστοποιεί την αποτελεσματικότητα και τις επιδόσεις.
Ο εγγενής μηχανισμός εκτέλεσης αυξάνει σημαντικά την απόδοση των ερωτημάτων, ελαχιστοποιώντας παράλληλα το κόστος λειτουργίας. Τα πραγματικά αποτελέσματα διαφέρουν ανάλογα με τα χαρακτηριστικά του φόρτου εργασίας και τη διαμόρφωση. Η μηχανή είναι έμπειρη στη διαχείριση μιας μεγάλης γκάμας σεναρίων επεξεργασίας δεδομένων, που κυμαίνονται από συνήθεις προσλήψεις δεδομένων, εργασίες δέσμης και εργασίες ETL (εξαγωγή, μετασχηματισμός, φόρτωση), έως σύνθετες αναλύσεις επιστήμης δεδομένων και δυναμικά αλληλεπιδραστικά ερωτήματα. Οι χρήστες επωφελούνται από τους επιταχυνόμενους χρόνους επεξεργασίας, την αυξημένη ταχύτητα μετάδοσης και τη βελτιστοποιημένη χρήση πόρων.
Ο εγγενής μηχανισμός εκτέλεσης βασίζεται σε δύο βασικά στοιχεία του OSS: το Velox, μια βιβλιοθήκη επιτάχυνσης βάσης δεδομένων C++ που παρουσιάστηκε από τη Meta και το Apache Meta (incubating), ένα μεσαίο επίπεδο που ευθύνεται για τη μείωση της φόρτωσης της εκτέλεσης κινητήρων SQL που βασίζονται σε JVM σε εγγενείς κινητήρες που εισήγαγε η Intel.
Οι υποστηριζόμενοι χειριστές εκφορτώνονται από το Spark που βασίζεται σε JVM σε μια διανυσματική διαδρομή εκτέλεσης C++, παρέχοντας στηλοειδή, επιταχυνόμενη επεξεργασία SIMD με εγγενή υποστήριξη για μορφές Parquet και Delta. Ο εγγενής μηχανισμός διατηρεί βασικές βελτιστοποιήσεις ερωτημάτων Fabric Spark, συμπεριλαμβανομένης της προσαρμοστικής εκτέλεσης ερωτημάτων (AQE), των επανεγγραφών βάσει κόστους, της περικοπής στηλών και της προώθησης κατηγορημάτων, έτσι ώστε αυτές οι συμπεριφορές βελτιστοποίησης να παραμένουν πλήρως ενεργές όταν οι χειριστές εκφορτώνονται. Ο κινητήρας υποστηρίζει επίσης παράλληλη φόρτωση στιγμιότυπων Delta και επιταχύνει τις λειτουργίες που επωφελούνται από τη διάταξη Z και το Liquid Clustering σε πίνακες Delta, παρέχοντας περαιτέρω κέρδη απόδοσης για οργανωμένες διατάξεις δεδομένων.
Πότε να χρησιμοποιείτε τον εγγενή μηχανισμό εκτέλεσης
Ο εγγενής μηχανισμός εκτέλεσης προσφέρει μια λύση για την εκτέλεση ερωτημάτων σε σύνολα δεδομένων μεγάλης κλίμακας. Βελτιστοποιεί την απόδοση χρησιμοποιώντας τις εγγενείς δυνατότητες των υποκείμενων προελεύσεων δεδομένων και ελαχιστοποιώντας την επιβάρυνση που συνήθως σχετίζεται με τη μετακίνηση δεδομένων και τη σειριοποίηση σε παραδοσιακά περιβάλλοντα Spark. Ο μηχανισμός υποστηρίζει διάφορους τελεστές και τύπους δεδομένων, συμπεριλαμβανομένων των συγκεντρωτικών αποτελεσμάτων συνάθροισης, της ένθετης ένωσης ένθετων βρόχων μετάδοσης (BNLJ) και επακριβών μορφών χρονικής σήμανσης. Ωστόσο, για να επωφεληθείτε πλήρως από τις δυνατότητες της μηχανής, θα πρέπει να εξετάσετε τις βέλτιστες περιπτώσεις χρήσης:
- Η μηχανή είναι αποτελεσματική όταν εργάζεται με δεδομένα σε μορφές Parquet και Delta, τις οποίες μπορεί να επεξεργαστεί εγγενώς και αποτελεσματικά.
- Τα ερωτήματα που περιλαμβάνουν περίπλοκους μετασχηματισμούς και συναθροίσεις επωφελούνται σημαντικά από τις δυνατότητες επεξεργασίας στηλών και διανυσματικής λειτουργίας του μηχανισμού.
- Η βελτίωση των επιδόσεων είναι πιο σημαντική σε σενάρια όπου τα ερωτήματα δεν ενεργοποιούν τον εναλλακτικό μηχανισμό, αποφεύγοντας μη υποστηριζόμενες δυνατότητες ή παραστάσεις.
- Ο μηχανισμός είναι κατάλληλος για ερωτήματα που κάνουν εντατική χρήση υπολογιστικών υπολογισμών, αντί για απλή σύνδεση με I/O.
Για πληροφορίες σχετικά με τους τελεστές και τις συναρτήσεις που υποστηρίζονται από τον εγγενή μηχανισμό εκτέλεσης, ανατρέξτε στην τεκμηρίωση για τη μέθοδο Apache Url.
Ενεργοποίηση του εγγενούς μηχανισμού εκτέλεσης
Για να χρησιμοποιήσετε τις πλήρεις δυνατότητες του εγγενούς μηχανισμού εκτέλεσης κατά τη φάση προεπισκόπησης, απαιτούνται συγκεκριμένες ρυθμίσεις παραμέτρων. Οι παρακάτω διαδικασίες δείχνουν πώς μπορείτε να ενεργοποιήσετε αυτήν τη δυνατότητα για σημειωματάρια, ορισμούς εργασιών Spark και ολόκληρα περιβάλλοντα.
Σημαντικό
Ο εγγενής μηχανισμός εκτέλεσης υποστηρίζει Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2) και Runtime 2.0 (Apache Spark 4.1, Delta Lake 4.1).
Ενεργοποίηση σε επίπεδο περιβάλλοντος
Για να εξασφαλίσετε ομοιόμορφη βελτίωση των επιδόσεων, ενεργοποιήστε τον εγγενή μηχανισμό εκτέλεσης σε όλες τις εργασίες και σημειωματάρια που σχετίζονται με το περιβάλλον σας:
Μεταβείτε στον χώρο εργασίας που περιέχει το περιβάλλον σας και επιλέξτε το περιβάλλον. Εάν δεν έχετε δημιουργήσει περιβάλλον, ανατρέξτε στο θέμα Δημιουργία, ρύθμιση παραμέτρων και χρήση περιβάλλοντος στο Fabric.
Στην περιοχή Υπολογισμός σπινθήρα, επιλέξτε Επιτάχυνση.
Επιλέξτε το πλαίσιο με την ετικέτα Ενεργοποίηση εγγενούς μηχανισμού εκτέλεσης.
Αποθηκεύστε και δημοσιεύστε τις αλλαγές.
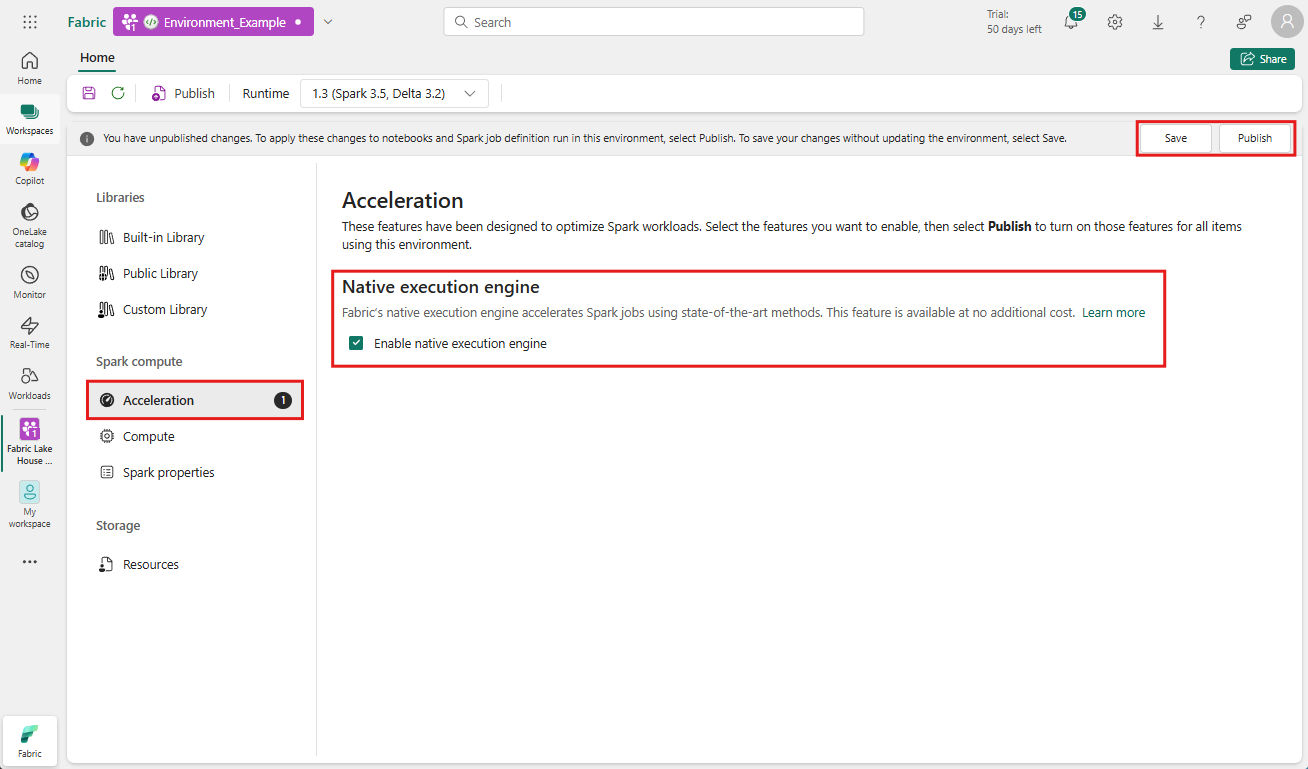

Όταν ενεργοποιηθεί στο επίπεδο περιβάλλοντος, όλες οι επόμενες εργασίες και σημειωματάρια μεταβιβάζονται στη ρύθμιση. Αυτή η μεταβίβαση εξασφαλίζει ότι οποιεσδήποτε νέες περίοδοι λειτουργίας ή πόροι που δημιουργούνται στο περιβάλλον επωφελούνται αυτόματα από τις βελτιωμένες δυνατότητες εκτέλεσης.
Σημαντικό
Στο παρελθόν, ο εγγενής μηχανισμός εκτέλεσης ενεργοποιήθηκε μέσω των ρυθμίσεων Spark εντός της ρύθμισης παραμέτρων περιβάλλοντος. Ο εγγενής μηχανισμός εκτέλεσης μπορεί πλέον να ενεργοποιηθεί πιο εύκολα χρησιμοποιώντας ένα κουμπί εναλλαγής στην καρτέλα Επιτάχυνση των ρυθμίσεων περιβάλλοντος. Για να συνεχίσετε να το χρησιμοποιείτε, μεταβείτε στην καρτέλα Επιτάχυνση και ενεργοποιήστε το κουμπί εναλλαγής. Μπορείτε επίσης να την ενεργοποιήσετε μέσω των ιδιοτήτων Spark, εάν προτιμάτε.
Ενεργοποίηση για ορισμό εργασίας σημειωματάριου ή Spark
Μπορείτε επίσης να ενεργοποιήσετε τον εγγενή μηχανισμό εκτέλεσης για ένα μόνο σημειωματάριο ή ορισμό εργασίας Spark. Πρέπει να ενσωματώσετε τις απαραίτητες ρυθμίσεις παραμέτρων στην αρχή της δέσμης ενεργειών εκτέλεσης:
%%configure
{
"conf": {
"spark.native.enabled": "true",
}
}
Για σημειωματάρια, εισαγάγετε τις απαιτούμενες εντολές ρύθμισης παραμέτρων στο πρώτο κελί. Για ορισμούς εργασίας Spark, συμπεριλάβετε τις ρυθμίσεις στην πρώτη γραμμή του ορισμού εργασίας Spark. Ο εγγενής μηχανισμός εκτέλεσης ενσωματώνεται με χώρους συγκέντρωσης, επομένως, μόλις ενεργοποιήσετε τη δυνατότητα, τίθεται σε ισχύ αμέσως χωρίς να χρειάζεται να ξεκινήσετε μια νέα περίοδο λειτουργίας.
Στοιχείο ελέγχου σε επίπεδο ερωτήματος
Οι μηχανισμοί ενεργοποίησης του εγγενούς μηχανισμού εκτέλεσης στα επίπεδα μισθωτή, χώρου εργασίας και περιβάλλοντος, απρόσκοπτα ενοποιημένοι με το περιβάλλον εργασίας χρήστη, βρίσκονται υπό ενεργή ανάπτυξη. Εν τω μεταξύ, μπορείτε να απενεργοποιήσετε τον εγγενή μηχανισμό εκτέλεσης για συγκεκριμένα ερωτήματα, ειδικά εάν περιλαμβάνουν τελεστές που δεν υποστηρίζονται αυτήν τη στιγμή (ανατρέξτε στους περιορισμούς). Για να απενεργοποιήσετε, ορίστε τη ρύθμιση παραμέτρων Spark spark.native.enabled σε false για το συγκεκριμένο κελί που περιέχει το ερώτημά σας.
%%sql
SET spark.native.enabled=FALSE;

Αφού εκτελέσετε το ερώτημα στο οποίο είναι απενεργοποιημένος ο εγγενής μηχανισμός εκτέλεσης, πρέπει να τον ενεργοποιήσετε ξανά για τα επόμενα κελιά, ορίζοντας το spark.native.enabled σε true. Αυτό το βήμα είναι απαραίτητο, επειδή το Spark εκτελεί κελιά κώδικα διαδοχικά.
%%sql
SET spark.native.enabled=TRUE;
Προσδιορισμός λειτουργιών που εκτελέστηκαν από τη μηχανή
Υπάρχουν διάφορες μέθοδοι για να προσδιορίσετε εάν έγινε επεξεργασία ενός τελεστή στην εργασία σας Apache Spark χρησιμοποιώντας τον εγγενή μηχανισμό εκτέλεσης.
Περιβάλλον εργασίας χρήστη Spark και διακομιστής ιστορικού Spark
Αποκτήστε πρόσβαση στο περιβάλλον εργασίας χρήστη Spark ή στο διακομιστή ιστορικού Spark για να εντοπίσετε το ερώτημα που πρέπει να ελέγξετε. Για να αποκτήσετε πρόσβαση στο περιβάλλον εργασίας web Spark, μεταβείτε στον ορισμό εργασίας Spark και εκτελέστε τον. Από την καρτέλα

Στο σχέδιο ερωτήματος που εμφανίζεται στη διασύνδεση Spark UI, αναζητήστε τυχόν ονόματα κόμβων που τελειώνουν με το επίθημα Transformer, *NativeFileScan ή VeloxColumnarToRowExec. Το επίθημα υποδεικνύει ότι ο εγγενής μηχανισμός εκτέλεσης εκτέλεσε τη λειτουργία. Για παράδειγμα, οι κόμβοι μπορεί να έχουν ετικέτα ως RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer ή BroadcastNestedLoopJoinExecTransformer. Για πηγές δεδομένων CSV, οι εγγενείς σαρώσεις ενδέχεται να εμφανίζονται ως κόμβοι σάρωσης εγγενών αρχείων ή μετασχηματιστών στο περιβάλλον εργασίας χρήστη Spark, παρόμοιοι με τους κόμβους σάρωσης Parquet και Delta.

Επεξήγηση dataFrame
Εναλλακτικά, μπορείτε να εκτελέσετε την df.explain() εντολή στο σημειωματάριό σας για να προβάλετε το σχέδιο εκτέλεσης. Εντός της εξόδου, αναζητήστε τα ίδια transformer, *NativeFileScan ή επιθήματα VeloxColumnarToRowExec. Αυτή η μέθοδος παρέχει έναν γρήγορο τρόπο για να επιβεβαιώσετε εάν ο χειρισμός συγκεκριμένων λειτουργιών γίνεται από τον εγγενή μηχανισμό εκτέλεσης.

Ειδοποιήσεις του Fabric Spark Advisor
Το Fabric Spark Advisor παρέχει εναλλακτική ορατότητα σε πραγματικό χρόνο κατά την εκτέλεση κελιών σημειωματαρίου. Όταν ένας χειριστής ή ένα τμήμα σχεδίου επιστρέφει στο Spark που βασίζεται σε JVM αντί για την εγγενή διαδρομή, ο Σύμβουλος εμφανίζει μια ειδοποίηση απευθείας στην έξοδο του κελιού σημειωματάριου, βοηθώντας σας να εντοπίσετε γρήγορα μη υποστηριζόμενους χειριστές ή διαμορφώσεις χωρίς να βγείτε από το σημειωματάριο. Μπορείτε να χρησιμοποιήσετε αυτές τις ειδοποιήσεις για να διαγνώσετε πότε δεν εφαρμόζεται η εγγενής μείωση φόρτου και να αποφασίσετε εάν θα προσαρμόσετε το ερώτημα ή τη ρύθμιση παραμέτρων.
Μηχανισμός επιστροφής
Σε ορισμένες περιπτώσεις, ο εγγενής μηχανισμός εκτέλεσης ενδέχεται να μην μπορεί να εκτελέσει ένα ερώτημα για λόγους όπως μη υποστηριζόμενες δυνατότητες. Σε αυτές τις περιπτώσεις, η λειτουργία πέφτει πίσω στον παραδοσιακό μηχανισμό Spark. Αυτός ο αυτόματος μηχανισμός επαναφοράς εξασφαλίζει ότι δεν υπάρχει διακοπή στη ροή εργασιών σας.


Παρακολούθηση ερωτημάτων και dataFrame που εκτελούνται από τον μηχανισμό
Για να κατανοήσετε καλύτερα τον τρόπο με τον οποίο εφαρμόζεται ο μηχανισμός εγγενούς εκτέλεσης σε ερωτήματα SQL και λειτουργίες DataFrame, καθώς και για να κάνετε λεπτομερή έρευνα στα επίπεδα σταδίου και τελεστή, μπορείτε να ανατρέξετε στο περιβάλλον εργασίας χρήστη Spark και στον Spark History Server για πιο λεπτομερείς πληροφορίες σχετικά με την εκτέλεση του εγγενούς μηχανισμού.
Καρτέλα "Εγγενής μηχανισμός εκτέλεσης"
Μπορείτε να μεταβείτε στη νέα καρτέλα 'Sql / DataFrame' Για να δείτε τις πληροφορίες δόμησης Δονήσεων και τις λεπτομέρειες εκτέλεσης ερωτημάτων. Ο πίνακας Ερωτήματα παρέχει πληροφορίες σχετικά με τον αριθμό των κόμβων που εκτελούνται στον εγγενή μηχανισμό και εκείνους που επιστρέφουν στην JVM για κάθε ερώτημα.

Γράφημα εκτέλεσης ερωτημάτων
Μπορείτε επίσης να επιλέξετε στην περιγραφή ερωτήματος για την απεικόνιση σχεδίου εκτέλεσης ερωτήματος Apache Spark. Το γράφημα εκτέλεσης παρέχει λεπτομέρειες εγγενούς εκτέλεσης σε στάδια και τις αντίστοιχες λειτουργίες τους. Τα χρώματα φόντου διαφοροποιούν τις μηχανές εκτέλεσης: το πράσινο αντιπροσωπεύει τον εγγενή μηχανισμό εκτέλεσης, ενώ το ανοιχτό μπλε υποδεικνύει ότι η λειτουργία εκτελείται στον προεπιλεγμένο μηχανισμό JVM.

Περιορισμοί
Παρόλο που ο εγγενής μηχανισμός εκτέλεσης (NEE) στο Microsoft Fabric αυξάνει σημαντικά την απόδοση για τις εργασίες Apache Spark, αυτήν τη στιγμή έχει τους ακόλουθους περιορισμούς:
Υπάρχοντες περιορισμοί
Μη συμβατές δυνατότητες Spark: Ο εγγενής μηχανισμός εκτέλεσης δεν υποστηρίζει προς το παρόν δομημένη ροή. Εάν οι μη υποστηριζόμενες δυνατότητες χρησιμοποιούνται είτε απευθείας είτε μέσω βιβλιοθηκών που έχουν εισαχθεί, το Spark επανέρχεται στον προεπιλεγμένο μηχανισμό του. Υποστηρίζονται πλέον Python UDF, Scala UDF και σύνθετοι τύποι δεδομένων (πίνακες, χάρτες, δομές). Για περισσότερες πληροφορίες, ανατρέξτε στο θέμα Python UDF, Scala UDF και σύνθετοι τύποι δεδομένων στον εγγενή μηχανισμό εκτέλεσης.
Μη υποστηριζόμενες μορφές αρχείων: Τα ερωτήματα και
JSONXMLοι μορφές δεν επιταχύνονται από τον εγγενή μηχανισμό εκτέλεσης. Αυτά επιστρέφουν από προεπιλογή στην κανονική μηχανή Spark JVM για εκτέλεση. Το CSV υποστηρίζεται πλέον μέσω του διανυσματικού αναλυτή CSV.Η λειτουργία ANSI δεν υποστηρίζεται: Ο εγγενής μηχανισμός εκτέλεσης δεν υποστηρίζει τη λειτουργία ANSI SQL. Εάν ενεργοποιηθεί, η εκτέλεση επιστρέφει στη μηχανή vanilla Spark.
Αναντιστοιχίες τύπου φίλτρου ημερομηνίας: Για να επωφεληθείτε από την επιτάχυνση του εγγενούς μηχανισμού εκτέλεσης, βεβαιωθείτε ότι και οι δύο πλευρές μιας σύγκρισης ημερομηνιών συμφωνούν στον τύπο δεδομένων. Για παράδειγμα, αντί να συγκρίνετε μια
DATETIMEστήλη με μια σταθερά συμβολοσειράς, χρησιμοποιήστε την ρητά όπως φαίνεται:CAST(order_date AS DATE) = '2024-05-20'
Άλλα ζητήματα και περιορισμοί
Δεκαδικός σε ασυμφωνία χύτευσης κινητής υποδιαστολής: Όταν γίνεται χύτευση από
DECIMALσεFLOAT, το Spark διατηρεί την ακρίβεια με τη μετατροπή σε μια συμβολοσειρά και την ανάλυση της. Το NEE (μέσω Velox) εκτελεί απευθείας από την εσωτερικήint128_tαναπαράσταση, το οποίο μπορεί να οδηγήσει σε ασυμφωνίες στρογγυλοποίηση.Σφάλματα ρύθμισης παραμέτρων ζώνης ώρας : Η ρύθμιση μιας μη αναγνωρίσιμης ζώνης ώρας στο Spark προκαλεί αποτυχία της εργασίας στο NEE, ενώ η spark JVM την χειρίζεται με χάρη. Για παράδειγμα:
"spark.sql.session.timeZone": "-08:00" // May cause failure under NEEΑσυνεπής συμπεριφορά στρογγυλοποίησης: Η
round()συνάρτηση συμπεριφέρεται διαφορετικά στο NEE λόγω της εξάρτησης απόstd::roundτο , το οποίο δεν αναπαράγει τη λογική στρογγυλοποίησης του Spark. Αυτό μπορεί να οδηγήσει σε αριθμητικές ασυνέπειες στα αποτελέσματα στρογγυλοποίηση.Λείπει η συνάρτηση ελέγχου
map()διπλότυπου κλειδιού: Ότανspark.sql.mapKeyDedupPolicyοριστεί σε ΕΞΑΙΡΕΣΗ, το Spark εμφανίζει ένα σφάλμα για τα διπλότυπα κλειδιά. Προς το παρόν, η NEE παραλείπει αυτόν τον έλεγχο και επιτρέπει την εσφαλμένη επιτυχία του ερωτήματος.
Παράδειγμα:SELECT map(1, 'a', 1, 'b'); -- Should fail, but returns {1: 'b'}Διακύμανση σειράς σε
collect_list()σχέση με την ταξινόμηση: Όταν χρησιμοποιείτεDISTRIBUTE BYτα καιSORT BY, ο Spark διατηρεί τη σειρά στοιχείων στοcollect_list(). Το NEE μπορεί να επιστρέψει τιμές με διαφορετική σειρά λόγω διαφορών με τυχαία σειρά, γεγονός που μπορεί να οδηγήσει σε αναντιστοιχίες προσδοκιών για λογική ευαίσθητη στις παραγγελίες.Ασυμφωνία ενδιάμεσου τύπου για
collect_list()/collect_set()το : Το Spark χρησιμοποιείBINARYτον ενδιάμεσο τύπο για αυτές τις συναθροίσεις, ενώ το NEE χρησιμοποιείARRAYτο . Αυτή η αναντιστοιχία μπορεί να οδηγήσει σε προβλήματα συμβατότητας κατά τον σχεδιασμό ή την εκτέλεση ερωτημάτων.Διαχειριζόμενα ιδιωτικά τελικά σημεία που απαιτούνται για πρόσβαση στον χώρο αποθήκευσης: Όταν είναι ενεργοποιημένος ο εγγενής μηχανισμός εκτέλεσης (NEE) και εάν οι εργασίες spark προσπαθούν να αποκτήσουν πρόσβαση σε έναν λογαριασμό χώρου αποθήκευσης χρησιμοποιώντας ένα διαχειριζόμενο ιδιωτικό τελικό σημείο, οι χρήστες πρέπει να ρυθμίσουν τις παραμέτρους ξεχωριστών διαχειριζόμενων ιδιωτικών τελικών σημείων για τα τελικά σημεία Blob (blob.core.windows.net) και DFS / File System (dfs.core.windows.net), ακόμα και αν παραπέμπουν στον ίδιο λογαριασμό χώρου αποθήκευσης. Ένα μεμονωμένο τελικό σημείο δεν μπορεί να επαναχρησιμοποιηθεί και για τα δύο. Αυτός είναι ένας τρέχων περιορισμός και ενδέχεται να απαιτεί πρόσθετη ρύθμιση παραμέτρων δικτύου κατά την ενεργοποίηση του εγγενούς μηχανισμού εκτέλεσης σε έναν χώρο εργασίας που έχει διαχειρισμένα ιδιωτικά τελικά σημεία σε λογαριασμούς αποθήκευσης.
Σχετικό περιεχόμενο
- Delta Lake σε Microsoft Fabric επισκόπηση
- Python UDF, Scala UDF και σύνθετοι τύποι δεδομένων στην εγγενή μηχανή εκτέλεσης
- Αποτελεσματικός διαχειριστής μείωσης και απομακρυσμένης τυχαίας αναπαραγωγής
- Χρόνοι εκτέλεσης Apache Spark στο Fabric
- Τι είναι το autotune για διαμορφώσεις Apache Spark στο Fabric;